本文主要是介绍labelme使用笔记:目标检测数据集标注和语义分割数据集批量生成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI应用开发相关目录
本专栏包括AI应用开发相关内容分享,包括不限于AI算法部署实施细节、AI应用后端分析服务相关概念及开发技巧、AI应用后端应用服务相关概念及开发技巧、AI应用前端实现路径及开发技巧
适用于具备一定算法及Python使用基础的人群
- AI应用开发流程概述
- Visual Studio Code及Remote Development插件远程开发
- git开源项目的一些问题及镜像解决办法
- python实现UDP报文通信
- python实现日志生成及定期清理
- Linux终端命令Screen常见用法
- python实现redis数据存储
- python字符串转字典
- python实现文本向量化及文本相似度计算
- python对MySQL数据的常见使用
- 一文总结python的异常数据处理示例
- 基于selenium和bs4的通用数据采集技术(附代码)
- 基于python的知识图谱技术
- 一文理清python学习路径
- Linux、Git、Docker常用指令
- linux和windows系统下的python环境迁移
- linux下python服务定时(自)启动
- windows下基于python语言的TTS开发
- python opencv实现图像分割
- python使用API实现word文档翻译
- yolo-world:”目标检测届大模型“
- 爬虫进阶:多线程爬虫
- python使用modbustcp协议与PLC进行简单通信
- ChatTTS:开源语音合成项目
- sqlite性能考量及使用(附可视化操作软件)
- 拓扑数据的关键点识别算法
- python脚本将视频抽帧为图像数据集
- 图文RAG组件:360LayoutAnalysis中文论文及研报图像分析
- Ubuntu服务器的GitLab部署
- 无痛接入图像生成风格迁移能力:GAN生成对抗网络
- 一文理清OCR的前世今生
- labelme使用笔记
文章目录
- AI应用开发相关目录
- 简介
- 部署
- 使用
简介
Labelme 是一个开源的数据标注工具,它能够帮助用户为图像、视频等数据添加标签,以供机器学习模型训练使用。Labelme 支持多种类型的标注,包括目标检测、分割、分类等任务,用户可以通过绘制矩形框、多边形、圆形等图形来标注对象,也可以进行像素级的分割标注。
Labelme 的特点包括:
跨平台:Labelme 支持多个操作系统,包括 Windows、macOS 和 Linux。
易于使用:它有一个直观的用户界面,方便用户进行标注工作。
灵活性:支持多种格式的输出,包括常见的 PASCAL VOC、COCO 等格式,方便与其他机器学习框架集成。
可扩展性:Labelme 支持插件,用户可以根据自己的需求定制或扩展功能。
社区支持:作为一个开源项目,Labelme 拥有活跃的社区,用户可以获取支持或分享经验。
Labelme 在学术界和工业界都有广泛的应用,特别是在计算机视觉领域。
部署
conda create -n labelme python=3.6
conda activate labelme
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple labelme
使用

如上图所示,在labelme指定虚拟环境下运行labelme指令。
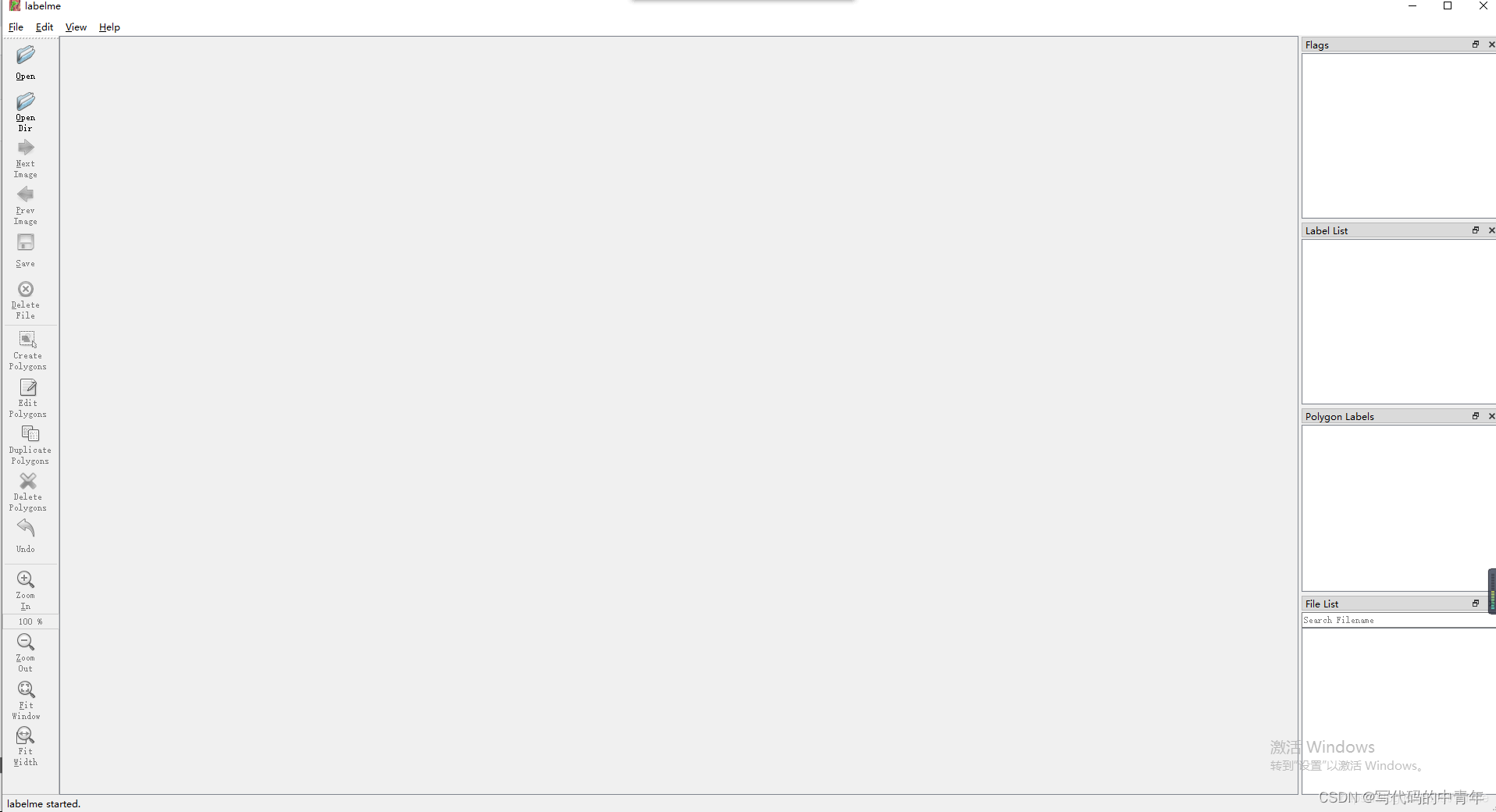
可以选择Open打开一张图片对图片进行标注;
Open Dir选择图片保存的路径,即可标注多张图片。其中,保存ison到指定文件夹:File->Change Output Dir ->选择指定文件夹路径;
create polygons可以进行描边界点,通用还有矩形框等标注方式。
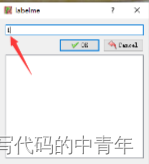
框住或标注图形后输入对应label即可。
注:
Ctrl+S:保存标注
D:下一张图片
S:上一张图片
一般的目标检测、分类等任务到此结束了,可以使用标注数据集进行算法模型训练。
但对于语义分割等任务还需根据标注生成语义图像。
cd 到指定存储生成的json文件的地址。
运行如下指令即可获得目标数据。
labelme_json_to_dataset <文件名>.json
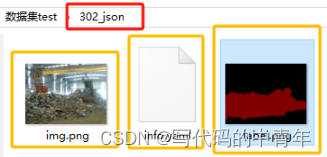
json中包含png原图、yaml文件、png语义图像。
当然这只是一张图像而已,一张一张生成太麻烦,可通过如下代码批量生成:
# labelme版本:3.16.2
import os
import subprocess# JSON文件所在目录,一定要确保json文件与原图像在同一文件夹
json_dir = r"img2\labelme_jsons"# 遍历JSON文件
for json_file in os.listdir(json_dir):if json_file.endswith('.json'):# 构建labelme转换命令json_path = os.path.join(json_dir, json_file)cmd = 'labelme_json_to_dataset ' + json_path# 执行命令subprocess.run(cmd.split())
这篇关于labelme使用笔记:目标检测数据集标注和语义分割数据集批量生成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



