本文主要是介绍Learning Spatial Fusion for Single-Shot Object Detection--Songtao Liu,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
[1] Liu S , Huang D , Wang Y . Learning Spatial Fusion for Single-Shot Object Detection[J]. 2019.
- 1、介绍
- 2、ASFF的结构
- 2.1、特征同尺寸变换
- 2.2、自适应混合
- 2.3、相容性质
- 3、效果
多尺度特征特别是特征金字塔FPN是解决目标检测中跨尺度目标的最常用有效的解决方法,但是不同特征尺度中存在的不一致性限制了(基于特征金字塔的)single-shot检测器的性能。本文提出一种特征金字塔融合方法ASFF,它自动学习去抑制不同尺度特征在融合时空间上可能存在的冲突信息(即不一致性)。它提高了特征的尺度变性,同时几乎没有增加推理开销。作者在YOLOv3和MS COCO数据集上训练,实现了38.1%的AP(60FPS)、42.4%的AP(45FPS)和43.9%的AP(29FPS)。代码开源在:GOATmessi7/ASFF
Q1:ASFF要解决什么问题?
多尺度特征融合是解决多尺度目标检测的有效方法,像FPN这种多尺度特征牛逼,但是融合时本身存在不同层级的特征之间的冲突信息(即不一致性),导致它们仍有改进的空间。ASFF就是设计来帮助FPN融合时,抑制这种冲突信息(即不一致性),提高FPN的融合效果,进而提高目标检测的效果。
Q2:原理是什么?
看起来就是FPN+空间注意力。首先获取不同层的特征图;然后进行上采样调整为相同shape;根据文中操作生成空间权重(感觉就是空间注意力,只不过这里是注意哪些位置有冲突,然后抑制这个位置),和特征图相乘;最后将多个特征图相加,得到最终的融合效果。
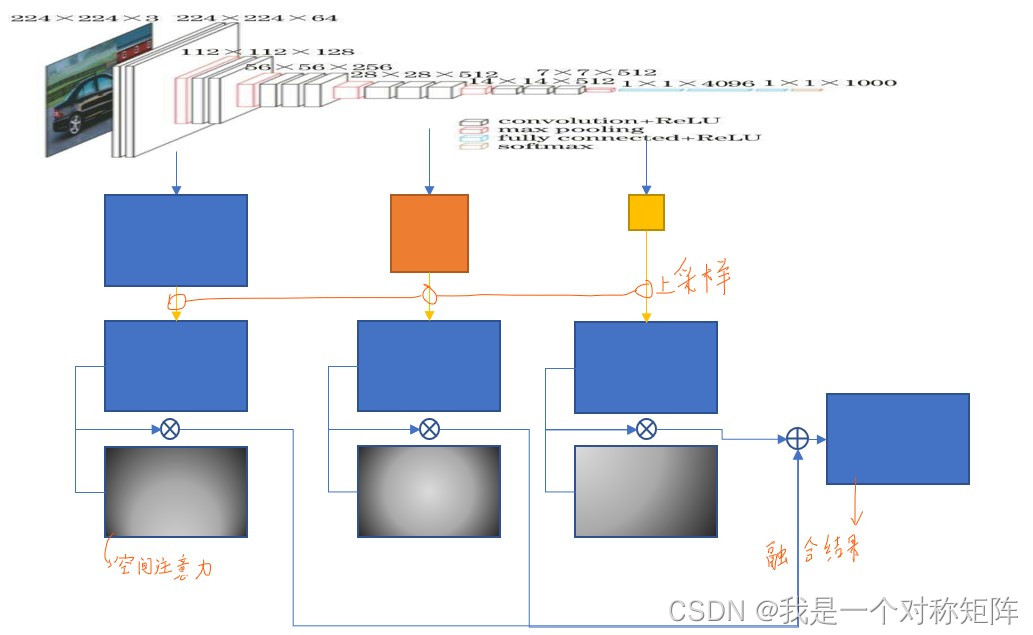
Q3:空间权重是如何计算的?
就是该层特征图经过1*1卷积得到一个通道的特征图,然后再经过归一化后,就是该层的空间权重。
Q4:当我尝试加载分类任务网络中时,效果变差了?
通过分析,我认为ASFF主要是针对小目标检测的效果,所以在目标检测中的效果提升应当是针对小目标检测的效果提升,也就是加了ASFF的提升效果主要来自于小目标检测效果,通过论文中的比较表看出: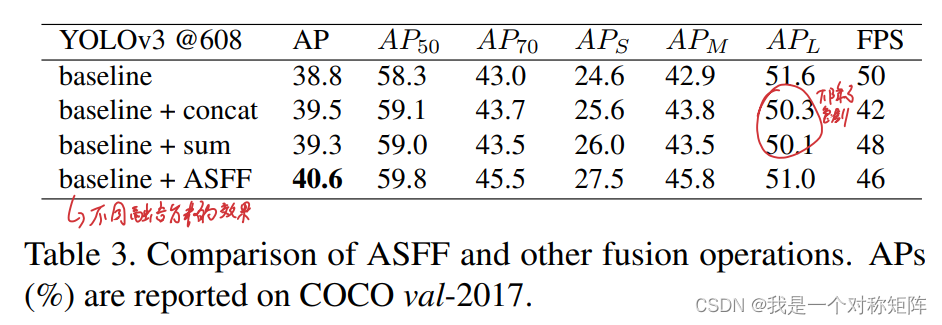
baseline和baseline+ASFF相比:
1)+ASFF在小目标和中目标的效果有提示
2)+ASFF在大目标的效果上下降了
由1)证明了上述的分析,那么2)为什么下降了,个人认为baseline中大目标检测是经过卷积后的高级特征,而+ASFF后,高级特征中含有部分低级特征,相当于baseline中的高级特征占比100%,现在只占比60%,包含了40%的低级特征,这样就损失了对大目标检测的效果。
所以ASFF对小目标和中目标效果友好,但是会随时大目标效果,但是总体效果高。所以如果你的任务不是检测小目标任务的话,建议不要使用ASFF,因为反而负优化。
1、介绍
首先说明了跨尺度的物体对象检测仍然是一个挑战,然后图中大尺度对象和小尺度对象确实不好同时处理,但是特征金字塔是缓解这个挑战的使用方法,很多SOTA都在多级特征塔中使用了特征金字塔。
- SSD
SSD是最先尝试卷积金字塔特征的一批方法。它重用来自不同卷积层的多尺度特征图来预测不同尺寸的物体。但是这种自底向上的方法存在问题:检测小物体的精确性很低。
如图小物体很多信息在左侧底层卷积的特征图,但是底层的卷积特征图还是不够充分的语义信息(还不够抽象),而具有充分语句信息是在高层卷积(右侧),右侧的卷积特征更多是大物体的信息。所以SSD中小目标信息来源是底层特征,这样虽然对检测小目标检测有帮助,但是不够大。
如果想要从底层特征再次卷积提取抽象充分的语义信息,那岂不是和主干网络一样,卷积到右侧又只剩下大物体的信息了。
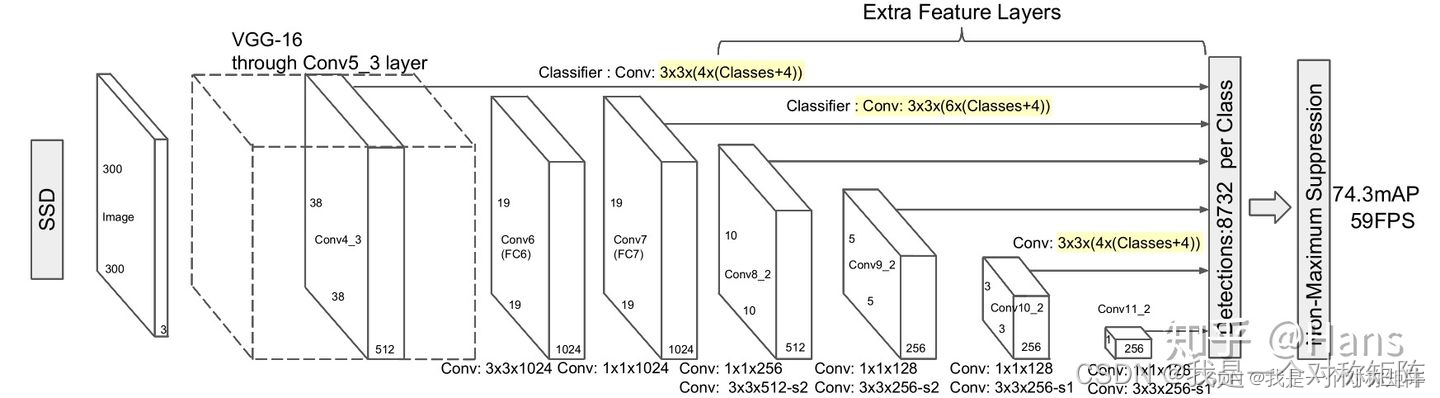
- FPN
【预习FPN:特征金字塔:FPN(Feature Pyramid Networks)】
为了解决SSD的缺点,特征金字塔(Feature Pyramid Network ,FPN)被提出来了。FPN自顶向下按顺序融合相邻两个被抽取的特征图(左侧)
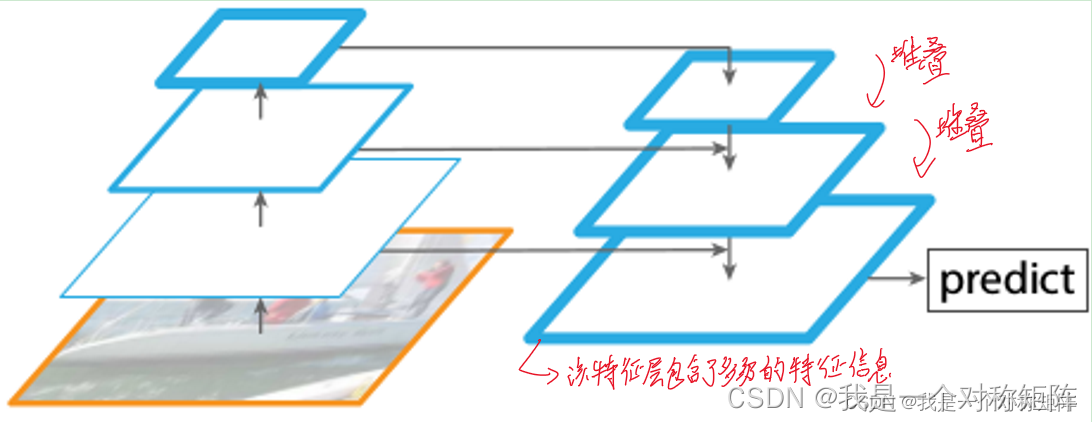
【随着卷积运算,特征图的语义信息更强,但是尺寸更小,分辨率更低】
低分辨率的特征图有着很强的语义信息,在融合时会上采样改变shape,然后和比它分辨率高但语义信息稍弱的邻层融合。因为将强语义信息层不断融合,这样在所有层都可以共享到强语义信息。
FPN和其他相似的自顶向下的结构都同样简单高效,到那时他们仍还有提升的空间。
(然后文中介绍了一些其他人解决不一致性的工作)
相比较于图像金字塔,FPN的主要缺点就是在跨不同尺度特征存在的不一致性(特征金字塔中,不同尺度的特征差异较大),尤其是在single-shot检测器。
具体来讲,当使用特征金字塔检测物体时,会采用启发式引导的特征选择:大物体会和上面的特征图(高层特征)关联,小物体回合底层特征图关联。当一个物体在某个特征图中位置被确认为positive时,在其他特征图中该位置可能会被认为是背景。因此一副图像包含了大小物体时,在不同特征图的冲突(一会儿是positive一会儿是背景)往往会占据特征金字塔的主要部分(FPN融合包含的信息应当共同为网络性能出力,但是现在大量冲突信息充斥其中,造成FPN的性能瓶颈)。这种不一致性会干涉梯度计算,降低FPN的效率。
在这篇paper中,我们提出了adaptively spatial feature fusion (ASFF),用以解决这种不一致性。ASFF会学习一个空间滤波权重(空间注意力矩阵),在融合时仅仅保留有用位置的信息,抑制冲突位置的信息。
ASFF的优势:1)在反向传播中很方便学习;2)这个ASFF对于主干网络是不可知的,即不影响主干网络(方便即插即用?);3)它应用起来方便,增加的计算成本是微不足道的。
2、ASFF的结构
不同于其他通过采样后element-wise sum或者concat直接融合,ASFF的关键点是去自适应为特征图的每个尺度学习一个空间权重。如下图所示,它包含了两步:同尺寸变换和自适应融合。
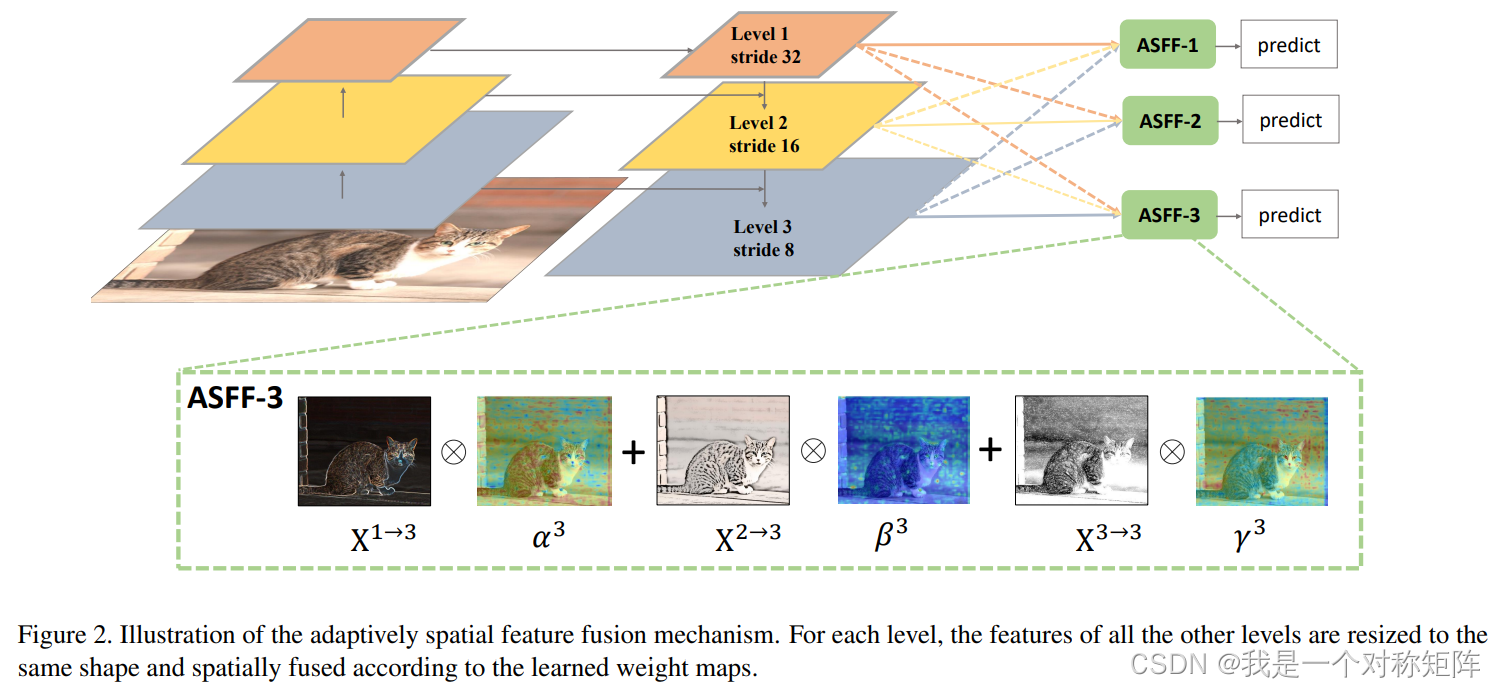
2.1、特征同尺寸变换
不同层的特征图shape不一样,所以无论什么融合方式都需要resize到相同的尺寸。如图要你选择在level 1融合,则level 2和level 3要变换尺寸和level 1的尺寸一样,当然你还可以选择在level 2或level 3融合。在这里有两种情况:情况一是小尺寸变大尺寸,情况二是大尺寸变小尺寸。
首先你需要清楚:小尺寸代表高层特征,通道数多,大尺寸代表底层特征,通道数少。
小尺寸变大尺寸(上采样):首先使用1*1卷积去压缩通道数,然后通过插值法将尺寸变换到目标层的尺寸,这样通道数和尺寸都和目标层一样了。
大尺寸变小尺寸(下采样):
- 1/2倍:通过stride=2的3*3卷积操作,同时改变了通道数和1/2的尺寸下采样
- 1/4倍:通过stride=2的max pooling+stride=2的3*3卷积操作,同时改变了通道数和1/4的尺寸下采样
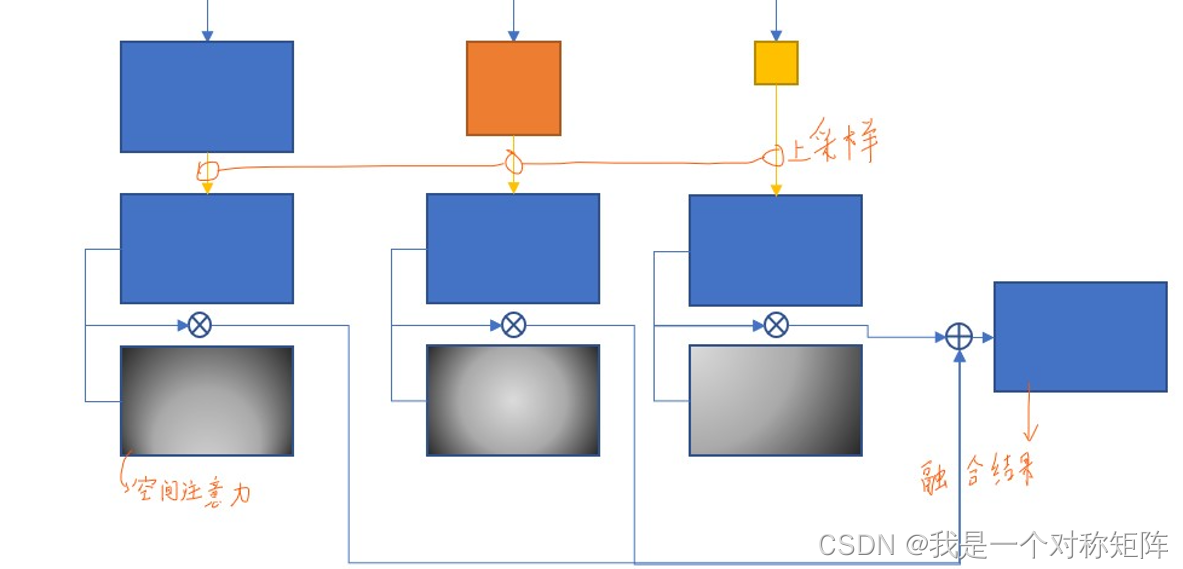
2.2、自适应混合
这个其实没什么好讲的,大致就是如下图
公式如下图,
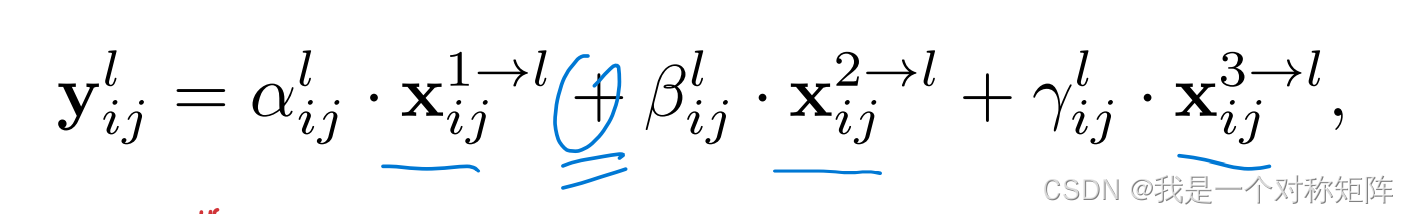
α,β,γ:权重值
X i j i → l X^{i→l}_{ij} Xiji→l:表示resize到相同大小后的特征图了,三个x的[channels,w,h]一样
公示的意思就是不同特征图的位置和各自位置上的权重相乘,然后3个结果相加,就得到融合后该位置的值。
现在重点讲讲空间位置权重是怎么计算的
这个权重是训练时学习到的,计算方式是对三个 X i j i → l X^{i→l}_{ij} Xiji→l进行1*1的卷积,就产生3个单通道的特征图,这就是3个初始空间权重信息矩阵,记为三个λ。
在位置 i j ij ij上的权重还要经过如下公式处理,即三个权重图相同位置的权重之和=1,且都∈[0,1]
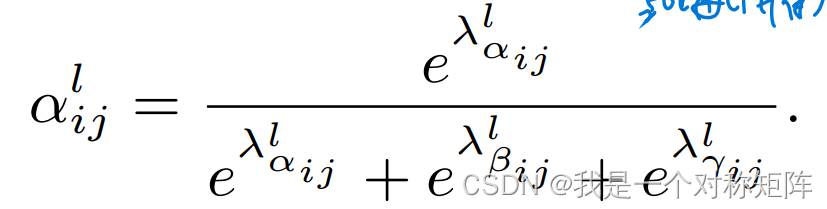
最终权重图变成下面公式的样子: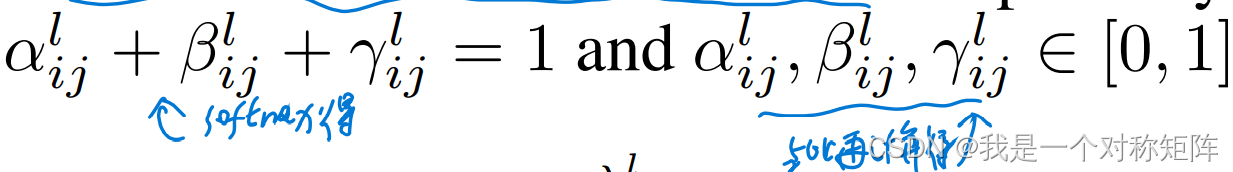
α,β,γ就是真正的权重值。
2.3、相容性质
数学证明,详见论文。
3、效果

上图展示在不同level层融合时,三个层级的空间权重(右侧是融合后效果)。
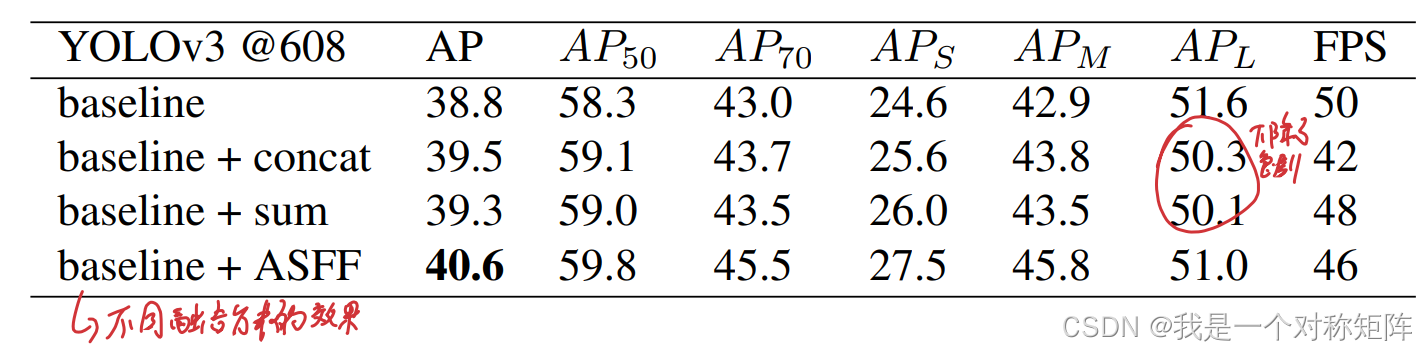
更详细的评价见论文
这篇关于Learning Spatial Fusion for Single-Shot Object Detection--Songtao Liu的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








