本文主要是介绍AI超强语音转文本SenseVoice,本地化部署教程!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 模型介绍
- SenseVoice在线预览链接
- 本地化部署
- VsCode 远程连接
模型介绍
SenseVoice专注于高精度多语言语音识别、情感辨识和音频事件检测
- 多语言识别: 采用超过40万小时数据训练,支持超过50种语言,识别效果上优于Whisper模型。
- 富文本识别:
- 具备优秀的情感识别,能够在测试数据上达到和超过目前最佳情感识别模型的效果。
- 支持声音事件检测能力,支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件进行检测。
- 高效推理:
SenseVoice-Small模型采用非自回归端到端框架,推理延迟极低,10s音频推理仅耗时70ms,15倍优于Whisper-Large。 - 微调定制: 具备便捷的微调脚本与策略,方便用户根据业务场景修复长尾样本问题。
SenseVoice在线预览链接
SenseVoice在线预览:https://www.modelscope.cn/studios/iic/SenseVoice

本地化部署
这里使用autodl 机器学习平台,官网地址:https://www.autodl.com/market/list
直接到算力市场,选择按量计费,地区随便选择一个,这里使用4090显卡。
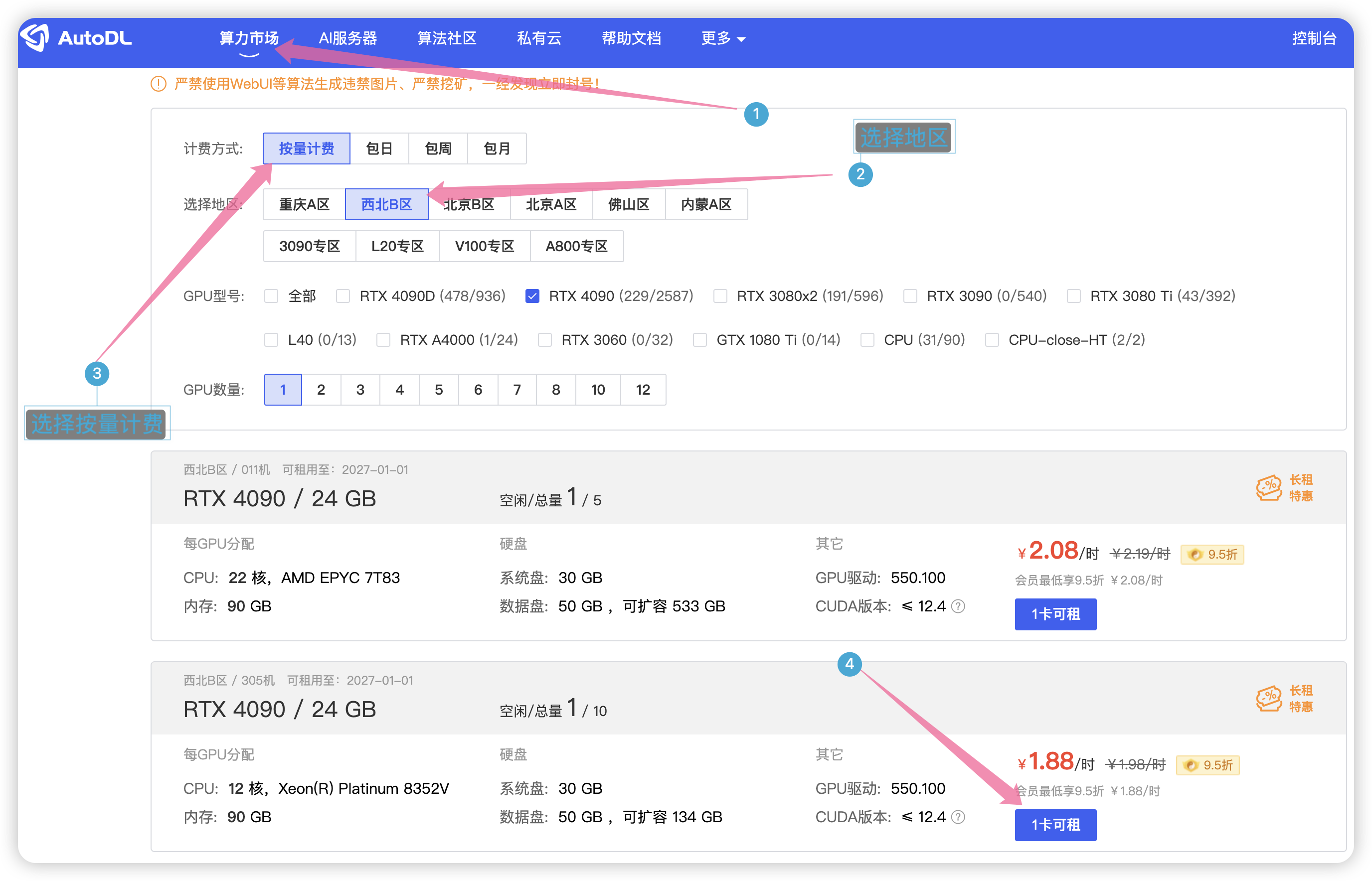
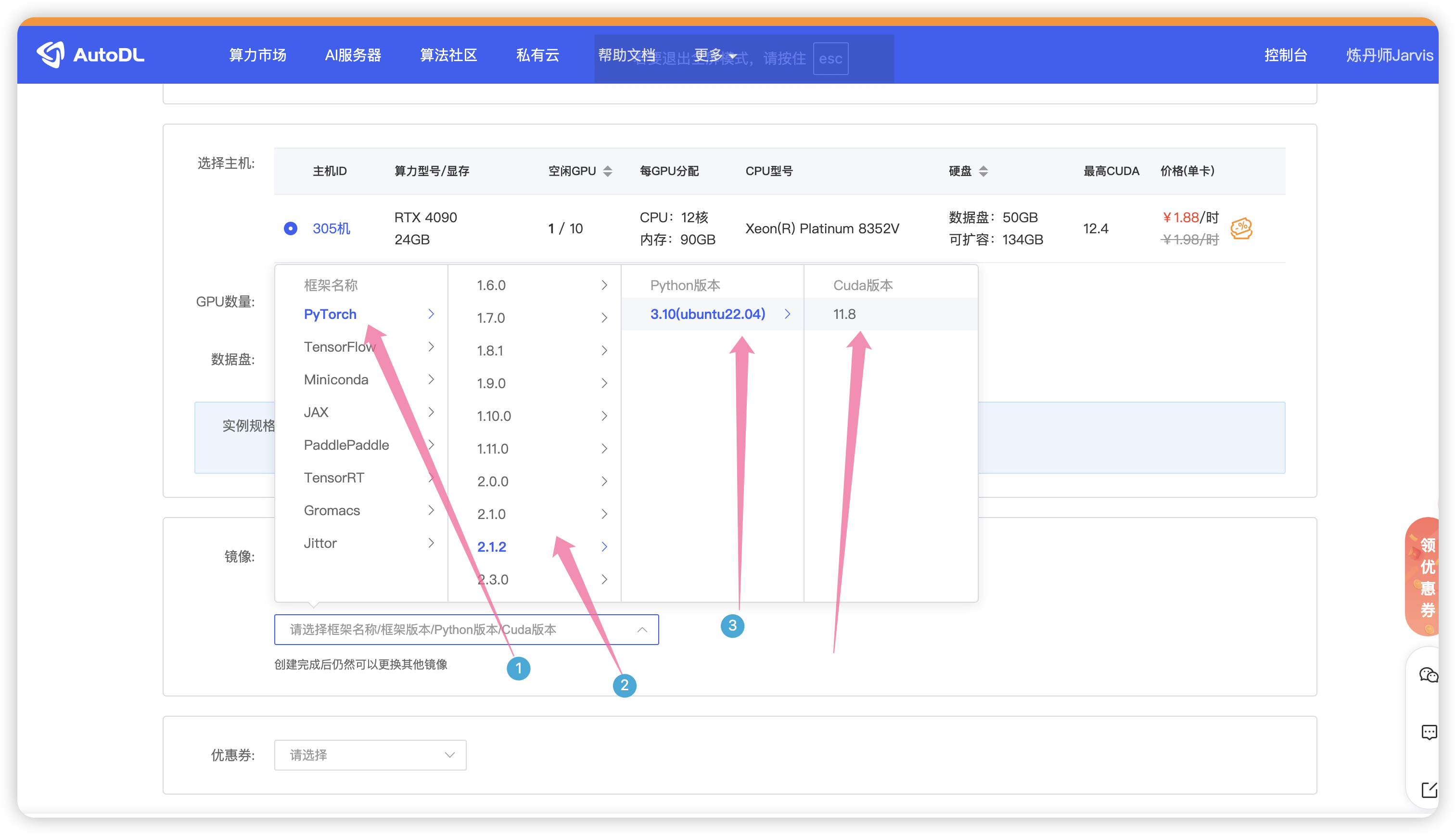
如图选择PyTorch 版本,最后点击创建。
创建好以后就来到了控制台,点击AutoPanel 面板,设置默认为清华源。

点击选择清华源,因为清华源下载依赖包比较快。

接着回到控制台,点击进入JupyterLab。

进入到autodl-tmp 目录下,然后打开终端。
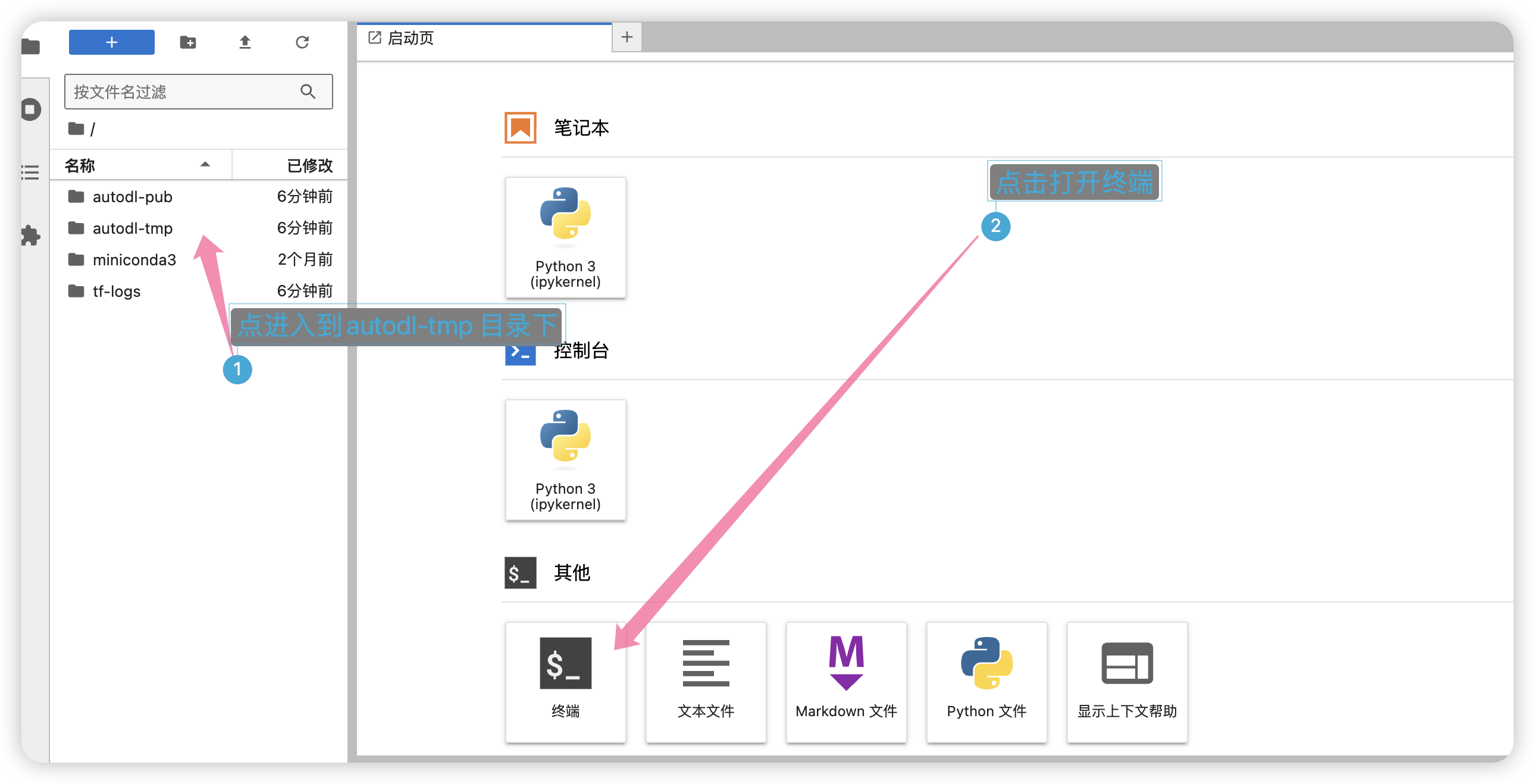
然后克隆项目,输入如下命令:
git clone https://github.com/FunAudioLLM/SenseVoice.git
如果提示网络超时等,输入如下命令,完了重新拉取代码就好。
source /etc/network_turbo
继续打开一个笔记本,下载模型。

键入如下代码后运行:
!pip install modelscope
继续键入如下代码下载模型:
from modelscope.hub.snapshot_download import snapshot_downloadmodel_dir = snapshot_download("iic/SenseVoiceSmall", cache_dir='ai_models')
print(model_dir)
model_dir = snapshot_download("iic/speech_fsmn_vad_zh-cn-16k-common-pytorch", cache_dir='ai_models')
print(model_dir)
出现进度条说明模型开始下载了。

然后回到终端,进入SenseVoice目录。
cd SenseVoice/
创建虚拟环境
# 创建一个名为venv 的虚拟环境。
python -m venv venv
接着激活虚拟环境。
source ./venv/bin/activate
安装依赖
pip install -r requirements.txt
安装好依赖以后,我们更新pip
pip install --upgrade pip

VsCode 远程连接
回到控制台,复制ssh配置。

打开Vsocode,远程连接。
粘贴登录信息
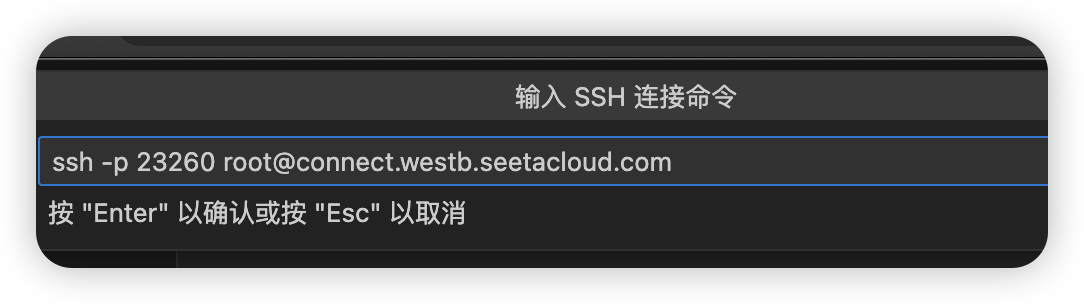
选择第一个默认配置。

选择第一个链接。

复制密码

粘贴密码

接着打开文件夹,选择/root/autodl-tmp/
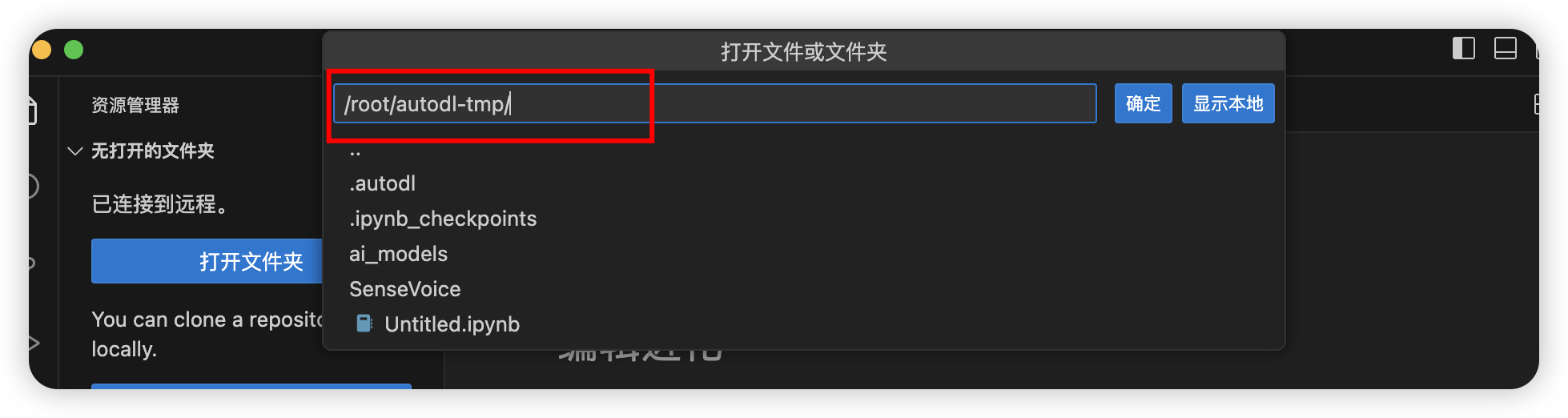
选择信任
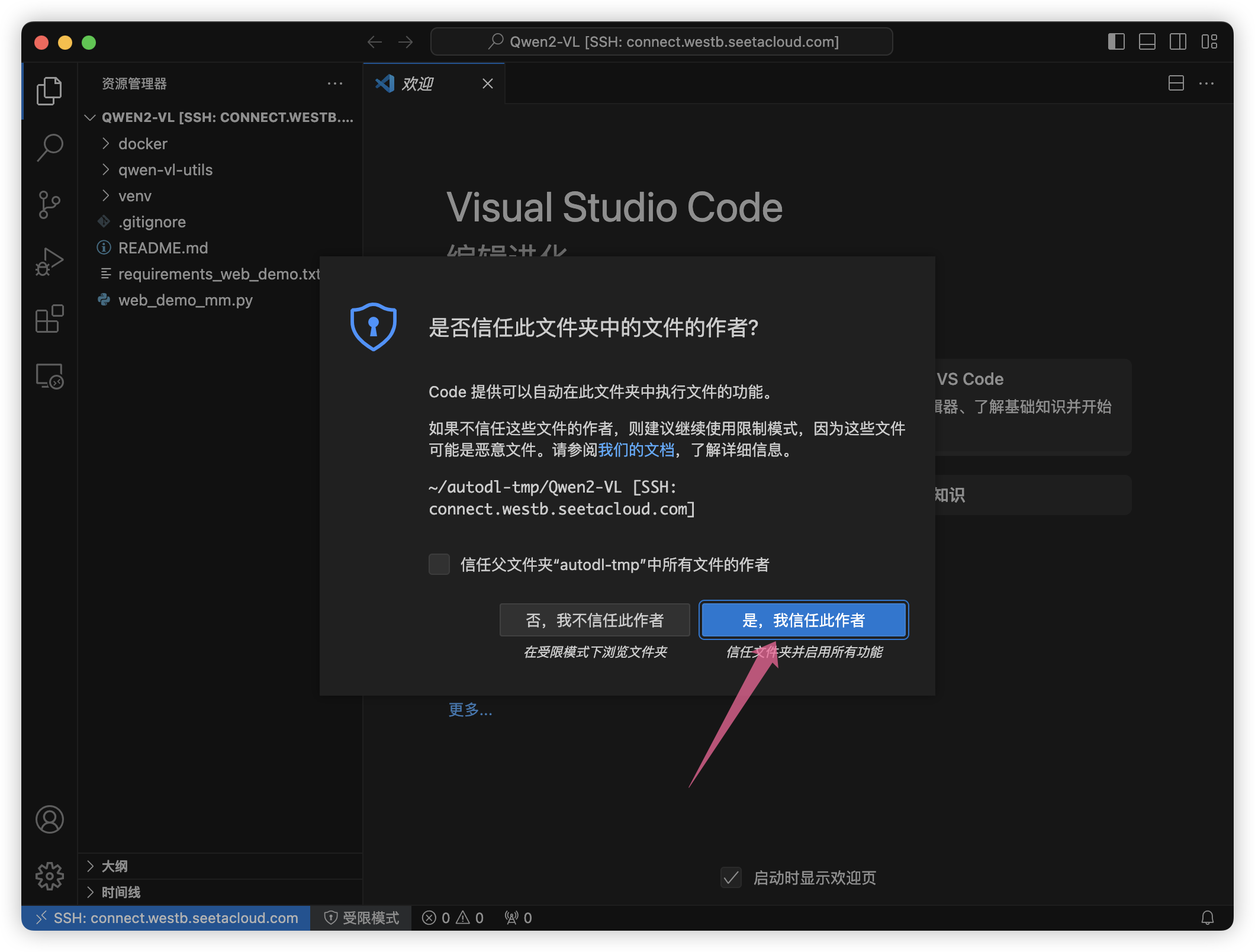
点击打开终端
接着激活虚拟环境。
source ./venv/bin/activate
接着回到笔记本模型哪里,复制下载的模型路径。

回到VsCode ,编辑SenseVoice/webui.py,设置模型的路径为如下:

最后,见证奇迹的时候到了,运行我们的Python代码。
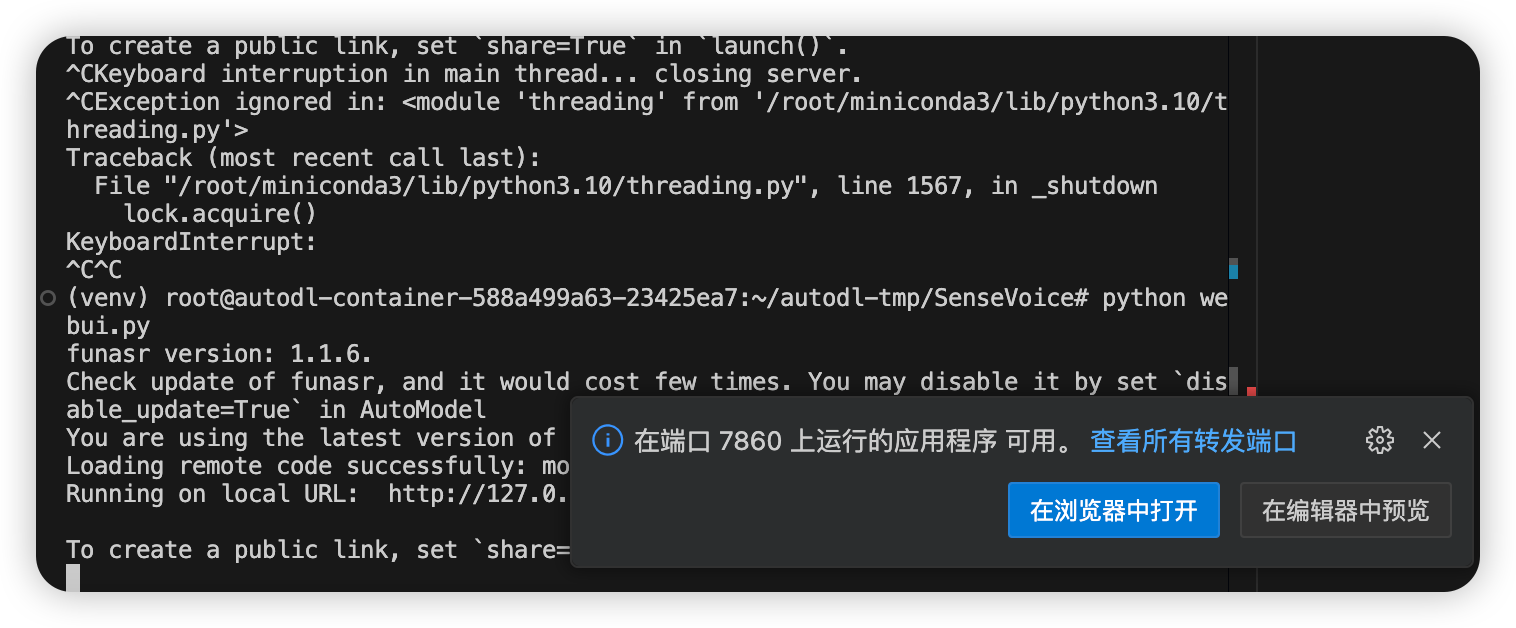
python webui.py
选择在浏览器打开。
接着,就可以快乐的玩耍了。

当我们上传音频时遇到了错误如下错误:

针对安装ffmpeg时遇到的问题,按以下步骤操作:
- 首先更新软件包列表:
sudo apt update
- 如果更新后仍无法安装,可能需要添加universe仓库:
sudo add-apt-repository universe
sudo apt update
- 然后再次尝试安装ffmpeg:
sudo apt install ffmpeg -y
如果还是不行,可能是ffmpeg所在的仓库没有启用。那么可以尝试:
- 启用multiverse仓库:
sudo add-apt-repository multiverse
sudo apt update
- 安装ffmpeg:
sudo apt install ffmpeg
这篇关于AI超强语音转文本SenseVoice,本地化部署教程!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






