本文主要是介绍Oracle体系结构,逻辑存储结构,物理存储结构,数据字典,用户模式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1 Oracle体系结构概述
2 逻辑存储结构
2.1 数据块 (Data Blocks)
2.2 数据区(Extent)
2.3 段(Segment)
2.4 表空间
2.4.1 SYSTEM 表空间
2.4.2 SYSAUX 表空间
2.4.3 UODO 表空间
2.4.4 USERS 表空间
3 物理存储结构
3.1 数据文件
3.1.1 系统数据文件
3.1.2 撤销数据文件
3.1.3 用户数据文件
3.2 控制文件
3.3 日志文件
3.3.1 重做日志文件
3.3.2 归档日志文件
3.4 服务器参数文件
3.4.1 查看服务器参数
3.4.2 修改服务器参数
3.5 密码文件、警告文件和跟踪文件
3.5.1 密码文件
3.5.2 警告文件
3.5.3 跟踪文件
4 数据字典
4.1 Oracle 数据字典概述
4.1.1 基本数据字典
4.1.2 常用动态性能视图
5 用户模式
5.1 用户、模式、模式对象
5.2 实例模式 SCOTT
1 Oracle体系结构概述
oracle体系结构主要用来分析数据库的组成、工作过程与原理,以及数据在数据库中的组织与管理机制。oracle数据库是一个逻辑概念,而不是物理概念上安装了oracle数据库管理系统的服务器。
在oracle数据库管理系统中有3个重要的概念需要理解,实例(instance)、数据库(database)和数据库服务器(database server)
- 实例:是一组oracle后台进程以及在服务器中分配的共享内存区域;
- 数据库:由基于磁盘的数据文件、控制文件、日志文件、参数文件和归档日志文件等组成的物理文件集合;
- 数据库服务器:管理数据库的各种软件工具和实例及数据库的三个部分。
从实例与数据库之间的辩证关系来讲,实例用于管理和控制数据库;而数据库为实例提供数据。一个数据库可以被多个实例装载和打开,而一个实例在其生存期内只能装载和打开一个数据库。
数据库的主要功能就是存储数据,数据库存储数据的方式通常称为存储结构, Oracle 数据库的存储结构分为逻辑存储结构和物理存储结构。逻辑存储结构用于描述 Oracle 内部组织和管理数据的方式,而物理存储结构用于展示 Oracle 在操作系统中的物理文件组成情况。 启动 Oracle 数据库服务器实际上是在服务器的内存中创建一个 Oracle 实例, 然后用这个实例来访问和控制磁盘中的数据文件。当用户连接到数据库时,实际上连接的是数据库的实例,然后由实例负责与数据库进行通信,最后将处理结果返回给用户。
2 逻辑存储结构
逻辑存储结构是 Oracle 数据库存储结构的核心内容,对 Oracle 数据库的所有操作都会涉及逻辑存储结构。逻辑存储结构是从逻辑的角度分析数据库的构成,是对数据存储结构在逻辑概念上的划分。Oracle 的逻辑存储结构是一种层次结构,主要由表空间、段、区间和数据块等概念组成。逻辑结构是面向用户的,当用户使用 Oracle 设计数据库时,其使用的就是逻辑存储结构。 Oracle 的逻辑存储结构中所包含的多个结构对象从数据块到表空间形成了不同层次的粒度关系,如下图所示:

从图中可以看到, Oracle 数据库由多个表空间组成(数据库自身也属于逻辑概念),而表空间
又由多个段组成,段由多个数据区组成,数据区又由多个数据块组成。
2.1 数据块 (Data Blocks)
数据块是 Oracle 逻辑存储结构中最小的逻辑单位, 也是执行数据库输入输出操作的最小存储单位。Oracle 数据存放在“Oracle 数据块”中,而不是“操作系统块”中。 Oracle 数据块有一定的标准大小,其大小被写入到初始化参数DB_BLOCK_SIZE 中。另外, Oracle 支持在同一个数据库中使用多种大小的块,与标准块大小不同的块就是非标准块。
SQL> col name format a30
SQL> col value format a20
SQL> select name,value from v$parameter where name = 'db_block_size' ;注意:上述语法中col是column的简称,format可以简称为for
数据块中各个组成部分的介绍如下:
- 块头: 存放数据块的基本信息, 如块的物理地址、 块所属的段的类型。
- 表目录:存放表的相关信息。如果数据块中存储的数据是表数据,则表目录中存储有关这些表的相关信息。
- 行目录:如果块中有行数据存在,则这些行的信息将被记录在行目录中。这些信息包括行的地址等。
- 空余空间:空余空间是一个块中未使用的区域,这片区域用于新行的插入和已经存在的行的更新。
- 行数据:用于存放表数据和索引数据的地方,这部分空间已被数据行所占用(如表中的若干行数据记录)。
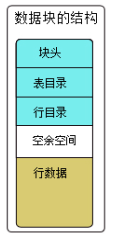
通常把块头、表目录、行目录这 3 部分组合起来称为头部信息区,头部信息区不存放数据,它存放整个块的引导信息,起到引导系统读取数据的作用。所以头部信息区若遭到破坏,则 Oracle 系统将无法读取这部分数据。另外,空余空间和行数据共同构成块的存储区,用于存放真正的数据记录。
2.2 数据区(Extent)
数据区(也可称作数据扩展区)是由一组连续的 Oracle 数据块所构成的 Oracle 存储结构,一个或多个数据块组成一个数据区,一个或多个数据区再组成一个段(Segment)。当一个段中的所有空间被使用完后, Oracle 系统将自动为该段分配一个新的数据区,这也正符合 数据区是 Oracle 存储分配的最小单位, Oracle 就以数据区为单位进行存储控件的扩展。使用数据区的目的是用来保存特定数据类型的数据。 数据区是表中数据增长的基本单位, 在 Oracle数据库中,分配存储空间就是以数据区为单位的。一个 Oracle 对象包含至少一个数据区。设置一个表或索引的存储参数包含设置它的数据区大小。
2.3 段(Segment)
段是由一个或多个数据区构成的,它不是存储空间的分配单位,而是一个独立的逻辑存储结构,用于存储表、索引或簇等占用空间的数据对象, Oracle 也把这种占用空间的数据对象统一称为段。一个段只属于一个特定的数据对象,每当创建一个具有独立段的数据对象时, Oracle 将为它创建一个段。段是为特定的数据对象(如表、索引、回滚等)分配的一系列数据区。段内包含的数据区可以不连续,并且可以跨越多个文件,使用段的目的是用来保存特定对象。一个 Oracle 数据库通常有以下 4种类型的段:
(1)数据段:数据段中保存的是表中的数据记录。在创建数据表时, Oracle 系统将为表创建数据段。当表中的数据量增大时,数据段的大小自然也随着变大,数据段的增大过程是通过向其添加新的数据区来实现的。当创建一个表时,系统自动创建一个以该表的名字命名的数据段。
(2)索引段:索引段中包含了用于提高系统性能的索引。一旦建立索引,系统自动创建一个以该索引的名字命名的索引段。
(3)回滚段:回滚段(也可称作撤销段)中保存了回滚条目, Oracle 将修改前的旧值保存在回滚条目中。利用这些信息,可以撤销未提交的操作,以便为数据库提供读入一致性和回滚未提交的事务,即用来回滚事务的数据空间。当一个事务开始处理时,系统为之分配回滚段,回滚段可以动态创建和撤销。
(4)临时段:当执行创建索引、查询等操作时, Oracle 可能会使用一些临时存储空间,用于暂时性地保存解析过的查询语句以及在排序过程中产生的临时数据。 Oracle 系统将在专门用于存储临时数据的表空间中为操作分配临时段。在执行“CREATE INDEX”、“SELECT ORDER BY”、“SELECT DISTINCT”和“SELECT GROUPBY”等几种类型的 SQL 语句时, Oracle 系统就会在临时表空间中为这些语句的操作分配一个临时段。在数据库管理过程中,若经常需要执行上面这类 SQL 语句,最好调整 SORT_AREA_SIZE 初始化参数来增大排序区,从而使排序操作尽量在内存中完成,以获得更好的执行效率,但同时这对数据库服务器的内存空间提出了更大的要求。
2.4 表空间
Oracle 使用表空间将相关的逻辑结构(如段、数据区等)组合在一起,表空间是数据库的最大逻辑划分区域,通常用来存放数据表、索引、回滚段等数据对象,任何数据对象在创建时都必须被指定存储在某个表空间中。表空间(属逻辑存储结构)与数据文件(属物理存储结构)相对应,一个表空间由一个或多个数据文件组成,一个数据文件只属于一个表空间; Oracle 数据的存储空间在逻辑上表现为表空间,而在物理上表现为数据文件。举个例子来说,表空间相当于操作系统中的文件夹,而数据文件就相当于文件夹中的文件。每个数据库至少有一个表空间(即 SYSTEM 表空间),表空间的大小等于所有从属于它的数据文件大小的总和。
由于表空间在物理上(即磁盘上)包含操作系统中的一个或多个数据文件,因此在表空间中创建的数据对象就存在以下两种情况:
- 若表空间只包含一个数据文件,则该表空间中的所有对象都存储在这个数据文件中。
- 若表空间包含多个数据文件,则 Oracle 即可将数据对象存储在该表空间的任意一个数据文件中,也可以将同一个数据对象中的数据分布在表空间的多个数据文件中。
在创建数据库时, Oracle 系统会自动创建多个默认的表空间,这些表空间除了用于管理用户数据
的表空间之外,默认创建的主要表空间。
2.4.1 SYSTEM 表空间
SYSTEM 表——系统表空间,用于存放 Oracle 系统内部表和数据字典的数据,如表名、列名、用户名等。 Oracle 本身不赞成将用户创建的表、索引等存放在系统表空间中。表空间中的数据文件个数不是固定不变的,可以根据需要向表空间中追加新的数据文件。
2.4.2 SYSAUX 表空间
SYSAUX 表空间是 Oracle 11g 新增加的表空间,是随着数据库的创建而创建的,它充当 SYSTEM的辅助表空间,降低了 SYSTEM 表空间的负荷,主要存储除数据字典以外的其他数据对象。 SYSAUX表空间一般不存储用户的数据,由 Oracle 系统内部自动维护。
2.4.3 UODO 表空间
UODO 表空间——撤销表空间,用于存储撤销信息的表空间。当用户对数据表进行修改操作(包括插入、更新、删除等操作)时, Oracle 系统自动使用撤销表空间来临时存放修改前的旧数据。当所做的修改操作完成并执行提交命令后, Oracle 根据系统设置的保留时间长度来决定何时释放掉撤销表空间的部分空间。一般在创建 Oracle 实例后, Oracle 系统自动创建一个名字为“UNDOTBS1”的撤销
表空间,该撤销表空间对应的数据文件是“UNDOTBS01.DBF”。
2.4.4 USERS 表空间
USERS 表空间——用户表空间,是 Oracle 建议用户使用的表空间,可以在这个表空间上创建各种数据对象,比如创建表、索引、用户等数据对象。 Oracle 系统的样例用户 SCOTT 对象就存放在 USERS表空间中。除了 Oracle 系统默认创建的表空间外,用户可根据应用系统的实际情况及其所要存放的对象类型创建多个自定义的表空间,以区分用户数据与系统数据。此外,不同应用系统的数据应存放在不同的表空间上,而不同表空间的文件应存放在不同的盘上,从而减少 I/O 冲突,提高应用系统的操作性能。
3 物理存储结构
逻辑存储结构是为了便于管理 Oracle 数据而定义的具有逻辑层次关系的抽象概念,不容易理解;但物理存储结构比较具体和直观,它用来描述 Oracle 数据在磁盘上的物理组成情况。从大的角度来讲,Oracle 的数据在逻辑上存储在表空间中,而在物理上存储在表空间所包含的物理文件(即数据文件)中。Oracle 数据库的物理存储结构由多种物理文件组成,主要有数据文件、控制文件、重做日志文件、归
档日志文件、参数文件、口令文件和警告日志文件等
3.1 数据文件
数据文件是用于保存用户应用程序数据和 Oracle 系统内部数据的文件,这些文件在操作系统中就是普通的操作系统文件, Oracle 在创建表空间的同时会创建数据文件。
Oracle 数据库在逻辑上由表空间组成,每个表空间可以包含一个或多个数据文件,一个数据文件只能隶属于一个表空间,在创建表空间的同时, Oracle 会创建该表空间的数据文件。在表空间中创建数据对象(如表、索引、簇等)时,用户是无法指定使用哪一个数据文件来进行存储的,只能由 Oracle 系统负责为数据对象选择具体的数据文件,并在其中分配物理存储空间。
一个数据对象的数据可以全部存储在一个数据文件中,也可以分布存储在同一个表空间的多个数据文件中。在读取数据时, Oracle 系统首先从数据文件中读取数据,并将数据存储在内存的高速数据缓冲区中。如果用户要读取数据库中的某些数据,而请求的数据又不在内存的高速数据缓冲区中,则需要从相应的数据文件中读取数据并存储在缓冲区中。当修改和插入数据时, Oracle 不会立即将数据写入数据文件,而是把这些数据保存在数据缓冲区中,然后由 Oracle 的后台进程 DBWR 决定如何将其写入相应的数据文件。这样的存取方式减少了磁盘的 I/O 操作,提高了系统的响应性能。
3.1.1 系统数据文件
用于存放“特殊”的用户数据和 Oracle 系统本身的数据,如用户建立的表名、列名及字段类型等,这些属于用户数据范畴,这些数据被存放在系统表空间所包含的数据文件中;而 Oracle 系统内部的数据字典、系统表(如 dba_data_files、 dba_temp_files 等)中所存储的数据属于 Oracle 系统的内部数据,这些数据也存放在系统表空间所包含的数据文件中。
3.1.2 撤销数据文件
撤销数据文件隶属于撤销表空间。如果修改 Oracle 数据库中的数据,那么就必须使用撤销段,撤销段用来临时存放修改前的旧数据,而撤销段通常存放在一个单独的撤销表空间中,这个撤销表空间所包含的数据文件就是撤销数据文件。
3.1.3 用户数据文件
用户数据文件用于存放用户应用系统的数据,这些数据包括与应用系统有关的所有相关信息,但是从Oracle 9i 以后, Oracle 将临时表空间所对应的临时数据文件与一般数据文件分开,要了解 Oracle 系统的临时数据文件信息,可以从 dba_temp_files 或 v$tempfile 数据字典中查询。
3.2 控制文件
控制文件是一个二进制文件,它记录了数据库的物理结构,其中主要包含数据库名、数据文件与日志文件的名字和位置、数据库建立日期等信息。
控制文件一般在 Oracle 系统安装时或创建数据库时自动创建,控制文件所存放的路径由服务器参数文件 spfileorcl.ora 的 control_files 参数值来指定。由于控制文件存放有数据文件、日志文件等的相关信息,因此, Oracle 实例在启动时必须访问控制文件。只有控制文件正常,实例才能加载并打开数据库;但若控制文件中记录了错误的信息,或者实例无法找到一个可用的控制文件,则实例无法正常启动。
当 Oracle 实例在正常启动时,系统首先要访问的是初始化参数文件 spfile,然后 Oracle 为系统全局区(SGA)分配内存。这时, Oracle 实例处于安装状态,并且控制文件处于打开状态;接下来 Oracle会自动读出“控制文件”中的所有数据文件和日志文件的信息,并打开当前数据库中所有的数据文件和所有的日志文件以供用户访问。每个数据库至少拥有一个控制文件,一个数据库可以同时拥有多个控制文件,但是一个控制文件只能属于一个数据库。控制文件内部除了存放数据库名及其创建日期、数据文件、日志文件等的相关信息之外,在系统运行过程中,还存放有系统更改号、检查点信息及归档的当前状态等信息。出于安全考虑,在安装 Oracle 数据库或创建数据库时,Oracle 数据库系统会自动创建两个或 3 个控制文件, 每个控制文件记录相同的信息。这样可确保在数据库运行时, 如果某个控制文件损坏, Oracle会自动使用另外一个控制文件,当所有控制文件都损坏时,系统将无法工作。
3.3 日志文件
日志文件的主要功能是记录对数据所作的修改,对数据库所作的修改几乎都记录在日志文件中。在出现问题时,可以通过日志文件得到原始数据,从而保障不丢失已有操作成果。 Oracle 的日志文件包括重做日志文件(Redo Log File)和归档日志文件(Archive Log File),它们是 Oracle 系统的主要文件之一,尤其是重做日志文件,它是 Oracle 数据库系统正常运行所不可或缺的。
下面将介绍这两种日志文件。
3.3.1 重做日志文件
重做日志文件用来记录数据库所有发生过的更改信息(修改、添加、删除等信息)及由 Oracle 内部行为(创建数据表、索引等)而引起的数据库变化信息。在数据库恢复时,可以从该日志文件中读取原始记录。在数据库运行期间,当用户执行 COMMIT 命令(数据库提交命令)时,数据库首先将每笔操作的原始记录写入到日志文件中,写入日志文件成功后,才把新的记录传递给应用程序。所以,
在日志文件上可以随时读取原始记录以恢复某些数据。
Oracle 系统在运行过程中产生的日志信息,首先被临时存放在系统全局区的“重做日志缓冲区”中,当发出 Commit 命令(或日志缓冲区信息满 1/3)时, LGWR 进程(日志写入进程)将日志信息从“重做日志缓冲区”中读取出来,并将“读取的日志信息”写入到日志文件组中序列号较小的文件里,一个日志组写满后接着写另外一个日志组。当 LGWR 进程将所有能用的日志文件都使用过一遍之后,它将再次转向第一个日志组重新覆写。
3.3.2 归档日志文件
在所有的日志文件被写入一遍之后, LGWR 进程将再次转向第一个日志组进行重新覆写,这样势必会导致一部分较早的日志信息被覆盖掉,但 Oracle 通过归档日志文件解决了这个问题。Oracle 数据库可以运行在两种模式下,即归档模式和非归档模式。
- 非归档模式是指在系统运行期间,所产生的日志信息不断地记录到日志文件组中,当所有重做日志组被写满后,又重新从第一个日志组开始覆写。
- 归档模式是在各个日志文件都被写满而即将被覆盖之前,先由归档进程(ARCH)将即将被覆盖的日志文件中的日志信息读出,并将“读出的日志信息”写入到归档日志文件中,而这个过程又被称为归档操作。
在归档操作进行的过程中,日志写入进程(ARCH)需要等待归档进程(ARCH)的结束才能开始覆写日志文件,这样就延迟了系统的响应时间,而且归档日志文件本身又会占用大量的磁盘空间,这些都会影响系统的整体性能。所以在默认情况下, Oracle 系统不采用归档模式运行。
3.4 服务器参数文件
服务器参数文件 SPFILE(Server parameter File)是二进制文件,用来记录了 Oracle 数据库的基本参数信息(如数据库名、控制文件所在路径、日志缓冲大小等)。
数据库实例在启动之前, Oracle 系统首先会读取 SPFILE 参数文件中设置的这些参数,并根据这些初始化参数来配置和启动实例。比如,设置标准数据块的大小(即参数 db_block_size 的值)、设置日志缓冲区的大小(即参数 log_buffer 的值)等,所以 SPFILE 参数文件非常重要。服务器参数文件在安装 Oracle 数据库系统时由系统自动创建,文件的名称为 SPFILEsid.ora, sid 为所创建的数据库实例名。与早期版本的初始化参数文件 INITsid.ora 不同的是, SPFILE 中的参数由 Oracle 系统自动维护,如果要对某些参数进行修改,则尽可能不要直接对 SPFILE 进行编辑,最好通过企业管理器(OEM)或ALTER SYSTEM 命令来修改,所修改过的参数会自动写到 SPFILE 中。
3.4.1 查看服务器参数
用户可以通过如下两种方式查看数据库的服务器参数。
- 查询视图 v$parameter,可利用该动态性能视图来确定参数的默认值是否被修改过,以及是否可以用 ALTER SYSTEM 和 ALTER SESSION 命令修改。
- 可以使用 SQL*Plus 的 show parameter 命令显示服务器的参数。
3.4.2 修改服务器参数
修改数据库的服务器参数,主要通过企业管理器(OEM)或 ALTER SYSTEM 命令来实现。
- 通过企业管理器(OEM)修改,首先使用 SYSTEM 用户登录 OEM,然后选择“服务器”页面中的“初始化参数”项,将打开如下图所示的“初始化参数”页面,在该页面的“值”列中就可以修改参数值,然后保存就可以。

- 使用 ALTER SYSTEM 命令修改服务器参数
例如:通过 ALTER SYSTEM 命令修改标准数据块的大小为 4096 字节,代码及运行结果如下。
alter system set db_block_size=4096
系统已更改3.5 密码文件、警告文件和跟踪文件
Oracle 系统运行时,除了必需的数据文件、控制文件、日志文件及服务器参数文件外,还需要一些辅助文件,如密码文件、警告文件和跟踪文件,下面将对这些辅助文件进行简单的介绍。
3.5.1 密码文件
密码文件是 Oracle 系统用于验证 sysdba 权限的二进制文件,当远程用户以 sysdba 或 sysoper 连接到数据库时,一般要用密码文件验证。Oracle 11g密码文件的默认存放位置在%dbhome_1%\database 目录下,密码文件的命名格式为 PWD<sid>,其中 sid 表示数据库实例名。创建密码文件既可以在创建数据库实例时自动创建,也可以使用 ORAPWD.EXE 工具手动创建,创建密码文件的命令格式如下:
C:\>ORAPWD FILE=<filename> PASSWORD=<password> ENTRIES=<max_users>- filename:表示密码文件名称。
- password:表示设置 internal/sys 账户口令。
- max_users:表示密码文件中可以存放的最大用户数,对应允许以 sysdba/sysoper 权限登录数据库的最大用户数。
创建了密码文件后,需要设置初始化参数 remote_login_passwordfile 来控制密码文件的使用状态,通常有 3 种状态值:
- NONE 表示只要通过操作系统验证,就不用通过 Oracle 密码文件验证;
- SHARED表示多个数据库实例都可以采用此密码文件验证;
- EXCLUSIVE 表示只有一个数据库实例可以使用此密码文件验证。
创建一个密码文件,其 SYS 口令为 012345,代码如下。
C:\>ORAPWD FILE=E:\app\Admin\product\11.2.0\dbhome_1\database\PWDorcl.ora password=012345 entries=403.5.2 警告文件
警告文件(即警告日志文件)是一个存储在 Oracle 系统目录下的文本文件(名称通常为 alert_orcl.log),它用来记录 Oracle 系统的运行信息和错误信息。运行信息一般包括 Oracle 实例的启动与关闭、建立表空间、增加数据文件等;错误信息包括空间扩展失败、启动实例失败等。当 Oracle 系统安装完毕后,其实例日常运行的基本信息都会记录在警告文件中。警告文件的路径可通过 Oracle 系统的 background_dump_dest 参数值来查看,并且该参数值由服务器进程和后台进程写入。
注意:随着时间的推移,警告文件会越来越大,数据库管理员应该定期删除警告文件
3.5.3 跟踪文件
跟踪文件包括后台进程跟踪文件和用户进程跟踪文件。后台进程跟踪文件用于记录后台进程的警告或错误消息。后台进程跟踪文件的磁盘位置由初始化参数 BACKGROUND_DUMP_DEST 确定,后台进程跟踪文件的命名格式为<sid>_<processname>_<spid>.trc,
例如: orcl_cjq0_5172.trc。用户进程跟踪文件用于记载与用户进程相关的信息,它主要用于跟踪 SQL 语句。通过用户进程跟踪文件,可以判断 SQL 语句的执行性能。用户进程跟跟踪文件的位置由初始化参数 user_dump_dest 确定,用户进程跟踪文件的命名格式为<sid>_ora_<spid>.trc,例如: orcl_ora_4888.trc。
在 v$parameter 视图中查看当前实例的用户跟踪文件的路径,代码及运行结果如下。
SQL> select value from v$parameter where name = 'user_dump_dest';
VALUE------------------------e:\app\administrator\diag\rdbms\orcl\orcl\trace4 数据字典
数据字典是 Oracle 存放关于数据库内部信息的地方,其用途是用来描述数据库内部的运行和管理情况。比如,一个数据表的所有者、创建时间、所属表空间、用户访问权限等信息,这些信息都可以在数据字典中查找到。当用户操作数据库遇到困难时,就可以通过查询数据字典来提供帮助信息。
4.1 Oracle 数据字典概述
Oracle 数据字典的名称由前缀和后缀组成,使用“_”连接,其代表的含义如下:
- dba_:包含数据库实例的所有对象信息。
- v$_:当前实例的动态视图,包含系统管理和系统优化等所使用的视图。
- user_:记录用户的对象信息。
- gv_:分布式环境下所有实例的动态视图,包含系统管理和系统优化使用的视图。
- all_:记录用户的对象信息机被授权访问的对象信息。
4.1.1 基本数据字典
基本数据字典主要包括描述逻辑存储结构和物理存储结构的数据表,另外,还包括一些描述其他数据对象信息的表,比如 dba_views、 dba_triggers、 dba_users 等。
| 数据字典名称 | 说 明 |
| dba_tablespaces | 关于表空间的信息 |
| dba_ts_quotas | 所有用户表空间限额 |
| dba_free_space | 所有表空间中的自由分区 |
| dba_segments | 描述数据库中所有段的存储空间 |
| dba_extents | 数据库中所有分区的信息 |
| dba_tables | 数据库中所有数据表的描述 |
| dba_tab_columns | 所有表、视图以及簇的列 |
| dba_views | 数据库中所有视图的信息 |
| dba_synonyms | 关于同义词的信息查询 |
| dba_sequences | 所有用户序列信息 |
| dba_constraints | 所有用户表的约束信息 |
| dba_indexs | 关于数据库中所有索引的描述 |
| dba_ind_columns | 在所有表及簇上压缩索引的列 |
| dba_triggers | 所有用户的触发器信息 |
| dba_source | 所有用户存储过程信息 |
| dba_data_files | 查询关于数据库文件的信息 |
| dba_tab_grants/privs | 查询关于对象授权的信息 |
| dba_objects | 数据库中所有的对象 |
| dba_users | 关于数据库中所有用户的信息 |
4.1.2 常用动态性能视图
Oracle 系统内部提供了大量的动态性能视图,之所以说是“动态”,是因为这些视图的信息在数据库运行期间会不断地更新。动态性能视图以 v$作为名称前缀,这些视图提供了关于内存和磁盘的运行情况,用户只能进行只读访问而不能修改它们。常用的动态性能视图及其说明如下图所示
| 数据字典名称 | 说 明 |
| v$database | 描述关于数据库的相关信息 |
| v$datafile | 数据库使用的数据文件信息 |
| v$log | 从控制文件中提取有关重做日志组的信息 |
| v$logfile | 有关实例重置日志组文件名及其位置的信息 |
| v$archived_log | 记录归档日志文件的基本信息 |
| v$archived_dest | 记录归档日志文件的路径信息 |
| v$controlfile | 描述控制文件的相关信息 |
| v$instance | 记录实例的基本信息 |
| v$system_parameter | 显示实例当前有效的参数信息 |
| v$sga | 显示实例的 SGA 区的大小 |
| v$sgastat | 统计 SGA 使用情况的信息 |
| v$parameter | 记录初始化参数文件中所有项的值 |
| v$lock | 通过访问数据库会话,设置对象锁的所有信息 |
| v$session | 有关会话的信息 |
| v$sql | 记录 SQL 语句的详细信息 |
| v$sqltext | 记录 SQL 语句的语句信息 |
| v$bgprocess | 显示后台进程信息 |
| v$process | 当前进程的信息 |
5 用户模式
在 Oracle 数据库中,为了便于管理用户所创建的数据库对象(比如数据表、索引、视图等),引入了模式的概念,这样某个用户所创建的数据库对象就都属于该用户模式。
5.1 用户、模式、模式对象
用户、模式、模式对象区别:
- 用户:这里的用户并不是指数据库的操作人员,而是数据库中定义的一个名称,更准确地说它是账户,只是习惯上称其为用户。也可以说用户是用来连接数据库和访问数据库对象的。
- 模式:在oracle中,为了便于管理用户所创建的数据库对象,引入了模式概念。模式是一个数据库对象的集合。模式为一个数据库用户所拥有,并且具有与该用户相同的名称
- 模式对象:由用户创建的逻辑结构,用以存储或引用数据,其实就是指数据库对象
用户与模式区别:
- 用户是连接数据库对象
- 模式是管理数据库对象的
- 用户与模式在oracle中是一对一关系
模式与模式对象:
- 模式是一个数据库对象的集合。模式为一个数据库用户所有,并且具有与该用户相同的名称,比如SYSTEM 模式、 SCOTT 模式等。在一个模式内部不可以直接访问其他模式的数据库对象,即使在具有访问权限的情况下,也需要指定模式名称才可以访问其他模式的数据库对象。
- 模式对象是由用户创建的逻辑结构,用以存储或引用数据。简单地说,模式与模式对象之间的关系就是拥有与被拥有的关系,即模式拥有模式对象;而模式对象被模式所拥有。
5.2 实例模式 SCOTT
Oracle 提供的 SCOTT 模式的目的,就是为了给用户提供一些实例表和数据来展示 Oracle 数据库的一些特性,通过连接到 SCOTT 用户模式,查询数据字典视图 USER_TABLES 可以获得该模式所包含的数据表,共计 4 个。
另外,用户也可以在 SYSTEM 模式下查询 SCOTT 模式所拥有的数据表,但要求使用 dba_tables数据表。
这篇关于Oracle体系结构,逻辑存储结构,物理存储结构,数据字典,用户模式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






