本文主要是介绍深度神经网络——决策树的实现与剪枝,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概述
决策树 是一种有用的机器学习算法,用于回归和分类任务。 “决策树”这个名字来源于这样一个事实:算法不断地将数据集划分为越来越小的部分,直到数据被划分为单个实例,然后对实例进行分类。如果您要可视化算法的结果,类别的划分方式将类似于一棵树和许多叶子。
这是决策树的快速定义,但让我们深入了解决策树的工作原理。 更好地了解决策树的运作方式及其用例,将帮助您了解何时在机器学习项目中使用它们。
决策树的结构
决策树的结构类似于流程图,从一个起点或根节点开始,根据过滤条件的判断结果,逐级分支,直至达到树的末端,即叶子节点。每个内部节点代表一个特征的测试条件,而叶子节点则代表数据点的分类标签。
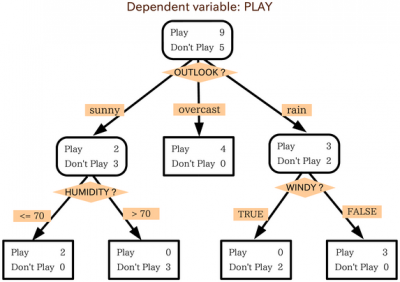
决策树是一种层次化的决策模型,它通过一系列的问题将数据分类。以下是决策树结构的关键组成部分和特性:
-
根节点(Root Node):
- 决策树的起点,代表整个数据集。
-
内部节点(Internal Nodes):
- 表示决策问题或属性测试。每个内部节点对应一个特征(或属性)的分割点。
-
分支(Branches):
- 从每个内部节点延伸出来,代表测试的不同结果。分支的数量取决于该节点特征的可能值。
-
叶子节点(Leaf Nodes):
- 树的末端,代表最终决策或分类结果。在分类问题中,叶子节点通常包含类别标签;在回归问题中,它们包含预测值。
-
路径(Path):
- 从根节点到任一叶子节点的连接序列,代表一系列决策规则。
-
分割(Split):
- 在内部节点处,根据特征值将数据集分割成子集的过程。
-
特征(Feature):
- 用于分割数据的特征或属性。
-
阈值(Threshold):
- 用于确定数据点是否沿着特定分支的值。
-
纯度(Purity):
- 衡量节点中数据点是否属于同一类别的指标。高纯度意味着节点中的数据点属于同一类别。
-
深度(Depth):
- 从根节点到树中任意节点的最长路径长度。
-
宽度(Width):
- 树中叶子节点的最大数量。
-
树高(Tree Height):
- 从根节点到最远叶子节点的边数。
-
基尼指数(Gini Index):
- 用于分类树的内部节点评估,衡量节点不纯度的指标。
-
熵(Entropy):
- 另一种衡量节点不纯度的指标,常用于构建分类树。
-
信息增益(Information Gain):
- 通过分割获得的信息量,用于选择最佳分割点。
-
决策规则(Decision Rules):
- 从根到叶的路径上的一系列决策,用于对数据点进行分类。
决策树的结构使得模型不仅能够进行预测,还能够解释预测背后的逻辑。这种可解释性使得决策树在需要模型透明度的应用中非常有用。然而,决策树也容易过拟合,特别是当树变得非常深和复杂时。因此,剪枝技术通常用于简化决策树,提高其泛化能力。
决策树算法
决策树的构建过程采用递归二元分割算法,该算法通过评估不同特征对数据集进行分割的效果,选择最佳分割点。分割的目的是使得每个子集尽可能地“纯”,即包含的数据点属于同一类别或具有相似的响应值。
分割成本的确定
决策树是一种常用用于分类和回归任务。在回归问题中,决策树的目标是预测一个连续的输出值。如果你使用决策树进行回归预测,并希望计算预测误差,你可以使用均方误差(Mean Squared Error, MSE)作为评估指标。MSE 衡量的是模型预测值与实际值之间差异的平方的平均值。
对于决策树来说,计算 MSE 的过程如下:
-
使用决策树模型进行预测:给定一个训练好的决策树模型,对于每个数据点,使用模型进行预测,得到预测值
prediction_i。 -
计算误差:对于每个数据点,计算其实际值
y_i与预测值prediction_i之间的差异,然后计算这个差异的平方。 -
求和:将所有数据点的误差平方求和。
-
平均:将求和结果除以数据点的总数
n,得到 MSE。
数学公式表示为:
M S E = 1 n ∑ i = 1 n ( y i − prediction i ) 2 {MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \text{prediction}_i)^2 MSE=n1i=1∑n(yi−predictioni)2
其中:
- n n n 是数据集中的样本数量。
- y i y_i yi
是第i` 个样本的实际值。 - p r e d i c t i o n i {prediction}_i predictioni 是模型对第
i个样本的预测值。
在 Python 中,如果使用 scikit-learn 库,可以很容易地计算决策树模型的 MSE。以下是一个简单的例子:
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error
import numpy as np# 假设 X 是特征数据,y 是目标变量
X = ... # 特征数据
y = ... # 目标变量# 创建决策树回归模型
tree_reg = DecisionTreeRegressor()# 训练模型
tree_reg.fit(X, y)# 进行预测
y_pred = tree_reg.predict(X)# 计算 MSE
mse = mean_squared_error(y, y_pred)
print(f"Mean Squared Error: {mse}")
MSE 仅适用于回归问题。如果你在处理分类问题,可能需要考虑其他指标,如准确率、召回率、F1 分数等。此外,MSE 对异常值敏感,因此在某些情况下,你可能还想使用其他指标,如平均绝对误差(Mean Absolute Error, MAE)来评估模型性能。
决策树的剪枝
决策树的剪枝是防止模型过拟合的重要技术。过拟合的决策树可能会在训练数据上表现良好,但在未见过的数据上泛化能力差。剪枝通过移除树中的一些分支来简化模型,从而提高其在新数据上的预测性能。以下是几种常见的决策树剪枝方法:
-
预剪枝(Pre-pruning):
- 在构建决策树的过程中,预剪枝会在树生长的每个阶段评估是否应该停止分裂。如果某个节点的分裂不能显著提高模型的性能,那么这个节点将被标记为叶子节点,不再进一步分裂。
-
后剪枝(Post-pruning):
- 后剪枝是在决策树完全生长完成后进行的。它从树的叶子节点开始,评估移除节点对模型性能的影响。如果移除某个节点后的模型性能没有显著下降,那么这个节点将被删除。
-
错误率降低剪枝(Reduced-Error Pruning):
- 这种方法是在后剪枝的基础上,通过比较剪枝前后的错误率来决定是否剪枝。如果剪枝后的模型在交叉验证集上的错误率没有增加,或者增加的幅度在可接受范围内,那么剪枝是成功的。
-
代价复杂性剪枝(Cost-Complexity Pruning):
- 代价复杂性剪枝是一种后剪枝技术,它通过引入一个参数来平衡模型的复杂度和预测误差。这种方法允许模型在剪枝过程中保持一定程度的复杂性,同时减少过拟合的风险。
-
最小描述长度剪枝(Minimum Description Length Pruning):
- 这种方法基于信息论原理,试图找到能够最小化描述模型和数据所需的信息量(即描述长度)的树。它考虑了模型的复杂性和预测误差,以找到最佳的剪枝点。
-
基于规则的剪枝:
- 在某些情况下,可以使用领域知识来定义规则,以指导剪枝过程。例如,如果某个特征在数据集中的分布非常不均匀,可以考虑剪枝掉依赖于该特征的分支。
使用决策树的注意事项
决策树在需要快速分类且计算时间受限的场景下非常有用。它们能够清晰地展示数据集中哪些特征最具预测力,并且与许多其他机器学习算法相比,决策树的规则更易于解释。此外,决策树能够处理分类变量和连续变量,减少了预处理的需求。
然而,决策树在预测连续属性值时可能表现不佳,且在类别众多而训练样本较少的情况下,分类准确性可能降低。
通过深入理解决策树的工作原理和特性,我们可以更好地判断在机器学习项目中何时使用它们,以及如何优化它们的性能。
这篇关于深度神经网络——决策树的实现与剪枝的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




