本文主要是介绍目标定位与检测系列(12):RetinaNet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文链接:RetinaNet
摘要
目前目标检测任务中精度最高的模型是基于主流的R-CNN框架的二阶段模型,该类方法在一些列目标候选框上进行分类。相对的,一阶段模型直接在大量的可能包含目标的区域进行检测,这样做速度更快但相比于两阶段模型也牺牲了精度,我们在本文工作中分析了这个问题的原因。我们发现训练过程中正负样本(指前景和背景)之间严重的不平衡是主要原因。我们通过修改标准的交叉信息熵损失函数来解决类别之间的不平衡,使得那些被很好地分类的样本的权重降低。我们提出的Focal Loss在训练中更关注那些难分类的样本,抑制了那些易分类的负样本的主导作用。为了评估Focal Loss的作用,我们设计并训练了一个简单的检测器即RetinaNet。我们的实验结果表明当使用Focal Loss进行训练时,RetinaNet可以在达到当前一阶段检测模型速度的同时超过现有的所有排名靠前的二阶段模型。源码地址: https://github.com/facebookresearch/Detectron.(目前Detectron已经更新到Detectron2)
动机
作者在文中指出,一阶段模型虽然在速度上比二阶段模型快很多,但在精度上却也不如二阶段模型。而导致这个问题的最根本原因是一阶段模型的正负样本不平衡要比二阶段模型严重德多,这样就会导致模型在训练过程中背景占据主导作用。那为什么一阶段模型的样本不平衡要比二阶段模型严重呢?这取决于两者候选框的生成机制:
- 二阶段模型使用诸如RPN的网络来生成候选框,在生成候选框的时候控制了候选框的数量,并且过滤掉了大部分的背景框。在训练分类器的时候,又严格控制了正负样本的比例(如典型的1:3)。
- 一阶段模型中并没有像RPN网络这样的机制,只能在原图上生成大量的候选框(高达数万个),其中大多数是背景框,导致候选框中的正负样本比例严重不平衡。虽然可以采用一些重采样的策略(如困难样本挖掘),但背景框依然占据着绝对的主导作用,导致模型在训练过程过拟合问题严重。
基于上述分析,文章从检测模型的类别损失函数入手,基于经典的交叉信息熵损失进行改进,使得模型在训练过程中自动权衡多数简单样本和少数困难样本的权重,从而解决一阶段模型中样本失衡的问题。
主要工作
Focal Loss
Focal Loss是对典型的交叉信息熵损失函数的改进。对于一个二分类问题,交叉信息熵损失函数定义如下:
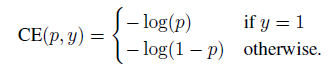
为了同一正负样本的损失函数表达式,做如下定义:
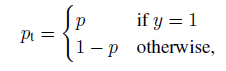
p t p_t pt在形式上就表示被预测为对应的正确类别的置信度。这样二分类交叉信息熵损失就可以重写成如下形式:
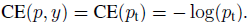
为了平衡多数类和少数类的损失,一种常规的思想就是在损失项前乘上一个平衡系数 α ∈ ( 0 , 1 ) \alpha\in(0,1) α∈(0,1),当类别为正时,取 α t = α \alpha_t=\alpha αt=α,当类别为负时,取 α t = 1 − α \alpha_t=1-\alpha αt=1−α,这样得到的带有平衡系数的交叉信息熵损失定义如下:
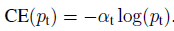
这样,根据训练样本中正负样本数量来选取 α \alpha α的值,就可以达到平衡正负样本的作用。然而,这样做还不能对简单和困难样本区别对待,在目标检测中,既要平衡多数类(背景)和少数类(包含目标的前景),还要平衡简单样本和困难样本,而往往训练过程中往往遇到的问题就是大量简单的背景样本占据损失函数的主要部分。因此,还需要对上述带有平衡系数的交叉信息熵损失做进一步的改进。于是就有了文章的核心内容Focal Loss,它定义如下:
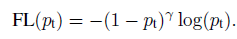
相比于上面的加了平衡系数 α \alpha α的损失函数相比,Focal Loss有以下两点不同:
- 固定的平衡系数 α \alpha α替换成了可变的平衡系数 ( 1 − p t ) (1-p_t) (1−pt)
- 多了另外一个调节因子 γ \gamma γ,且 γ ≥ 0 \gamma\ge0 γ≥0
之前已经提到过, p t p_t pt在形式上表示样本被预测为对应的正确类别的置信度,因此,可以理解为 p t p_t pt越接近于1,样本被正确分类的概率越高,也就意味着这个样本越容易分类,即简单样本。当 p t p_t pt越接近于0,表明样本被错误分类的概率越大,意味着这个样本越难分类,即困难样本。这时候再看前面的系数 ( 1 − p t ) (1-p_t) (1−pt),在 p t p_t pt越接近于1时,该项的值越小,反之越大,而由于 γ \gamma γ始终大于0,它对 ( 1 − p t ) (1-p_t) (1−pt)的结果做了进一步的放缩。举个例子,当 γ = 2 \gamma=2 γ=2时,假设有一个正样本预测正确的置信度 p t = 0.9 p_t=0.9 pt=0.9,可以说是一个容易分类的样本,此时平衡的系数项为 ( 1 − 0.9 ) 2 = 0.01 (1-0.9)^2=0.01 (1−0.9)2=0.01,意味它产生的损失变为原来的1/100;相反地,若一个样本被正确分类的置信度 p t = 0.1 p_t=0.1 pt=0.1,说明这是一个难分类的样本,此时它对应的平衡系数的结果为 ( 1 − 0.1 ) 2 = 0.81 (1-0.1)^2=0.81 (1−0.1)2=0.81,衰减程度远小于置信度为0.9的样本。论文也对比了 γ \gamma γ在取不同的值时的loss变化,如下图:
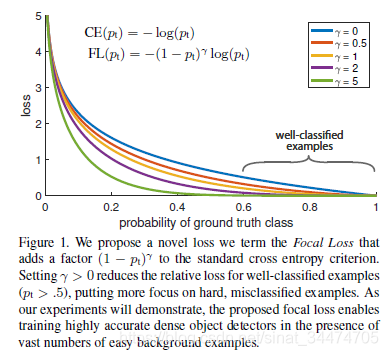
可以发现, γ \gamma γ取值越大,分类结果好的样本对应的缩放幅度越大。而在实验中文章也指出在 γ = 2 \gamma=2 γ=2的时候结果最好。
RetinaNet框架
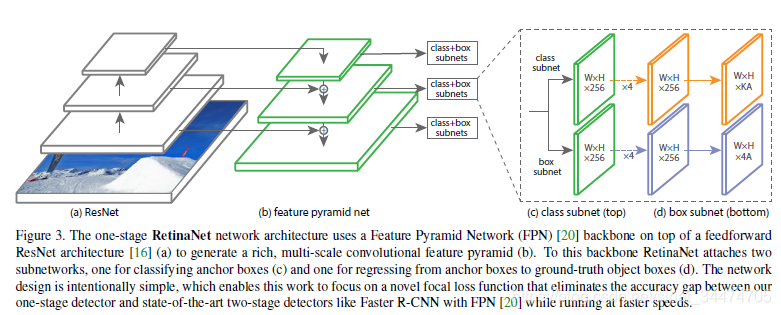
模型结构。 RetinaNet整体上是一个一阶段模型,由一个主干网络和两个分支网络组成。主干网络在ResNet结构采用特征金字塔,通过引入横向的连接融合不同层次的特征图;两个分支网络采用相同结构的全卷积网络(参数不共享),第一个分支负责预测类别信息;第二个分支网络用于边界框回归。从整体上看,RetinaNet是ResNet+FPN+FCN的组合使用。
锚点机制。 RetinaNet中也采用了类似RPN中的锚点机制,在每个特征金字塔层上都使用了3种长宽比的锚点,每个长宽比的锚点又有3个不同的尺度,共9个锚点。
推理过程。 当一张图片输入到网络进行前向传播时,在每个特征金字塔层级上会预测很多候选框,为了提高推理速度,RetinaNet种只取每层输出的前1000个置信度最高的候选框,最后将所有层级得到的候选框放到一起进行非极大值抑制(阈值取0.5),得到最终的检测结果。
实验结果
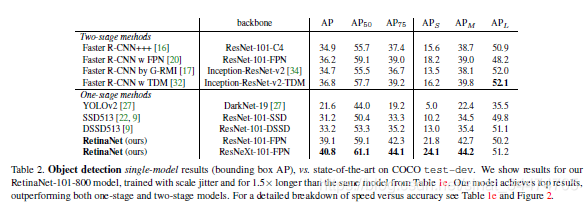
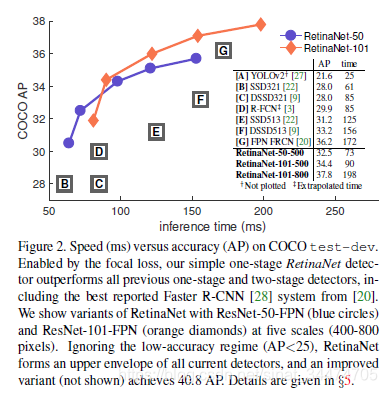
从实验对比中可以看出,基于ResNet-101-FPN和ResNeXt-101-FPN的RetinaNet几乎在COCO目标检测的各个指标上都明显高于主流的二阶段模型和一阶段模型,而在检测速度上,RetinaNet也与SSD框架相当。
总结
文章最主要的贡献是提出了Focal Loss来处理模型训练过程中少数难分类样本和多数简单样本的不平衡问题。为了验证Focal Loss的有效性,文中还设计了一阶段检测网络RetinaNet,并对比了和主流一阶段模型以及二阶段模型的性能和速度。结果也表明RetinaNet能够以一阶段模型的检测速度达到二阶段模型的检测精度。
这篇关于目标定位与检测系列(12):RetinaNet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









