本文主要是介绍摩根大通研究论文:大型语言模型+自动规划器用来作有保障的旅行规划,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

【摘要】旅行规划是一项复杂的任务,涉及生成一系列与访问地点相关的动作序列,需要满足约束条件并最大化某些用户满意度标准。传统方法依赖于以给定形式语言表示问题,从网络来源中提取相关的旅行信息,并使用适当的问题求解器生成有效解决方案。作为替代方案,最近基于大型语言模型(LLM)的方法直接使用自然语言从用户需求中输出计划。虽然LLM拥有广泛的旅行领域知识,并能提供诸如兴趣点和潜在路线等高层信息,但当前最先进的模型生成的计划往往缺乏一致性,无法完全满足约束条件,也无法保证生成高质量的解决方案。我们提出了TRIP-PAL,一种结合LLM和自动规划器优势的混合方法,其中(i)LLM获取旅行信息和用户信息并将其转化为可输入规划器的数据结构;(ii)自动规划器生成保证满足约束条件并优化用户效用的旅行计划。我们在各种旅行场景下的实验表明,TRIP-PAL在生成旅行计划方面优于单独使用LLM。
原文:TRIP-PAL: Travel Planning with Guarantees by Combining Large Language Models and Automated Planners
地址:未知
代码:未知
出版:未知
机构: 摩根大通人工智能研究组, 卡洛斯三世大学
1 研究问题
本文研究的核心问题是: 如何结合大型语言模型和自动规划器的优势,提供具有保障的旅行规划服务。
::: block-1
以一个游客计划去巴黎旅行为例。游客希望在一天内游览卢浮宫、埃菲尔铁塔等著名景点。如果只是询问ChatGPT这样的大语言模型,它可能会根据旅游知识库推荐一些热门景点和大致游览顺序。但它很难精准考虑实际的交通时间、开放时间、游览时长等细节约束,导致生成的行程表往往不太具有可执行性。而传统的旅行规划系统虽然能严格满足约束生成可行方案,但需要耗费大量人力将知识抽象为形式化语言,灵活性不足。理想的解法是将大语言模型海量知识与规划系统的逻辑推理能力结合起来,既减少了人工知识抽象的开销,又能兼顾旅行计划的可执行性和最优性。
:::
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
- 传统的旅行规划系统需要以形式化语言(如PDDL)来表示问题,人工知识抽取和建模的成本很高
- 大语言模型拥有丰富的旅游领域知识,能够灵活地分析用户需求并提供一些高层次的推荐,但很难处理硬约束和优化问题
- 需要在知识表达的灵活性和解的可靠性之间权衡,同时算法要尽可能减少与大语言模型的交互开销
针对这些挑战,本文提出了一种高效结合了大语言模型和规划器的"TRIP-PAL"方法:
::: block-1
TRIP-PAL的核心思想是让大语言模型和规划器各司其职、互补长短。具体来说,TRIP-PAL先利用对话式LLM从用户查询中提取旅行相关的原始信息,如感兴趣的景点、对景点的偏好程度、交通方式等。然后,将这些信息翻译成规划器可接受的数据结构,如将景点偏好映射为数值化的效用函数。接着,规划器以此为输入,考虑各种实际约束(如游览时间、开放时间、交通时间等),搜索出一个最大化用户效用的最优旅行计划。这种解耦合的架构充分利用了大语言模型强大的自然语言理解能力和知识库,又通过规划器来保障方案的可行性和最优性。
就像一个懂行的导游,先根据客户的口头描述迅速规划出一条大致的游览路线,再把安排交给一个细心的行程管家,考虑各种细节把初步方案优化为一份精准的旅行指南。
TRIP-PAL的创新之处在于,它将大语言模型视为"导游",将规划器视为"管家",让各自擅长的模块分别负责用户交互和约束求解,达到了1+1>2的效果。同时通过精心设计LLM和规划器之间的接口,既减少了不必要的信息交换开销,又最大程度保留了两个模块原有的特性和性能。
:::
2 研究方法
本文提出了一种名为TRIP-PAL的旅行规划混合方法,结合大型语言模型(LLM)和自动化规划器的优势,为用户生成最优可行的旅行计划。总体流程如图1所示,主要包括以下三个步骤:利用LLM提取旅行信息、构建自动规划问题、求解规划问题生成旅行计划。下面依次介绍。
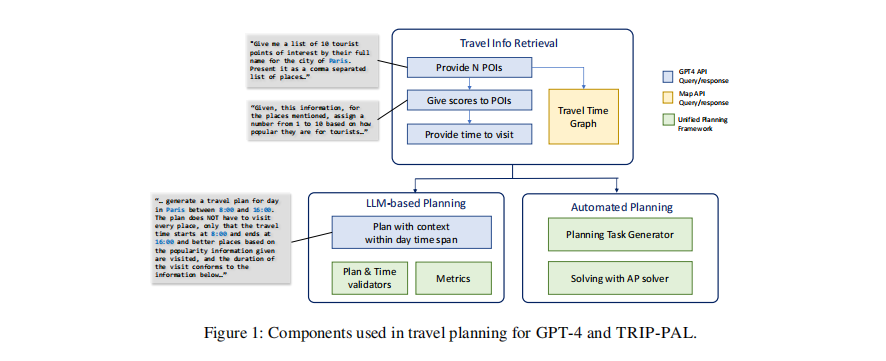
2.1 利用LLM提取旅行信息
首先,TRIP-PAL利用LLM(本文使用GPT-4)与用户进行交互,获取用户的旅行需求和偏好,并提取所需的关键信息。举个例子,用户可能会说"我想去巴黎玩5天,对艺术感兴趣,希望去参观一些知名博物馆和美术馆"。TRIP-PAL通过一系列提示,引导GPT-4从中提取出关键信息:
- 旅游目的地城市 C C C,如巴黎
- 感兴趣的景点(POI)类型,如博物馆、美术馆
- 希望旅行的总时长 H H H,如5天
- 希望获得的景点数量 N N N,如10个
然后,TRIP-PAL再次提示GPT-4,让其结合已有的旅游领域知识,给出在目的地城市 C C C 中符合用户偏好的 N N N 个推荐景点,并附上每个景点的受欢迎程度打分(1-10分) u i u_i ui 作为景点效用值,以及推荐游玩时长 t i t_i ti。这就好比一个旅游达人在了解你的喜好后,迅速给出他的推荐清单。
最后,TRIP-PAL从其他数据源如谷歌地图API获取这 N N N 个景点间的通勤时间估计 c i j c_{ij} cij。
至此,我们提取并准备好了构建旅行规划问题所需的所有信息,包括:
- 候选景点集合 P = { p 1 , … , p N } P=\{p_1,\dots,p_N\} P={p1,…,pN}
- 每个景点的效用值 u i u_i ui 和推荐游玩时长 t i t_i ti
- 景点间的通勤时间 c i j c_{ij} cij
2.2 构建自动规划问题
有了上一步提取的信息,TRIP-PAL将其转化为一个形式化的自动规划问题。规划问题定义了规划领域(动作的前置条件和效果等)和规划实例(初始状态、目标状态等),通常采用PDDL语言描述。
在我们的旅行规划问题中,规划领域包含以下动作:
- Visit(?loc, ?t0, ?visit-time, ?tf): 在位置?loc参观?visit-time时长,从时间?t0到?tf
- Move(?from, ?to, ?t0, ?move-time, ?tf): 从位置?from移动到?to,从?t0开始,历时?move-time
这些动作的前置条件确保游客在对的时间在对的地点,而效果则改变了当前时间和位置。
规划实例的初始状态为旅行开始的时间(如8:00)和地点,以及景点信息(如效用值 u i u_i ui、游览时间 t i t_i ti、通勤时间 c i j c_{ij} cij 等)。目标状态要求达到旅行结束时间(如18:00)。
在目标规划问题中,TRIP-PAL还需考虑oversubscription(过度需求)的情况,即不可能访问所有景点。直觉上,如果我们让GPT给出50个甚至更多巴黎的旅游景点,一天是不可能全部游览的。因此并非所有访问景点的目标都必须满足。本文按照Keyder等人提出的编译方法,引入人工动作避免未访问景点的惩罚,并优化目标函数。
最终,TRIP-PAL得到了一个完整的PDDL表示的过度需求自动规划问题,要求在时间约束下选择一组景点,使得访问景点的效用总和最大。
2.3 求解规划问题生成旅行计划
为了高效求解上一步构建的规划问题,TRIP-PAL采用Unified Planning框架中提供的Fast Downward规划器和LMCUT启发式函数。该方法可以找到一个最优的满足时间约束的可行计划。
最终得到的旅行计划会明确告知游客:
- 在给定的时间限制(如5天)内
- 每天从几点到几点
- 去哪些景点参观(选自候选集合 P P P)
- 每个景点参观多长时间
- 景点之间如何通勤
使得在满足时间约束的情况下,访问的景点效用总和最大。
具体来说,还是以去巴黎旅行5天为例。TRIP-PAL最终可能给出如下计划:
第一天(总时长8小时):
- 8:00-10:00 参观卢浮宫博物馆(2小时)
- 10:00-10:30 从卢浮宫步行至奥赛博物馆(0.5小时)
- 10:30-12:00 参观奥赛博物馆(1.5小时)
- 12:00-14:00 午餐休息(2小时)
- 14:00-14:30 从奥赛博物馆乘车至凯旋门(0.5小时)
- 14:30-15:30 参观凯旋门(1小时)
- 15:30-16:00 从凯旋门乘车至埃菲尔铁塔(0.5小时)
- 16:00-18:00 参观埃菲尔铁塔(2小时)
第二天(总时长7.5小时):
- …
以此类推,直到满足5天的旅行时间。该计划保证满足所有时间约束,并在可选景点中根据效用最大化原则做出选择。
与直接让LLM生成计划不同,TRIP-PAL利用LLM提取用户偏好和推荐候选景点,再将其编码进规划器求解,保证了计划的可行性、最优性和可解释性,帮助用户做出明智的旅行决策。
3 实验
3.1 实验场景介绍
本文提出了一种结合大语言模型(LLM)和自动规划器的混合方法TRIP-PAL用于旅行规划。实验主要对比了GPT-4和TRIP-PAL在不同规模的一日游规划任务上生成的旅行规划的质量。
3.2 实验设置
- Datasets:从GPT-4生成的热门和冷门旅游城市中随机抽取20个,每个城市随机生成5组兴趣点集合,共100个规划任务
- Baseline:GPT-4
- Implementation details:
- TRIP-PAL以Fast Downward作为自动规划器,使用SEQ-OPT-LMCUT配置,运行在4GB RAM的EC2 T3实例上
- 单日旅游时长为8小时,时间离散化为15分钟的时隙
- metric:
- 规划可行性:检查GPT-4生成的规划是否满足动作可执行性和时间约束
- 规划效用:旅行规划访问的兴趣点的效用之和
- 运行时间:生成一个旅行规划所需的时间(秒)
3.3 实验结果
3.3.1 实验一、标准的一日游规划

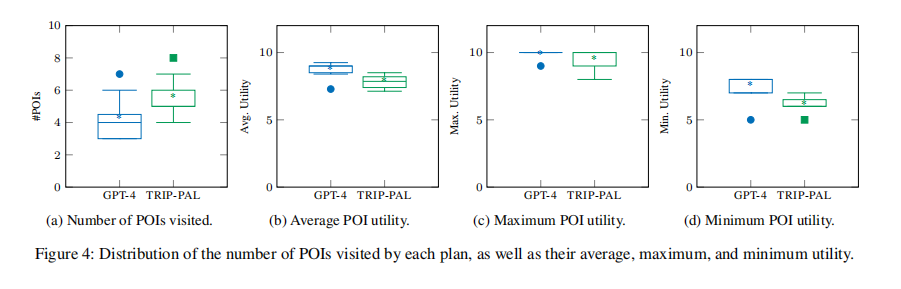
目的:对比GPT-4和TRIP-PAL在100个标准一日游规划任务(8小时旅游,10个候选兴趣点)上生成的规划的质量
涉及图表:图3a、图3b、图4
实验细节概述:对比了两种方法在100个任务上生成规划的效用,以及有效规划的比例。另外统计了访问兴趣点的数量分布以及最大、最小和平均效用。
结果:
- TRIP-PAL在所有任务上生成的规划效用都高于GPT-4。GPT-4只有14%的规划满足所有约束,主要违反访问时长、旅行时长等硬约束。即使去掉约束检查,TRIP-PAL仍在79%的任务上超过GPT-4。
- TRIP-PAL平均访问5.5个兴趣点,GPT-4仅4.2个。GPT-4倾向选择访问效用最高的3-5个点,导致平均效用略高,但TRIP-PAL能在满足约束下多覆盖一些次高效用的点,从而使整体旅行效用最大化。
3.3.2 实验二、扩展性分析

目的:考察GPT-4和TRIP-PAL生成规划的性能随问题规模(兴趣点数量、旅游时长)的变化趋势
涉及图表:图5
实验细节概述:固定旅游时长8小时,兴趣点从8个增加到18个;或固定10个兴趣点,旅游时长从6小时增加到10小时。对比GPT-4规划的有效性和次优率,以及TRIP-PAL相比GPT-4的额外耗时。
结果:
- 随兴趣点数量增加,GPT-4生成有效规划的比例急剧下降,次优率也逐渐升高并稳定在1.6倍左右。这表明GPT-4很难处理过量订阅(over-subscription)问题,不能很好地权衡旅行约束和整体效用最大化。
- 相比GPT-4,TRIP-PAL在10个以内兴趣点时运行时间基本一致,超过10个后额外耗时逐渐上升,最多需要800秒。这主要是解决过量订阅问题的复杂度导致的。
- 随旅游时长增加,GPT-4规划有效性逐渐下降,但次优率变化不明显。TRIP-PAL运行时间也基本一致。这表明该因素对两种方法的影响不如兴趣点数量大。
4 总结后记
本论文针对旅行规划问题,提出了一种结合大语言模型(LLM)和自动规划器(automated planner)的混合方法TRIP-PAL。该方法利用LLM从用户需求中提取相关的旅行信息,并将其转化为规划器可接受的形式。之后,规划器在满足各种约束条件的前提下,生成最大化用户效用的最优旅行计划。实验结果表明,与单纯使用GPT-4相比,TRIP-PAL生成的旅行计划在可执行性和用户满意度方面都有显著提升。
::: block-2
疑惑和想法:
- 除了旅行规划,TRIP-PAL的框架是否可以应用于其他需要满足复杂约束的领域,如会议日程安排、供应链优化等?
- 在提取旅行信息时,是否可以引入知识图谱等外部知识源,进一步增强LLM的理解和表达能力?
- 如何设计更加个性化的用户效用函数,使得生成的旅行计划更加贴合用户的偏好和需求?
:::
::: block-2
可借鉴的方法点: - 利用LLM进行信息抽取和转化,再结合领域特定的优化工具进行求解的思路值得借鉴,可以扩展到更多实际应用场景。
- 将过约束问题转化为软目标规划问题的技巧可以应用于其他资源受限的任务,提高求解的灵活性。
- 通过discretization和编码技巧简化问题表示的方法可以借鉴,使得规划器能够高效地处理更复杂的实际约束。
:::
这篇关于摩根大通研究论文:大型语言模型+自动规划器用来作有保障的旅行规划的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









