本文主要是介绍[目标检测]Fast RCNN算法详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载来自:http://blog.csdn.net/shenxiaolu1984/article/details/51036677
继2014年的RCNN之后,Ross Girshick在15年推出Fast RCNN,构思精巧,流程更为紧凑,大幅提升了目标检测的速度。在Github上提供了源码。
同样使用最大规模的网络,Fast RCNN和RCNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。在PASCAL VOC 2007上的准确率相差无几,约在66%-67%之间.
思想
基础:RCNN
简单来说,RCNN使用以下四步实现目标检测:
a. 在图像中确定约1000-2000个候选框
b. 对于每个候选框内图像块,使用深度网络提取特征
c. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
d. 对于属于某一特征的候选框,用回归器进一步调整其位置
更多细节可以参看前一篇博客。
改进:Fast RCNN
Fast RCNN方法解决了RCNN方法三个问题:
问题一:测试时速度慢
RCNN一张图像内候选框之间大量重叠,提取特征操作冗余。
本文将整张图像归一化后直接送入深度网络。在邻接时,才加入候选框信息,在末尾的少数几层处理每个候选框。
问题二:训练时速度慢
原因同上。
在训练时,本文先将一张图像送入网络,紧接着送入从这幅图像上提取出的候选区域。这些候选区域的前几层特征不需要再重复计算。
问题三:训练所需空间大
RCNN中独立的分类器和回归器需要大量特征作为训练样本。
本文把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
以下按次序介绍三个问题对应的解决方法。
特征提取网络
基本结构
图像归一化为224×224直接送入网络。
前五阶段是基础的conv+relu+pooling形式,在第五阶段结尾,输入P个候选区域(图像序号×1+几何位置×4,序号用于训练)?。
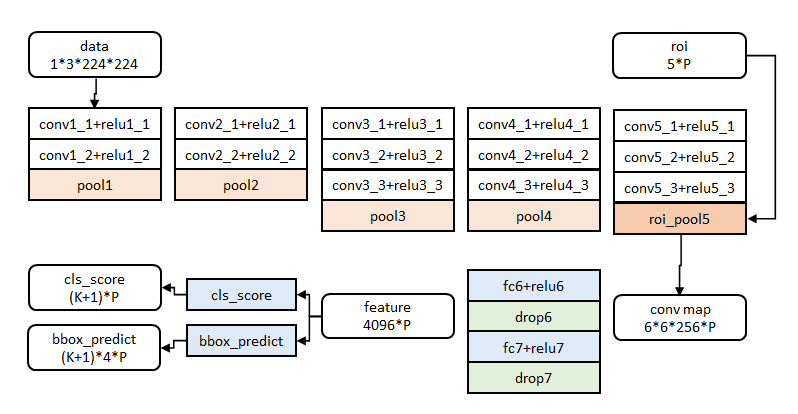
注:文中给出了大中小三种网络,此处示出最大的一种。三种网络基本结构相似,仅conv+relu层数有差别,或者增删了norm层。
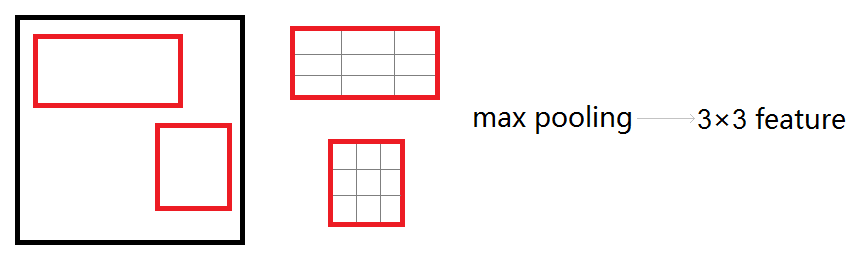
roi_pool层的测试(forward)
roi_pool层将每个候选区域均匀分成M×N块,对每块进行max pooling。将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。
roi_pool层的训练(backward)
首先考虑普通max pooling层。设 xi 为输入层的节点, yj 为输出层的节点。
其中判决函数 δ(i,j) 表示i节点是否被j节点选为最大值输出。不被选中有两种可能: xi 不在 yj 范围内,或者 xi 不是最大值。
对于roi max pooling,一个输入节点可能和多个输出节点相连。设 xi 为输入层的节点, yrj 为第 r 个候选区域的第 j 个输出节点。
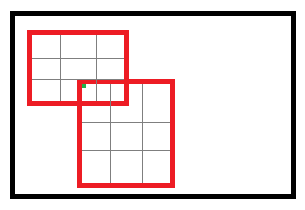
判决函数 δ(i,r,j) 表示i节点是否被候选区域r的第j个节点选为最大值输出。代价对于 xi 的梯度等于所有相关的后一层梯度之和。
网络参数训练
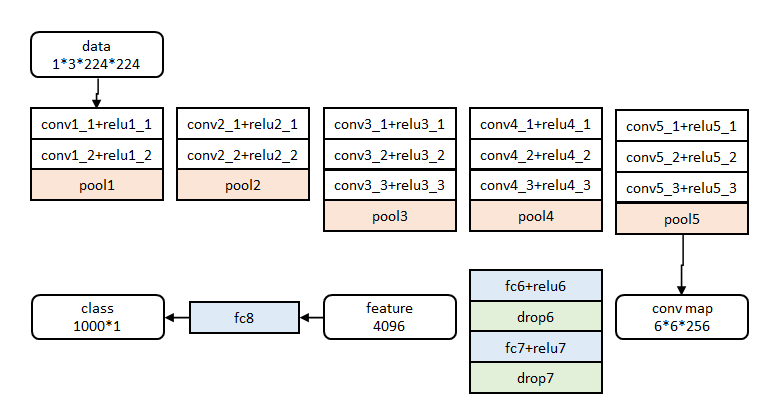
参数初始化
网络除去末尾部分如下图,在ImageNet上训练1000类分类器。结果参数作为相应层的初始化参数。
其余参数随机初始化。
分层数据
在调优训练时,每一个mini-batch中首先加入N张完整图片,而后加入从N张图片中选取的R个候选框。这R个候选框可以复用N张图片前5个阶段的网络特征。
实际选择N=2, R=128。
训练数据构成
N张完整图片以50%概率水平翻转。
R个候选框的构成方式如下:
| 类别 | 比例 | 方式 |
|---|---|---|
| 前景 | 25% | 与某个真值重叠在[0.5,1]的候选框 |
| 背景 | 75% | 与真值重叠的最大值在[0.1,0.5)的候选框 |
分类与位置调整
数据结构
第五阶段的特征输入到两个并行的全连层中(称为multi-task)。
cls_score层用于分类,输出K+1维数组 p ,表示属于K类和背景的概率。
bbox_prdict层用于调整候选区域位置,输出4*K维数组 t ,表示分别属于K类时,应该平移缩放的参数。
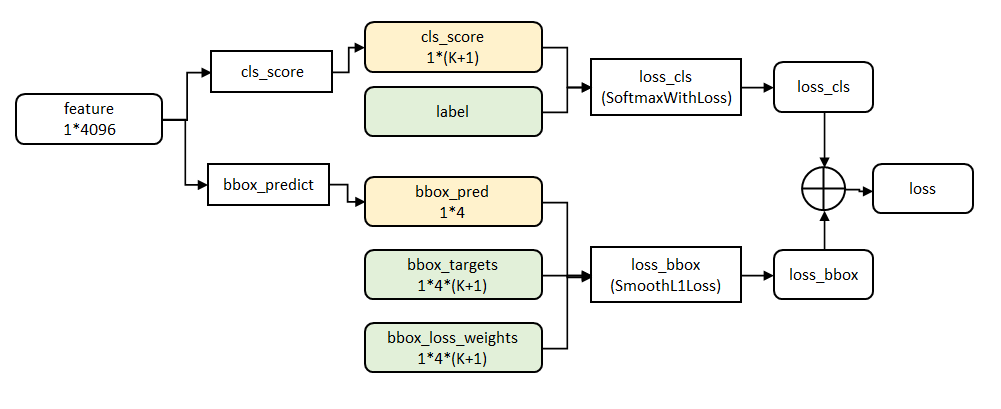
代价函数
loss_cls层评估分类代价。由真实分类 u 对应的概率决定:
loss_bbox评估检测框定位代价。比较真实分类对应的预测参数 tu 和真实平移缩放参数为 v 的差别:
g为Smooth L1误差,对outlier不敏感:
总代价为两者加权和,如果分类为背景则不考虑定位代价:
源码中bbox_loss_weights用于标记每一个bbox是否属于某一个类
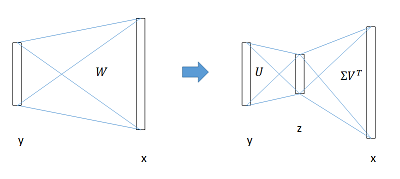
全连接层提速
分类和位置调整都是通过全连接层(fc)实现的,设前一级数据为 x 后一级为 y ,全连接层参数为 W ,尺寸 u×v 。一次前向传播(forward)即为:
计算复杂度为 u×v 。
将 W 进行SVD分解,并用前t个特征值近似:
原来的前向传播分解成两步:
计算复杂度变为 u×t+v×t 。
在实现时,相当于把一个全连接层拆分成两个,中间以一个低维数据相连。
在github的源码中,这部分似乎没有实现。
实验与结论
实验过程不再详述,只记录结论
- 网络末端同步训练的分类和位置调整,提升准确度
- 使用多尺度的图像金字塔,性能几乎没有提高
- 倍增训练数据,能够有2%-3%的准确度提升
- 网络直接输出各类概率(softmax),比SVM分类器性能略好
- 更多候选窗不能提升性能
同年作者团队又推出了Faster RCNN,进一步把检测速度提高到准实时。
关于RCNN, Fast RCNN, Faster RCNN这一系列目标检测算法,可以进一步参考作者在15年ICCV上的讲座Training R-CNNs of various velocities。
这篇关于[目标检测]Fast RCNN算法详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





