本文主要是介绍2024 年最新 Python 基于火山引擎豆包大模型搭建 QQ 机器人详细教程(更新中),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
豆包大模型概述
火山引擎官网:https://www.volcengine.com/
字节跳动推出的自研大模型。通过字节跳动内部50+业务场景实践验证,每日千亿级tokens大使用量持续打磨,提供多模态能力,以优质模型效果为企业打造丰富的业务体验。
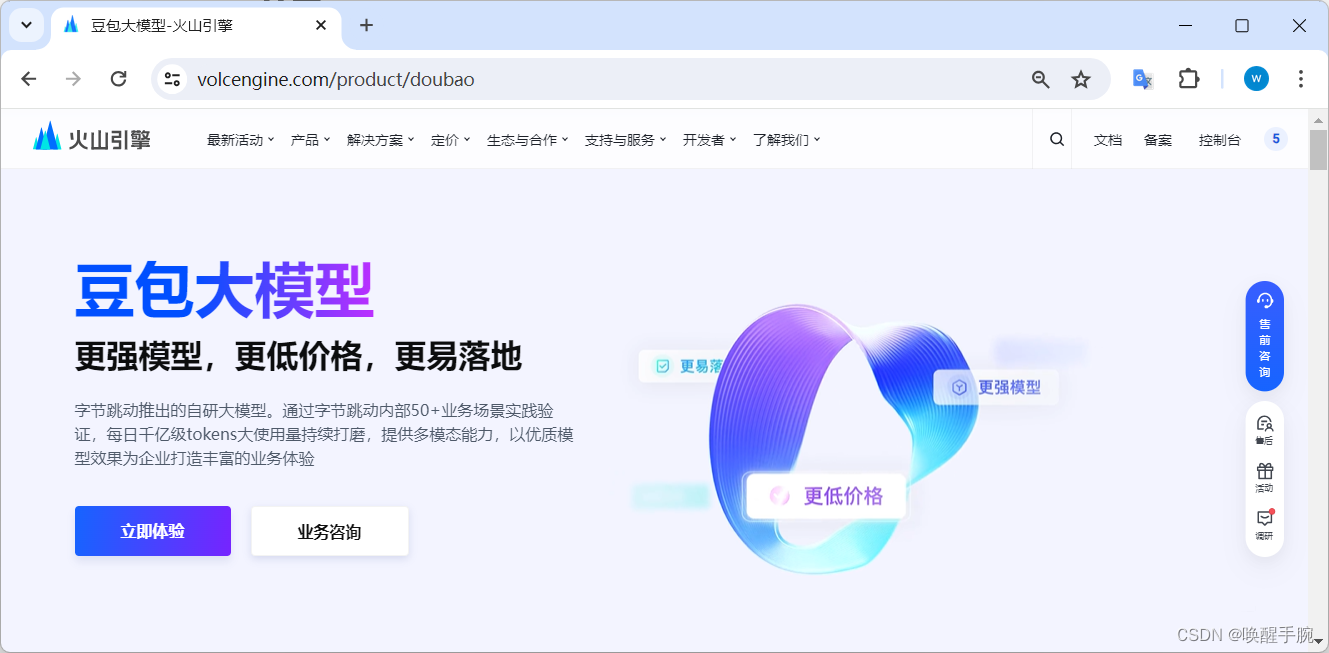
模型控制台
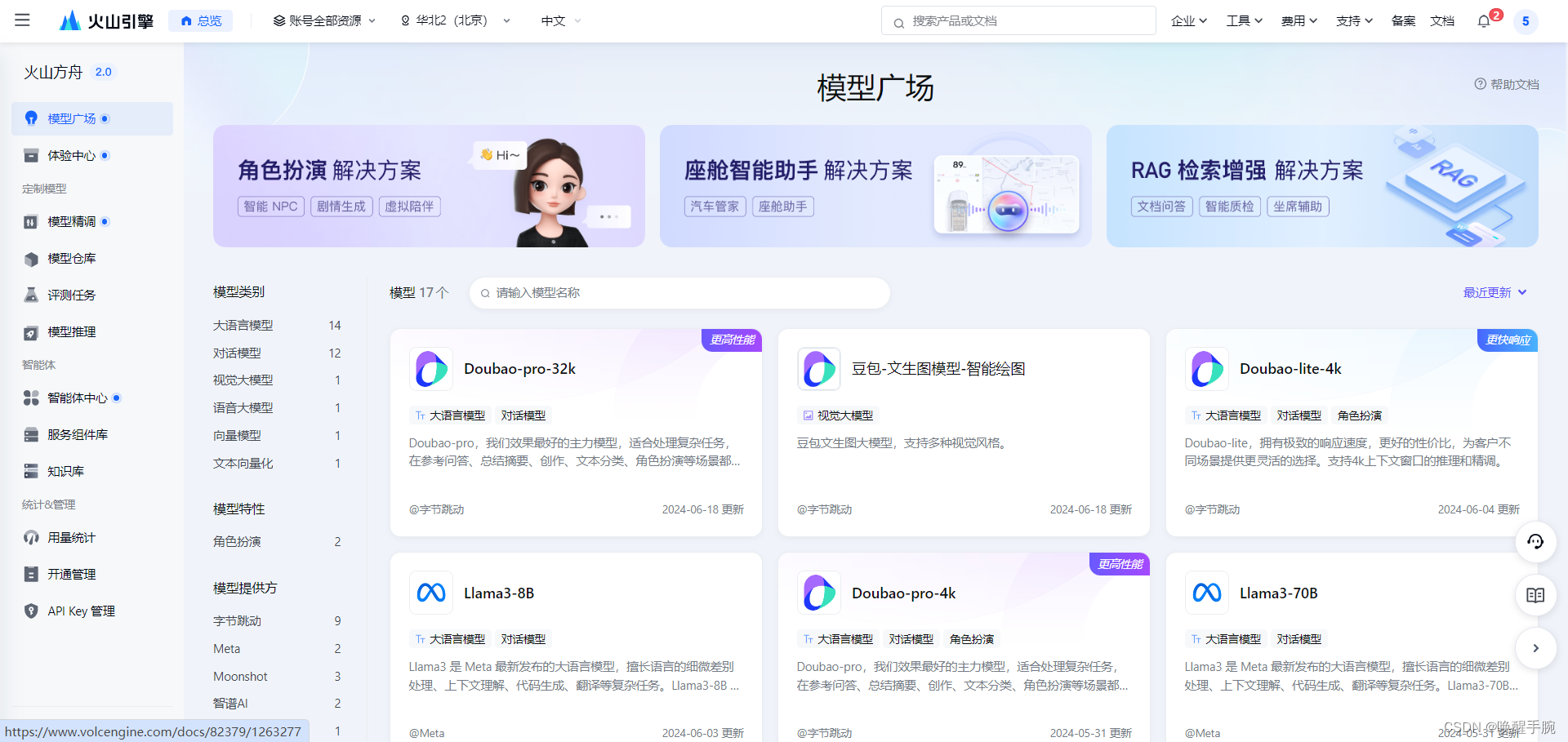
当前模型支持类目
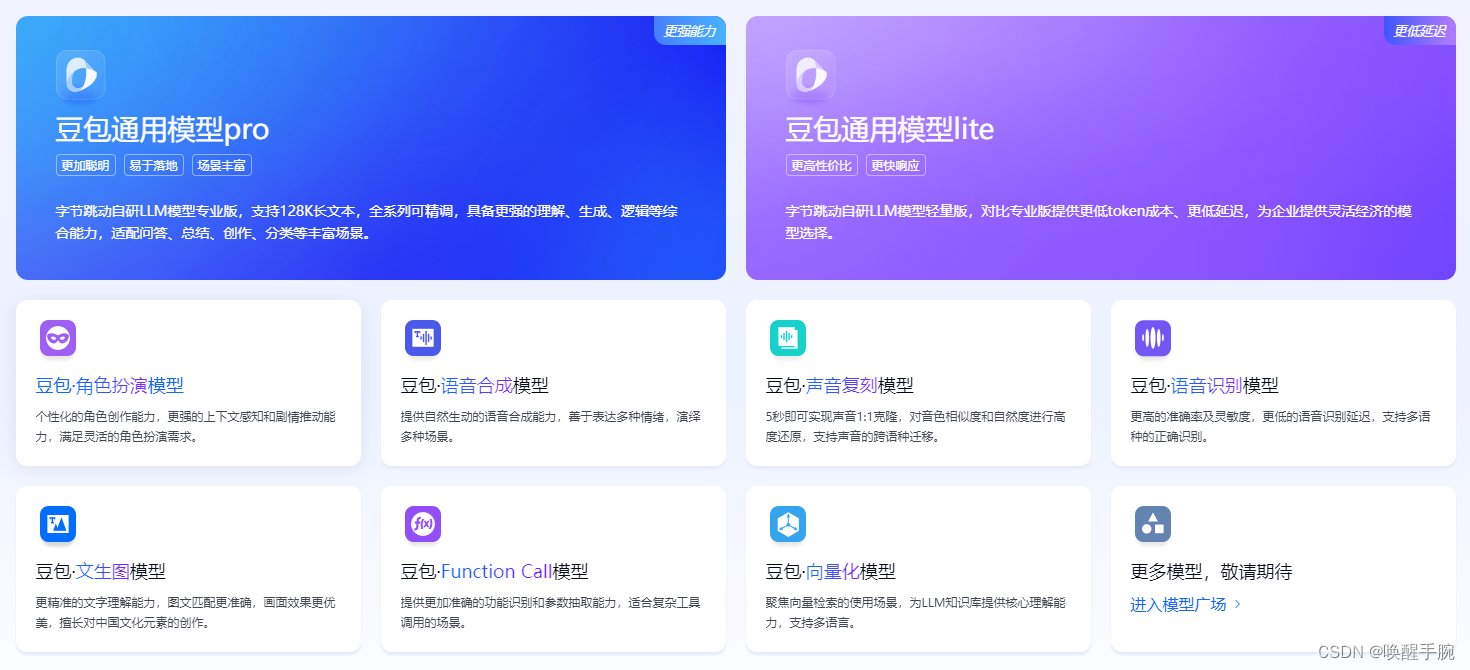
开通模型付费
您可以在 开通管理 页中查看各模型定价与使用限制,开通后使用各模型服务,不同模型的单价不同。其中,大语言模型费用计算方式:费用 = tokens使用量 X 模型 tokens 单价。
Tokens 定义说明: 通常 1 个中文词语、英文单词、数字、符号计为 1 个 token,由于不同模型采用的分词器不同,同一段文本可能会分为不同的 tokens 数量。
安装 SDK 环境
安装火山 python sdk 环境
pip install volcengine-python-sdk
······
note: This error originates from a subprocess, and is likely not a problem with pip.ERROR: Failed building wheel for volcengine-python-sdkRunning setup.py clean for volcengine-python-sdk
Failed to build volcengine-python-sdk
ERROR: Could not build wheels for volcengine-python-sdk, which is required to install pyproject.toml-based projects
解决方案
GitHub 地址:https://github.com/volcengine/volcengine-python-sdk
git clone https://github.com/volcengine/volcengine-python-sdk.git
开始安装 volcengine-python-sdk
python setup.py install --user
在 Python 中,setup.py 是一个常用的脚本文件,用于安装、分发和管理 Python 包。这个文件通常包含setuptools(或distutils)的调用,用于定义包的各种属性和设置。
python setup.py 这部分命令指示Python解释器运行setup.py脚本。
install 这是setup.py的一个常见命令,用于安装定义的Python包。
--user 这是一个选项,指示安装程序将包安装到用户的Python库目录中,而不是全局的Python库目录。
配置 API KEY 鉴权
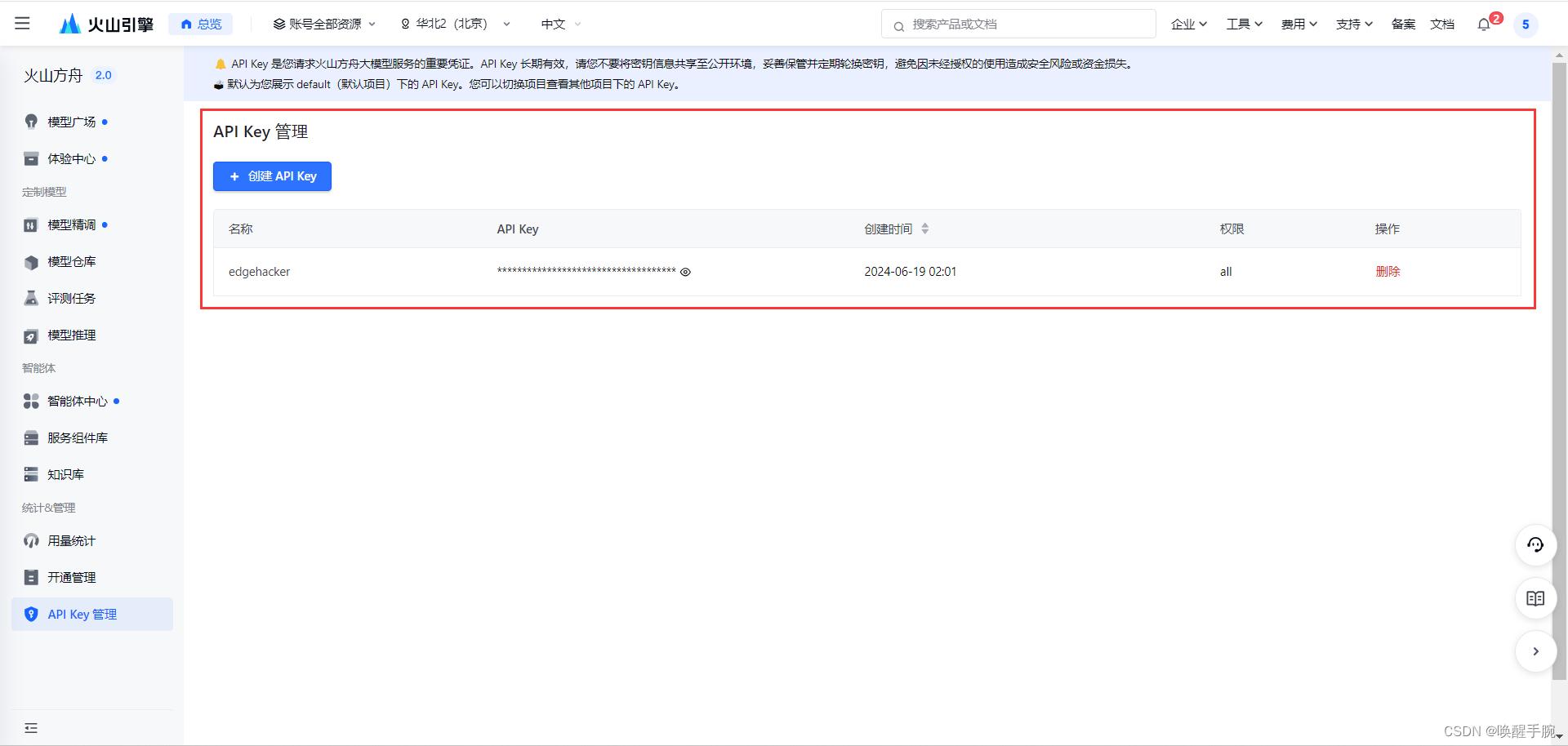
方案一:API 管理页面获取 API KEY
进入 API Key 管理 页面,选择需要的项目,点击 创建 API Key,即可生成长效 API Key。all权限默认给予项目下所有模型接入点和智能体访问权限。地址:https://console.volcengine.com/ark/region:ark+cn-beijing/apiKey
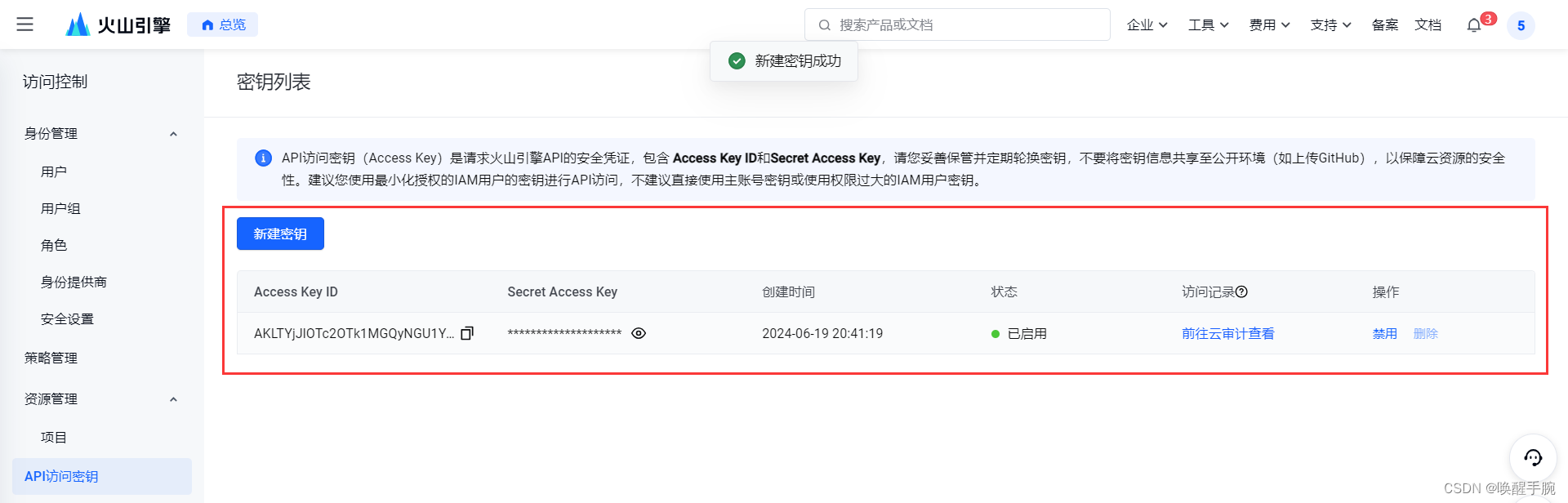
方案二:配置火山引擎 API 的安全凭证
API 访问密钥(Access Key)是请求火山引擎 API 的安全凭证,包含 Access Key ID和Secret Access Key,请您妥善保管并定期轮换密钥,不要将密钥信息共享至公开环境(如上传GitHub),以保障云资源的安全性。建议您使用最小化授权的IAM用户的密钥进行API访问,不建议直接使用主账号密钥或使用权限过大的IAM用户密钥。
访问密钥 Access Key 管理:https://console.volcengine.com/iam/keymanage
方案三:SDK 获取 API KEY
创建推理接入点地址:https://console.volcengine.com/ark/region:ark+cn-beijing/endpoint?current=1&pageSize=10
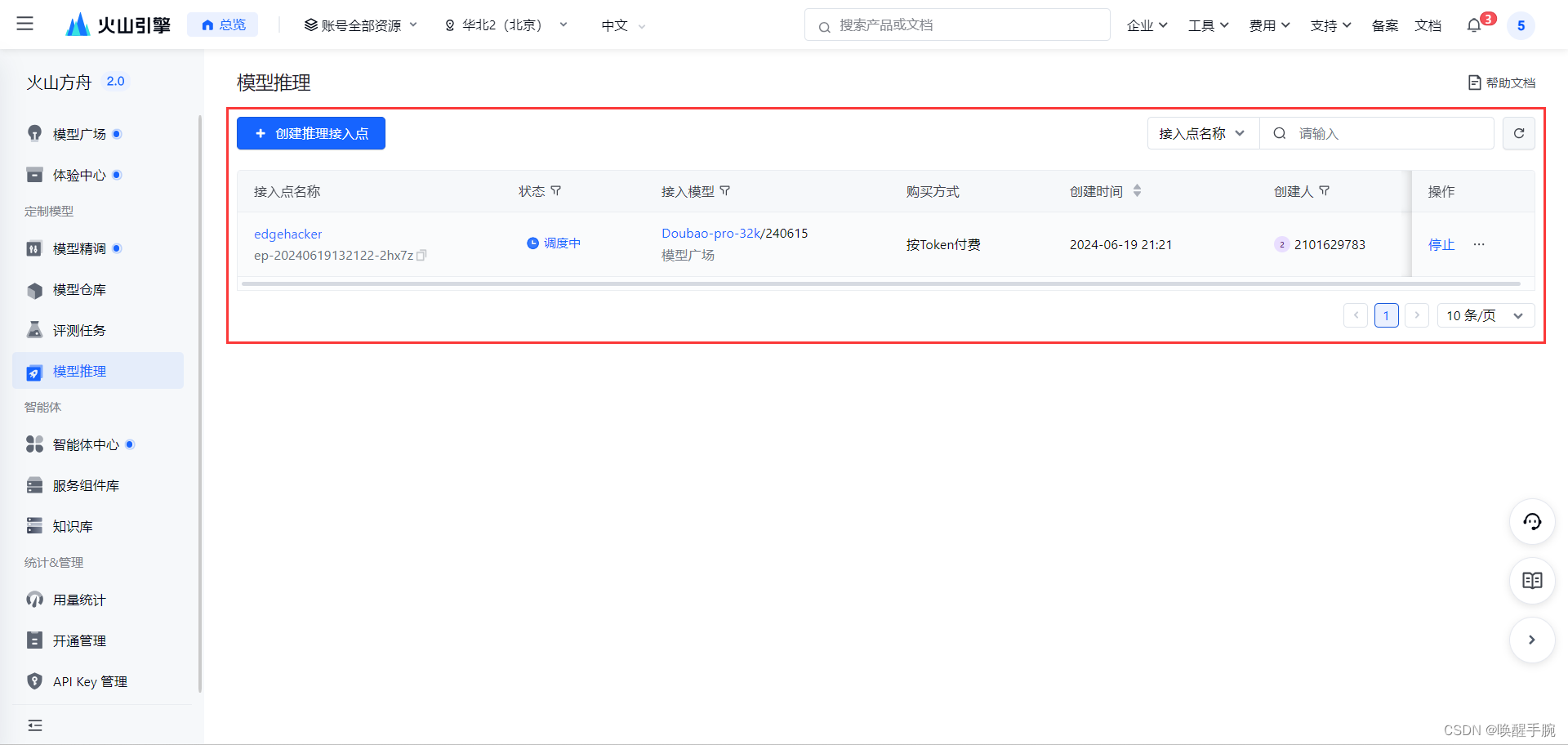
推理接入点读取 ENDPOINT_ID 编号:ep-20240619132122-2hx7z
设置 AK/SK 作为环境变量 .env 配置文件
VOLC_ACCESSKEY=YOUR_AK
VOLC_SECRETKEY=YOUR_SK
ENDPOINT_ID=YOUR_ENDPOINT_ID(例如:ep-20240619132122-2hx7z)
源码预览
from __future__ import print_functionimport osimport volcenginesdkcore
import volcenginesdkark
from pprint import pprint
from volcenginesdkcore.rest import ApiException
import dotenv
dotenv.load_dotenv(".env")if __name__ == '__main__':configuration = volcenginesdkcore.Configuration()configuration.ak = os.getenv("VOLC_ACCESSKEY")configuration.sk = os.getenv("VOLC_SECRETKEY")configuration.region = "cn-beijing"volcenginesdkcore.Configuration.set_default(configuration)api_instance = volcenginesdkark.ARKApi()get_api_key_request = volcenginesdkark.GetApiKeyRequest(duration_seconds=30 * 24 * 3600,resource_type="endpoint",resource_ids=[os.getenv("ENDPOINT_ID")],)try:resp = api_instance.get_api_key(get_api_key_request)pprint(resp)except ApiException as e:print("Exception when calling api: %s\n" % e)
运行结果
{'api_key': '······', 'expired_time': 1721395557}
Ark 模型接口
标准请求 standard request
import osfrom volcenginesdkarkruntime import Ark
import dotenv
dotenv.load_dotenv(".env")client = Ark()completion = client.chat.completions.create(model=os.getenv("ENDPOINT_ID"),messages=[{"role": "system", "content": "你是豆包,是由字节跳动开发的 AI 人工智能助手"},{"role": "user", "content": "常见的十字花科植物有哪些?"},],
)
print(completion.choices[0].message.content)
流式请求 stream request
在 stream 模式下,基于 SSE (Server-Sent Events) 协议返回生成内容,每次返回结果为生成的部分内容片段。内容片段按照生成的先后顺序返回,完整的结果需要调用者拼接才能得到。如果流式请求开始时就出现错误(如参数错误),HTTP返回非200,方法调用也会直接返回错误。如果流式过程中出现错误,HTTP 依然会返回 200, 错误信息会在一个片段返回。
import osfrom volcenginesdkarkruntime import Ark
import dotenv
dotenv.load_dotenv(".env")client = Ark()stream = client.chat.completions.create(model=os.getenv("ENDPOINT_ID"),messages=[{"role": "system", "content": "你是豆包,是由字节跳动开发的 AI 人工智能助手"},{"role": "user", "content": "常见的十字花科植物有哪些?"},],stream=True
)
for chunk in stream:if not chunk.choices:continueprint(chunk.choices[0].delta.content, end="")
文档地址:https://www.volcengine.com/docs/82379/1263512
Prompt 提示词工程
在自然语言处理(NLP)和对话系统中,提示(prompt)通常是指用户输入的文本或问题。通过仔细设计和选择提示,可以指导模型的生成过程,使其更符合用户的需求。Prompt engineering 是指设计和优化提示的过程,以使人工智能模型能够更好地理解用户的意图和要求,并生成更准确、有用的响应。
Prompt Engineering 主要目标
1. 了解如何格式化和设计提示使模型效果最佳。
2. 探索不同 prompt 对模型输出的影响。
3. 创造出能优化模型输出的提示。
注意:一般业务优化的过程,主要包括三个环节,prompt 设计、prompt 优化和 prompt 评测,如下我们分别分三个部分来进行介绍。
限制模型输出格式
最后针对模型的输出,可以限制输出的格式,一方面可以提高可读性,使结果更清晰明了。另一方面也可以方便后续的处理,提高稳定性。以提取“病症”的任务来展示下如何去限制模型的输出格式。要求直接以 json 的格式返回。
请提取参考资料中的所有病症,并且以json格式返回。
回答满足下面的格式要求:
1、以json的格式返回答案,json只包括一个key, key="disease",对应的值为列表,存储参考资料中的病症。
参考资料:
"""
失眠在《内经》中称为“目不瞑”、“不得眠”、“不得卧”,其原因主要有两种:一是其他病症影响,如咳嗽、呕吐、腹满等,使人不得安卧;二是气血阴阳失和,使人不能入寐。中医常用养心安神的方法治疗失眠,既可治标、又可治本,还可以避免西药安眠药容易成瘾的弊端。中医认为,失眠多因脏腑阴阳失调,气血失和所致。正如《灵枢大惑论》中记载:“卫气不得入于阴,常留于阳,留于阳则气满;阳气满则阳娇盛,不得入于阴则阴气虚,故目不瞑矣。”在临床上,治疗失眠应着重调理脏腑及气血阴阳,以“补其不足,泻其有余,调其虚实”,可采取补益心脾、滋阴降火、交通心肾、疏肝养血、益气镇惊、活血通络等治法,使气血和畅,阴阳平衡,脏腑功能恢复正常。
"""
Prompt 优化:模型扮演角色
让模型扮演一个具体的角色,模型的输出会更符合人类的表达方式,从而更容易被人类理解;同时输出也会更加一致。例如,在问答系统中,让模型扮演一个特定领域的专家可以使其回答更符合该领域的知识和语言习惯,从而提高回答的一致性。
比如下面的案例,让模型分别扮演科学家和玄幻小说家生成一篇文章,文章的主题是:“黑洞是如何形成的”。在科学家的角度下,模型基于科学事实首先解释了黑洞是什么,然后回答了黑洞的形成过程;而在玄幻小说家的角度下,模型此时的输出不再基于科学事实,而是完全虚构,并且给人更多神秘的感觉,勾起读者的兴趣。

构造分类接口
def construct_classification_req():req = {"model": {"name": "skylark2-pro-4k", # 这里根据模型不同,设置不同的 model_name"version": "1.1", # 设置调用模型的版本号},"parameters": {"max_new_tokens": 1000, # 输出文本的最大tokens限制"min_new_tokens": 1, # 输出文本的最小tokens限制"temperature": 0.01, # 用于控制生成文本的随机性和创造性,Temperature值越大随机性越大,取值范围0~1"top_p": 0.7, # 用于控制输出tokens的多样性,TopP值越大输出的tokens类型越丰富,取值范围0~1"top_k": 0, # 选择预测值最大的k个token进行采样,取值范围 0-1000,0 表示不生效"max_prompt_tokens": 3000, # 最大输入 token 数,如果给出的 prompt 的 token 长度超过此限制,取最后 max_prompt_tokens 个 token 输入模型。"system_prompt": '', # 系统角色,设定模型的行为和背景,告知模型需要扮演的角色。"repetition_penalty": 1.1 # 重复token输出的惩罚项},"query": "中国的第一个经济特区是?","labels": ["北京", "珠海", "深圳", "厦门", "上海"] # 输出的结果都在labels的选项内}return req
这篇关于2024 年最新 Python 基于火山引擎豆包大模型搭建 QQ 机器人详细教程(更新中)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





