本文主要是介绍mysql 性能优化方法汇总,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0、加索引
索引建立规则:
索引的字段必须是经常作为查询条件的字段;
如果索引多个字段,第一个字段要是经常作为查询条件的。如果只有第二个字段作为查询条件,这个索引不会起到作用;
索引的字段必须有足够的区分度;
Mysql 对于长字段支持前缀索引;1、当只要一行数据时使用 LIMIT 1
当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。
在这种情况下,加上 LIMIT 1 可以增加性能。这样一样,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
下面的示例,只是为了找一下是否有“中国”的用户,很明显,后面的会比前面的更有效率。(请注意,第一条中是Select *,第二条是Select 1)
//没有效率的:
$r = mysql_query("SELECT * FROM user WHERE country = 'China'");
if (mysql_num_rows($r) > 0) {//...
}
// 有效率的:
$r = mysql_query("SELECT 1 FROM user WHERE country = 'China' LIMIT 1");
if (mysql_num_rows($r) > 0) {//...
}2、 千万不要 ORDER BY RAND()
想打乱返回的数据行?随机挑一个数据?真不知道谁发明了这种用法,但很多新手很喜欢这样用。但你确不了解这样做有多么可怕的性能问题。
如果你真的想把返回的数据行打乱了,你有N种方法可以达到这个目的。这样使用只让你的数据库的性能呈指数级的下降。这里的问题是:MySQL会不得 不去执行RAND()函数(很耗CPU时间),而且这是为了每一行记录去记行,然后再对其排序。就算是你用了Limit 1也无济于事(因为要排序)
下面的示例是随机挑一条记录
// 千万不要这样做:
$r = mysql_query("SELECT username FROM user ORDER BY RAND() LIMIT 1");// 这要会更好:
$r = mysql_query("SELECT count(*) FROM user");
$d = mysql_fetch_row($r);
$rand = mt_rand(0,$d[0] - 1);
$r = mysql_query("SELECT username FROM user LIMIT $rand, 1");3、 避免 SELECT *
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。
所以,你应该养成一个需要什么就取什么的好的习惯。
// 不推荐
$r = mysql_query("SELECT * FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";
// 推荐
$r = mysql_query("SELECT username FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";4、永远为每张表设置一个ID
我们应该为数据库里的每张表都设置一个ID做为其主键,而且最好的是一个INT型的(推荐使用UNSIGNED),并设置上自动增加的AUTO_INCREMENT标志。
就算是你 users 表有一个主键叫 “email”的字段,你也别让它成为主键。使用 VARCHAR 类型来当主键会使用得性能下降。另外,在你的程序中,你应该使用表的ID来构造你的数据结构。
而且,在MySQL数据引擎下,还有一些操作需要使用主键,在这些情况下,主键的性能和设置变得非常重要,比如,集群,分区……
在这里,只有一个情况是例外,那就是“关联表”的“外键”,也就是说,这个表的主键,通过若干个别的表的主键构成。我们把这个情况叫做“外键”。比 如:有一个“学生表”有学生的ID,有一个“课程表”有课程ID,那么,“成绩表”就是“关联表”了,其关联了学生表和课程表,在成绩表中,学生ID和课 程ID叫“外键”其共同组成主键。
5、尽可能的使用 NOT NULL
除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL。这看起来好像有点争议,请往下看。
首先,问问你自己“Empty”和“NULL”有多大的区别(如果是INT,那就是0和NULL)?如果你觉得它们之间没有什么区别,那么你就不要使用NULL。(你知道吗?在 Oracle 里,NULL 和 Empty 的字符串是一样的!)
不要以为 NULL 不需要空间,其需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用NULL值。
下面摘自MySQL自己的文档:
“NULL columns require additional space in the row to record whether their values are NULL. For MyISAM tables, each NULL column takes one bit extra, rounded up to the nearest byte.”
6、选择正确的存储引擎
在 MySQL 中有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。酷壳以前文章《MySQL: InnoDB 还是 MyISAM?》讨论和这个事情。
MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都 无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
下面是MySQL的手册
target=”_blank”MyISAM Storage Engine
InnoDB Storage Engine
7、对表进行水平划分
如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了。如果我拆成100个表,那么每个表只有10万条记录。当然这 需要数据在逻辑上可以划分。一个好的划分依据,有利于程序的简单实现,也可以充分利用水平分表的优势。比如系统界面上只提供按月查询的功能,那么把表按月 拆分成12个,每个查询只查询一个表就够了。如果非要按照地域来分,即使把表拆的再小,查询还是要联合所有表来查,还不如不拆了。所以一个好的拆分依据是 最重要的。
水平分表,能够降低单表的数据量,一定程度上可以缓解查询性能瓶颈。但本质上这些表还保存在同一个库中,所以库级别还是会有IO瓶颈。所以,一般不建议采用这种做法。
8、对表进行垂直划分
有些表记录数并不多,可能也就2、3万条,但是字段却很长,表占用空间很大,检索表时需要执行大量I/O,严重降低了性能。这个时候需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。(降低了每张表的文件大小)
实例:文章信息表就可以拆分成两张表,一张记录文章信息如作者、栏目、发表日期、关键词等,另一张表记录 文章内容,摘要等。利用id进行对应。因为在大多数情况下只需要搜索第一张表即可,只有在文章展示页才需要访问两张表,如此可以提高搜索性能!
9、mysql主从同步,读写分离
详见:
http://blog.csdn.net/u013372487/article/details/51658692
10、使用INNER JOIN 而不是WHERE来创建连接(多表查询)
一些SQL开发人员更喜欢使用WHERE来做join,比如:
SELECT Customers.CustomerID, Customers.Name, Sales.LastSaleDate
FROM Customers, Sales WHERE Customers.CustomerID = Sales.CustomerID这个类型where实际上创建时笛卡尔连接。 在笛卡尔连接中,所有可能的组合都会被创建出来。在上面的例子中,如果有1000顾客和1000条销售记录,这个查询会先产生1000000个结果,然后通过正确的 CustomerID过滤出1000条记录。 这是一种低效利用数据库资源,数据库多做100倍的工作。 在大型数据库中,笛卡尔连接是一个大问题,对两个大表的笛卡尔积会创建数10亿或万亿的记录。
为了避免创建笛卡尔积,应该使用INNER JOIN :
SELECT Customers.CustomerID, Customers.Name, Sales.LastSaleDate
FROM Customers INNER JOIN Sales ON Customers.CustomerID = Sales.CustomerID这样数据库就只产生等于CustomerID 的1000条目标结果。
有些数据库系统会识别出 WHERE连接并自动转换为 INNER JOIN。在这些数据库系统中,WHERE 连接与INNER JOIN 就没有性能差异。但是, INNER JOIN 是所有数据库都能识别的,因此DBA会建议在你的环境中使用它。
11、水平分库分表
平分库分表与上面讲到的水平分表的思想相同,唯一不同的就是将这些拆分出来的表保存在不同的数据中。这也是很多大型互联网公司所选择的做法。如下图:

某种意义上来讲,有些系统中使用的“冷热数据分离”(将一些使用较少的历史数据迁移到其他的数据库中。而在业务功能上,通常默认只提供热点数据的查询),也是类似的实践。在高并发和海量数据的场景下,分库分表能够有效缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源的瓶颈。当然,投入的硬件成本也会更高。同时,这也会带来一些复杂的技术问题和挑战(例如:跨分片的复杂查询,跨分片事务等)
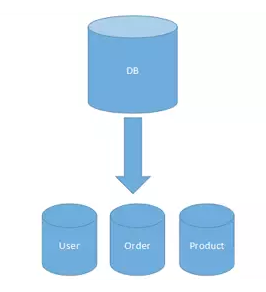
12、垂直分库
垂直分库在“微服务”盛行的今天已经非常普及了。基本的思路就是按照业务模块来划分出不同的数据库,而不是像早期一样将所有的数据表都放到同一个数据库中。如下图:
这篇关于mysql 性能优化方法汇总的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







