本文主要是介绍论文阅读:DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1、论文总述
- 2、baseline:HTC介绍
- 3、ASPP模块介绍
- 4、RFP模块的具体实现
- 5、SAC模块的具体实现
- 6、SAC与条件卷积的区别
- 7、SAC中的global context与SENet中的不同
- 8、 Ablation Studies
- 9、 State-of-the-art comparison on COCO test-dev
- 10、SAC和RFP的优势(可视化结果)
- 参考文献
1、论文总述
本篇论文提出的目标检测模型DetectoRS在COCO数据集上的性能是当前最好(mAP:54.7),在实例分割和全景分割上效果也不错,主要是因为提出的改进方法是 基于backbone和FPN的, 适用于多种视觉任务,其他次优模型如:ResNeSt,CBnet也是基于backbone的改进,也许现在的趋势就是目标检测的网络结构大致已定(除anchor-free系列外),而且也有论文统计过,如今检测网络性能不好的大部分原因是因为目标检测网络的分类性能提不上去,所以现在的改进基本都是基于backbone和FPN的,例如BiFPN也是如此。
论文主要工作有两方面:一是在宏观方面提出了递归FPN:Recursive Feature Pyramid(RFP),就是把FPN的输出先连接到bottom up那儿进行再次输入,然后再输出时候与原FPN的输出再进行结合一起输出;二是在微观方面提出了可切换的空洞卷积:Switchable Atrous Convolution(SAC)。
注: 作者把提出的两个模块加入到HTC这个网络中,baseline就是HTC,作者也非常nice,论文给出的东西都很细,干货比较多,所以建议阅读一下原论文,只是看几篇博客是不能完全理解这些细节的,作者在实验部分对权重的初始化都进行了详细介绍。

DetectoRS指标对比:

At the macro level, our proposed Recursive Feature Pyramid (RFP) builds on top of the Feature Pyramid Networks
(FPN) [44] by incorporating extra feedback connections from
the FPN layers into the bottom-up backbone layers, as illustrated in Fig. 1a. Unrolling the recursive structure to a
sequential implementation, we obtain a backbone for object
detector that looks at the images twice or more. Similar to
the cascaded detector heads in Cascade R-CNN trained with
more selective examples, our RFP recursively enhances FPN
to generate increasingly powerful representations.
At the micro level, we propose Switchable Atrous Convolut
ion (SAC), which convolves the same input feature with
different atrous rates [11,30,53] and gathers the results using
switch functions. Fig. 1b shows an illustration of the concept of SAC. The switch functions are spatially dependent,
i.e., each location of the feature map might have different
switches to control the outputs of SAC. To use SAC in the
detector, we convert all the standard 3x3 convolutional layers in the bottom-up backbone to SAC, which improves the
detector performance by a large margin. Some previous
methods adopt conditional convolution, e.g., [39, 74], which
also combines results of different convolutions as a single
output. Unlike those methods whose architecture requires
to be trained from scratch, SAC provides a mechanism to
easily convert pretrained standard convolutional networks
(e.g., ImageNet-pretrained [59] checkpoints). Moreover, a
new weight locking mechanism is used in SAC where the
weights of different atrous convolutions are the same except
for a trainable difference.
Combining the proposed RFP and SAC results in our DetectoRS. To demonstrate its effectiveness, we incorporate
DetectoRS into the state-of-art HTC [7] on the challenging
COCO dataset [47].
2、baseline:HTC介绍
 HTC的主要思想:
HTC的主要思想:
通过在每个阶段结合级联和多任务来改善信息流,并利用空间背景来进一步提高准确性。整个网络是多任务多阶段的混合级联结构,训练时每个 stage 内 box 和 mask 分支采用交替执行,并在不同 stage 的 mask 分支之间引入直接的信息流。
总结:
(1)多任务多阶段的混合级联结构
(2)训练时每个 stage 内 box 和 mask 分支采用交替执行
(3)在不同 stage 的 mask 分支之间引入直接的信息流
(4)语义分割的特征和原始的 box/mask 分支融合,增强 spatial context(图d的s模块)
参考:实例分割的进阶三级跳:从 Mask R-CNN 到 Hybrid Task Cascade
3、ASPP模块介绍
使用带有空洞卷积的空间金字塔池化(ASPP)模块来实现两个递归特征金字塔的级联连接,该连接模块以其特征为输入并将其转换为Figure3中使用的RFP的特征(RFP Feature)。

本文中有所修改去除了1x1卷积分支。
本文中的ASPP有四个并行分支对其输入进行扩展,然后将它们的输出沿通道维连接在一起,以形成的最终输出。它们的三个分支使用卷积层,然后是ReLU层,输出通道数是输入通道数的1/4。最后一个分支使用全局平均池化层来压缩特征,然后使用1x1卷积层和ReLU层将压缩后的特征转换为1/4尺寸(逐通道)的特征。最后,将其调整大小并与其他三个分支的特征进行连接。三个空洞模块的配置:kernel size = [1, 3, 3], atrous rate =[1, 3, 6], padding = [0, 3, 6]。四个分支中的每个分支都产生一个具有输入特征通道数量1/4的通道的特征,将它们连接起来将生成与RFP的输入特征尺寸相同的特征。
4、RFP模块的具体实现

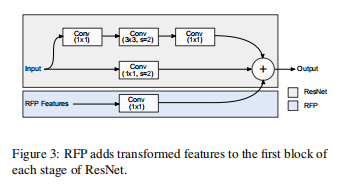
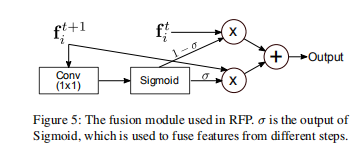
Figure2显示的RFP模块的整体流程, 其中第一次FPN出来的feature map要经过ASPP模块转换之后就是figure3所示的RFP Features,Figure3上方所显示的就是以resnet 为基础bottom up的原始结构,然后和ASPP出来的RFP Features进行相加,这个就是作者提出的RFP模块在融合进Resnet时的具体操作,最后第二次出来的feature map和第一次出来的feature map进行融合时需要根据figure5所示的操作进行,作者提到这是借鉴了RNN。
We make changes to the ResNet [28] backbone B to
allow it to take both x and R(f) as its input. ResNet has four
stages, each of which is composed of several similar blocks.
We only make changes to the first block of each stage, as
shown in Fig. 3. This block computes a 3-layer feature and
adds it to a feature computed by a shortcut. To use the feature
R(f), we add another convolutional layer with the kernel
size set to 1. The weight of this layer is initialized with 0 to
make sure it does not have any real effect when we load the
weights from a pretrained checkpoint.
We use Atrous Spatial Pyramid Pooling (ASPP) [12] to
implement the connecting module R, which takes a feature
f ti as its input and transforms it to the RFP feature used
in Fig. 3. In this module, there are four parallel branches
that take f ti as their inputs, the outputs of which are then
concatenated together along the channel dimension to form
the final output of R. Three branches of them use a convolutional layer followed by a ReLU layer, the number of
the output channels is 1/4 the number of the input channels. The last branch uses a global average pooling layer to
compress the feature, followed by a 1x1 convolutional layer
and a ReLU layer to transform the compressed feature to
a 1/4-size (channel-wise) feature. Finally, it is resized and
concatenated with the features from the other three branches.
5、SAC模块的具体实现

SAC的数学表达式:
 注:开关函数的实现是通过5乘5的卷积核,然后跟一个1乘1卷积层实现的。
注:开关函数的实现是通过5乘5的卷积核,然后跟一个1乘1卷积层实现的。
下面是Figure4图中那个锁的介绍:
We propose a locking mechanism by setting one weight
as w and the other as w + ∆w for the following reasons.
Object detectors usually use pretrained checkpoints to initialize the weights. However, for an SAC layer converted
from a standard convolutional layer, the weight for the larger
atrous rate is missing. Since objects at different scales can
be roughly detected by the same weight with different atrous
rates, it is natural to initialize the missing weights with those
in the pretrained model. Our implementation uses w + ∆w
for the missing weight where w is from the pretrained checkpoint and ∆w is initialized with 0. When fixing ∆w = 0,
we observe a drop of 0.1% AP. But ∆w alone without the
locking mechanism degrades AP a lot.
(1)这个 locking mechanism就是作者提出的将IMAGEnet上的预训练模型与SAC模块相结合,这样就不用将自己的backbone从头开始训练,有可以利用的预训练模型,那些空洞卷积不为1的新加进来的卷积模块权重先暂时用预训练模型里的,但是给他们一个detaW 让他们同时也可以学习。
(2)SAC中锁定机制,通过将一个权重设置为w而另一个权重设置为w +Δw,其原因如下:目标检测器通常使用预训练的checkpoint来初始化权重。但是,对于从标准卷积层转换而来的SAC层,较大的空洞率rate的权重通常是缺失的。由于可以通过相同的权重以不同的粗略度粗略地检测出不同比例的物体,因此用预训练模型中的权重来初始化丢失的权重是可以的。本文使用w + ∆w表示从预训练checkpoint开始的缺失的权重,并使用0初始化∆wi。当固定Δw= 0时,通过实验观察到AP下降了0.1%,但是没有锁定机制的∆w会使AP降低很多。
Figure 4中 Pre-Global Context 的作者的解释:
As shown in Fig. 4, we insert two global context modules
before and after the main component of SAC. These two
modules are light-weighted as the input features are first
compressed by a global average pooling layer. The global
context modules are similar to SENet [31] except for two
major differences: (1) we only have one convolutional layer
without any non-linearity layers, and (2) the output is added
back to the main stream instead of multiplying the input by
a re-calibrating value computed by Sigmoid.
Experimentally, we found that adding the global context information
before the SAC component (i.e., adding global information
to the switch function) has a positive effect on the detection
performance. We speculate that this is because S can make
more stable switching predictions when global information
is available. We then move the global information outside
the switch function and place it before and after the major
body so that both Conv and S can benefit from it. We did
not adopt the original SENet formulation as we found no
improvement on the final model AP. In the ablation study in
Sec. 5, we show the performances of SAC with and without
the global context modules.
6、SAC与条件卷积的区别
SAC可以利用ImageNet上的预训练权重(因为卷积核大小一样,但是空间卷积的rate不一样),并且在空洞卷积前后加入了全局平均池化获取全局信息;有个锁机制,可以将不同rate的空洞卷积的权重关联起来。
Conditional convolutional networks adopt dynamic kernels, widths, or depths, e.g.,
[16,39,43,48,74,77]. Unlike them, our proposed Switchable
Atrous Convolution (SAC) allows an effective conversion
mechanism from standard convolutions to conditional convolutions without changing any pretrained models.
SAC is thus a plug-and-play module for many pretrained backbones.
Moreover, SAC uses global context information and a novel
weight locking mechanism to make it more effective.
7、SAC中的global context与SENet中的不同
These two modules are light-weighted as the input features are first
compressed by a global average pooling layer. The global
context modules are similar to SENet [31] except for two
major differences:
(1) we only have one convolutional layer
without any non-linearity layers, and
(2) the output is added
back to the main stream instead of multiplying the input by
a re-calibrating value computed by Sigmoid.
Experimentally, we found that adding the global context information
before the SAC component (i.e., adding global information
to the switch function) has a positive effect on the detection
performance.
8、 Ablation Studies
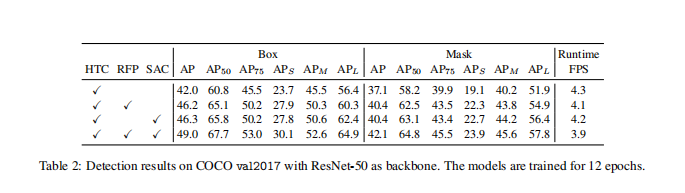

注:DS表示Dual Switch,即两个独立的开关函数,S1(x)和S2(x),而不是S1(x)和1-S1(x)
For RFP, we show ‘RFP + sharing’ where B1i and B2i
share their weights.
9、 State-of-the-art comparison on COCO test-dev

10、SAC和RFP的优势(可视化结果)

Fig. 6 provides visualization of the results by HTC, ‘HTC+ RFP’ and ‘HTC + SAC’.
From this comparison, we notice
that RFP, similar to human visual perception that selectively
enhances or suppresses neuron activations, is able to find
occluded objects more easily for which the nearby context
information is more critical. SAC, because of its ability
to increase the field-of-view as needed, is more capable of
detecting large objects in the images. This is also consistent
with the results of SAC shown in Tab. 2 where it has a higher
APL.
参考文献
1、重磅开源!目标检测新网络 DetectoRS:54.7 AP,特征金字塔与空洞卷积的完美结合
2、详解目标检测新网络 DetectoRS:54.7 AP,特征金字塔与空洞卷积的完美结合
3、实例分割的进阶三级跳:从 Mask R-CNN 到 Hybrid Task Cascade
这篇关于论文阅读:DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








