本文主要是介绍使用 Databend Kafka Connect 构建实时数据同步,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:韩山杰
Databend Cloud 研发工程师
hantmac (Jeremy) · GitHub

Kafka Connect 介绍
Kafka Connect 是一个用于在 Apache Kafka® 和其他数据系统之间可扩展且可靠地流式传输数据的工具。通过将数据移入和移出 Kafka 进行标准化,使得快速定义连接器以在 Kafka 中传输大型数据集变得简单,可以更轻松地构建大规模的实时数据管道。
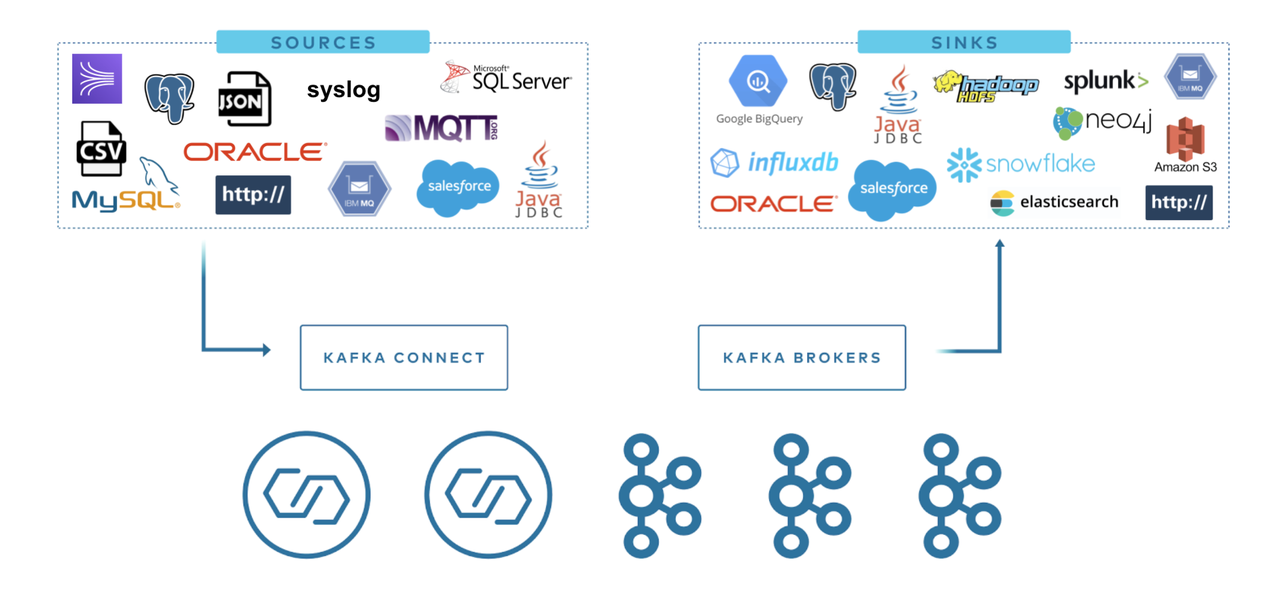
我们使用 Kafka Connector 读取或写入外部系统、管理数据流以及扩展系统,所有这些都无需开发新代码。Kafka Connect 管理与其他系统连接时的所有常见问题( Schema 管理、容错、并行性、延迟、投递语义等),每个 Connector 只关注如何在目标系统和 Kafka 之间复制数据。
Kafka 连接器通常用来构建 data pipeline,一般有两种使用场景:
-
开始和结束的端点: 例如,将 Kafka 中的数据导出到 Databend 数据库,或者把 Mysql 数据库中的数据导入 Kafka 中。
-
数据传输的中间媒介: 例如,为了把海量的日志数据存储到 Elasticsearch 中,可以先把这些日志数据传输到 Kafka 中,然后再从 Kafka 中将这些数据导入到 Elasticsearch 中进行存储。Kafka 连接器可以作为数据管道各个阶段的缓冲区,将消费者程序和生产者程序有效地进行解耦。
Kafka Connect 分为两种:
- Source Connect: 负责将数据导入 Kafka。
- Sink Connect: 负责将数据从 Kafka 系统中导出到目标表。

Databend Kafka Connect
Kafka 目前在 Confluent Hub 上提供了上百种 Connector,比如 Elasticsearch Service Sink Connector, Amazon Sink Connector, HDFS Sink 等,用户可以使用这些 Connector 以 Kafka 为中心构建任意系统之间的数据管道。现在我们也为 Databend 提供了 Kafka Connect Sink Plugin,这篇文章我们将会介绍如何使用 MySQL JDBC Source Connector 和 Databend Sink Connector 构建实时的数据同步管道。

启动 Kafka Connect
本文假定操作的机器上已经安装 Apache Kafka,如果用户还没有安装,可以参考 Kafka quickstart 进行安装。
Kafka Connect 目前支持两种执行模式:Standalone 模式和分布式模式。
启动模式
Standalone 模式
在 Standalone 模式下,所有的工作都在单个进程中完成。这种模式更容易配置以及入门,但不能充分利用 Kafka Connect 的某些重要功能,例如,容错。我们可以使用如下命令启动 Standalone 进程:
bin/connect-standalone.sh config/connect-standalone.properties connector1.properties [connector2.properties ...]第一个参数 config/connect-standalone.properties 是 worker 的配置。这其中包括 Kafka 连接参数、序列化格式以及提交 Offset 的频率等配置:
bootstrap.servers=localhost:9092
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000后面的配置是指定要启动的 Connector 的参数。上述提供的默认配置适用于使用 config/server.properties 提供的默认配置运行的本地集群。如果使用不同配置或者在生产部署,那就需要对默认配置做调整。但无论怎样,所有 Worker(独立的和分布式的)都需要一些配置:
-
bootstrap.servers: 该参数列出了将要与 Connect 协同工作的 broker 服务器,Connector 将会向这些 broker 写入数据或者从它们那里读取数据。你不需要指定集群的所有 broker,但是建议至少指定 3 个。
-
key.converter 和 value.converter: 分别指定了消息键和消息值所使用的的转换器,用于在 Kafka Connect 格式和写入 Kafka 的序列化格式之间进行转换。这控制了写入 Kafka 或从 Kafka 读取的消息中键和值的格式。由于这与 Connector 没有任何关系,因此任何 Connector 可以与任何序列化格式一起使用。默认使用 Kafka 提供的 JSONConverter。有些转换器还包含了特定的配置参数。例如,通过将 key.converter.schemas.enable 设置成 true 或者 false 来指定 JSON 消息是否包含 schema。
-
offset.storage.file.filename: 用于存储 Offset 数据的文件。
这些配置参数可以让 Kafka Connect 的生产者和消费者访问配置、Offset 和状态 Topic。配置 Kafka Source 任务使用的生产者和 Kafka Sink 任务使用的消费者,可以使用相同的参数,但需要分别加上 ‘producer.’ 和 ‘consumer.’ 前缀。bootstrap.servers 是唯一不需要添加前缀的 Kafka 客户端参数。
distributed 模式
分布式模式可以自动平衡工作负载,并可以动态扩展(或缩减)以及提供容错。分布式模式的执行与 Standalone 模式非常相似:
bin/connect-distributed.sh config/connect-distributed.properties
不同之处在于启动的脚本以及配置参数。在分布式模式下,使用 connect-distributed.sh 来代替 connect-standalone.sh。第一个 worker 配置参数使用的是 config/connect-distributed.properties 配置文件:
bootstrap.servers=localhost:9092
group.id=connect-cluster
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1
#offset.storage.partitions=25
config.storage.topic=connect-configs
config.storage.replication.factor=1
status.storage.topic=connect-status
status.storage.replication.factor=1
#status.storage.partitions=5
offset.flush.interval.ms=10000Kafka Connect 将 Offset、配置以及任务状态存储在 Kafka Topic 中。建议手动创建 Offset、配置和状态的 Topic,以达到所需的分区数和复制因子。如果在启动 Kafka Connect 时尚未创建 Topic,将使用默认分区数和复制因子来自动创建 Topic,这可能不适合我们的应用。在启动集群之前配置如下参数至关重要:
-
group.id: Connect 集群的唯一名称,默认为 connect-cluster。具有相同 group id 的 worker 属于同一个 Connect 集群。需要注意的是这不能与消费者组 ID 冲突。
-
config.storage.topic: 用于存储 Connector 和任务配置的 Topic,默认为 connect-configs。需要注意的是这是一个只有一个分区、高度复制、压缩的 Topic。我们可能需要手动创建 Topic 以确保配置的正确,因为自动创建的 Topic 可能有多个分区或自动配置为删除而不是压缩。
-
offset.storage.topic: 用于存储 Offset 的 Topic,默认为 connect-offsets。这个 Topic 可以有多个分区。
-
status.storage.topic: 用于存储状态的 Topic,默认为 connect-status。这个 Topic 可以有多个分区。
需要注意的是在分布式模式下需要通过 rest api 来管理 Connector。
比如:
GET /connectors – 返回所有正在运行的connector名。
POST /connectors – 新建一个connector; 请求体必须是json格式并且需要包含name字段和config字段,name是connector的名字,config是json格式,必须包含你的connector的配置信息。
GET /connectors/{name} – 获取指定connetor的信息。
GET /connectors/{name}/config – 获取指定connector的配置信息。
PUT /connectors/{name}/config – 更新指定connector的配置信息。配置 Connector
MySQL Source Connector
1. 安装 MySQL Source Connector Plugin
这里我们使用 Confluent 提供的 JDBC Source Connector。
从 Confluent hub 下载 Kafka Connect JDBC 插件并将 zip 文件解压到 /path/kafka/libs 目录下。
2. 安装 MySQL JDBC Driver
因为 Connector 需要与数据库进行通信,所以还需要 JDBC 驱动程序。JDBC Connector 插件也没有内置 MySQL 驱动程序,需要我们单独下载驱动程序。MySQL 为许多平台提供了 JDBC 驱动程序。选择 Platform Independent 选项,然后下载压缩的 TAR 文件。该文件包含 JAR 文件和源代码。将此 tar.gz 文件的内容解压到一个临时目录。将 jar 文件(例如,mysql-connector-java-8.0.17.jar),并且仅将此 JAR 文件复制到与 kafka-connect-jdbc jar 文件相同的 libs 目录下:
cp mysql-connector-j-8.0.32.jar /opt/homebrew/Cellar/kafka/3.4.0/libexec/libs/3. 配置 MySQL Connector
在 /path/kafka/config 下创建 mysql.properties 配置文件,并使用下面的配置:
name=test-source-mysql-autoincrement
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost:3306/mydb?useSSL=false
connection.user=root
connection.password=123456
#mode=timestamp+incrementing
mode=incrementing
table.whitelist=mydb.test_kafka
poll.interval.ms=1000
table.poll.interval.ms=3000
incrementing.column.name=id
#timestamp.column.name=tms
topics=test_kafka针对配置我们这里重点介绍 mode , incrementing.column.name ,和 timestamp.column.name 几个字段。Kafka Connect MySQL JDBC Source 提供了三种增量同步模式:
-
incrementing
-
timestamp
-
timestamp+incrementing
4. 在 incrementing 模式下,每次都是根据 incrementing.column.name 参数指定的列,查询大于自上次拉取的最大id:
SELECT * FROM mydb.test_kafka
WHERE id > ?
ORDER BY id ASC这种模式的缺点是无法捕获行上更新操作(例如,UPDATE、DELETE)的变更,因为无法增大该行的 id。
5. timestamp 模式基于表上时间戳列来检测是否是新行或者修改的行。该列最好是随着每次写入而更新,并且值是单调递增的。需要使用 timestamp.column.name 参数指定时间戳列。
需要注意的是时间戳列在数据表中不能设置为 Nullable.
在 timestamp 模式下,每次都是根据 timestamp.column.name 参数指定的列,查询大于自上次拉取成功的 gmt_modified:
SELECT * FROM mydb.test_kafka
WHERE tms > ? AND tms < ?
ORDER BY tms ASC这种模式可以捕获行上 UPDATE 变更,缺点是可能造成数据的丢失。由于时间戳列不是唯一列字段,可能存在相同时间戳的两列或者多列,假设在导入第二条的过程中发生了崩溃,在恢复重新导入时,拥有相同时间戳的第二条以及后面几条数据都会丢失。这是因为第一条导入成功后,对应的时间戳会被记录已成功消费,恢复后会从大于该时间戳的记录开始同步。此外,也需要确保时间戳列是随着时间递增的,如果人为的修改时间戳列小于当前同步成功的最大时间戳,也会导致该变更不能同步。
6. 仅使用 incrementing 或 timestamp 模式都存在缺陷。将 timestamp 和 incrementing 一起使用,可以充分利用 incrementing 模式不丢失数据的优点以及 timestamp 模式捕获更新操作变更的优点。需要使用 incrementing.column.name 参数指定严格递增列、使用 timestamp.column.name 参数指定时间戳列。
SELECT * FROM mydb.test_kafka
WHERE tms < ?AND ((tms = ? AND id > ?) OR tms > ?)
ORDER BY tms, id ASC由于 MySQL JDBC Source Connector 是基于 query-based 的数据获取方式,使用 SELECT 查询来检索数据,并没有复杂的机制来检测已删除的行,所以不支持
DELETE操作。可以使用基于 log-based 的 [Kafka Connect Debezium]。
后面的演示中会分别演示上述模式的效果。更多的配置参数可以参考 MySQL Source Configs 。
Databend Kafka Connector
1. 安装 OR 编译 Databend Kafka Connector
可以从源码编译得到 jar 或者从 release 直接下载。
git clone https://github.com/databendcloud/databend-kafka-connect.git & cd databend-kafka-connect
mvn -Passembly -Dmaven.test.skip package将 databend-kafka-connect.jar 拷贝至 /path/kafka/libs 目录下。
2. 安装 Databend JDBC Driver
从 Maven Central 下载最新的 Databend JDBC 并拷贝至 /path/kafka/libs 目录下。
3. 配置 Databend Kafka Connector
在 /path/kafka/config 下创建 mysql.properties 配置文件,并使用下面的配置:
name=databend
connector.class=com.databend.kafka.connect.DatabendSinkConnectorconnection.url=jdbc:databend://localhost:8000
connection.user=databend
connection.password=databend
connection.attempts=5
connection.backoff.ms=10000
connection.database=defaulttable.name.format=default.${topic}
max.retries=10
batch.size=1
auto.create=true
auto.evolve=true
insert.mode=upsert
pk.mode=record_value
pk.fields=id
topics=test_kafka
errors.tolerance=allauto.create 和 auto.evolve 设置成 true 后会自动建表并在源表结构发生变化时同步到目标表。关于更多配置参数的介绍可以参考 Databend Kafka Connect Properties。
测试 Databend Kafka Connect
准备各个组件
1. 启动 MySQL
version: '2.1'
services:postgres:image: debezium/example-postgres:1.1ports:- "5432:5432"environment:- POSTGRES_DB=postgres- POSTGRES_USER=postgres- POSTGRES_PASSWORD=postgresmysql:image: debezium/example-mysql:1.1ports:- "3306:3306"environment:- MYSQL_ROOT_PASSWORD=123456- MYSQL_USER=mysqluser- MYSQL_PASSWORD=mysqlpw2. 启动 Databend
version: '3'
services:databend:image: datafuselabs/databendvolumes:- /Users/hanshanjie/databend/local-test/databend/databend-query.toml:/etc/databend/query.tomlenvironment:QUERY_DEFAULT_USER: databendQUERY_DEFAULT_PASSWORD: databendMINIO_ENABLED: 'true'ports:- '8000:8000'- '9000:9000'- '3307:3307'- '8124:8124'3. 以 standalone 模式启动 Kafka Connect,并加载 MySQL Source Connector 和 Databend Sink Connector:
./bin/connect-standalone.sh config/connect-standalone.properties config/databend.properties config/mysql.properties[2023-09-06 17:39:23,128] WARN [databend|task-0] These configurations '[metrics.context.connect.kafka.cluster.id]' were supplied but are not used yet. (org.apache.kafka.clients.consumer.ConsumerConfig:385)
[2023-09-06 17:39:23,128] INFO [databend|task-0] Kafka version: 3.4.0 (org.apache.kafka.common.utils.AppInfoParser:119)
[2023-09-06 17:39:23,128] INFO [databend|task-0] Kafka commitId: 2e1947d240607d53 (org.apache.kafka.common.utils.AppInfoParser:120)
[2023-09-06 17:39:23,128] INFO [databend|task-0] Kafka startTimeMs: 1693993163128 (org.apache.kafka.common.utils.AppInfoParser:121)
[2023-09-06 17:39:23,148] INFO Created connector databend (org.apache.kafka.connect.cli.ConnectStandalone:113)
[2023-09-06 17:39:23,148] INFO [databend|task-0] [Consumer clientId=connector-consumer-databend-0, groupId=connect-databend] Subscribed to topic(s): test_kafka (org.apache.kafka.clients.consumer.KafkaConsumer:969)
[2023-09-06 17:39:23,150] INFO [databend|task-0] Starting Databend Sink task (com.databend.kafka.connect.sink.DatabendSinkConfig:33)
[2023-09-06 17:39:23,150] INFO [databend|task-0] DatabendSinkConfig values:...Insert
Insert 模式下我们需要使用如下的 MySQL Connector 配置:
name=test-source-mysql-jdbc-autoincrement
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost:3306/mydb?useSSL=false
connection.user=root
connection.password=123456
#mode=timestamp+incrementing
mode=incrementing
table.whitelist=mydb.test_kafka
poll.interval.ms=1000
table.poll.interval.ms=3000
incrementing.column.name=id
#timestamp.column.name=tms
topics=test_kafka在 MySQL 中创建数据库 mydb 和表 test_kafka:
CREATE DATABASE mydb;
USE mydb;CREATE TABLE test_kafka (id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,name VARCHAR(255) NOT NULL,description VARCHAR(512));
ALTER TABLE test_kafka AUTO_INCREMENT = 10;在插入数据之前,databend-kafka-connect 并不会收到 event 进行建表和数据写入。
插入数据:
INSERT INTO test_kafka VALUES (default,"scooter","Small 2-wheel scooter"),
(default,"car battery","12V car battery"),
(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),
(default,"hammer","12oz carpenter's hammer"),
(default,"hammer","14oz carpenter's hammer"),
(default,"hammer","16oz carpenter's hammer"),
(default,"rocks","box of assorted rocks"),
(default,"jacket","water resistent black wind breaker"),
(default,"cloud","test for databend"),
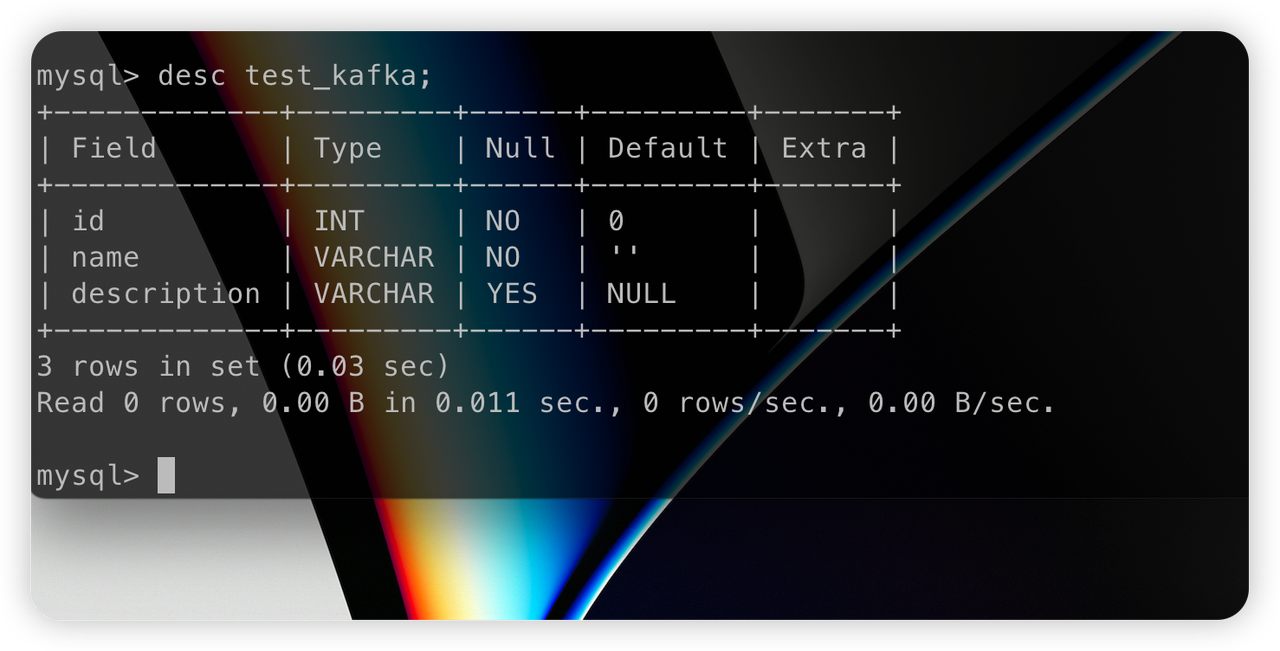
(default,"spare tire","24 inch spare tire");源表端插入数据后,
Databend 目标端的表就新建出来了:
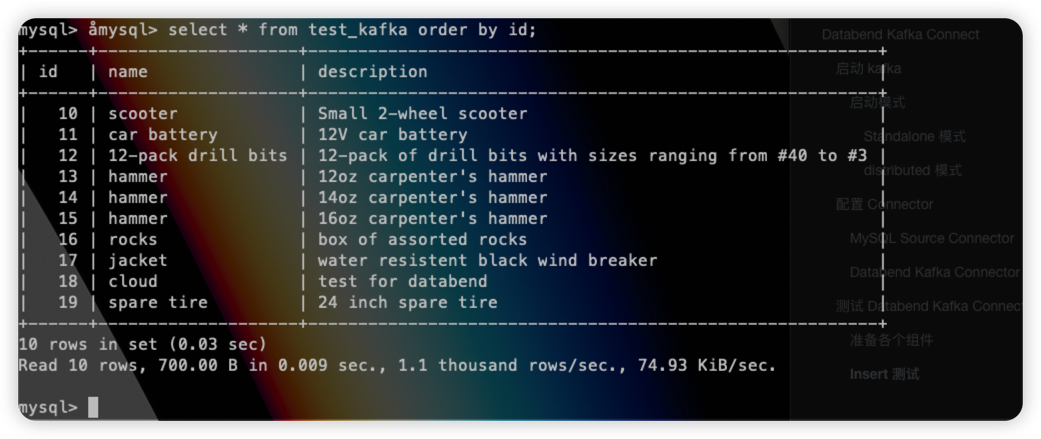
同时数据也会成功插入:
Support DDL
我们在配置文件中 auto.evolve=true,所以在源表结构发生变化的时候,会将 DDL 同步至目标表。这里我们正好需要将 MySQL Source Connector 的模式从 incrementing 改成 timestamp+incrementing,需要新增一个 timestamp 字段并打开 timestamp.column.name=tms 配置。我们在原表中执行:
alter table test_kafka add column tms timestamp;并插入一条数据:
insert into test_kafka values(20,"new data","from kafka",now());到目标表中查看:
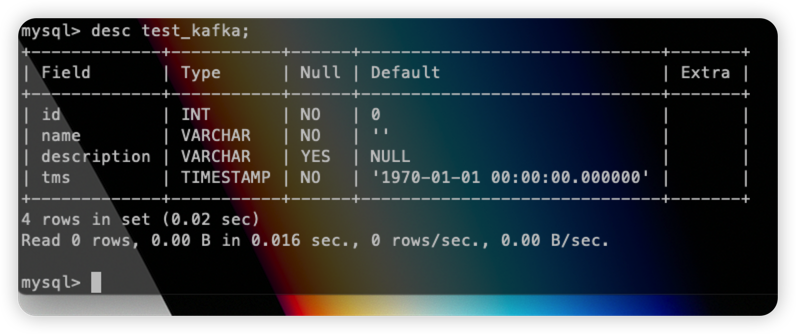
发现 tms 字段已经同步至 Databend table,并且该条数据也已经插入成功:
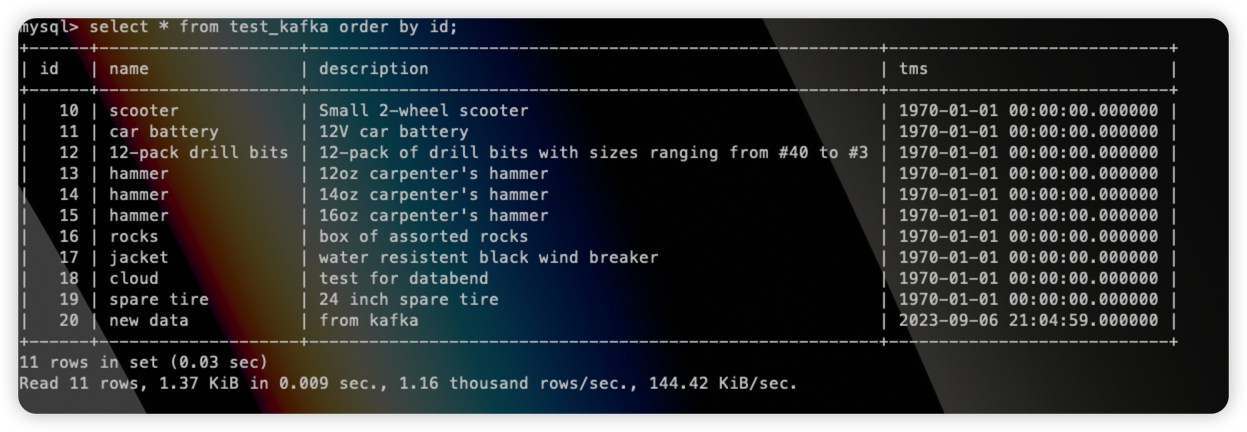
Upsert
修改 MySQL Connector 的配置为:
name=test-source-mysql-jdbc-autoincrement
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost:3306/mydb?useSSL=false
connection.user=root
connection.password=123456
mode=timestamp+incrementing
#mode=incrementing
table.whitelist=mydb.test_kafka
poll.interval.ms=1000
table.poll.interval.ms=3000
incrementing.column.name=id
timestamp.column.name=tms
topics=test_kafka主要是将 mode 改为 timestamp+incrementing并添加 timestamp.column.name 字段。
重启 Kafka Connect。
在源表中更新一条数据:
update test_kafka set name="update from kafka test" where id=20;到目标表中可以看到更新的数据:
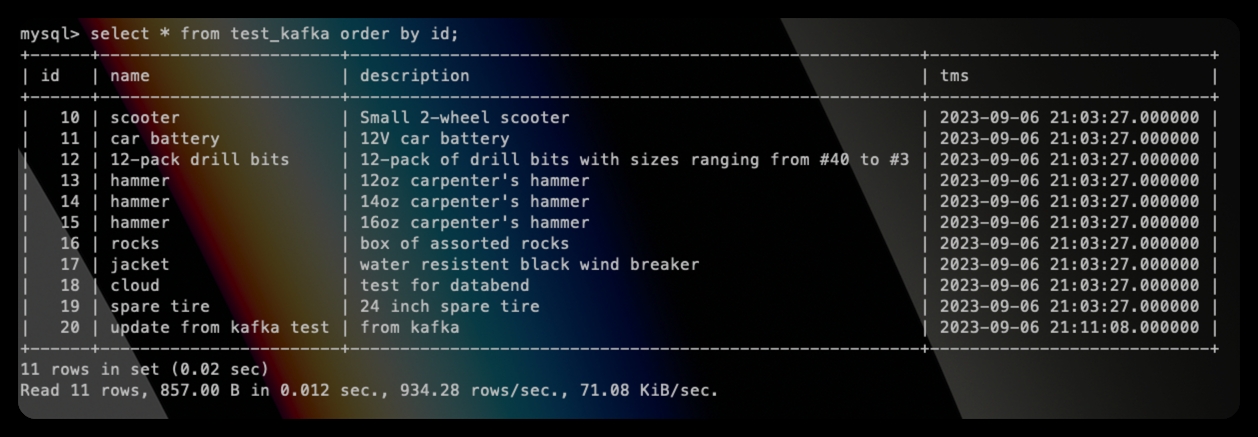
总结
通过上面的内容可以看到 Databend Kafka Connect 具有以下特性:
-
Table 和 Column 支持自动创建:
auto.create和auto-evolve的配置支持下,可以自动创建 Table 和 Column,Table name是基于 Kafka topic name 创建的; -
Kafka Shemas 支持: Connector 支持 Avro、JSON Schema 和 Protobuf 输入数据格式。必须启用 Schema Registry 才能使用基于 Schema Registry 的格式;
-
多个写入模式: Connector 支持
insert和upsert写入模式; -
多任务支持: 在 Kafka Connect 的能力下,Connector 支持运行一个或多个任务。增加任务的数量可以提高系统性能;
-
高可用: 分布式模式下可以自动平衡工作负载,并可以动态扩展(或缩减)以及提供容错能力。
同时,Databend Kafka Connect 也能够使用原生 Connect 支持的配置,更多配置参考 Kafka Connect Sink Configuration Properties for Confluent Platform。
Connect With Us
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
- Databend Website
- GitHub Discussions
- Slack Channel
这篇关于使用 Databend Kafka Connect 构建实时数据同步的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





