本文主要是介绍【YOLOv5/v7改进系列】引入特征融合网络——ASFYOLO,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

一、导言
ASF-YOLO结合空间和尺度特征以实现精确且快速的细胞实例分割。在YOLO分割框架的基础上,通过引入尺度序列特征融合(SSFF)模块来增强网络的多尺度信息提取能力,并利用三重特征编码器(TFE)模块融合不同尺度的特征图以增加细节信息。此外,还引入了通道和位置注意力机制(CPAM),整合SSFF和TFE模块,专注于有信息的通道和与小物体空间位置相关的特征,从而提升检测和分割性能。实验验证显示,ASF-YOLO模型在两个细胞数据集上取得了显著的分割精度和速度,包括在2018年数据科学碗数据集上的框mAP为0.91,掩码mAP为0.887,推理速度为47.3 FPS,优于当时最先进的方法。
优点:
1.创新性模块设计
提出了Scale Sequence Feature Fusion (SSFF) 和 Triple Feature Encoder (TFE) 模块,能够有效融合多尺度特征,增强了网络对不同尺寸、方向和长宽比细胞对象的处理能力。这克服了现有模型如FPN在YOLov5中的局限性,后者无法充分利用金字塔特征图之间的相关性。
2.注意力机制的集成
Channel and Position Attention Mechanism (CPAM) 的引入使模型能自适应地聚焦于与小物体相关的通道和空间位置,这对于提高密集重叠细胞的分割性能至关重要。
3.改进的损失函数与后处理
使用Enhanced Intersection over Union (EIoU) 损失函数优化边界框定位,相比YOLOv5和YOLOv8中使用的CIoU,EIoU更能精确捕捉小对象的位置。同时应用Soft Non-Maximum Suppression (Soft-NMS) 减少密集重叠问题,提高了检测精度。
4.高性能表现
实验结果显示,ASF-YOLO在DSB2018和BCC两个基准细胞数据集上,不仅在分割精度上(box mAP为0.91,mask mAP为0.887)超越了当前最优方法,而且保持了较快的推理速度(47.3 FPS),这在医学和生物学应用中尤为重要。
5.实际应用潜力
作为首个基于YOLO框架用于细胞实例分割的工作,ASF-YOLO展示了在细胞图像分析领域的广泛适用性和潜力,对于推动医疗和生物领域研究有积极影响。
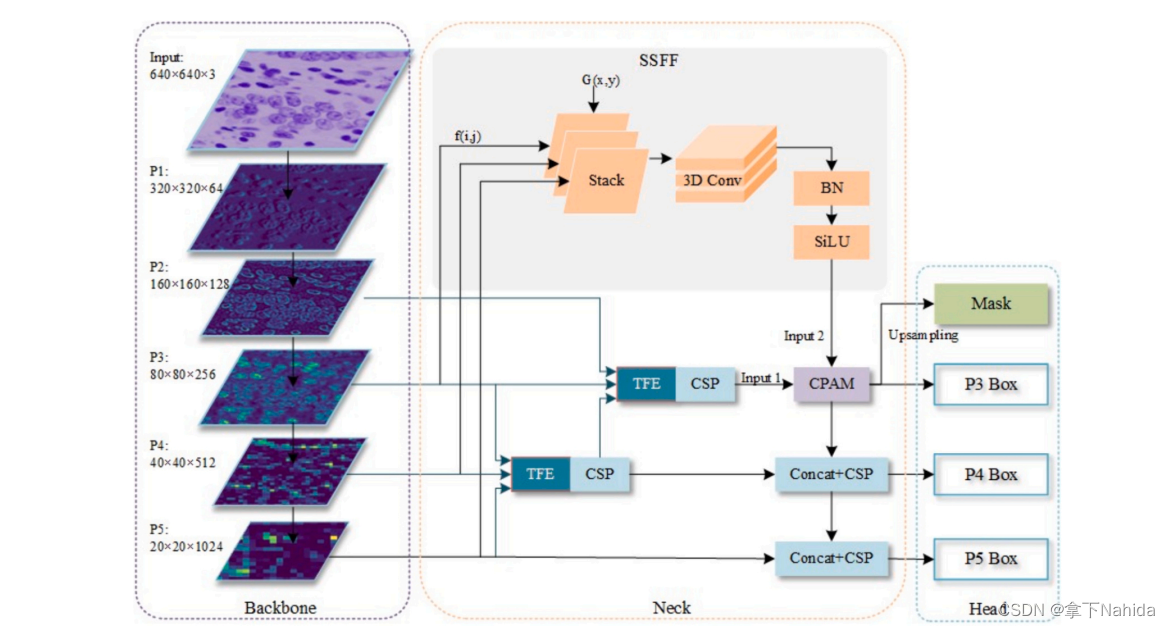
二、准备工作
首先在YOLOv5/v7的models文件夹下新建文件asfyolo.py,导入如下代码
from models.common import *class Zoom_cat(nn.Module):def __init__(self):super().__init__()def forward(self, x):l, m, s = x[0], x[1], x[2]tgt_size = m.shape[2:]l = F.adaptive_max_pool2d(l, tgt_size) + F.adaptive_avg_pool2d(l, tgt_size)s = F.interpolate(s, m.shape[2:], mode='nearest')lms = torch.cat([l, m, s], dim=1)return lmsclass ScalSeq(nn.Module):def __init__(self, inc, channel):super(ScalSeq, self).__init__()self.conv0 = Conv(inc[0], channel, 1)self.conv1 = Conv(inc[1], channel, 1)self.conv2 = Conv(inc[2], channel, 1)self.conv3d = nn.Conv3d(channel, channel, kernel_size=(1, 1, 1))self.bn = nn.BatchNorm3d(channel)self.act = nn.LeakyReLU(0.1)self.pool_3d = nn.MaxPool3d(kernel_size=(3, 1, 1))def forward(self, x):p3, p4, p5 = x[0], x[1], x[2]p3 = self.conv0(p3)p4_2 = self.conv1(p4)p4_2 = F.interpolate(p4_2, p3.size()[2:], mode='nearest')p5_2 = self.conv2(p5)p5_2 = F.interpolate(p5_2, p3.size()[2:], mode='nearest')p3_3d = torch.unsqueeze(p3, -3)p4_3d = torch.unsqueeze(p4_2, -3)p5_3d = torch.unsqueeze(p5_2, -3)combine = torch.cat([p3_3d, p4_3d, p5_3d], dim=2)conv_3d = self.conv3d(combine)bn = self.bn(conv_3d)act = self.act(bn)x = self.pool_3d(act)x = torch.squeeze(x, 2)return xclass Add(nn.Module):# Concatenate a list of tensors along dimensiondef __init__(self):super().__init__()def forward(self, x):input1, input2 = x[0], x[1]x = input1 + input2return xclass channel_att(nn.Module):def __init__(self, channel, b=1, gamma=2):super(channel_att, self).__init__()kernel_size = int(abs((math.log(channel, 2) + b) / gamma))kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1self.avg_pool = nn.AdaptiveAvgPool2d(1)self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):y = self.avg_pool(x)y = y.squeeze(-1)y = y.transpose(-1, -2)y = self.conv(y).transpose(-1, -2).unsqueeze(-1)y = self.sigmoid(y)return x * y.expand_as(x)class local_att(nn.Module):def __init__(self, channel, reduction=16):super(local_att, self).__init__()self.conv_1x1 = nn.Conv2d(in_channels=channel, out_channels=channel // reduction, kernel_size=1, stride=1,bias=False)self.relu = nn.ReLU()self.bn = nn.BatchNorm2d(channel // reduction)self.F_h = nn.Conv2d(in_channels=channel // reduction, out_channels=channel, kernel_size=1, stride=1,bias=False)self.F_w = nn.Conv2d(in_channels=channel // reduction, out_channels=channel, kernel_size=1, stride=1,bias=False)self.sigmoid_h = nn.Sigmoid()self.sigmoid_w = nn.Sigmoid()def forward(self, x):_, _, h, w = x.size()x_h = torch.mean(x, dim=3, keepdim=True).permute(0, 1, 3, 2)x_w = torch.mean(x, dim=2, keepdim=True)x_cat_conv_relu = self.relu(self.bn(self.conv_1x1(torch.cat((x_h, x_w), 3))))x_cat_conv_split_h, x_cat_conv_split_w = x_cat_conv_relu.split([h, w], 3)s_h = self.sigmoid_h(self.F_h(x_cat_conv_split_h.permute(0, 1, 3, 2)))s_w = self.sigmoid_w(self.F_w(x_cat_conv_split_w))out = x * s_h.expand_as(x) * s_w.expand_as(x)return outclass attention_model(nn.Module):# Concatenate a list of tensors along dimensiondef __init__(self, ch=256):super().__init__()self.channel_att = channel_att(ch)self.local_att = local_att(ch)def forward(self, x):input1, input2 = x[0], x[1]input1 = self.channel_att(input1)x = input1 + input2x = self.local_att(x)return x
其次在在YOLOv5/v7项目文件下的models/yolo.py中在文件首部添加代码
from models.asfyolo import *并搜索def parse_model(d, ch)
定位到如下行添加以下代码
elif m is Zoom_cat:c2 = sum(ch[x] for x in f)elif m is Add:c2 = ch[f[-1]]elif m is attention_model:c2 = ch[f[-1]]args = [c2]elif m is ScalSeq:c1 = [ch[x] for x in f]c2 = make_divisible(args[0] * gw, 8)args = [c1, c2]
三、YOLOv7-tiny改进工作
完成二后,在YOLOv7项目文件下的models文件夹下创建新的文件yolov7-tiny-asfyolo.yaml,导入如下代码。
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# anchors
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# yolov7-tiny backbone
backbone:# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True[[-1, 1, Conv, [32, 3, 2, None, 1, nn.LeakyReLU(0.1)]], # 0-P1/2[-1, 1, Conv, [64, 3, 2, None, 1, nn.LeakyReLU(0.1)]], # 1-P2/4[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 7[-1, 1, MP, []], # 8-P3/8[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 14[-1, 1, MP, []], # 15-P4/16[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 21[-1, 1, MP, []], # 22-P5/32[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 28]# yolov7-tiny head
head:[[-1, 1, v7tiny_SPP, [256]], # 29[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[14, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, 21, -2], 1, Zoom_cat, []],[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 38[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[7, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 40[[-1, 14, -2], 1, Zoom_cat, []],[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 47[-1, 1, Conv, [128, 3, 2, None, 1, nn.LeakyReLU(0.1)]],[[-1, 38], 1, Concat, [1]],[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 55[-1, 1, Conv, [256, 3, 2, None, 1, nn.LeakyReLU(0.1)]],[[-1, 29], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 63[[14, 21, 28], 1, ScalSeq, [64]],[[47, -1], 1, attention_model, []], #65[65, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[63, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[55, 1, Conv, [512, 3, 1, None, 1, nn.LeakyReLU(0.1)]],[[66, 67, 68], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)]
from n params module arguments 0 -1 1 928 models.common.Conv [3, 32, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]1 -1 1 18560 models.common.Conv [32, 64, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]2 -1 1 2112 models.common.Conv [64, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]3 -2 1 2112 models.common.Conv [64, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]4 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]5 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]6 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 7 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]8 -1 1 0 models.common.MP [] 9 -1 1 4224 models.common.Conv [64, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]10 -2 1 4224 models.common.Conv [64, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]11 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]12 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]13 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 14 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]15 -1 1 0 models.common.MP [] 16 -1 1 16640 models.common.Conv [128, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]17 -2 1 16640 models.common.Conv [128, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]18 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]19 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]20 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 21 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]22 -1 1 0 models.common.MP [] 23 -1 1 66048 models.common.Conv [256, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]24 -2 1 66048 models.common.Conv [256, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]25 -1 1 590336 models.common.Conv [256, 256, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]26 -1 1 590336 models.common.Conv [256, 256, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]27 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 28 -1 1 525312 models.common.Conv [1024, 512, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]29 -1 1 657408 models.common.v7tiny_SPP [512, 256] 30 -1 1 66048 models.common.Conv [256, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]31 14 1 33280 models.common.Conv [128, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]32 [-1, 21, -2] 1 0 models.asfyolo.Zoom_cat [] 33 -1 1 49280 models.common.Conv [768, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]34 -2 1 49280 models.common.Conv [768, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]35 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]36 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]37 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 38 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]39 -1 1 16640 models.common.Conv [128, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]40 7 1 8448 models.common.Conv [64, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]41 [-1, 14, -2] 1 0 models.asfyolo.Zoom_cat [] 42 -1 1 12352 models.common.Conv [384, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]43 -2 1 12352 models.common.Conv [384, 32, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]44 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]45 -1 1 9280 models.common.Conv [32, 32, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]46 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 47 -1 1 8320 models.common.Conv [128, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]48 -1 1 73984 models.common.Conv [64, 128, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]49 [-1, 38] 1 0 models.common.Concat [1] 50 -1 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]51 -2 1 16512 models.common.Conv [256, 64, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]52 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]53 -1 1 36992 models.common.Conv [64, 64, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]54 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 55 -1 1 33024 models.common.Conv [256, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]56 -1 1 295424 models.common.Conv [128, 256, 3, 2, None, 1, LeakyReLU(negative_slope=0.1)]57 [-1, 29] 1 0 models.common.Concat [1] 58 -1 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]59 -2 1 65792 models.common.Conv [512, 128, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]60 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]61 -1 1 147712 models.common.Conv [128, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]62 [-1, -2, -3, -4] 1 0 models.common.Concat [1] 63 -1 1 131584 models.common.Conv [512, 256, 1, 1, None, 1, LeakyReLU(negative_slope=0.1)]64 [14, 21, 28] 1 62016 models.asfyolo.ScalSeq [[128, 256, 512], 64] 65 [47, -1] 1 779 models.asfyolo.attention_model [64] 66 65 1 73984 models.common.Conv [64, 128, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]67 63 1 590336 models.common.Conv [256, 256, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]68 55 1 590848 models.common.Conv [128, 512, 3, 1, None, 1, LeakyReLU(negative_slope=0.1)]69 [66, 67, 68] 1 17132 models.yolo.IDetect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]Model Summary: 288 layers, 5906519 parameters, 5906519 gradients, 15.2 GFLOPS运行后若打印出如上文本代表改进成功。
四、YOLOv5s改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5s-asfyolo.yaml,导入如下代码。
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]], #10[4, 1, Conv, [512, 1, 1]], #11[[-1, 6, -2], 1, Zoom_cat, []], # 12 cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]], #14[2, 1, Conv, [256, 1, 1]], #15[[-1, 4, -2], 1, Zoom_cat, []], #16 cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]], #18[[-1, 14], 1, Concat, [1]], #19 cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]], #21[[-1, 10], 1, Concat, [1]], #22 cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[4, 6, 8], 1, ScalSeq, [256]],[[17, -1], 1, attention_model, []], #25[[25, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
from n params module arguments 0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2] 1 -1 1 18560 models.common.Conv [32, 64, 3, 2] 2 -1 1 18816 models.common.C3 [64, 64, 1] 3 -1 1 73984 models.common.Conv [64, 128, 3, 2] 4 -1 2 115712 models.common.C3 [128, 128, 2] 5 -1 1 295424 models.common.Conv [128, 256, 3, 2] 6 -1 3 625152 models.common.C3 [256, 256, 3] 7 -1 1 1180672 models.common.Conv [256, 512, 3, 2] 8 -1 1 1182720 models.common.C3 [512, 512, 1] 9 -1 1 656896 models.common.SPPF [512, 512, 5] 10 -1 1 131584 models.common.Conv [512, 256, 1, 1] 11 4 1 33280 models.common.Conv [128, 256, 1, 1] 12 [-1, 6, -2] 1 0 models.asfyolo.Zoom_cat [] 13 -1 1 427520 models.common.C3 [768, 256, 1, False] 14 -1 1 33024 models.common.Conv [256, 128, 1, 1] 15 2 1 8448 models.common.Conv [64, 128, 1, 1] 16 [-1, 4, -2] 1 0 models.asfyolo.Zoom_cat [] 17 -1 1 107264 models.common.C3 [384, 128, 1, False] 18 -1 1 147712 models.common.Conv [128, 128, 3, 2] 19 [-1, 14] 1 0 models.common.Concat [1] 20 -1 1 296448 models.common.C3 [256, 256, 1, False] 21 -1 1 590336 models.common.Conv [256, 256, 3, 2] 22 [-1, 10] 1 0 models.common.Concat [1] 23 -1 1 1182720 models.common.C3 [512, 512, 1, False] 24 [4, 6, 8] 1 132224 models.asfyolo.ScalSeq [[128, 256, 512], 128] 25 [17, -1] 1 3093 models.asfyolo.attention_model [128] 26 [25, 20, 23] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]Model Summary: 306 layers, 7281291 parameters, 7281291 gradients, 18.3 GFLOPs
运行后若打印出如上文本代表改进成功。
五、YOLOv5n改进工作
完成二后,在YOLOv5项目文件下的models文件夹下创建新的文件yolov5n-asfyolo.yaml,导入如下代码。
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]], #10[4, 1, Conv, [512, 1, 1]], #11[[-1, 6, -2], 1, Zoom_cat, []], # 12 cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]], #14[2, 1, Conv, [256, 1, 1]], #15[[-1, 4, -2], 1, Zoom_cat, []], #16 cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]], #18[[-1, 14], 1, Concat, [1]], #19 cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]], #21[[-1, 10], 1, Concat, [1]], #22 cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[4, 6, 8], 1, ScalSeq, [256]],[[17, -1], 1, attention_model, []], #25[[25, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
from n params module arguments 0 -1 1 1760 models.common.Conv [3, 16, 6, 2, 2] 1 -1 1 4672 models.common.Conv [16, 32, 3, 2] 2 -1 1 4800 models.common.C3 [32, 32, 1] 3 -1 1 18560 models.common.Conv [32, 64, 3, 2] 4 -1 2 29184 models.common.C3 [64, 64, 2] 5 -1 1 73984 models.common.Conv [64, 128, 3, 2] 6 -1 3 156928 models.common.C3 [128, 128, 3] 7 -1 1 295424 models.common.Conv [128, 256, 3, 2] 8 -1 1 296448 models.common.C3 [256, 256, 1] 9 -1 1 164608 models.common.SPPF [256, 256, 5] 10 -1 1 33024 models.common.Conv [256, 128, 1, 1] 11 4 1 8448 models.common.Conv [64, 128, 1, 1] 12 [-1, 6, -2] 1 0 models.asfyolo.Zoom_cat [] 13 -1 1 107264 models.common.C3 [384, 128, 1, False] 14 -1 1 8320 models.common.Conv [128, 64, 1, 1] 15 2 1 2176 models.common.Conv [32, 64, 1, 1] 16 [-1, 4, -2] 1 0 models.asfyolo.Zoom_cat [] 17 -1 1 27008 models.common.C3 [192, 64, 1, False] 18 -1 1 36992 models.common.Conv [64, 64, 3, 2] 19 [-1, 14] 1 0 models.common.Concat [1] 20 -1 1 74496 models.common.C3 [128, 128, 1, False] 21 -1 1 147712 models.common.Conv [128, 128, 3, 2] 22 [-1, 10] 1 0 models.common.Concat [1] 23 -1 1 296448 models.common.C3 [256, 256, 1, False] 24 [4, 6, 8] 1 33344 models.asfyolo.ScalSeq [[64, 128, 256], 64] 25 [17, -1] 1 779 models.asfyolo.attention_model [64] 26 [25, 20, 23] 1 8118 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [64, 128, 256]]Model Summary: 306 layers, 1830497 parameters, 1830497 gradients, 4.8 GFLOPs运行后打印如上代码说明改进成功。
六、附各个创新模块优缺点以及简略解释
1.Zoom_cat
功能: 此模块接收三个不同尺度的特征图(大、中、小),通过自适应最大池化和平均池化调整较大尺度特征图(l)的尺寸,使得其与中尺度(m)特征图尺寸相同,并使用最近邻插值方法调整小尺度特征图(s)的尺寸。随后,将这三个调整后的特征图沿着通道维度拼接起来,以融合不同尺度的信息。
优点: 通过这种方式,Zoom_cat模块能够整合来自不同层级的特征信息,提高模型对于不同尺寸目标的检测和分割能力,特别是在处理包含密集小对象的图像时。
2.ScalSeq (Scale Sequence Feature Fusion)
功能: ScalSeq模块首先对输入的三个特征图(p3, p4, p5)应用单独的卷积操作,然后调整尺寸,确保它们可以被有效地融合。之后,将这些特征图转换成三维张量,并通过三维卷积进行融合,以捕捉多尺度特征。最后,通过最大池化操作进一步提炼这些特征。
优点: 该模块通过独特的三维卷积策略,有效融合不同尺度的特征,提高了模型在处理多尺度问题时的性能,尤其是在细胞图像分析这样的任务中,能够更精确地捕捉不同大小和形状的细胞。
3.channel_att (Channel Attention)
功能: 实现通道注意力机制,通过全局平均池化减少空间维度,然后使用一维卷积和sigmoid函数生成通道重要性权重,最后将这些权重应用于输入特征图以增强重要通道。
优点: 通过强调重要的特征通道,减少不必要信息的影响,从而提升模型的特征表达能力和识别精度。
4.local_att (Local Attention)
功能: 引入空间注意力机制,通过计算特征图在宽度和高度方向上的均值,然后通过一系列卷积操作生成空间注意力图,用于突出图像中的特定位置信息。
优点: 能够更好地定位图像中的关键区域,尤其是对小而密集的对象,提高了模型的空间定位精度和分割效果。
5.attention_model
功能: 综合了通道注意力和局部注意力机制,先通过通道注意力机制调整特征图的通道权重,然后结合两个特征图,最后应用局部注意力机制进一步优化特征表示。
优点: 通过集成两种注意力机制,该模块能够更精细地调整和优化特征,增强模型对复杂场景下目标的检测和分割能力,特别适用于细胞实例分割这类需要精确处理小对象的任务。
6.Add
功能: 这是一个简单的模块,用于将两个张量在指定维度上相加,常用于特征图的直接融合。
优点: 提供了一种直接且高效的特征合并方式,有助于简化模型架构并加速计算过程。
更多文章产出中,主打简洁和准确,欢迎关注我,共同探讨!
这篇关于【YOLOv5/v7改进系列】引入特征融合网络——ASFYOLO的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






