本文主要是介绍Apache Kylin在绿城客户画像系统中的实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
作为国内知名的房地产开发商,绿城经过24年的发展,已为全国25万户、80万人营造了美丽家园,并将以“理想生活综合服务提供商”为目标,持续为客户营造高品质的房产品和生活服务。
2017年,绿城理想生活集团成立,围绕客户全生活链、房屋全生命周期,为客户提供从买房子到房屋的保养维护,再到业主全方位的生活服务。为此构建了绿城+App生活服务平台、房产营销数字化平台及房屋4S服务平台,这些系统的构建为业主购房及生活服务提供了极大的便利,部分系统不仅开放给绿城客户、业主使用,同时也服务于非绿城的客户。通过一整套垂直行业的用户画像系统构建并使用Apache Kylin加速主要数据服务,有效提升了互联网广告推广、营销服务的效率。
一、绿城客户画像系统的背景
房产品的营造和线下销售是当前绿城的主营业务,为有效提升服务质量、管理效能,降低营销费用,实现客户服务智能化、销售行为自动化、成本管理合理化,绿城积极拥抱互联网,于2015年开始了数字化营销(Digital Marketing)的探索和研究,通过+互联网创新营销业务。
经过2年的探索和模式验证之后,2017年绿城成立了专门的大数据团队,围绕营销全过程和客户全生命周期, 构建了房地产行业首个全闭环的“房产营销数字化平台”,服务于营销找客到成交回款全过程,如下图所示:

图1 绿城房产营销数字化平台
在“房产营销数字化平台”中,精准营销和智慧案场为营销线最核心的两个系统,它们以广告投放、客户数据资产管理、经营指标分析为基础,延展出集合营销知识分享与学习、营销与转化工具、第三方供应商为一体的互联网平台,服务于房地产市场营销产业链生态圈,为Marketing阶段的客户获取提供了一站式程序化解决方案。另外置业绿城、掌上销售等系统则为后续的Sales环节提供数字化服务。
精准营销系统和智慧案场系统,基于DMP(Data Management Platform,数据管理平台)的数据分析和处理能力支撑和流转起所有业务逻辑,一方面,绿城DMP系统通过积累营销投放过程中的回流数据,另外一方面又采集置业绿城、全民营销系统(绿粉汇)、掌上销售系统中的埋点行为数据及数据库数据。通过上述种种方式为数字化营销建立更为准确优化的策略,从而真正做到“数据驱动营销”。绿城DMP的数据包含第一、第二和第三方数据:
第一方数据,即完全自有的数据。企业自身的CRM系统数据、网站和APP等运营活动的应用数据;
第二方数据,主要包括程序化广告投放过程中的交易数据;
第三方数据,主要为BAT数据、运营商数据等。
绿城DMP整体的业务架构图如下:
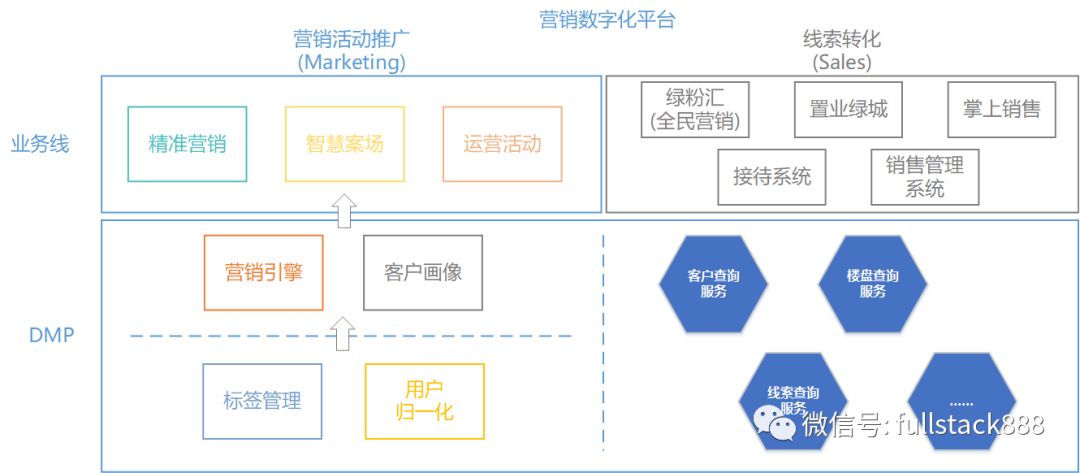
图2: 绿城DMP与系统间的逻辑架构
DMP作为服务于Marketing的核心工具,客户画像发挥着极其重要的作用。客户画像依赖于DMP的标签管理、用户归一化以及营销相关的客户数据,它为房子的营销推广提供决策支持和依据。
另外一方面,营销相关运营活动也需要画像系统支持。营销引擎基于用户画像系统,为精准营销、智慧案场系统提供统一的广告投放服务。
二、客户画像与Apache Kylin的结合
如前所述,客户画像服务于Marketing,其核心的业务流程可以用下图表示:
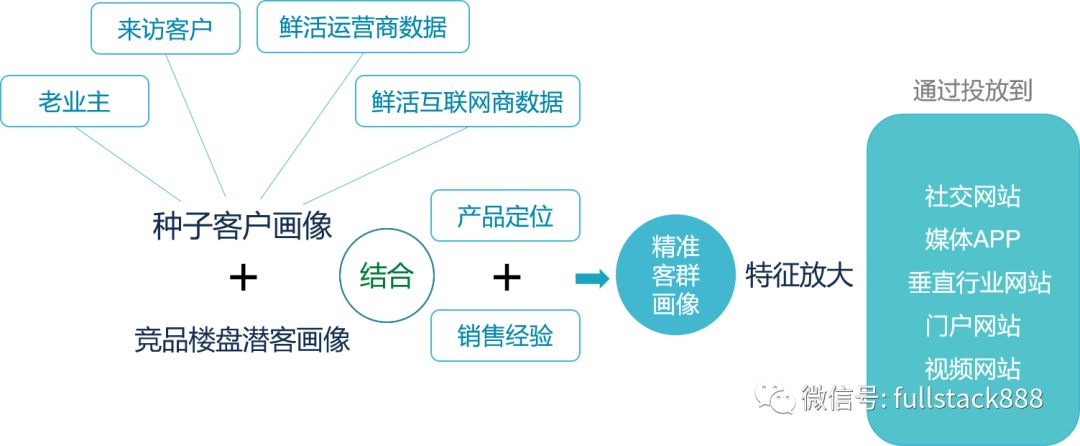
图3 客户画像的核心逻辑
通过DMP进行数据的采集、融合分析、归一化处理,再基于行业标签,为精准营销系统提供精准的人群画像,并投放到各类媒体及网站,实现对于受众的精准触达。
2015~2016年,绿城大数据平台中的数据主要通过Hive + HBase进行存储以及分析计算,后台的数据服务尤其是画像服务,均是基于HBase的Java API开发,那时基本能满足业务秒级的响应需求。但经历2017年的业务高速发展之后,随着渠道及合作方的增多,数据的体量和维度的增加了数十倍,画像等数据服务的响应速度逐渐降至5秒甚至30秒,部分业务查询甚至超过了1min,而且数据源头繁杂、维度众多,需要体系化地管理。为解决这个问题,绿城大数据团队于17年上半年进行标签体系建设形成共13大类、8000+细类的多维度标签,客户画像的构建,便依赖于这个丰富成熟的标签体系。
日均300G以上数据会沉淀在大数据平台中,数据体量的增加导致性能瓶颈明显,经过多轮测试、综合对比分析Apache Kudu,Presto,Druid以及Apache Kylin之后,最终选择Apache Kylin作为OLAP工具,最终优化并解决了数据服务查询的性能问题。选择Apache Kylin的主要原因有以下几点:
成熟度来讲:Apache Kylin和Druid 更为成熟(参照稳定性、性能、社区活跃度等因素)
查询效率来讲:Druid ≈ Apache Kylin,优于其他(主要业务场景)
实用和便捷性:Apache Kylin搭建和使用均较为便捷(同时也是华人的顶级开源项目)
另外,Apache Kylin还有以下优点:
Apache Kylin进行预计算,空间换时间,通过预定义、计算Cube的方式提升查询的速度和性能,同时,查询的性能随业务的增长也不会受到影响;
数据管理及同步方便。预计算、构建Cube、数据管理都可基于Apache Kylin自行管理;有开放的API可以方便、快速地对接内部数据处理流程、与调度系统打通。
绿城大数据平台每日增量构建数百GB的Cube,构建的时间从几小时到十几小时不等,之前后台较慢的查询时间范围是从十几到几十秒,使用Apache Kylin后则基本都在1-2秒内即可予以响应。最终优化之后的客户画像构建流程如下:
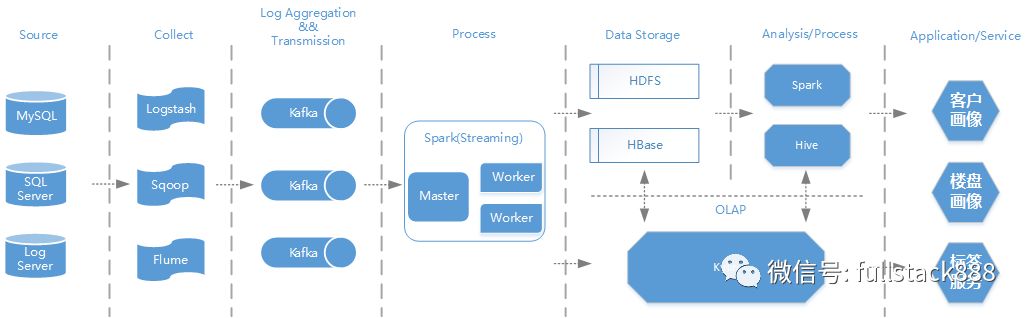
图4 客户画像构建流程
其中,业务系统数据和Log数据通过采集、传输后,基于Spark进行初步处理,之后包含埋点、运营活动等的结果数据会写入HDFS以及HBase中。一部分客户、楼盘的数据报告和分析服务通过Hive及Spark进行支撑和输出,而主要的数据服务则通过Apache Kylin进行构建。
在Kylin中,对于小数据量的Cube,或者经常需要全表更新的Cube,使用全量构建需要更少的运维精力,以少量的重复计算降低生产环境中的维护复杂度。而对于大数据量的Cube,例如对于一个包含两年历史数据的Cube,如果需要每天更新,那么每天为了新数据而去重复计算过去两年的数据就会变得非常浪费,而在这种情况下需要考虑使用增量构建。
因为绿城大数据平台的数据每天按日更新,并且日均数据量都会在百G以上,所以我们用到了Apache Kylin的增量构建Cube。Kylin在Web界面上提供了手动构建Cube的操作,此外,Apache Kylin也提供了Rest API进行增量构建。在绿城客户画像系统中,70%的自动化触发增量构建都基于Rest API完成。
图5 Apache Kylin构建Cube的Web页面
我们基于Apache Kylin构建好的数据服务,又通过开源工具Superset进行客户画像中标签数据的可视化分析展示,如下图:
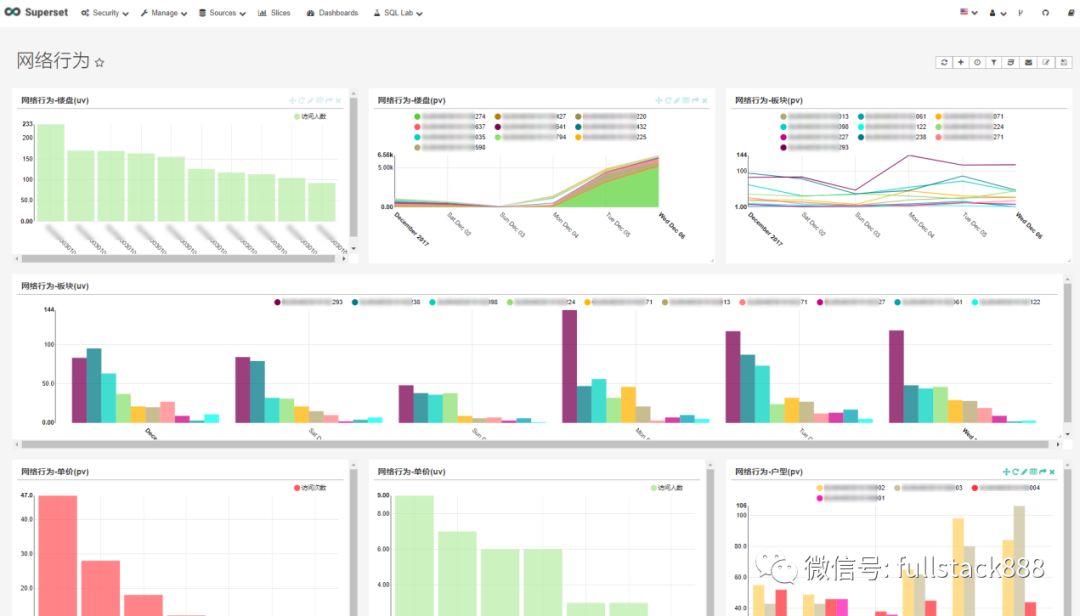
图6 基于Superset的标签画像展示
大数据可视化工具的选择非常丰富。在对比了开源工具Superset、Zeppelin以及商业工具FineBI后,最终采用Airbnb开源的Superset(曾用名Caravel)的主要原因如下:
数据安全性、权限控制,仅Superset有表检索的权限控制
图表多样性,Superset拥有多达30张以上的图表,多表的联动性-filter支持多表联动
数据库多元性,Superset既支持关系型数据库,也支持像Apache Kylin这样的大数据框架
社区活跃度相对更高
Superset作为一款开源的BI工具,能够满足我们对于标签画像联动分析的需求,节省了前端、UI的开发资源
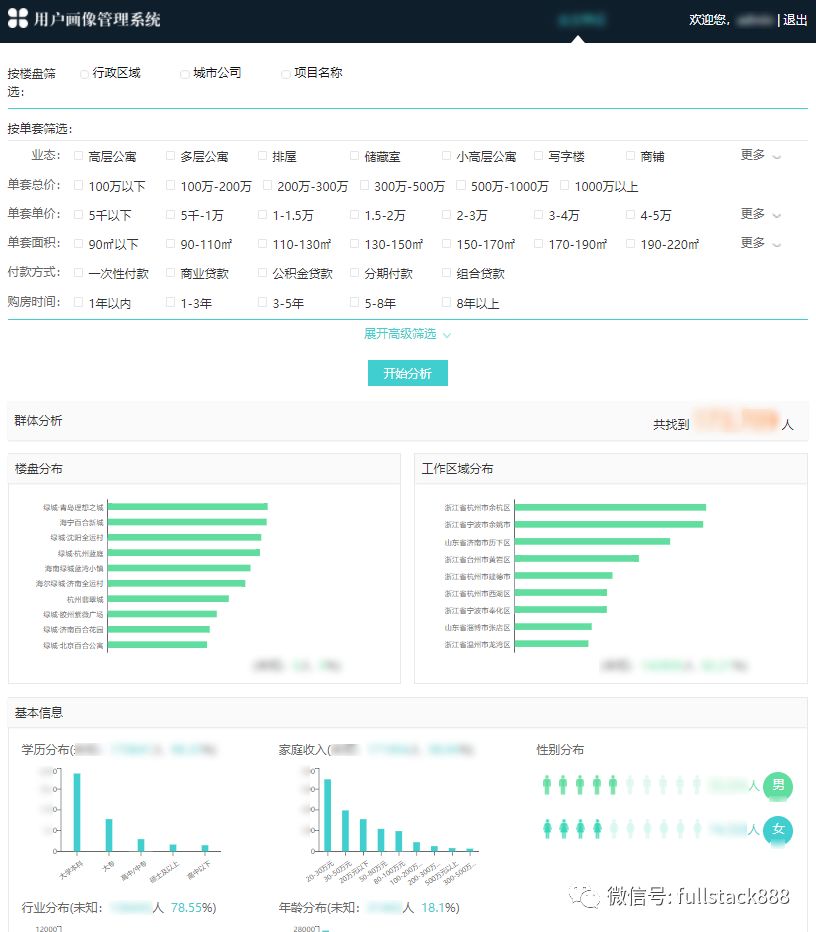
客户画像依赖的数据、后台计算引擎以及标签都构建完成后,绿城客户画像的一瞥如下图所示:
三、未来客户画像系统的展望
绿城客户画像系统目前只服务于房产营销,随着房屋4S、园区商业、绿城+App生活服务平台的日益成熟,画像系统将融合各业务系统数据,完成客户全生活链用户画像的建设,同时客户画像会融入知识图谱,建立业主与业主、业主与房子之间的连接,从而形成一套更加全面、可视化的用户画像系统。绿城大数据团队将积极拥抱开源、拥抱互联网,拥抱变化,持续用技术和数据驱动绿城各条线的业务发展。
推荐阅读:
1,Apache Kylin优化之—Cube的高级设置
2,kylin集群Nginx负载均衡
3,Phoenix边讲架构边调优
4,数据仓库③-实现与使用(含OLAP重点讲解)

这篇关于Apache Kylin在绿城客户画像系统中的实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








