本文主要是介绍【MVOS】Efficient Video Object Segmentation via Network Modulation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址 :http://openaccess.thecvf.com/content_cvpr_2018/papers/Yang_Efficient_Video_Object_CVPR_2018_paper.pdf
有代码!
Motivation
本文是semi-supervised的方法。最近有很多方法是在已有标注的视频帧上finetune出结果,所以作者想提出单一forward的网络segment instance object in video。
Pipline

网络的主体是“Segmentation Net”,Backbone是VGG16,作者在倒数四层每一层都加了一个“Modulator”,每个Modulator包括一个“Visual M”和“Spatial M”。
Visual Modulator
把visual guide frame(annotated first frame)输入网络(VGG16),并通过全链接,输出scalar个数为对应Segmentation Net最后4层通道数数。相当于学习Segmentation Net最后4层每个通道数的weight,每个通道学到的参数记作:![]()
Spatial Modulator
把pre-mask变成一个2维高斯分布的heatmap,记作![]() ,用于添加一个location信息,会做下采样来和Segmentation Net最后四层的feature map 的尺寸对齐。同时还会对每次下采样的heatmap做一个防缩和平移(用一个1x1的卷积实现):
,用于添加一个location信息,会做下采样来和Segmentation Net最后四层的feature map 的尺寸对齐。同时还会对每次下采样的heatmap做一个防缩和平移(用一个1x1的卷积实现):
![]()
Modulator
因此结合两者,可以得到每一层的输出:
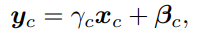
Implementation details
作者也是先在image dataset上pretrain(stage1),再在video dataset(DAVIS2017)上finetune20 epoch。
Result
作者做了对比实验,-B实验是只在image 上pretrain,-M实验是作者在这两个网络最后一层加上作者设计的Modulator

就搞不懂作者说的FT是怎么样的
2020年01月08日
这篇关于【MVOS】Efficient Video Object Segmentation via Network Modulation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs](https://img-blog.csdnimg.cn/img_convert/e75c9a4137c39630cd34c5ebe3fe8196.png)