本文主要是介绍论文阅读 【77】A Ranking-Based Cross-Entropy Loss for Early Classification of Time Series,SCI 一区,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
A Ranking-Based Cross-Entropy Loss for Early Classification of Time Series
IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS ,SCI 一区
Early classification of time series (ECTS)旨在在观察完整数据之前对时间序列进行分类。它在时间敏感的应用中至关重要,如重症监护病房(ICU)的早期败血症诊断。早期诊断可以为医生提供更多挽救生命的机会。
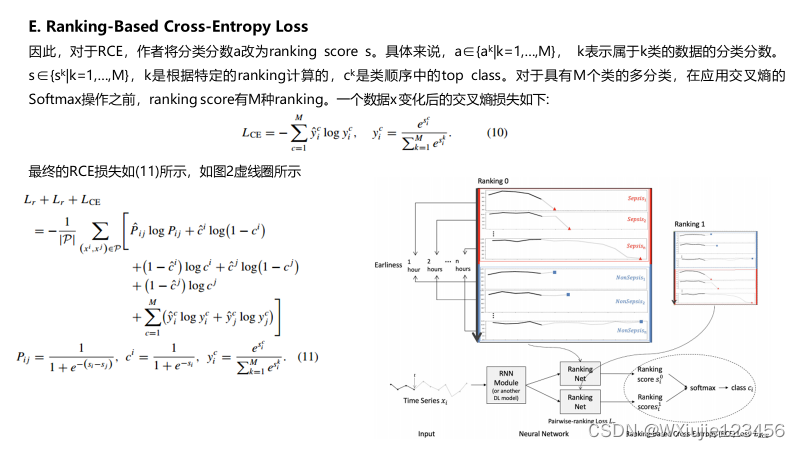
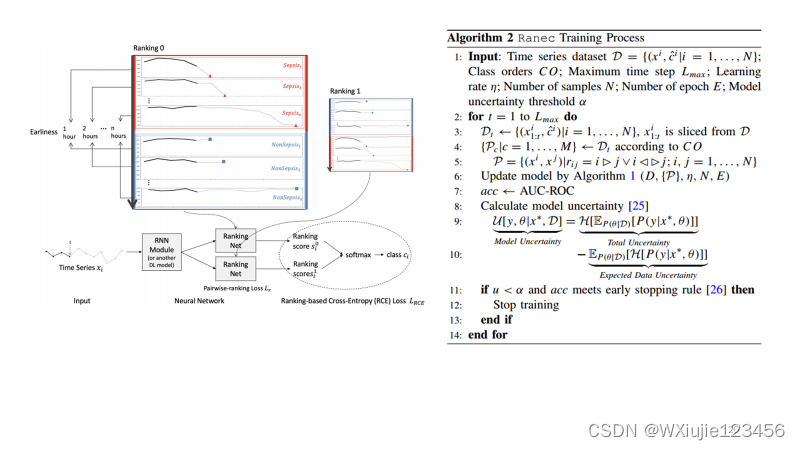
本文提出了一种基于ranking的交叉熵损失(RCE)方法,从时间序列数据中共同学习类的特征和早期顺序。这样,RCE可以帮助分类器生成具有更可区分边界的时间序列在不同阶段的概率分布。从而最终提高了每个时间步的分类精度。此外,为了提高方法的适用性,作者还将学习过程集中在高阶样本上,从而加快了训练过程。
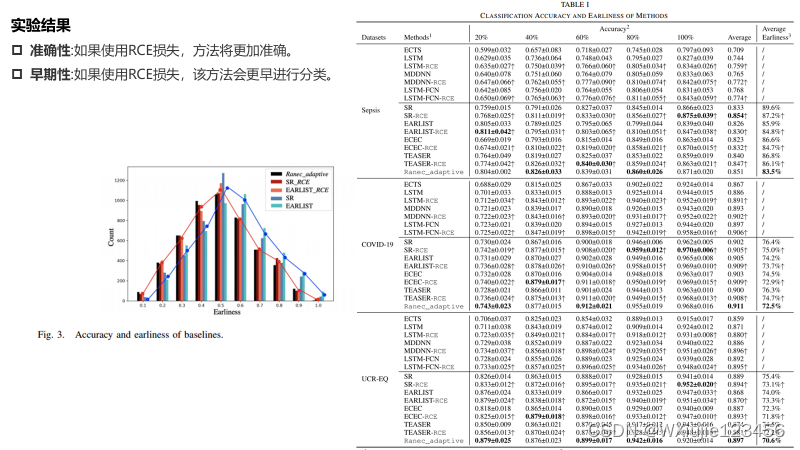
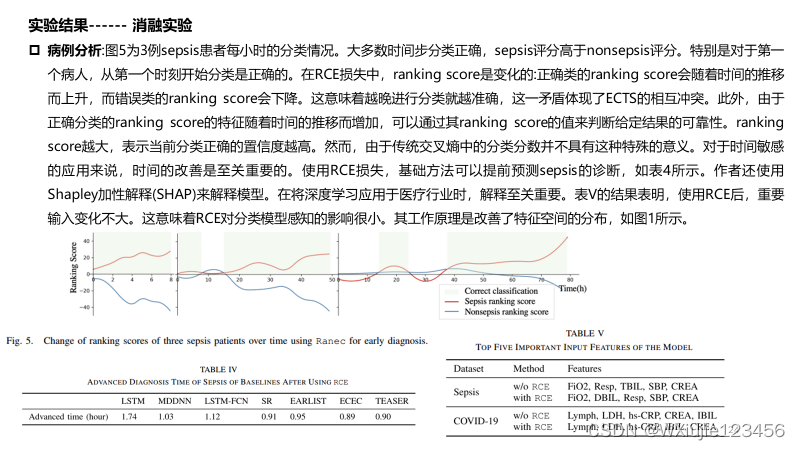
在三个真实数据集上的实验表明,本方法在任何时刻都能比所有baseline更准确地进行分类。
代码:https://github.com/SCXsunchenxi/RCE

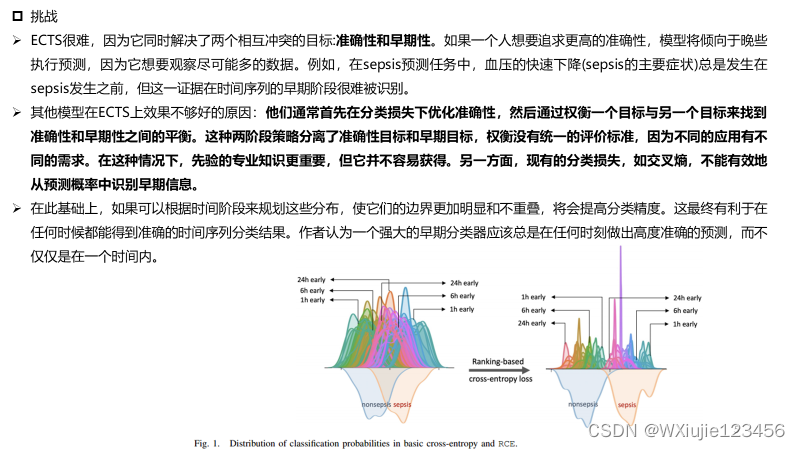

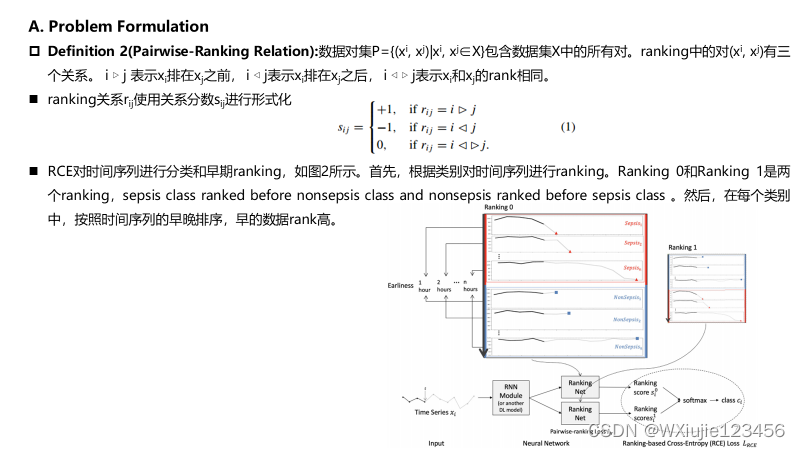
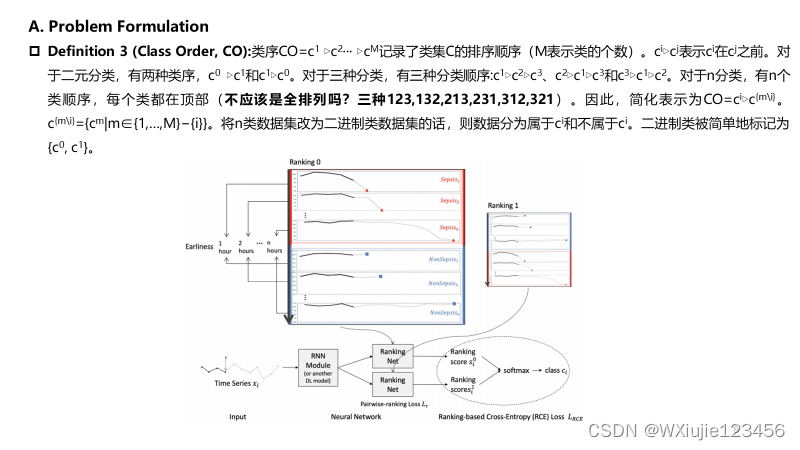

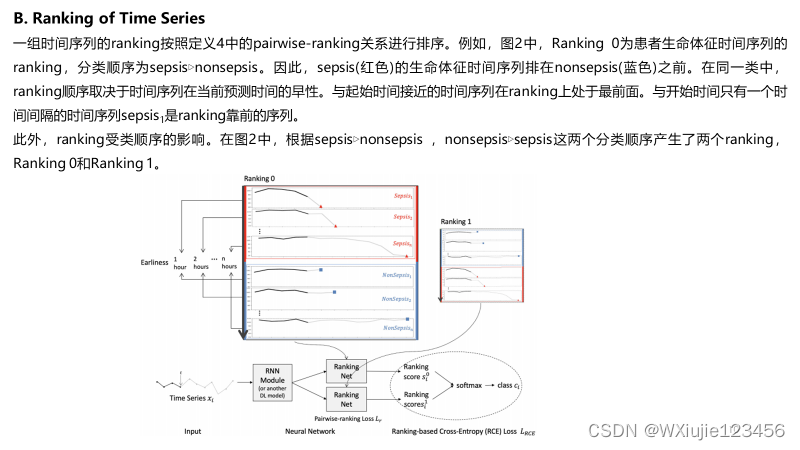










更多论文分享,请参考: 深度学习相关阅读论文汇总(持续更新)
这篇关于论文阅读 【77】A Ranking-Based Cross-Entropy Loss for Early Classification of Time Series,SCI 一区的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




