本文主要是介绍LeetCode 0690.员工的重要性:哈希表+广度优先搜索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【LetMeFly】690.员工的重要性:哈希表+广度优先搜索
力扣题目链接:https://leetcode.cn/problems/employee-importance/
你有一个保存员工信息的数据结构,它包含了员工唯一的 id ,重要度和直系下属的 id 。
给定一个员工数组 employees,其中:
employees[i].id是第i个员工的 ID。employees[i].importance是第i个员工的重要度。employees[i].subordinates是第i名员工的直接下属的 ID 列表。
给定一个整数 id 表示一个员工的 ID,返回这个员工和他所有下属的重要度的 总和。
示例 1:
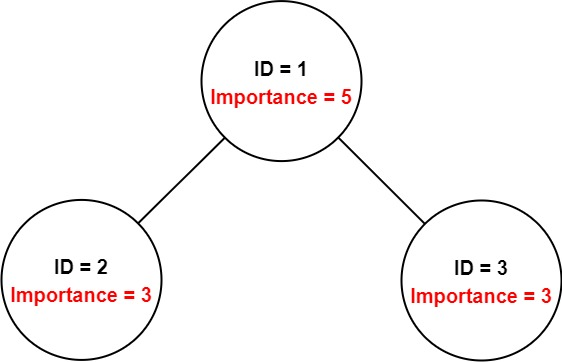
输入:employees = [[1,5,[2,3]],[2,3,[]],[3,3,[]]], id = 1 输出:11 解释: 员工 1 自身的重要度是 5 ,他有两个直系下属 2 和 3 ,而且 2 和 3 的重要度均为 3 。因此员工 1 的总重要度是 5 + 3 + 3 = 11 。
示例 2:
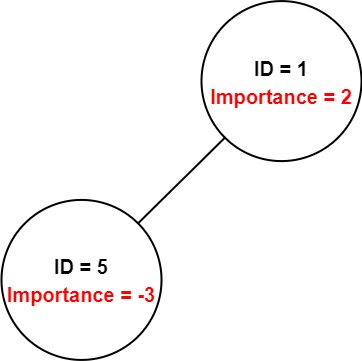
输入:employees = [[1,2,[5]],[5,-3,[]]], id = 5 输出:-3 解释:员工 5 的重要度为 -3 并且没有直接下属。 因此,员工 5 的总重要度为 -3。
提示:
1 <= employees.length <= 20001 <= employees[i].id <= 2000- 所有的
employees[i].id互不相同。 -100 <= employees[i].importance <= 100- 一名员工最多有一名直接领导,并可能有多名下属。
employees[i].subordinates中的 ID 都有效。
解题方法:哈希表+广度优先搜索
因为要多次依据员工id获取员工信息,因此可以二话不说建立一个哈希表。
接着只需要一个广度优先搜索,从id这个员工开始,出队时累加重要程度并将所有子员工入队,直至队列为空。
- 时间复杂度 O ( l e n ( e m p l o y e e s ) ) O(len(employees)) O(len(employees))
- 空间复杂度 O ( l e n ( e m p l o y e e s ) ) O(len(employees)) O(len(employees))
AC代码
Python
from typing import List# # Definition for Employee.
# class Employee:
# def __init__(self, id: int, importance: int, subordinates: List[int]):
# self.id = id
# self.importance = importance
# self.subordinates = subordinatesclass Solution:def getImportance(self, employees: List['Employee'], id: int) -> int:table = dict()for e in employees:table[e.id] = eans = 0q:List['Employee'] = [table[id]]while q:this = q.pop()ans += this.importancefor next in this.subordinates:q.append(table[next])return ans
C++
// // Definition for Employee.
// class Employee {
// public:
// int id;
// int importance;
// vector<int> subordinates;
// };class Solution {
public:int getImportance(vector<Employee*> employees, int id) {unordered_map<int, Employee*> table;for (Employee* thisEmployee : employees) {table[thisEmployee->id] = thisEmployee;}int ans = 0;queue<Employee*> q;q.push(table[id]);while (q.size()) {Employee* thisEmployee = q.front();q.pop();ans += thisEmployee->importance;for (int nextEmployeeId : thisEmployee->subordinates) {q.push(table[nextEmployeeId]);}}return ans;}
};
Java
import java.util.Map;
import java.util.HashMap;
import java.util.List;
import java.util.Queue;
import java.util.LinkedList;// // Definition for Employee.
// class Employee {
// public int id;
// public int importance;
// public List<Integer> subordinates;
// };class Solution {public int getImportance(List<Employee> employees, int id) {Map<Integer, Employee> table = new HashMap<Integer, Employee>();for (Employee thisEmployee : employees) {table.put(thisEmployee.id, thisEmployee);}int ans = 0;Queue<Employee> q = new LinkedList<Employee>();q.add(table.get(id));while (!q.isEmpty()) {Employee thisEmployee = q.poll();ans += thisEmployee.importance;for (int nextId : thisEmployee.subordinates) {q.add(table.get(nextId));}}return ans;}
}
Golang
package mainimport "container/list" // 其实是一个列表// // Definition for Employee.
// type Employee struct {
// Id int
// Importance int
// Subordinates []int
// }func getImportance(employees []*Employee, id int) int {table := map[int]*Employee{};for _, thisEmployee := range employees {table[thisEmployee.Id] = thisEmployee;}ans := 0q := list.New()q.PushBack(table[id])for q.Len() > 0 {thisEmployee := q.Front()q.Remove(thisEmployee)ans += thisEmployee.Value.(*Employee).Importancefor _, nextId := range thisEmployee.Value.(*Employee).Subordinates {q.PushBack(table[nextId])}}return ans
}
End
不得不说,这题员工的重要程度还有负数,也忒损了。
同步发文于CSDN和我的个人博客,原创不易,转载经作者同意后请附上原文链接哦~
Tisfy:https://letmefly.blog.csdn.net/article/details/141576521
这篇关于LeetCode 0690.员工的重要性:哈希表+广度优先搜索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



