本文主要是介绍【Redis】之高并发场景下主从同步数据一致性问题探究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
高并发极限场景
问题分布式锁失效,高并发极限场景下主从同步延时主节点崩溃等原因导致的数据不一致
背景知识:redis主从复制为异步同步过程
如图:redis cluster集群部署,多主多从架构(基于哈希槽的分配策略)
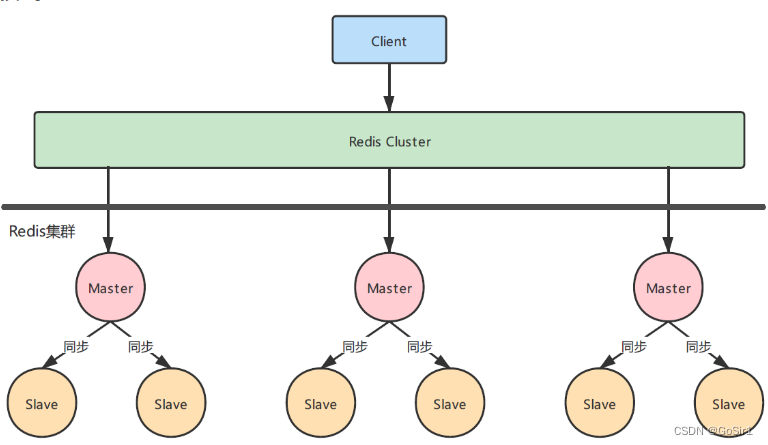
问题出现过程
1.A线程调用主节点master,A加锁成功
2.master节点崩溃or运维重启,master同步到slave异步操作,此时数据没有同步到slave节点
3.Cluster集群判断master节点发生故障,将slave节点升为主节点
4.并发B线程同时抢锁,请求达到新master,B加锁成功
针对这个问题2016年redis作者也给出了一个解决方案:RedLock
RedLock核心思想:
部署n个(最好奇数)独立的redis,请求同时发往这n个独立的redis,大多数的加锁请求成功才算加锁成功,否则回滚。请求过程还会计算一个TTL时间,来处理多个redis带来的时钟漂移。
RedLock潜在问题,极端场景举例:
1.如果仅为n个独立redis,无主从,以3台redis独立机器ABC为例,当第一次加锁请求AB成功C失败,判断加锁成功,此时B机器宕机,第次请求BC成功A失败,同样加锁成功
2.如果为n+n的主从结构,就又存在主从同步问题,除非一条命令一同步,否则和1相似,两次请求前后,存在机器宕机,主从同步失败的问题
有没有更好的分布式锁方案?
zookeeper!!!
这篇关于【Redis】之高并发场景下主从同步数据一致性问题探究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





