本文主要是介绍[LLM][Prompt Engineering]:思维链(CoT),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
思维链
- 思维链
- 1. 思维链提示方法和增强策略
- 1.1 简单的思维链提示
- 1.2 示例形式的思维链提示
- 1.3 思维链提示的后处理方案
- 1.4 拓展推理结构
- 2. CoT的能力来源:为什么思维链提示能显著提升大语言模型在推理任务上的效果?
强大的逻辑推理是大语言模型“智能涌现”出的核心能力之一。
推理:一般指根据几个已知的前提推导得出新的结论的过程,区别于理解,推理一般是一个“多步骤”的过程,推理的过程可以形成非常必要的“中间概念”,这些中间概念将辅助复杂问题的求解。
思维链提示(Chain-of-Thought,CoT)作为上下文学习的一种扩展形式,旨在增强大语言模型在各类复杂推理任务上的表现。常见的推理任务包括算术推理、常识推理以及符号推理多种任务。与上下文学习方法仅使用$⟨ 输入,输出⟩ $ 二元组 来构造提示不同,思维链提示进一步融合了中间的推理步骤来指导从输入到输出的推理过程。将原始的 $⟨ 输入,输出⟩ $ 映射关系转换为 ⟨ 输入,思维链,输出 ⟩ ⟨ 输入,思维链,输出⟩ ⟨输入,思维链,输出⟩三元组形式。通过提供一系列语义连贯且具有逻辑性的中间推理步骤,建立起输入与输出之间的桥接关系。
上下文学习:https://blog.csdn.net/qq_41897558/article/details/141676968?spm=1001.2014.3001.5501
接下来,将介绍基础的思维链提示方法以及相关的增强策略,还将探讨思维链的能力来源以及思维链提示对模型推理的影响。
1. 思维链提示方法和增强策略
1.1 简单的思维链提示
目前有一些简单的方法可以让大模型在回答问题之前生成思考过程。例如,通过向大语言模型提供诸如“Let’s think step by step.”或“Take a deep breath and work on this problemstep-by-step.” 这样的诱导性指令,能够在不提供思维链示例的情况下,仍然让大语言模型先生成思维链再回答问题来提高准确率。
1.2 示例形式的思维链提示
目前大语言模型在使用思维链提示进行推理时,大多采用了上下文学习的设定,即思维链提示通过示例的形式输入给大语言模型,那么如何在上下文学习的基础上设计思维链提示的示例呢?
- 基于复杂度指标设计思维链示例:对于一个上下文示例,增加他的推理步骤(将推理步骤作为复杂度指标),通过对更多子问题的解答,使得推理过程更为缜密。当使用较多推理步骤的示例作为提示输入给模型时,模型更容易学习到多种子问题的解决方案以及对应的逻辑推理过程,能够提升模型在复杂推理任务上的表现。
- 基于多样化示例设计思维链示例:在提示中包含多样化的思维链示例能够有效改善模型的推理能力,主要是因为多样化的思维链示例可以为模型提供多种思考方式以及推理结构。
1.3 思维链提示的后处理方案
LLM模型在生成思维链时容易出现推理错误和生成结果不稳定等情况,还需要对大语言模型生成思维链的过程进行改进。
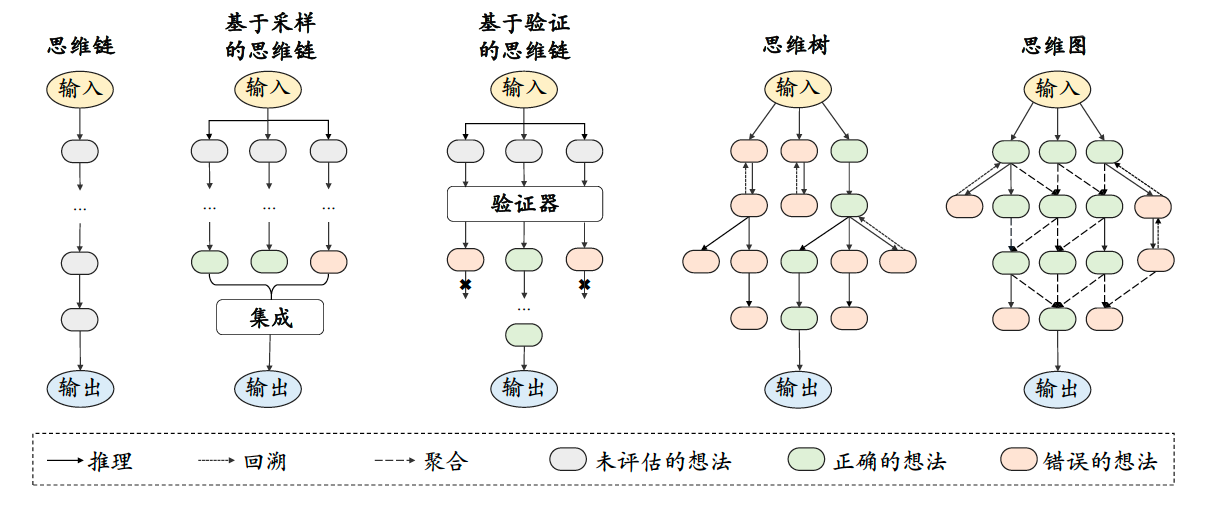
- 基于采样的方法:大语言模型在使用单一的思维链进行推理时,一旦中间推理步骤出错,容易导致最终生成错误的答案。为了缓解这一问题,可以通过采样多条推理路径来缓解单一推理路径的不稳定问题。
Selfconsistency 首先使用大语言模型生成多个推理路径和对应的答案(如图所示),然后对这些候选答案进行集成并获得最终输出。具体的集成方法可以选择各条推理路径所得到答案中出现频率最高的那个答案作为最终输出,在某些情况下也可以对所有答案进行某种形式的加权。我们还可以对上述过程做进一步的扩展:假设大语言模型在一个思维链提示下生成了𝑀1 条推理路径,那么可以使用𝑀2 个思维链提示依次输入给大语言模型,这样一共就能得到𝑀1 × 𝑀2 条推理路径,从中投票选出最终的答案,进一步增加答案的可靠性。基于采样的思维链生成方法不仅简单易行,而且相较于单一思维链方法在多个任务中展现出了更为优异的性能。
- 基于验证的方法:思维链提示所具有的顺序推理本质可能导致推理过程中出现错误传递或累积的现象。为了解决这一问题,可以使用专门训练的验证器或大语言模型自身来验证所生成的推理步骤的准确性。
1.4 拓展推理结构
如上文所述,基于简单的思维链提示和基于采样方法的思维链提示方法,都是链式推理结构,但链式推理结构无法处理前瞻、回溯探索相关问题,存在一定的局限性。
- 树形推理结构:这一方法的代表性工作是思维树(Tree of Thought, ToT)。思维树的每个节点对应一个思考步骤,父节点与子节点之间的连边表示从一个步骤进行下一个步骤。它和思维链的区别在于:思维链从一个节点出发,只能生成一个节点,而思维树则可以生成多个节点。当某一个思考步骤无法得到正确答案时,可以回溯到它的父节点,选择另一个子节点继续推理。
- 图状推理结构:相较于树形结构,图形结构能够支持更为复杂的拓扑结构,从而刻画更加错综复杂的推理关系,可以展现出更强的推理性能。这一方法的代表性工作是思维图(Graph of Thought, GoT)。思维图将整个推理过程抽象为图结构,其中的节点表示大语言模型的中间步骤,节点之间的连边表示这些步骤之间的依赖关系。由于树形结构中只有父节点和子节点之间有连边,因此无法构建不同子节点之间的联系。思维图则允许图上的任意节点相连,因此可以在生成新的中间步骤的同时考虑其他推理路径。
2. CoT的能力来源:为什么思维链提示能显著提升大语言模型在推理任务上的效果?
- 思维链推理能力的来源. 对于思维链工作机制的研究需要探究推理的本质。
- 斯坦福大学的研究人员,假设思维链对大语言模型有效的原因是训练数据中存在很多相互重叠且互相影响的局部变量空间(例如主题、概念和关键词等)。在这个条件下,即使两个变量没有在训练数据中共现,也可以通过一系列重叠的中间变量的推理而联系起来。为了验证这一假设,研究人员构建了一个具有链式结构的贝叶斯网络,并用这个网络合成了一批训练样本,这些样本包含许多相互影响的局部变量空间。然后,使用这批数据来训练一个语言模型,根据给定一个变量来预测另一个变量的条件概率。实验结果发现,如果这两个变量不经常在数据中共现时,模型直接预测这个条件概率总会与真实概率有一定偏差,但是当使用中间变量进行推理预测时,可以获得比直接预测更小的偏差;而当这两个变量经常在数据中共现时,通过中间变量推理和直接预测两种方式带来的偏差会比较接近。
- 还有研究工作从函数学习的角度出发,认为复杂推理任务可以看作是一种组合函数,因此思维链推理实际上是将组合函数的学习过程分解为了两个不同阶段:信息聚焦和上下文学习单步的组合函数。在第一阶段,语言模型将隐式地聚焦到思维链提示中与推理的中间步骤相关的信息。在第二阶段,基于聚焦得到的提示,语言模型通过上下文学习输出一个推理的步骤(即单步组合函数的解),并走向下一步,从而得到最终答案(即整个组合函数的最终解)。通过理论证明与实验验证,研究人员发现信息聚焦阶段显著减少了上下文学习的复杂度,只需要关注提示中与推理相关的重要信息,而上下文学习阶段则促进了复杂组合函数的学习过程,而标准提示则很难让模型学习到这种复杂函数。
- **思维链可以看作一种增强的上下文学习:**因为任务过于复杂,基础提示已经无法准确表达任务意图,因此需要思维链提示来增强对于任务意图的表达。
这篇关于[LLM][Prompt Engineering]:思维链(CoT)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)





![[机缘参悟-222] - 系统的重构源于被动的痛苦、源于主动的精进、源于进化与演进(软件系统、思维方式、亲密关系、企业系统、商业价值链、中国社会、全球)](https://i-blog.csdnimg.cn/direct/fd1df13932fb4df09c34297f62f78bf0.png)