本文主要是介绍[分布式网络通讯框架]----ZooKeeper下载以及Linux环境下安装与单机模式部署(附带每一步截图),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
-
首先进入apache官网

-
点击中间的see all Projects->Project List菜单项进入页面

-
找到zookeeper,进入
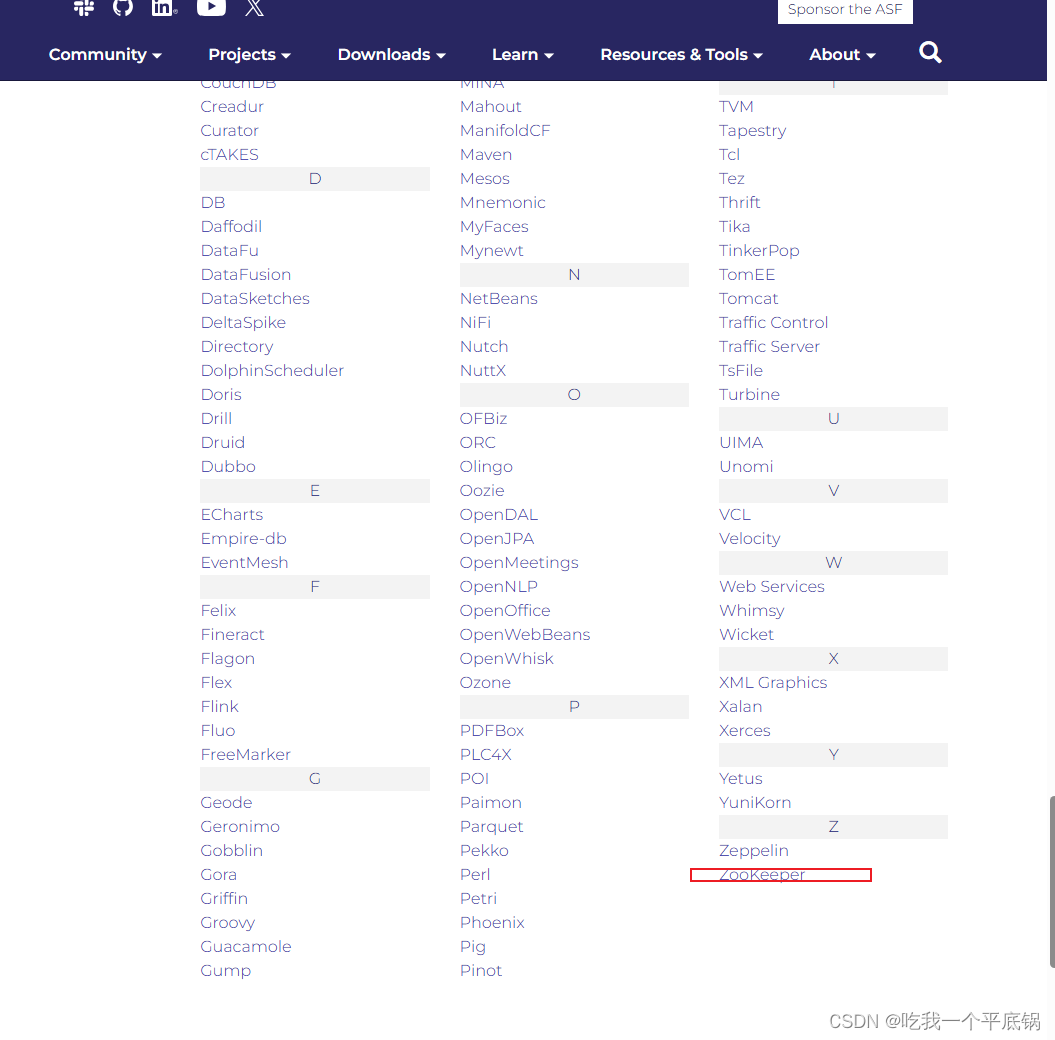
-
在Zookeeper主页的顶部点击菜单Project->Releases,进入Zookeeper发布版本信息页面,如下图:
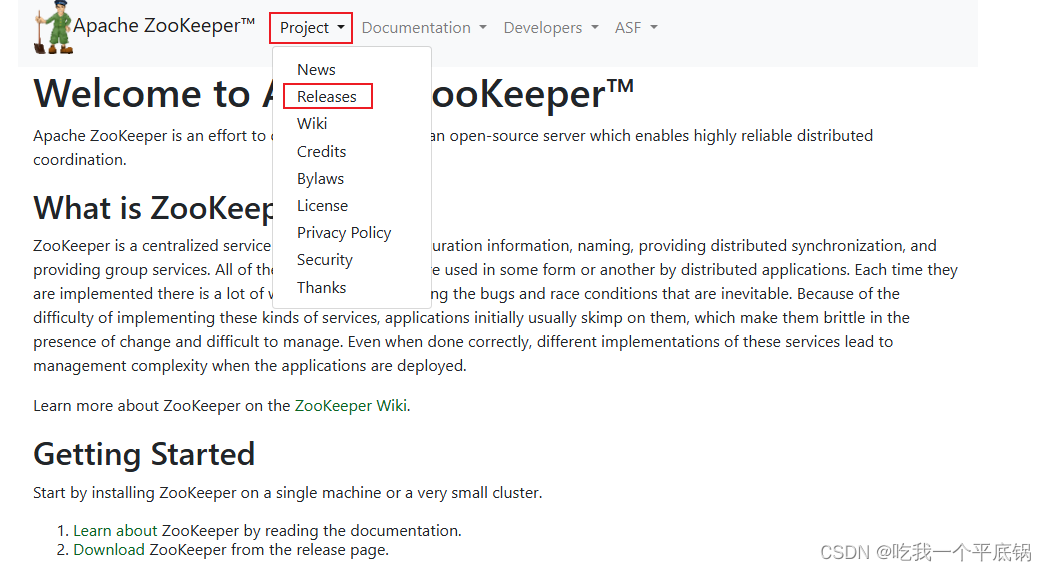
-
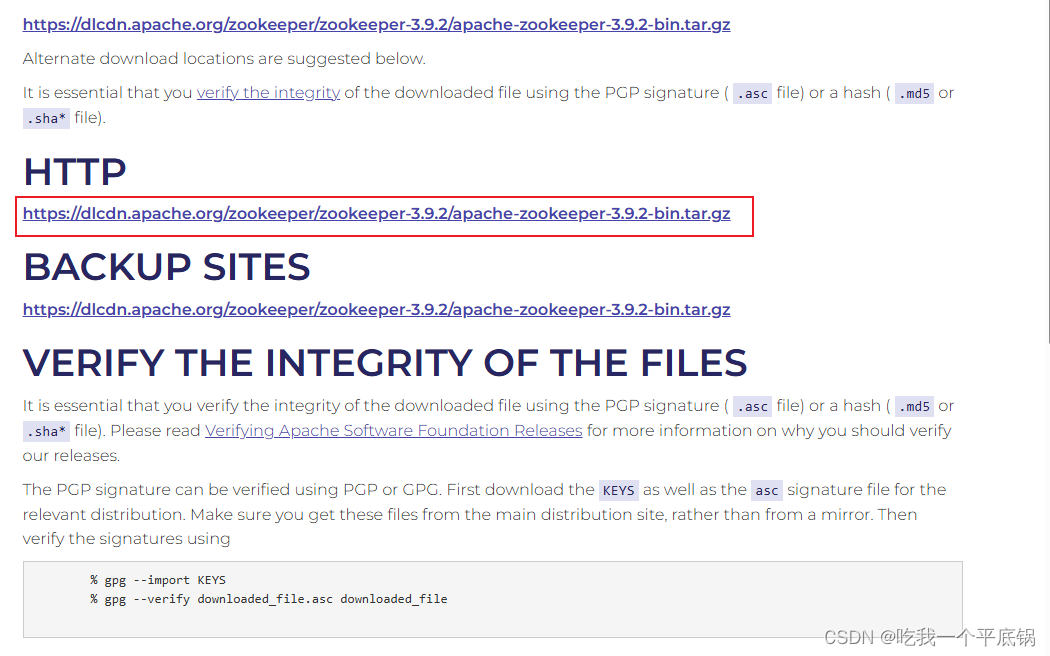
找到需要下载的版本

-
进行下载既可,这里我已经下载过3.4.10,所以以下使用3.4.10进行演示其他的步骤。
Linux环境下安装与单机模式部署
要求一定是安装了JDK环境
-
下载好安装包后,解压安装包
tar -zxvf xxxxx

-
进入文件夹
cd zookeeper-3.4.10/,进入conf,cd conf


-
进入 zoo.cfg
vim zoo.cfg;

-
自己定义一个数据目录。
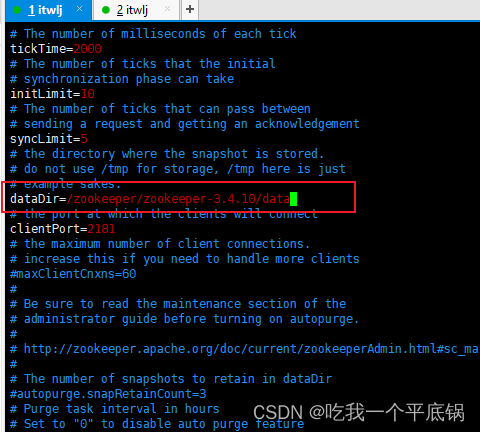
如果使用tmp的话,他是一个临时文件,重启linux就会消失。
参数说明:
- tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
- initLimit:LF初始通信时限,集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
- syncLimit:LF同步通信时限,集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
- dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
- clientPort:客户端连接端口,这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
- autopurge.snapRetainCount:保留数量。
- autopurge.purgeInterval:清理时间间隔,单位:小时。
- server.N = YYY:A:B,其中N表示服务器编号,YYY表示服务器的IP地址,A为LF通信端口,表示该服务器与集群中的leader交换的信息的端口。B为选举端口,表示选举新leader时服务器间相互通信的端口(当leader挂掉时,其余服务器会相互通信,选择出新的leader)。一般来说,集群中每个服务器的A端口都是一样,每个服务器的B端口也是一样。但是当所采用的为伪集群时,IP地址都一样,只能时A端口和B端口不一样。
-
保存退出
:wq -
进入bin目录,
cd ../bin;

-
启动
./zkServer.sh start

-
查询相关服务
ps -ef | grep zookeeper

-
查看端口
netstat -tanp

到此,ZooKeeper下载以及Linux环境下安装与单机模式部署就完成了~
这篇关于[分布式网络通讯框架]----ZooKeeper下载以及Linux环境下安装与单机模式部署(附带每一步截图)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








