本文主要是介绍Python 算法交易实验72 QTV200第一步: 获取原始数据并存入队列,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明
最近的数据流往前进了一步,我觉得基本可以开始同步的推进QTV200了。上次规划了整体的数据流,现在开始第一步。
内容
1 结构位置
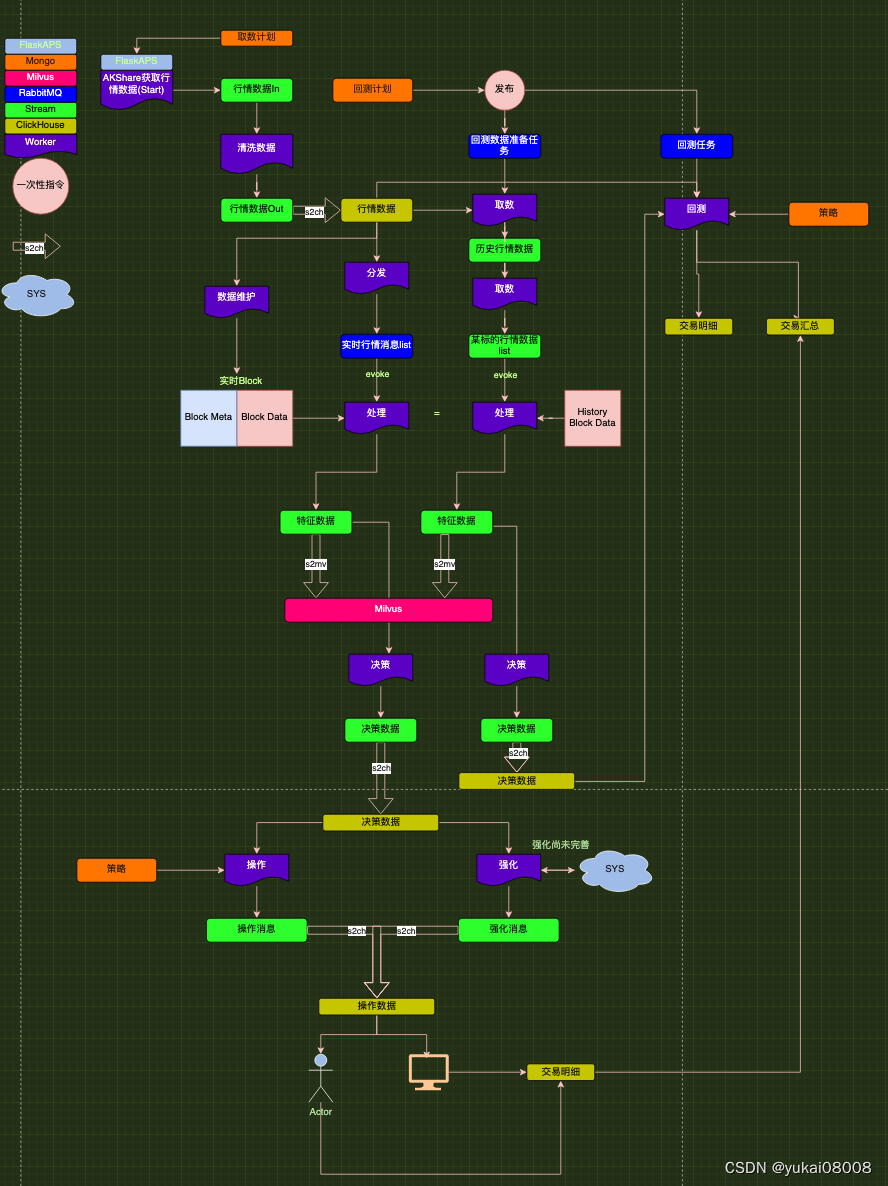
这是上次的总体图:
以下是这次要实现的一小部分:
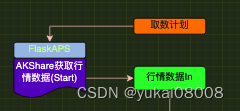
从结构上,这个是整体数据流的起点,系统因为这些不断 运行的数据才开始“动”了起来,可以称为源点。
2 规范与约束
源点是基于每分钟的节拍从外界读取数据,这部分目前我没用用付费接口(数据的需求量很小),所以基于自律(类似与吃自助餐)的原则,增加一些规范与约束。
- 我获取的数据不会多,可以约束在60个ETF之内。
- 每次请求只会查询当前时刻的前10分钟数据(数据少),每只ETF一天最多有60610 ~ 3600条数据
- 每次请求10条的目的是为了防止某个时隙程序中断或者失效,通过冗余的数据可以在10分钟之内的终端内无缝恢复(从这角度,用某个云服务器做这件事比较合适,下一版考虑)
- 任务按照秒进行划分,每秒最多提交6只ETF的请求,数据请求总量为60条
- 周末一定不会发起查询请求
这样可以确保非必要不请求数据,即使请求数据,请求也被均匀分摊,每次的请求量非常之小(环保)
3 工具与方法
通过FLask-APS执行秒级的任务调度,通过Flask-Celery实现各ETF的异步抓取,确保时效的同时,减少CPU开销。(同步方式会独占一个核,很浪费的)。
有的时候倒也不纯粹是为了节约这点计算成本,而是总体成本。设想,一开始只跟踪3~4个ETF,同步状态下并发,可能抢占4个核一小会,还不至于出现卡顿(主机有32核)。但是如果跟踪60个ETF,那么整个机器就会因为这个原因处于卡顿状态,那就真的很没必要。
即使是现阶段,QTV102与Mongo通信的时候更新少量数据,但是是同步状态的,都让我的CPU负载处于一个很奇怪的状态。

虽然看着很满,其实我知道很多是处于浪费的状态的。
所以,如果用合适的方法进行调度,那么即使是60个ETF,甚至是600个ETF可能单核都足够了。这种效率的提升是很夸张的。目前在IO密集处理这块可以做到的提升最大。未来QTV200实现后,应该会把QTV102整个卸载掉。
3.1 worker
对于每一个ETF来说,处理的流程是相同的。所以,可以先做一个worker,然后调用的时候按不通的ETF代码进行参数化就可以了。
etf_crawl_worker.py
# 0 记录日志
import logging
from logging.handlers import RotatingFileHandlerlogger = logging.getLogger('MyLogger')
handler = RotatingFileHandler('/var/log/workers.log', maxBytes=1024*1024*100, backupCount=5)
logger.addHandler(handler)
logger.setLevel(logging.INFO)# 1 允许传入一个参数
import argparse
def get_arg():parser = argparse.ArgumentParser(description='Customized Arguments')
# parser.add_argument('-p','--pkl', default='Meta')# 制程名parser.add_argument('--etf_code')parser.add_argument('--assigned_work_dt')# 准备解析参数args = parser.parse_args()res_dict = {}res_dict['etf_code'] = args.etf_coderes_dict['assigned_work_dt'] = args.assigned_work_dtreturn res_dictarg_dict = get_arg()etf_code = arg_dict['etf_code']
assigned_work_dt = arg_dict.get('assigned_work_dt')from Basefuncs import *
import time# 2 判断是否是可执行时间
if assigned_work_dt is None:ts = time.time()
else:if assigned_work_dt.strip() == '':ts = time.time()else:ts = inverse_time_str(assigned_work_dt)cur_dt_str = get_time_str1(ts)
cur_time = cur_dt_str.split()[-1]morning_start = '09:25:00'
morning_end = '11:41:00'
afternoon_start = '12:55:00'
afternoon_end = '15:11:00'is_moring_work = False
is_afternoon_work = False
if cur_time >= morning_start and cur_time < morning_end:is_moring_work = True
if cur_time >= afternoon_start and cur_time < afternoon_end:is_afternoon_work = True is_work_time = is_moring_work or is_afternoon_workif is_work_time:start_dt = get_time_str1( (ts//60)*60 - 600 )end_dt = get_time_str1( ts + 60 )# 目标队列设置qm = QManager(redis_agent_host = 'http://192.168.0.4:24118/',redis_connection_hash = None)# qm.info()# 3 执行# etf_code = '510300'import akshare as ak para_dict ={}para_dict['symbol'] = etf_codepara_dict['period'] = "1"para_dict['adjust'] = ''para_dict['start_date'] = start_dtpara_dict['end_date'] = end_dt# 如果时间段不对,那么就是空df = ak.fund_etf_hist_min_em(**para_dict)# 是否获取到了数据is_query_data = True if len(df) else False if is_query_data:# ak的变量字典映射ak_dict = {}ak_dict['时间'] = 'data_dt'ak_dict['开盘'] = 'open'ak_dict['收盘'] = 'close'ak_dict['最高'] = 'high'ak_dict['最低'] = 'low'ak_dict['成交量'] = 'vol'ak_dict['成交额'] = 'amt'keep_cols = ['data_dt','open','close','high','low','vol','amt']cols = list(df.columns)new_cols = [ak_dict.get(x) or x for x in cols ]df.columns = new_colsdf1 = df[keep_cols]df1['data_source'] = 'AK'df1['code'] = etf_codedf1['market'] = 'SH'df1['rec_id'] = df1['data_source'] + '_' + df1['market'] + '_' + df1['code'].apply(str) \+ '_' + df1['data_dt']# 调整股和手vol_approximal = df1['amt'] / df1['close']maybe_wrong = (vol_approximal / df1['vol']) > 10if maybe_wrong.sum() > 0:df1['vol'] = df1['vol'] * 100stream_name = 'YOURS.stream_in'# 写入结果队列data_listofdict = df1.to_dict(orient='records')resp = qm.parrallel_write_msg(stream_name, data_listofdict)logger.info('%s %s 【%s】' % (cur_dt_str,'etf_crawl_worker',resp['msg'] )) else:logger.info('%s %s 【未获取到数据】' % (cur_dt_str,'etf_crawl_worker')) else:logger.info('%s %s 【不在工作时间】' % (cur_dt_str,'etf_crawl_worker')) worker分为几部分:
- 1 设定使用rotate日志,记录每次执行的效果
- 2 get_arg 获取调用时传入的关键字参数
- 3 判断是否在工作时间。默认情况,使用当前时间;也可接受使用指定的时间
- 4 如果是在工作时间,那么推算对应时间的前10分钟和后1分钟,作为参数发起请求
- 5 获取数据后,还有一个判断交易量是手还是股的小逻辑
- 6 处理完成后,推入队列,然后记录日志,worker执行完毕
两种调用方法:
- 1 实时获取
python3 etf_crawl_worker.py --etf_code=510300
- 2 指定历史时间的获取
python3 etf_crawl_worker.py --etf_code=510300 --assigned_work_dt='2024-06-21 10:00:00'
获取日志查看,第三条数据是因为指定了工作时间。
/var/log/workers.log
└─ $ cat workers.log
2024-06-23 20:27:07 etf_crawl_worker 【不在工作时间】
2024-06-23 20:40:41 etf_crawl_worker 【不在工作时间】
2024-06-23 20:57:48 etf_crawl_worker 【ok,add 12 of 12 messages】
3.2 shell
exe_etf_crawl_worker.sh
chmod +x exe_etf_crawl_worker.sh
本来想让脚本可以接受第二个参数的,但是似乎隔空传带空格的参数很麻烦,另外实时调用(脚本)的时候没有必要再筛选时间了。
#!/bin/bash# 记录
# sh /home/test_exe.sh com_info_change_pattern running# 有些情况需要把source替换为 .
# . /root/anaconda3/etc/profile.d/conda.sh
# 激活 base 环境(或你创建的特定环境)
source /root/miniconda3/etc/profile.d/conda.sh#conda init
conda activate basecd /home/workers && python3 etf_crawl_worker.py --etf_code=$13.3 flask_celery
将flask_celery升级为可执行脚本的版本
In [1]: import requests as req...: param_dict = {'the_cmd': 'bash /home/test_exe.sh'}...: resp = req.post('http://127.0.0.1:24104/exe_sh/',json = param_dict )In [2]: resp
Out[2]: <Response [200]>└─ $ cat tem.log
2024-06-23 22:16:25 - 脚本执行
3.4 将任务发布为flask_aps任务
任务参数如下
# 任务6:执行脚本-qtv200 510300 get
task006 = {}
task006['machine'] = 'm4'
task006['task_id'] = 'task006'
task006['description'] = '执行脚本,在周一到周五,上午9点到下午4点执行,获取510300的数据。在秒0执行'
task006['pid'] = '.'.join([task006['machine'],task006['task_id'] ])
task006['job_name'] = 'make_a_request' # 这个是对flask-aps来说的
task006['set_to_status'] = 'running'
task006['running_status'] = ''
task006['start_dt'] = '2024-05-01 00:00:00'
task006['end_dt'] = '2099-06-01 00:00:00'
task006['task_kwargs'] = {'para_dict': {'url':'http://172.17.0.1:24104/exe_sh/','json_data':{'the_cmd': 'bash /home/exe_etf_crawl_worker.sh 510300'}}}
task006['interval_para'] ={'second':'0','day_of_week':'0-4','hour':'9-16'}
task006 = TaskTable(**task006)
task006.save()
ok,明天等着看吧
In [11]: the_task_obj = TaskTable.objects(machine='m4',task_id ='task006').first()...: exe_a_task(the_task_obj)
set to status running current state init
Publish a task
Out[11]: 1
这篇关于Python 算法交易实验72 QTV200第一步: 获取原始数据并存入队列的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



