本文主要是介绍【Python程序开发系列】一文带你熟悉Jupyter Notebook的使用方法(案例演示),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是我的第347篇原创文章。
一、引言
Jupyter 是一个开源的交互式计算环境,它支持多种编程语言,包括 Python、R、Julia 等。Jupyter通过 Jupyter Notebook 提供了一个基于 Web 的界面,可以创建、编辑和运行 Notebooks。Notebooks是一个包含可执行代码、富文本元素(如说明文档、图表和公式)以及展示结果的交互式环境,你可以在 Jupyter Notebook 中编写和运行 Python 代码。
二、实现过程
2.1 打开anaconda的终端命令窗口Anaconda Prompt
2.2 配置jupyter的Anaconda环境
激活环境:
conda activate <环境名>下载ipykernel :
pip install ipykernel建立连接,将虚拟环境导入jupyter的kernel中:
python -m ipykernel install --name <环境名>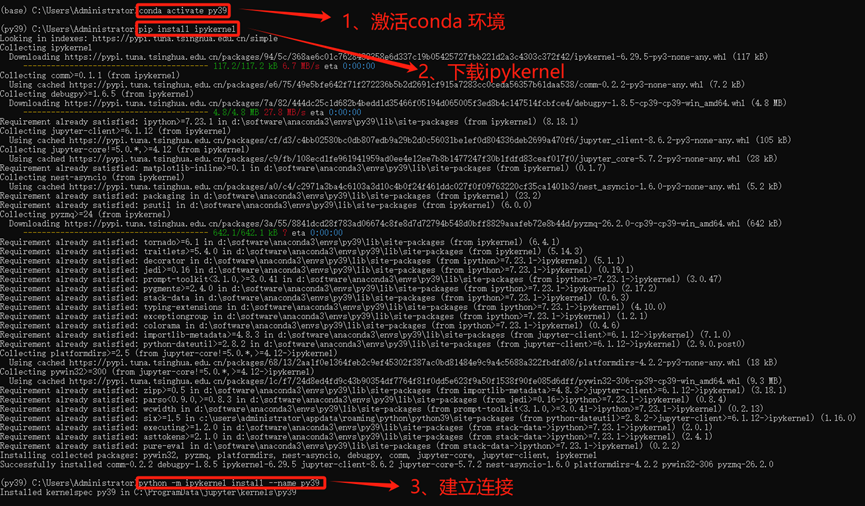
查看已经安装好的虚拟环境的kernel:
jupyter kernelspec list
有时我们要将多余虚拟环境删除,那么jupyter的kernel也需要删除,不然会一直保留这个选项,对于强迫症来说看着一个无用的的kernel选项着实不舒服。(注意:上图中的python3 kernel内核是base的内置核,删除不掉)。删除kernel内核:
jupyter kernelspec remove GANPytorch
jupyter kernelspec remove py310删除完毕上述的kernel后,jupyter中虚拟环境GANPytorch的 kernel内核选项会消失,界面变得更加清爽。(可以继续用命令:jupyter kernelspec list 查看是否还有neural_net选项,没有就是删除干净了)
2.3 运行jupyter
输入:
jupyter notebook实现自动跳转:
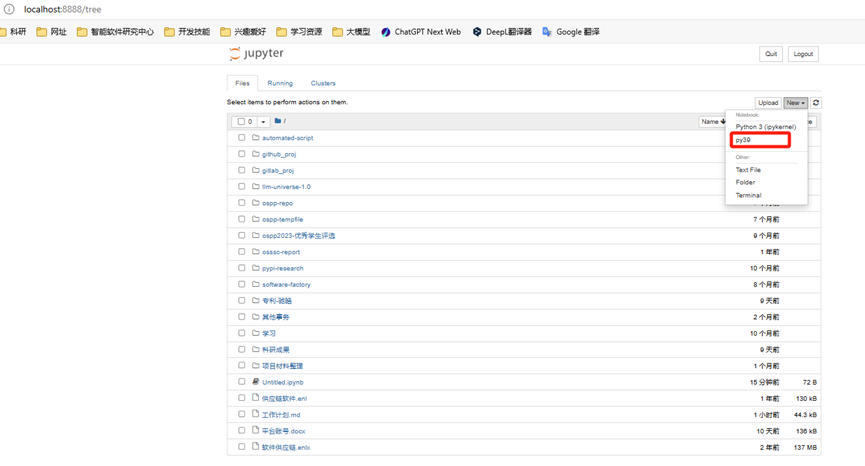
这里的工作目录是‘D:\workspace’,如果我想更改怎么办,比如我想改为'D:\workspace\gitlab_proj\ospp-report',接下来说一下如何更改jupyter notebook的工作目录。
三、更改默认工作目录
1、菜单中打开Anaconda Prompt,生成配置文件:
jupyter notebook --generate-config2、根据上面运行出的路径打开C:\Users\Administrator\.jupyter\ jupyter_notebook_config,找到 #c.NotebookApp.notebook_dir = ‘’,去掉该行前面的“#”;修改NotebookApp.notebook_dir = r'D:\workspace\gitlab_proj\ospp-report'
3、在开始菜单找到“Jupyte Notebook”快捷键
鼠标右击 – 属性 – 目标,去掉后面的 “%USERPROFILE%/”(很重要),然后点击“应用”,“确定”,修改起始位置:'D:\workspace\gitlab_proj\ospp-report'
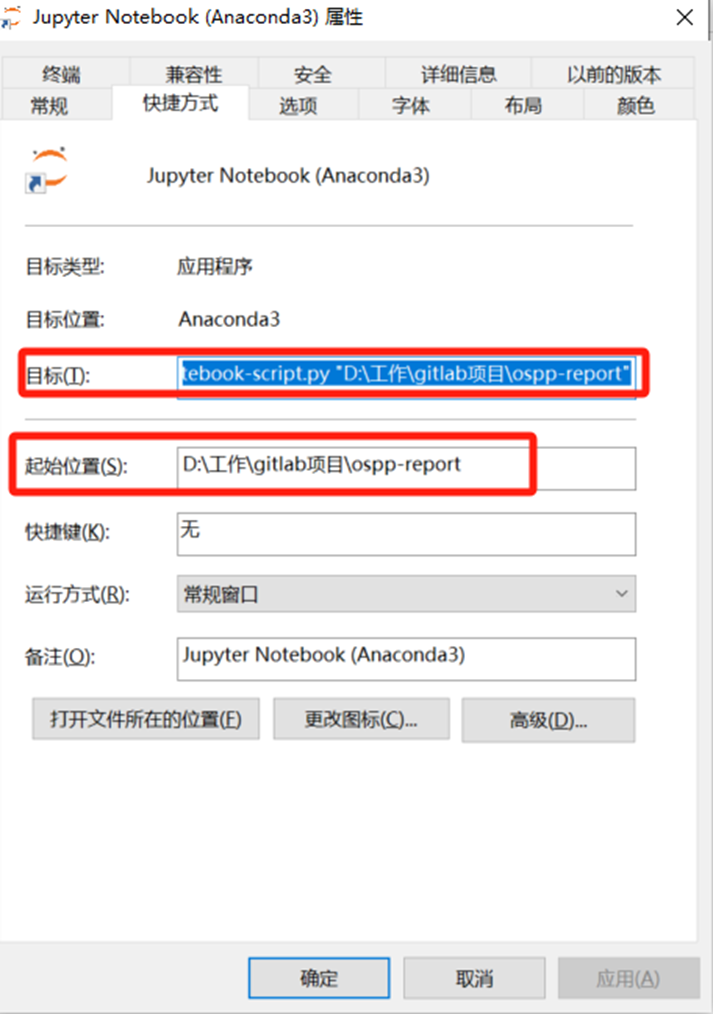
注意:如果改了 jupyter_notebook_config.py,这两个地方都不改的话,从这个快捷方式进入 Jupyter Notebook 会进入默认路径,用 Anaconda Navigator 启动就会进入改变后的路径。对“目标”栏进行改动后,则从快捷方式进入,也会进入修改后的路径。“起始位置”那里的值,改不改都不影响。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。
这篇关于【Python程序开发系列】一文带你熟悉Jupyter Notebook的使用方法(案例演示)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



