本文主要是介绍Go语言开发框架GoFly已集成数据可视化大屏开发功能,让开发者只专注业务开发,本文指导大家如何使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
框架提供数据大屏开发基础,是考虑当前市场软件应用有一大部分是需要把业务数据做出大屏,很多政府项目对大屏需求特别高,还有生产企业项目也对大屏有需求,没有提供基础规范的后台框架,在开发大屏需要很多时间去基础搭建,如独立起一个项目,或者改造框架,因为框架都有默认layout框框,和登录权限等无法单独打开全屏。还有个特别麻烦的是,屏幕兼容性,因为大屏一般都是在很大显示屏上展示和平时开发电脑屏幕比不一样,页面内容很容易变形,很难做到大屏兼容,很多开发者都是花很大时间去调整大屏幕适配问题。居于以上种种问题,我们框架这些容易出问题集成好的,开发者按着我们要求参考demo开发自己业务部分,只关注页面内容开发,减少很大调试和底层集成时间。
我们采用新版动态屏幕适配方案,全局渲染组件封装,支持数据动态刷新渲染、内部DataV、ECharts图表都支持自由替换,这样大家能做出功能丰富大屏。在线大屏体验地址 如果需要登录大家请登录在点击菜单“数据大屏”打开。效果如下:

开发说明
搭建大屏方法有两种,一种是接去代码包安装大屏demo插件直接在其基础上开发。另一种是直接搭建开发页面。
1.第一种按下图找到大屏插件包 点击安装即可,菜单路由都有已经在安装包里,安装好即可再左侧菜单看到“数据大屏”点击即可打开。
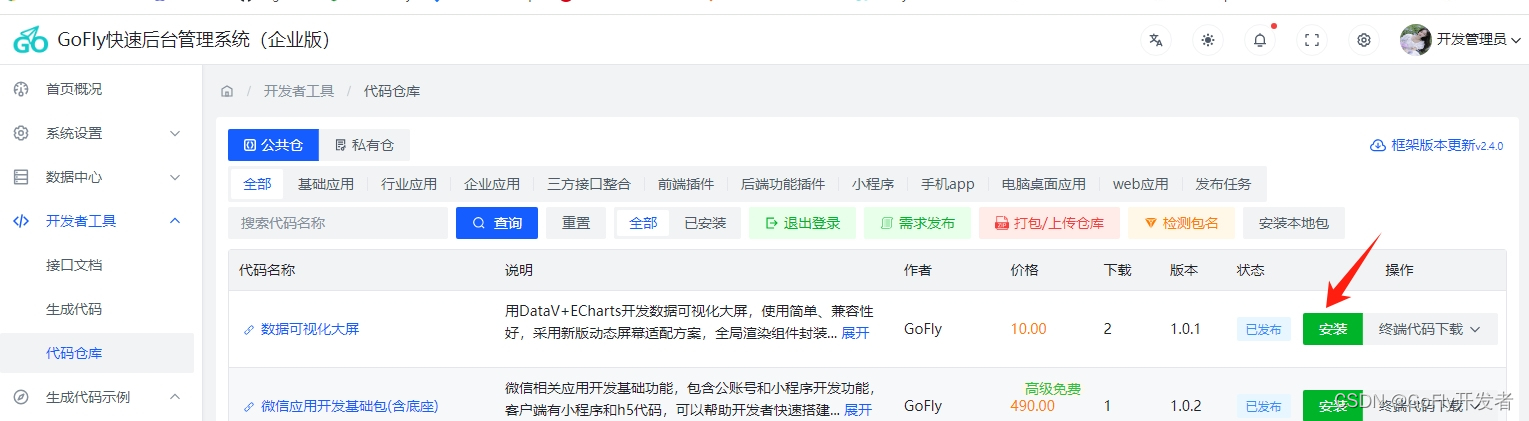
2.第2种手动搭建大屏页面,
在views中创建大屏文件目录,目录内容新建index.vue文件用来开发,再手动创建菜单,创建菜单要注意几个配置,1)组件路径这个是:你在views中创建大屏文件目录及index.vue文件省去.vue后缀,2)勾选独立页面这是:做大屏设置属性,它不要默认layout,点击菜单可以在新窗口打开页面。不需要登录则再勾掉登录权限,如下图
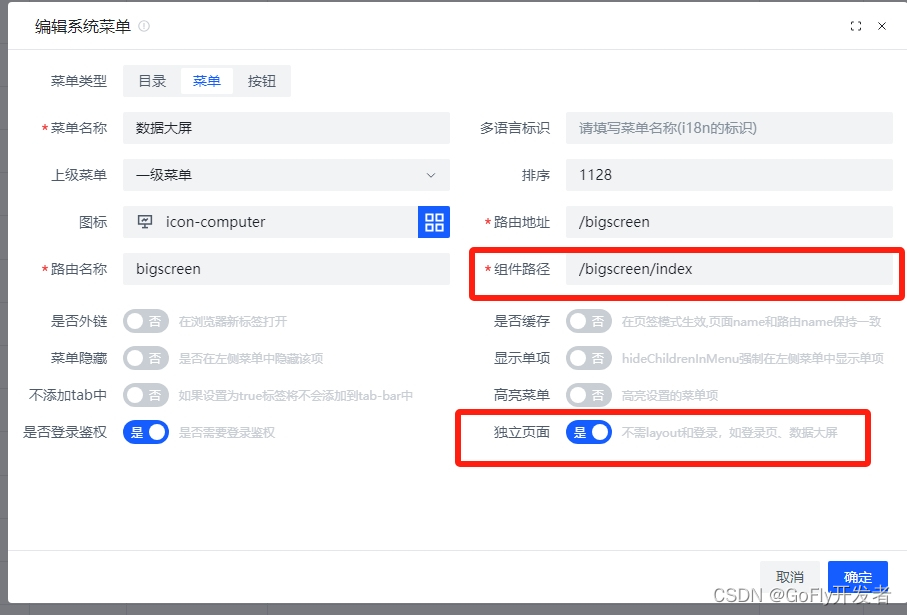
新来的开发者
新来的朋友可以先去,先去了解gofly快速开发框架,1.框架在线演示地址,2.框架代码社区,3.框架企业版地址
这篇关于Go语言开发框架GoFly已集成数据可视化大屏开发功能,让开发者只专注业务开发,本文指导大家如何使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







