本文主要是介绍利用python实现激光雷达LAS数据滤波的7种方式,使用laspy读写,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
激光雷达(LiDAR)数据在实际应用中可能受到噪声和不完美的测量影响,因此数据去噪和滤波方法变得至关重要,以提高数据质量和准确性。以下是一些常用的激光雷达数据去噪与滤波方法。
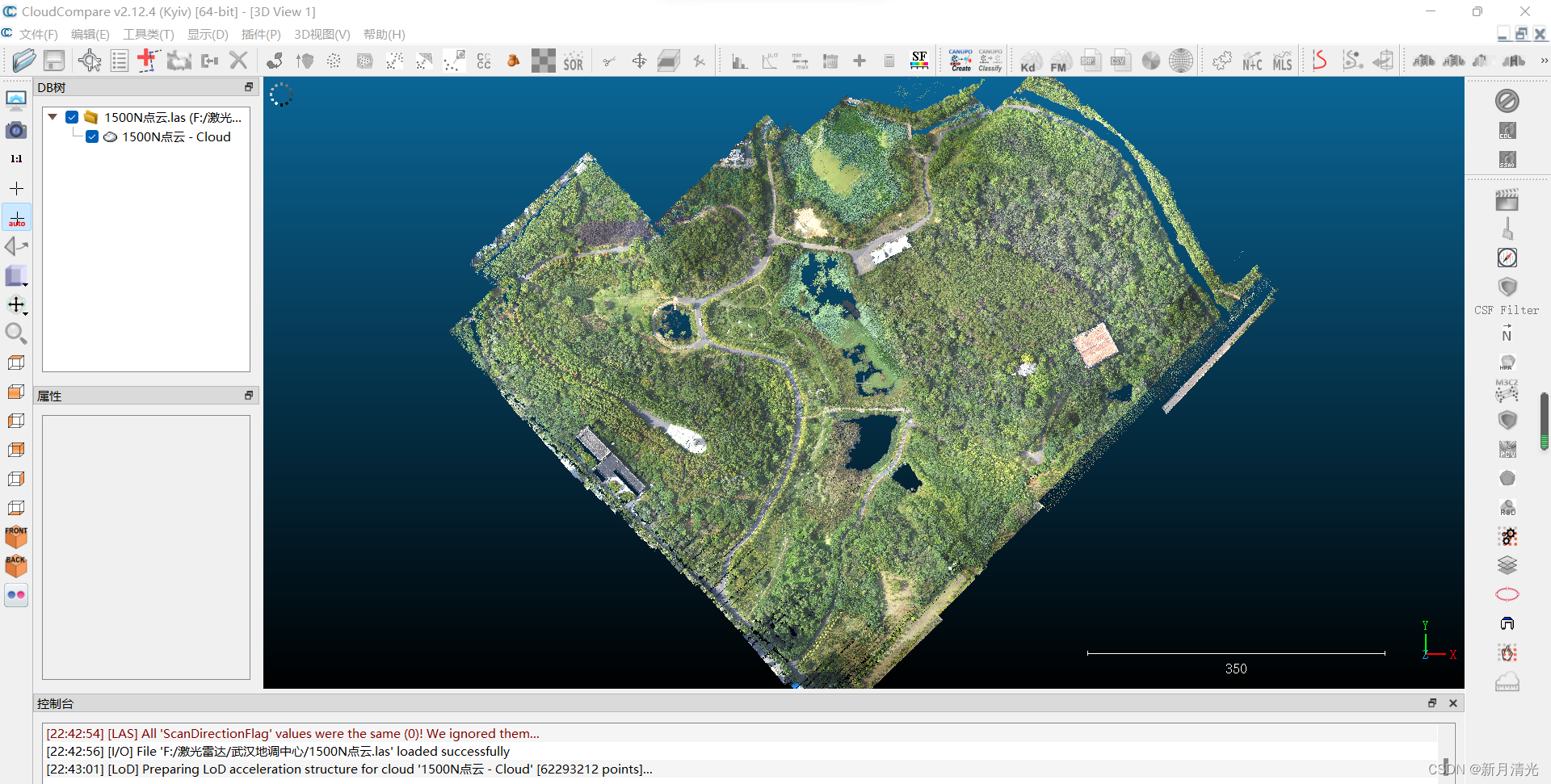
原始数据如下:
1. 移动平均滤波(Moving Average Filter):
移动平均滤波是一种简单的滤波方法,通过计算数据点周围一定范围内数据的平均值来平滑数据。这种方法适用于去除高频噪声,但可能会导致边缘信息模糊。
代码:
import laspy
import numpy as np
from scipy.signal import medfilt
from skimage.metrics import structural_similarity as ssim# 读取LAS文件
in_file_path = 'F:/激光雷达/武汉地调中心/1500N点云.las'
out_file_path_ma = 'F:/激光雷达/武汉地调中心/output_moving_average.las'in_las = laspy.file.File(in_file_path, mode='r')# 提取点云数据
x = in_las.x
y = in_las.y
z = in_las.z# 应用移动平均滤波
window_size = 5
filtered_z_ma = np.convolve(z, np.ones(window_size)/window_size, mode='same')# 创建新的LAS文件并保存滤波后数据
out_las_ma = laspy.file.File(out_file_path_ma, mode='w', header=in_las.header)
out_las_ma.x = x
out_las_ma.y = y
out_las_ma.z = filtered_z_ma
out_las_ma.close()2. 中值滤波(Median Filter):
中值滤波是一种非线性滤波方法,将数据点周围的值按大小排序,然后取中间值作为滤波结果。中值滤波能够有效去除脉冲噪声和异常值,但可能会降低数据的细节。
代码:
import laspy
import numpy as np
from scipy.signal import medfilt
from skimage.metrics import structural_similarity as ssim# 读取LAS文件
in_file_path = 'F:/激光雷达/武汉地调中心/1500N点云.las'
out_file_path_med = 'F:/激光雷达/武汉地调中心/output_median.las'in_las = laspy.file.File(in_file_path, mode='r')# 提取点云数据
x = in_las.x
y = in_las.y
z = in_las.z# 应用中值滤波
window_size_med = 3
filtered_z_med = medfilt(z, kernel_size=window_size_med)# 创建新的LAS文件并保存滤波后数据
out_las_med = laspy.file.File(out_file_path_med, mode='w', header=in_las.header)
out_las_med.x = x
out_las_med.y = y
out_las_med.z = filtered_z_med
out_las_med.close()3. 加权移动平均滤波(Weighted Moving Average Filter):
加权移动平均滤波将不同位置的数据点赋予不同的权重,根据权重计算加权平均值。这种方法可以根据数据分布的特点更好地平衡平滑和保留细节。
代码:
import laspy
import numpy as np
from scipy.signal import medfilt
from skimage.metrics import structural_similarity as ssim# 读取LAS文件
in_file_path = 'F:/激光雷达/武汉地调中心/1500N点云.las'
out_file_path_weighted_ma = 'F:/激光雷达/武汉地调中心/output_weighted_moving_average.las'in_las = laspy.file.File(in_file_path, mode='r')# 提取点云数据
x = in_las.x
y = in_las.y
z = in_las.z# 应用加权移动平均滤波
window_size = 5
weights = np.arange(1, window_size + 1).astype(float) # 转换为浮点数类型
weights /= np.sum(weights)
filtered_z_weighted_ma = np.convolve(z, weights, mode='same')# 创建新的LAS文件并保存滤波后数据
out_las_weighted_ma = laspy.file.File(out_file_path_weighted_ma, mode='w', header=in_las.header)
out_las_weighted_ma.x = x
out_las_weighted_ma.y = y
out_las_weighted_ma.z = filtered_z_weighted_ma
out_las_weighted_ma.close()4. 高斯滤波(Gaussian Filter):
高斯滤波基于高斯函数对数据进行平滑处理。它可以保留细节的同时有效地去除噪声,适用于光滑信号。
代码:
import laspy
import numpy as np
from scipy.ndimage import gaussian_filter1d
from skimage.metrics import structural_similarity as ssim# 读取LAS文件
in_file_path = 'F:/激光雷达/武汉地调中心/1500N点云.las'
out_file_path_gaussian = 'F:/激光雷达/武汉地调中心/output_gaussian.las'in_las = laspy.file.File(in_file_path, mode='r')# 提取点云数据
x = in_las.x
y = in_las.y
z = in_las.z# 应用高斯滤波
sigma = 1.0 # 高斯核标准差
filtered_z_gaussian = gaussian_filter1d(z, sigma=sigma)# 创建新的LAS文件并保存滤波后数据
out_las_gaussian = laspy.file.File(out_file_path_gaussian, mode='w', header=in_las.header)
out_las_gaussian.x = x
out_las_gaussian.y = y
out_las_gaussian.z = filtered_z_gaussian
out_las_gaussian.close()5. 波形去除滤波(Waveform Removal Filter):
这种滤波方法主要用于去除激光雷达回波中的地面信号,以便更好地检测障碍物。该方法需要先对地面进行建模,然后将地面信号从数据中减去。
代码:
import laspy
import numpy as np
from scipy.signal import detrend
from skimage.metrics import structural_similarity as ssim# 读取LAS文件
in_file_path = 'F:/激光雷达/武汉地调中心/1500N点云.las'
out_file_path_waveform_removal = 'F:/激光雷达/武汉地调中心/output_waveform_removal.las'in_las = laspy.file.File(in_file_path, mode='r')# 提取点云数据
x = in_las.x
y = in_las.y
z = in_las.z# 应用波形去除滤波
filtered_z_waveform_removal = detrend(z)# 创建新的LAS文件并保存滤波后数据
out_las_waveform_removal = laspy.file.File(out_file_path_waveform_removal, mode='w', header=in_las.header)
out_las_waveform_removal.x = x
out_las_waveform_removal.y = y
out_las_waveform_removal.z = filtered_z_waveform_removal
out_las_waveform_removal.close()6. 自适应滤波(Adaptive Filtering):
自适应滤波方法根据数据点的局部特征动态调整滤波参数。例如,自适应中值滤波根据数据分布的变化调整滤波窗口的大小,以平衡噪声去除和细节保留。
代码:
import laspy
import numpy as np
from scipy.signal import wiener
from skimage.metrics import structural_similarity as ssim# 读取LAS文件
in_file_path = 'F:/激光雷达/武汉地调中心/1500N点云.las'
out_file_path_adaptive = 'F:/激光雷达/武汉地调中心/output_adaptive.las'in_las = laspy.file.File(in_file_path, mode='r')# 提取点云数据
x = in_las.x
y = in_las.y
z = in_las.z# 应用自适应滤波
try:filtered_z_adaptive = wiener(z)
except (ValueError, ZeroDivisionError):# 处理除以零或无效值的情况filtered_z_adaptive = z # 可以选择保持原始数据,或者使用其他滤波方法来代替# 创建新的LAS文件并保存滤波后数据
out_las_adaptive = laspy.file.File(out_file_path_adaptive, mode='w', header=in_las.header)
out_las_adaptive.x = x
out_las_adaptive.y = y
out_las_adaptive.z = filtered_z_adaptive
out_las_adaptive.close()7. 小波变换滤波(Wavelet Transform Filter):
小波变换滤波可以将信号分解成不同频率的子信号,然后根据需要去除高频噪声,再将信号重构回去。这种方法在处理包含多尺度信息的数据时非常有用。
代码:
import laspy
import numpy as np
import pywt
from skimage.metrics import structural_similarity as ssim# 读取LAS文件
in_file_path = 'F:/激光雷达/武汉地调中心/1500N点云.las'
out_file_path_wavelet = 'F:/激光雷达/武汉地调中心/output_wavelet.las'in_las = laspy.file.File(in_file_path, mode='r')# 提取点云数据
x = in_las.x
y = in_las.y
z = in_las.z# 应用小波变换滤波
wavelet_name = 'db4' # 小波基函数的名称
level = 2 # 分解的级别
coeffs = pywt.wavedec(z, wavelet_name, level=level)
coeffs[1:] = [pywt.threshold(coeff, value=0.5, mode='soft') for coeff in coeffs[1:]] # 对细节系数进行软阈值处理
filtered_z_wavelet = pywt.waverec(coeffs, wavelet_name)# 创建新的LAS文件并保存滤波后数据
out_las_wavelet = laspy.file.File(out_file_path_wavelet, mode='w', header=in_las.header)
out_las_wavelet.x = x
out_las_wavelet.y = y
out_las_wavelet.z = filtered_z_wavelet
out_las_wavelet.close()对比结果发现,误差指标显示,自适应滤波(Adaptive Filtering)和小波变换滤波(Wavelet Transform Filter)处理效果较好,其中后者最佳。
这篇关于利用python实现激光雷达LAS数据滤波的7种方式,使用laspy读写的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





