本文主要是介绍CausalVAE: Disentangled Representation Learning via Neural Structural Causal Models,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
这篇论文我觉得最大的贡献是把因果关系、因果模型引入到解耦表征领域,使得解耦的潜变量z具有可解释性;对z加一个的扰动可以反映到VAE网络生成图像的对应物理量上。
贡献:1)我们提出了一个新的框架CausalVAE,支持因果分离和do-operation;2) 给出了模型可辨识性的理论证明;3)我们对合成的和真实的人脸图像进行了综合实验,以证明所学习的因素具有因果语义,并且可以被干预以生成不出现在训练数据中的反事实图像。
实验
以钟摆实验为例说明:
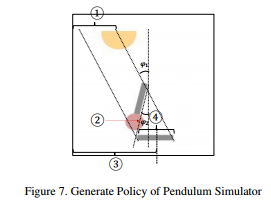
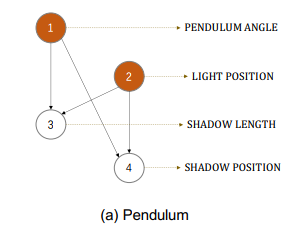
上左图为训练的钟摆图像,它包含4个因素:1光源位置、2摆钟角度、3影子位置、4影子长度,上右图对应其因果关系图,即1、2为因,3、4为果,那么就希望网络如果调整1、2对应的latent code可以影响到3、4,反之则不行。
看一下实验效果:
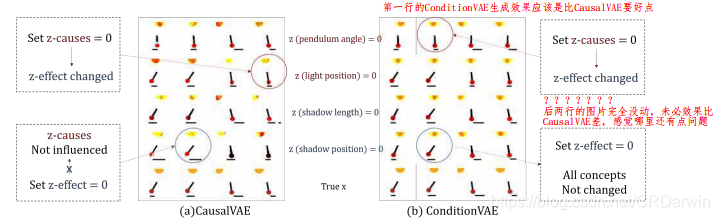
a为CausalVAE,b为ConditionVAE,前4行分别设置1、2、3、4对应的 z i z_i zi,为生成图像,最后一行为输入原始图像。CausalVAE的优势主要体现在后两行,论文也讲ConditionVAE可以看作消融版本。这个效果可能光源太大?看着有点不舒服,不过效果还是有的。
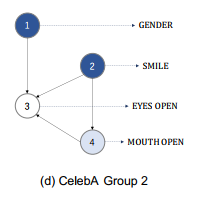
CelebA数据集效果图:

其对应的因果结构图如下,解读就不解读了,跟上面一样:
其后对A可视化出来效果,这是CelebA数据集的,颜色由浅到深从0到1,可以看到A的改变过程逐渐接近真实的A(这里可能需要看完全文再回过来再看):

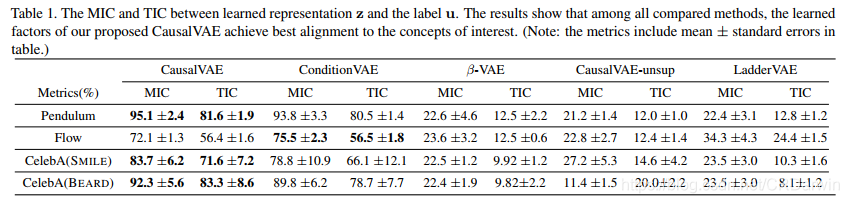
另外还有两个指标MIC和TIC:
网络结构图:
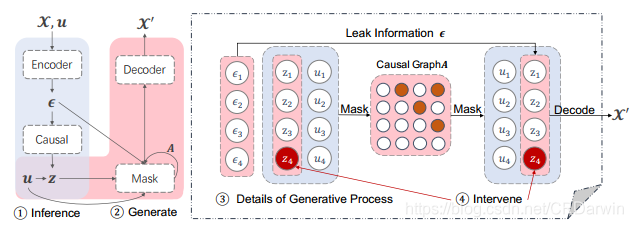
可以看作在VAE的隐变量空间嵌入了因果结构模型,就 ϵ \epsilon ϵ 、 z z z 、 A A A围住的三角形这里,把隐变量解耦再用decoder生成图像。emmm…也不严谨。
causal layer
作者在论文中也讲到,这部分的思想主要就是借鉴Shohei Shimizu, Patrik O Hoyer.A linear non-gaussian acyclic model for causal discovery, 2006.这篇文章,这个模型简称:线性非高斯无环模型(LiNGAM),该模型基于 SEM (Structural Equation Modeling)的因果模型,查阅资料就会发现SEM在金融、管理、社科等领域用的非常多,所以如下图这样的模型很常见,它就是建立各个因素之间的因果关系。
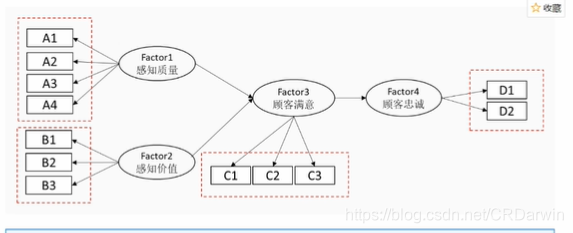
LiNGAM 对系统的数据生成方式做了线性假设和非高斯独立噪声的假设,并利用独立成分分析(ICA,independent component analysis)进行求解。线性非高斯无环模型要求三个基本的前提条件:
- 观测变量之间是存在因果顺序的,后续变量不会导致前序变量;这些变量可以用一个DAG(有向无环图)表示。
- 变量间的因果关系是线性的,可以用如下公式描述: x i = ∑ k ( j ) < k ( i ) b i , j x j + e i + c i x_i = \sum_{k(j)<k(i)} b_{i,j}x_j+e_i+c_i xi=k(j)<k(i)∑bi,jxj+ei+ci
- 扰动项e服从方差非零的非高斯分布,且互相独立。
当然这些是LiNGAM为求解矩阵 B B B的前提条件。上述公式可化简为: X = B X + e X=BX+e X=BX+e 即 z = A T z + e z=A^Tz+e z=ATz+e, 移项合并后 z = ( I − A T ) − 1 ϵ z=(I-A^T)^{-1} \epsilon z=(I−AT)−1ϵ。
ϵ \epsilon ϵ在论文中叫做独立高斯外生因子,它就对应网络结构图中的 ϵ \epsilon ϵ,由编码器生成,causal layer的作用是对 ϵ \epsilon ϵ施加线性变化,即乘 ( I − A T ) − 1 (I-A^T)^{-1} (I−AT)−1,得到内生变量 z z z。
mask layer
这部分作用是:模拟因果图中父节点的影响向子节点传递,同时这是由于这部分存在使得我们可以执行"do-operation"操作,控制图像的生成,以及生成一些counterfactual反事实的图像。
由于无监督的学习方式学出来的因果图不能保证因果图的identifiability可识别性,简单讲就是两个不同的联合分布 p θ ( x , z ) p_\theta(x,z) pθ(x,z), p θ ′ ( x , z ) p_ {\theta'}(x,z) pθ′(x,z)但是却对应着同一个边际分布 p ( x ) p(x) p(x), 或者可以理解为相同的观测变量下对应不同的因果图,这肯定不对了。这就identifiability的问题。
因此要引入额外的监督信号 u u u。在论文IVAE中的作法是给潜变量z加条件 p θ ( z ∣ u ) p_\theta(z|u) pθ(z∣u),u是一个额外观察到的变量,给定条件变量 u ,每个隐变量 z i ⊆ z z_i\subseteq z zi⊆z是条件独立的单变量指数分布族。即下式: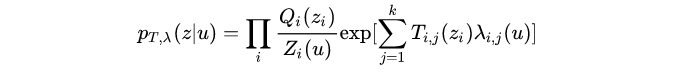
在CausalVAE中u就是label,它是[4,1]size的vector。如论文所述:
“In our work, we use the labels of the concepts. The additional information u is utilized in two ways. Firstly, we propose a conditional prior p(z|u) to regularize the learned posterior of z. This guarantees that the learned model belongs to an identifiable family. Secondly, we also leverage u to learn the causal structure A.”
根据文中mask layer的表达式: z i = g i ( A i ∘ z ; η i ) + ϵ i z_i=g_i(A_i\circ z;\eta_i)+\epsilon_i zi=gi(Ai∘z;ηi)+ϵi,可以看出这部分跟causal layer有点像,只是把线性变为非线性,作者说效果会更好。代码实现上causal layer层输出的z在这里乘A,之后过一个神经网络拟合的非线性函数 g i g_i gi,再加 ϵ i \epsilon_i ϵi,最后输出 z i z_i zi进decoder还原原图像。但是这个 ϵ i \epsilon_i ϵi好复杂?跟论文好像不一样

"do-operation"操作是对causal layer层输出z操作,对它的影响会传递到mask layer层输出的z;生成反事实图像是在此基础上再控制mask layer层的z不变。
损失函数方面:
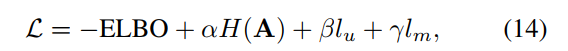
其中,ELBO如下,从VAE那来的,作者又做了改进并推导了置信下届。保证重构图像和原图尽可能像:
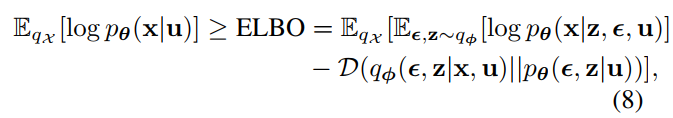
H ( A ) H(A) H(A)如下,与NOTEARS差不多,保证学出来的A是一个DAG。
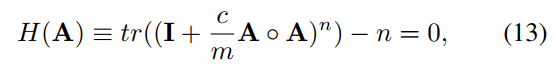
l u l_u lu和 l m l_m lm是对u和z的约束,和NOTEARS损失函数相似,都是保证A是DAG。
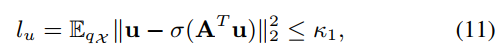

其实可以发现,CausalVAE的几篇重要参考文献其实都是讲的那么些东西,在前人的基础上做一点改进,大方向是没有变的,他们解决的问题都是:有一堆观测数据𝑋∈ℝ𝑛×𝑑,X∈R,n×d, 如何通过这些数据推测其(特征之间的)关系, 即对应的𝐴,拿到这个𝐴就得到对应的因果关系图。比如DAGs with NO TEARS是把DAG的复杂组合优化问题转化为连续最大化问题,这应该是不小的突破;Masked Gradient-Based Causal Structure Learning这篇又把它拓展到非线性的情况。以及DAGs with NO TEARS、DAG_GNN等都是因果关系图的改进及向其他领域的应用。
更理论的数学推导可能需要看看原文3.3. A Probabilistic Generative Model for CausalVAE和4.learn strategy;其他的帖子如CausalVAE
不足或疑问
我觉得对于每一维隐变量 z i z_i zi真的就能对应到实际的一个物理因素还表示怀疑,尽管作者讲了可以;其次论文中实验 z z z的维度是4,现实中肯定不只4,那多少合适?
参考资料
非时序线性非高斯模型 —— LiNGAM
以因果为先验的解耦表示|生成模型——CausalVAE及其扩展
贝叶斯网络简要概述
反事实推理:Causality 基础概念汇总
DAGs with NO TEARS: Continuous Optimization for Structure Learning
DAG_GNN:一种基于VAE的DAG结构学习架构
有两个博主应该是相关方向,这一系列论文都有介绍:馒头and花卷,学术农工
关于CausalVAE讲得比较理论一点的文章:CausalVAE,以因果为先验的解耦表示|生成模型——CausalVAE及其扩展
论文作者B站讲解视频
codes
文章主要讲我自己对论文的理解以及对读论文时查阅资料的整理,会不断补充和更新,欢迎来信探讨。
这篇关于CausalVAE: Disentangled Representation Learning via Neural Structural Causal Models的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)