本文主要是介绍多模态融合算法分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
多模态融合算法分析
- 多模态论文
- 多模态融合
- 早期融合
- 晚期融合
- 混合融合
- 模型级融合
- 对比分析
- 早期融合(Feature-level Fusion)
- 晚期融合(Decision-level Fusion)
- 混合融合(Hybrid Fusion)
- ML-LSTM(Multi-layer Long Short-Term Memory)
- 类比理解
- 适合什么医疗场景
- 多模态算法使用流程
多模态论文
https://github.com/pliang279/awesome-multimodal-ml#multimodal-fusion
-
Multimodal Representations (多模态表征)
- Identifiability Results for Multimodal Contrastive Learning, ICLR 2023 [code]
- Unpaired Vision-Language Pre-training via Cross-Modal CutMix, ICML 2022.
- Learning Transferable Visual Models From Natural Language Supervision, arXiv 2020 [blog] [code]
-
Multimodal Fusion (多模态融合)
- What Makes Multi-modal Learning Better than Single (Provably), NeurIPS 2021
- Efficient Multi-Modal Fusion with Diversity Analysis, ACMMM 2021
- Attention Bottlenecks for Multimodal Fusion, NeurIPS 2021
-
Multimodal Alignment (多模态对齐)
- Reconsidering Representation Alignment for Multi-view Clustering, CVPR 2021 [code]
- CoMIR: Contrastive Multimodal Image Representation for Registration, NeurIPS 2020 [code]
-
Multimodal Pretraining (多模态预训练)
- Align before Fuse: Vision and Language Representation Learning with Momentum Distillation, NeurIPS 2021 Spotlight [code]
- FLAVA: A Foundational Language And Vision Alignment Model, arXiv 2021
-
Multimodal Translation (多模态翻译)
- Zero-Shot Text-to-Image Generation, ICML 2021 [code]
- Language2Pose: Natural Language Grounded Pose Forecasting, 3DV 2019 [code]
-
Crossmodal Retrieval (跨模态检索)
- MURAL: Multimodal, Multitask Retrieval Across Languages, arXiv 2021
- Learning with Noisy Correspondence for Cross-modal Matching, NeurIPS 2021 [code]
多模态融合
在多模态融合中,有几种基本的方法来整合不同的信息:
-
特征融合:这是通过结合不同模态(如视觉、听觉等)的数据特征来实现的。
常见的特征融合技术包括:- 加权融合:为不同模态的特征分配不同的权重,并将它们线性组合。
- 级联融合:将不同模态的特征串联起来,形成一个更长的特征向量。
- 拼接融合:直接将不同模态的特征拼接在一起,形成一个更大的特征向量。
-
神经网络融合:这是一种基于深度学习的融合方法。它通过构建多模态神经网络模型,将不同模态的数据输入到不同的网络分支,然后融合这些特征,最终通过全连接层进行分类或回归等任务。常见的神经网络融合方法包括多分支网络、多输入网络和多层融合网络。
-
早期融合和晚期融合:
- 早期融合:在特征级别进行融合,通常是在抽取特征之前就开始融合数据。
- 晚期融合:也称为决策级融合,是在不同模态的模型独立训练后再将它们的结果融合。常用的方法包括规则融合,如最大值融合、平均值融合和贝叶斯规则融合。
-
混合融合:结合了早期和晚期融合的方法,尝试在两者优点的基础上增强模型性能,但同时也增加了模型的复杂性和训练难度。
-
模型级融合:例如ML-LSTM方法,这是一种多层次的LSTM模型,通过考虑不同话语间的关系来处理多模态融合问题。这种方法通常涉及将一个模态的特征先输入一个LSTM层,然后将输出与另一模态的特征结合,输入到下一个LSTM层,以此类推,最终的输出用于预测。
通过这些方法,多模态融合能够有效提高模型对复杂数据环境的适应性和预测准确性。
早期融合
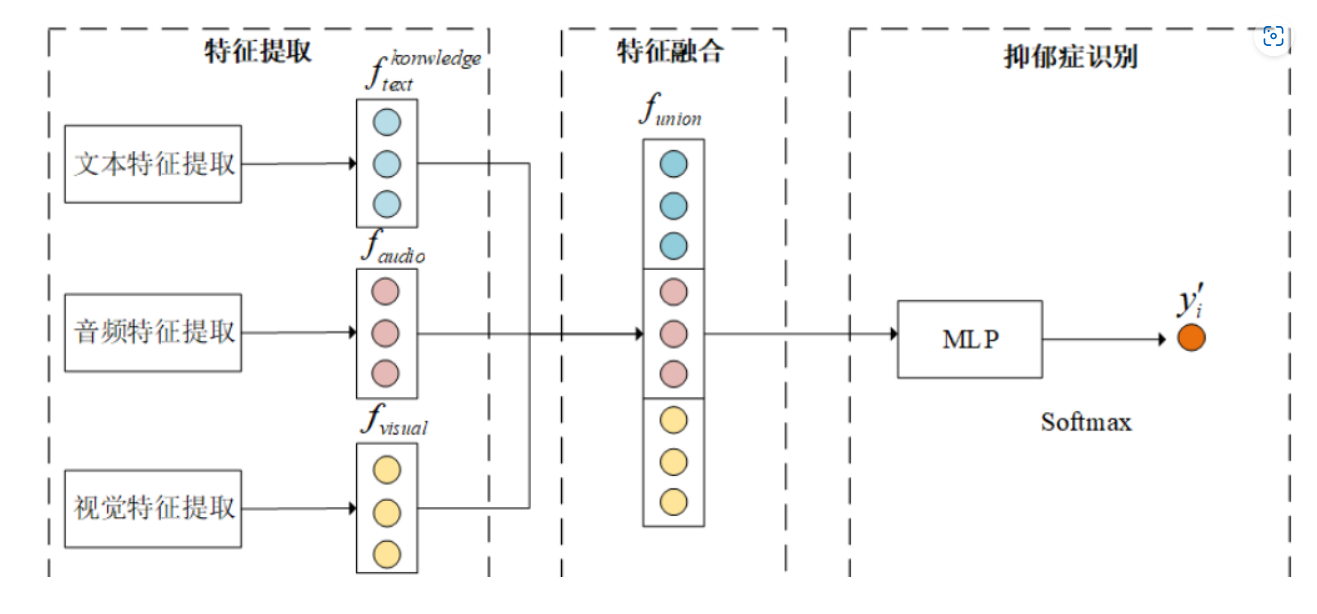
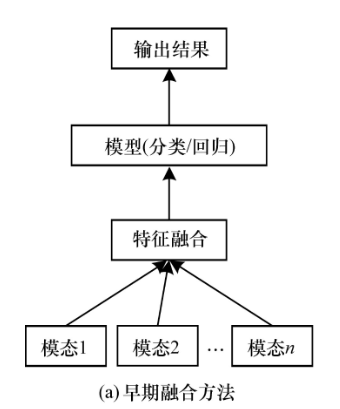
假设我们在开发一个智能监控系统,这个系统需要通过分析视频(视觉数据)和音频(声音数据)来识别特定的情况,比如是否有人在特定区域内大声喊叫。
早期融合的流程:
-
数据收集:
- 视频摄像头捕获视频数据,包括人的移动、表情等视觉信息。
- 麦克风捕获音频数据,如环境声、谈话声音、喊叫声等。
-
特征提取:
- 视频数据:从视频中提取特征,如移动速度、方向、人体姿势等。
- 音频数据:从音频中提取特征,如音量、音调、声音的持续时间等。
-
特征融合(早期融合):
- 在进一步处理和模型训练之前,将视频和音频的特征数据合并到一起。例如,可以将视频中的移动速度特征与音频的音量特征结合,形成一个融合的特征向量。
- 融合的特征向量现在包含了两种模态的信息,使得接下来的分析可以同时考虑视觉和听觉的信息。
-
决策制定:
- 使用深度学习模型(如神经网络)来分析这些融合的特征。
- 模型学习如何根据融合的特征来识别特定的事件,比如识别视频中是否有人在特定情况下大声喊叫。
性能:
- 优点:早期融合允许模型从整体上理解跨模态的关联,可能提高模型对复杂事件的识别能力。
- 挑战:不同模态的数据特性可能非常不同,直接融合这些特征可能导致信息的不一致性,处理这种不一致性是早期融合的一大挑战。
通过在较低层次(特征层次)将信息整合,为决策提供更丰富的数据基础。
晚期融合
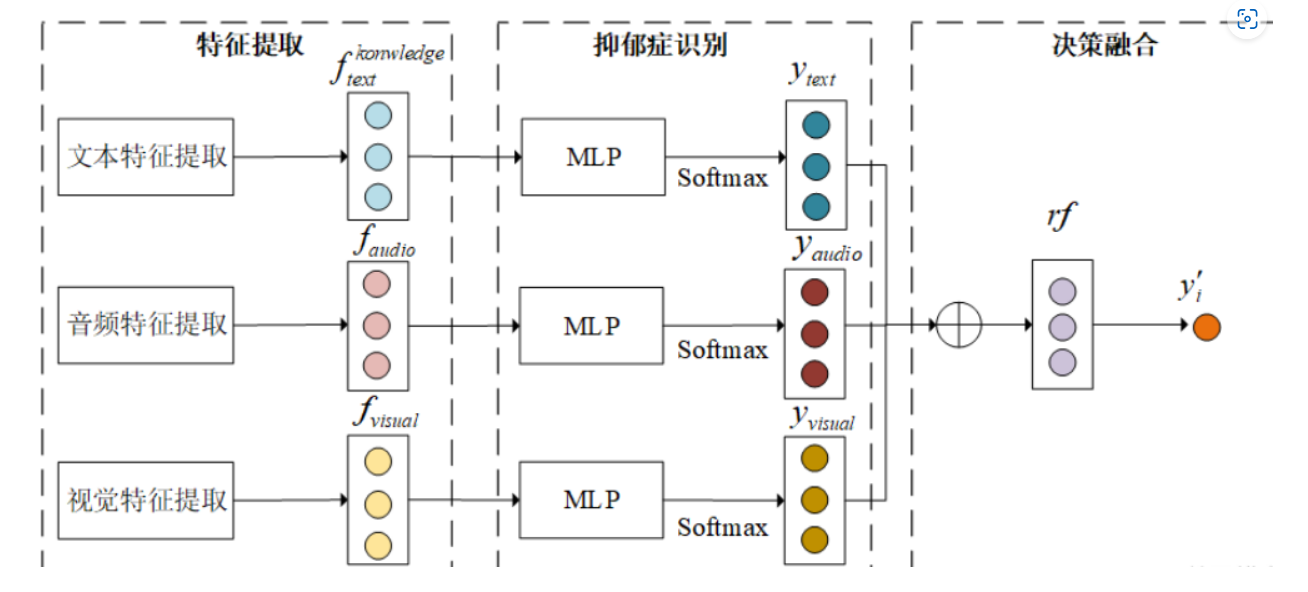
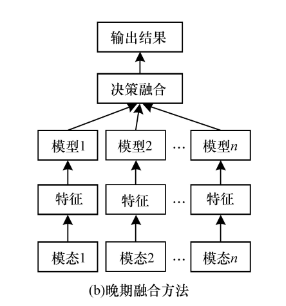
-
模态独立训练:
- 视觉模型:使用来自监控摄像头的视频数据,训练一个模型来检测区域内人的活动,比如人的位置、移动速度等。
- 音频模型:使用麦克风捕获的音频数据,训练一个模型来识别声音的类型和音量,尤其是监测尖叫或大声喊叫。
-
模型输出:
- 视觉模型可能输出人是否在监控区域内移动,以及他们的移动速度和行为模式。
- 音频模型可能输出当前环境中的声音级别,并且特别标注是否检测到喊叫声。
-
决策级融合:
- 最大值融合:如果任何一个模型强烈指示有异常(例如,音频模型检测到非常大的声音),则系统可能直接发出警报。
- 平均值融合:系统可能计算两个模型输出的平均“警觉级别”,来决定是否需要响应。如果平均值超过某个阈值,则发出警报。
- 贝叶斯规则融合:在有先验知识的情况下,例如该区域晚上通常很安静,可以使用贝叶斯方法根据视觉和声音数据来估计喊叫发生的概率。
假设系统监控一个公园,通常在夜间关闭。一晚,监控视频显示有一人急速跑动,同时麦克风检测到高音量的喊叫。下面是决策级融合的步骤:
- 视觉模型输出:人物快速移动。
- 音频模型输出:检测到高分贝喊叫。
- 决策级融合(使用最大值融合):由于两个模型中至少有一个显示异常情况(高分贝喊叫),系统决定触发报警并通知安全人员。
这种决策级融合方法使得系统能够更全面地利用多种数据源,减少错误报警的可能性,同时确保在真正的紧急情况下能快速做出反应。
通过结合多个独立模型的决策,可以更有效地处理复杂或不确定的情况。
混合融合
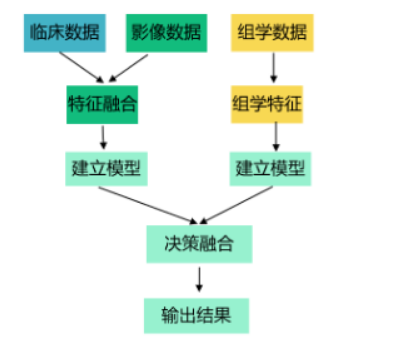
-
早期融合:
- 特征提取:从视频中提取运动特征(如人物移动速度和方向)和从音频中提取声学特征(如音量和音调)。
- 特征级融合:将提取的视频和音频特征早期结合,例如通过拼接或加权平均,创建一个综合的特征向量。这样做可以让后续的模型学习到不同模态之间的相互关系,提高特征的表达能力。
-
模型训练:
- 使用这些综合的特征向量来训练一个或多个深度学习模型,这些模型可以是卷积神经网络(CNN)或循环神经网络(RNN)等,以识别具体的行为模式,如大声喊叫。
-
晚期融合:
- 单独模型处理:同时,也可以保留一些独立模型来处理单一模态的数据。例如,一个专门处理音频的模型可能专注于声音的突发高峰,而视频模型则专注于异常运动检测。
- 决策级融合:将这些模型的输出(从早期融合训练的模型和单独模态的模型)进行晚期融合,如使用投票系统、最大值选择或概率统计方法来最终决定是否有人在区域内大声喊叫。
假设一个公园的监控系统在夜间捕捉到以下情况:
- 视频数据:显示有人在公园内快速移动。
- 音频数据:捕捉到突然的高分贝声音。
这些数据通过早期融合生成的特征被用来训练模型,模型可能预测出高运动活动与高分贝声音往往关联着紧急情况。与此同时,单独的音频模型也可能只因为高分贝声音而触发警报。通过晚期融合这些输出,如果两种或多种模型均指示潜在的安全问题,系统最终决定发出警报并通知安全人员。
这种混合融合方法结合了早期和晚期融合的优势,提高了预测的准确性和可靠性,尽管增加了模型的复杂性和训练难度。
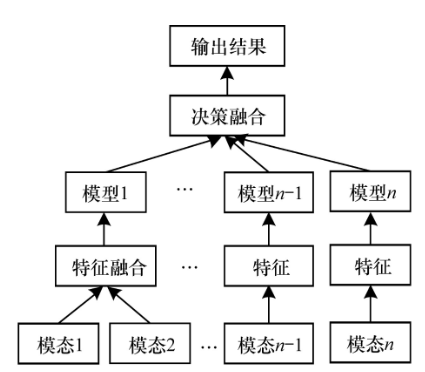
模型级融合

一个多模态融合神经网络模型的结构,用于处理和融合来自不同感知模态(如文本、音频和视觉)的数据。
模型使用了多层LSTM(长短期记忆网络)来逐步融合各个模态的信息。
-
第一层(Layer1):
- 输入文本数据,使用LSTM处理文本信息。
- 输出表示文本特征的 ( f t 1 ) ( f_t^1 ) (ft1),此特征是经过第一层LSTM处理后的结果。
-
第二层(Layer2):
- 将第一层的输出 ( f t 1 ) ( f_t^1 ) (ft1) 与音频特征 ( f a u d i o ) ( f_{audio} ) (faudio) 拼接,然后输入到第二层的LSTM。
- 输出表示文本和音频融合后的特征 ( f t 2 ) ( f_t^2 ) (ft2)。
-
第三层(Layer3):
- 将第二层的输出 ( f t 2 ) ( f_t^2 ) (ft2) 与视觉特征 ( f v i s u a l ) ( f_{visual} ) (fvisual) 拼接,然后输入到第三层的LSTM。
- 输出表示文本、音频和视觉三种模态融合后的特征 ( f t 3 ) ( f_t^3 ) (ft3)。
-
Softmax层:
- 将第三层的输出特征 ( f t 3 ) ( f_t^3 ) (ft3) 输入到一个Softmax层,用于最终的分类或预测。
- 输出 ( y i ′ ) ( y_i' ) (yi′) 是模型基于融合的多模态数据做出的预测结果。
假设一个场景,监控系统安装在一个公共场所,如火车站或购物中心,需要实时监控并识别安全威胁,如紧急情况下的喊叫。
-
第一层LSTM(Layer1):
- 输入:从摄像头捕获的视频序列中提取的文本信息,例如通过读唇技术识别的对话或背景广告板上的文字。
- 处理:第一层LSTM处理这些文本数据,提取时间序列特征,如文本内容的变化和语境。
- 输出:得到的隐藏层状态 ( f_t^1 ) 表示经过时间序列分析的文本特征。
-
第二层LSTM(Layer2):
- 输入:将第一层的输出 ( f_t^1 ) 与从麦克风捕获的音频特征(如声音的音调、音量等)拼接。
- 处理:第二层LSTM分析这些融合的文本和音频信息,学习识别声音和相关文本之间的关联。
- 输出:产生的特征 ( f_t^2 ) 包括了文本和音频的综合信息,如对话内容与声音紧急程度的关联。
-
第三层LSTM(Layer3):
- 输入:将第二层的输出 ( f_t^2 ) 与视觉数据特征(如人群密度、运动速度等)拼接。
- 处理:第三层LSTM进一步分析从文本、音频和视频融合的数据中的模式,如在特定视觉场景下的紧急声音事件。
- 输出:最终的特征 ( f_t^3 ) 表现出高度融合的多模态数据,可用于精确预测特定事件。
-
Softmax层:
- 处理:使用Softmax层来分类最终的特征 ( f_t^3 ),判断是否存在安全威胁,如大声喊叫。
- 输出:模型预测的结果 ( y_i’ ),例如是否有人在特定区域内大声喊叫。
对比分析
在多模态数据融合领域中,我们可以通过对比和类比来更好地理解早期融合、晚期融合、混合融合和ML-LSTM这四种方法的特点与适用场景:
早期融合(Feature-level Fusion)
定义:在模型的输入阶段就开始融合不同来源的数据,通常通过直接结合不同模态的特征向量来进行。
优点:
- 可以利用原始数据中的所有相关信息,允许模型学习跨模态特征之间的复杂关系。
- 通常能够提高模型的表现,尤其是在各模态数据高度相关的情况下。
缺点:
- 需要所有数据模态同时可用,处理同步问题可能较复杂。
- 当不同模态数据的特征空间差异很大时,性能可能不理想。
晚期融合(Decision-level Fusion)
定义:在模型的输出阶段进行融合,即独立训练每个模态的模型,然后合并这些模型的输出来做最终的决策。
优点:
- 模型训练简单,每个模态可以独立优化。
- 错误隔离,不同模态的错误不会相互影响。
缺点:
- 无法利用不同模态间的内在联系来增强模型表现。
- 对模型的最终表现高度依赖于单个模型的性能。
混合融合(Hybrid Fusion)
定义:结合了早期和晚期融合的优点,通过在不同的处理阶段融合数据,既可以在特征层面进行融合,也可以在决策层面进行融合。
优点:
- 灵活性高,可以根据需要选择融合阶段,优化模型性能。
- 可以处理更复杂的数据和任务,如在某些层面进行特征融合而在其他层面进行决策融合。
缺点:
- 增加了模型的复杂性和训练难度。
- 需要更精细的模型设计和参数调优。
ML-LSTM(Multi-layer Long Short-Term Memory)
定义:一种特殊的混合融合方法,使用多层LSTM网络逐层处理并融合不同模态的数据,每一层增加新模态的信息。
优点:
- 强大的时序数据处理能力,特别适合处理视频、音频等连续数据。
- 通过逐层融合,可以深入挖掘跨模态的相关性和互补信息。
缺点:
- 训练复杂且计算资源消耗较大。
- 需要精心设计网络结构以避免过拟合和梯度消失问题。
类比理解
将这四种方法比作不同的厨艺技巧:
- 早期融合像是混合烘焙,把所有原料(特征)一开始就混合在一起,让蛋糕(模型)的每一部分都有相同的味道。
- 晚期融合像是分菜烹饪,每道菜(模态)单独烹饪,最后一起上桌,食客(决策层)根据菜品组合来决定最终
的口味。
- 混合融合则像是组合烹饪,某些原料先混合,某些后混合,灵活调整以达到最佳口感。
- ML-LSTM则像是分层烘焙,每层蛋糕独自添加新的原料(模态),每层都有自己独特的风味,最后组成一个多层次的整体蛋糕。
这种对比和类比可以帮助更好地理解每种方法的特性和应用场景。
适合什么医疗场景
- 早期融合(Feature-level Fusion)
- 能够在数据处理的最初阶段捕捉和整合来自不同源(如影像、生化指标)的复杂和互补信息。
适用场景:
- 疾病早期诊断:当需要从多种诊断工具(如MRI、CT、生化分析等)中综合特征以提早发现疾病迹象时,早期融合非常有用。例如,在癌症诊断中,同时分析图像数据和分子生物标志物可以提供更全面的病情分析。
- 个体化治疗计划:结合基因数据、临床症状和生活方式数据,提前准备个性化的治疗方案。
- 晚期融合(Decision-level Fusion)
- 独立模型的输出可以在决策阶段集成,减少单一数据源带来的偏见和误差。
适用场景:
- 复杂病例的多专家会诊:在需要多个专家独立评估患者情况后做出集体决策的场景中,晚期融合可以整合每位专家的意见(可能来自不同的诊断模块),以形成最终的治疗方案。
- 稳健的诊断系统:在诊断系统必须处理高度不确定性或易受单一模型错误影响的情况下,晚期融合能增强诊断的准确性和可靠性。
- 混合融合(Hybrid Fusion)
- 结合早期和晚期融合的优点,使得融合过程更加灵活和动态,适应各种复杂场景。
适用场景:
- 多阶段疾病监测:对于慢性疾病管理,如糖尿病或心血管疾病,混合融合可以在初步筛选时使用早期融合捕获关键生物标志物,而在后续的个性化治疗调整阶段采用晚期融合整合更多维度的临床信息。
- 研究和实验室测试:在开发新的药物或治疗方案时,混合融合方法可以用来分析实验数据和临床试验结果,提高研究的有效性和效率。
- ML-LSTM(Multi-layer Long Short-Term Memory)
- 优于处理时间序列数据,能够学习长期依赖关系,适合连续监测和动态预测。
适用场景:
- 病情进展的动态监测:ML-LSTM非常适合处理时间序列数据,如监测ICU病人的生命体征或心电图(ECG)数据。通过分层分析,可以实时预测病情的变化趋势,提早介入治疗。
- 长期健康数据分析:用于分析患者长期的健康记录和生活习惯数据,预测疾病风险和优化长期治疗方案。
多模态算法使用流程
- 看自己的项目需要哪些模态数据(临床数据、医学影像、基因数据、电子病历、动态医学影像、脑电心电等)
- 选择特征提取的方法(pyradiomics提取图片特征变结构化数据,神经网络对任意数据提取特征)
这篇关于多模态融合算法分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







