本文主要是介绍使用星鸾云GPU云服务器搭配Jupyter Lab,创建个人AI大模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近我们公司IT部门宣布了一个大事情,他们开发了一款内部用的大模型,叫作一号AI员工(其实就是一个聊天机器人),这个一号员工可以回答所有关于公司财务、人事、制度、产品方面的问题。
我问了句:公司加班有加班费嘛。
它回答:主人,我是24小时待命,不需要加班费的噢。
好一个答非所问。
虽然我知道这应该是套用开源模型,用公司数据来训练,比较粗糙,但还是为IT同事们与时俱进的精神鼓掌。
现在各种AI大模型层出不穷,不光是互联网大厂在搞,各种传统公司也在赶时髦,比如像我们。其实大模型开发会涉及到三个难题,算法、算力、数据,不是一般企业能扛得住的。
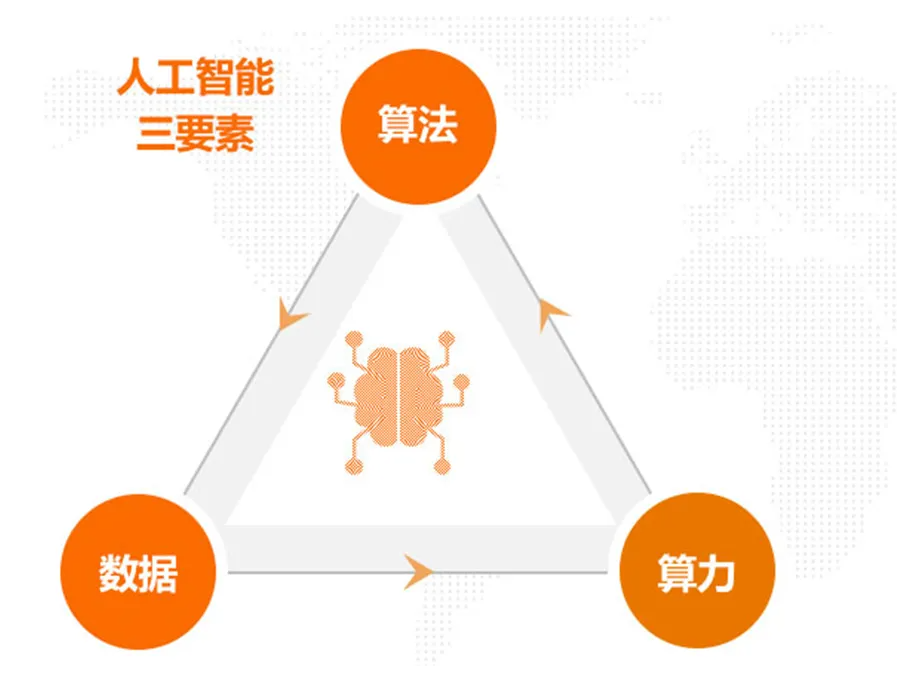
这其中以算力的成本最高,算法可以用开源的,数据可以用自己公司的,只有算力是需要花钱买大量的GPU、CPU来跑算法和数据,像现在英伟达的H100、H200 GPU已经卖到天价,就这样你还买不到。
但其实作为个人,你也可以创建自己的AI大模型,这次给大家介绍强烈推荐两个神器,星鸾云GPU云服务器和Jupyter Lab,两者结合既可以用于数据科学、数据可视化,也可以搞定机器学习、深度学习,搭建属于你的AI大模型。
星鸾云GPU云服务器,顾名思义,是一个搭建在云服务器上的GPU算力平台,具备超强的大规模、高并发计算能力,你不需要自己搭GPU服务器,也能用到稳定、高效且高性价比的算力。
https://xl.hzxingzai.cn/register?invitation_code=0006407067

Jupyter Lab是一款基于Python的web交互式开发环境,你可以在Lab上创建多个notebook,可以理解成是Jupyter notebook的加强升级版。
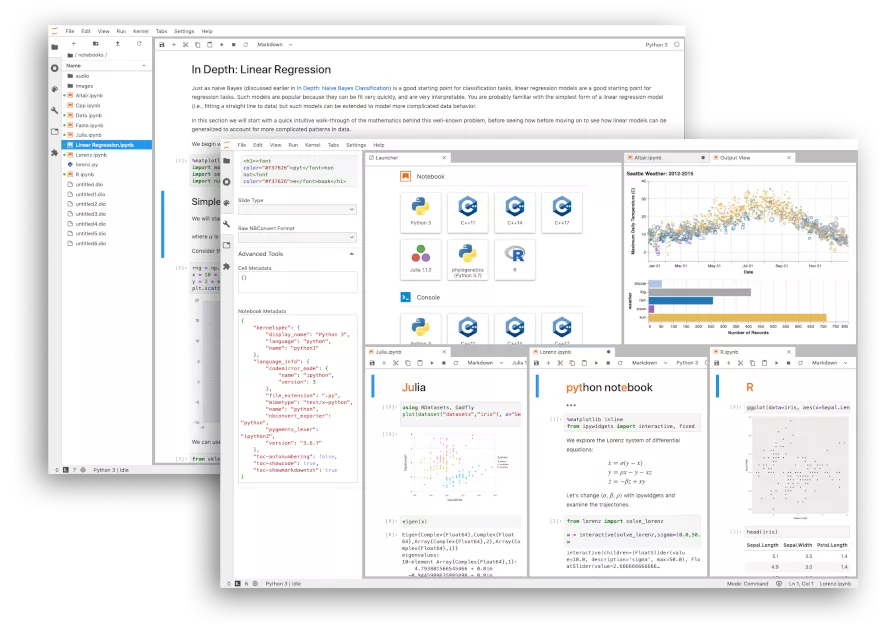
Jupyter Lab集编程开发、文本编辑器、可视化平台、终端以及各种个性化组件于一体,支持写代码、跑算法、展示可视化等等,几乎无所不包。
一般我们会把Jupyter Lab安装在本地,它运行在各种计算资源上,包括CPU、GPU、TPU等等,但由于本地电脑计算资源有限,只能跑跑一些简单的数据分析、机器学习任务,所以这时候就需要星鸾云GPU云服务器来提供GPU算力。
你能在星鸾云平台上创建使用 JupyterLab,享受业界超强算力的GPU计算卡,这样既能轻松进行代码调试、快速迭代和优化算法,还能极快的跑各种任务,非常的丝滑。

以下是在星鸾云中创建使用Jupyter Lab的步骤:
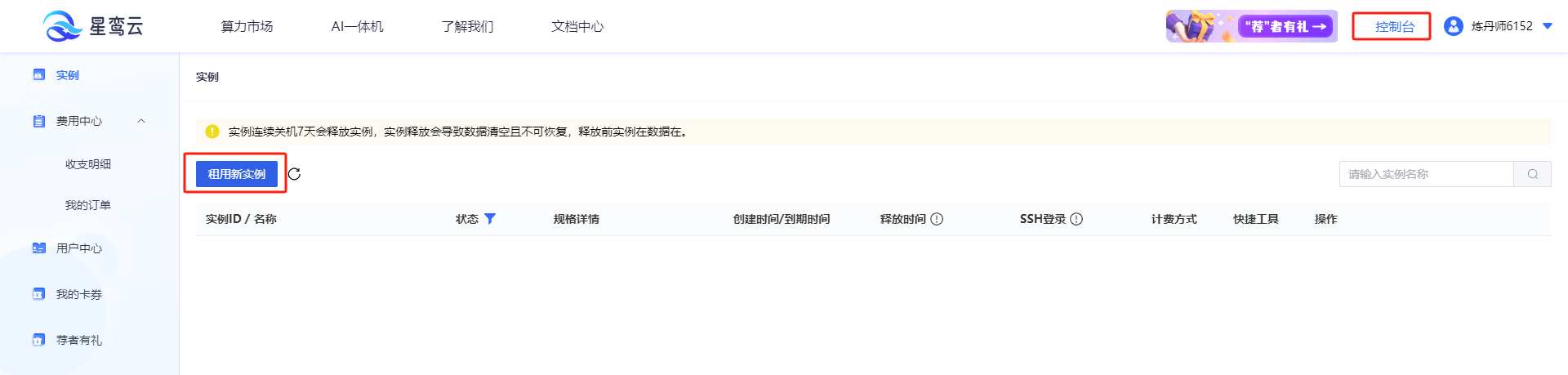
1. 创建星鸾云实例
首先,在星鸾云平台上创建一个GPU云服务器实例。选择合适的GPU型号和配置,并启动实例。
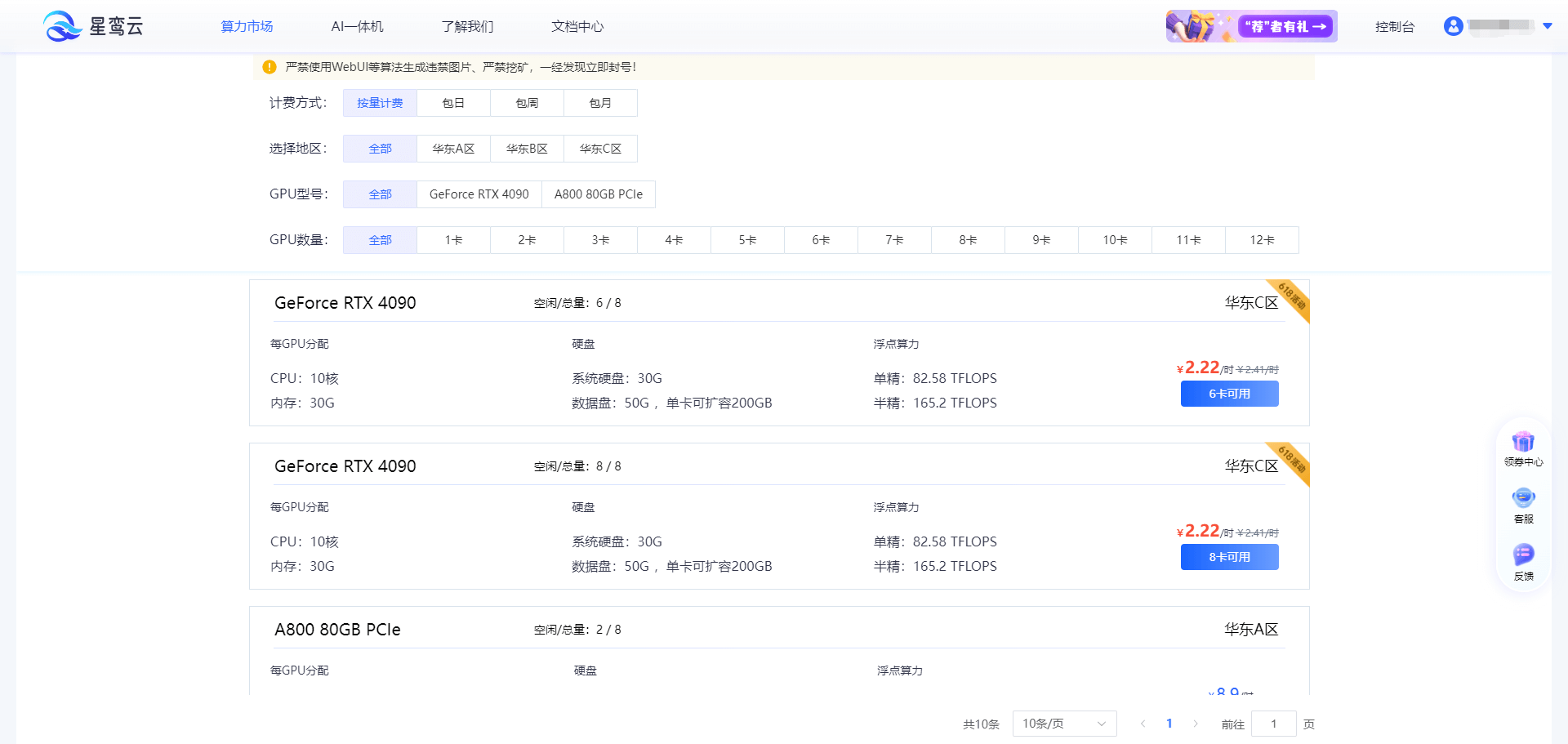
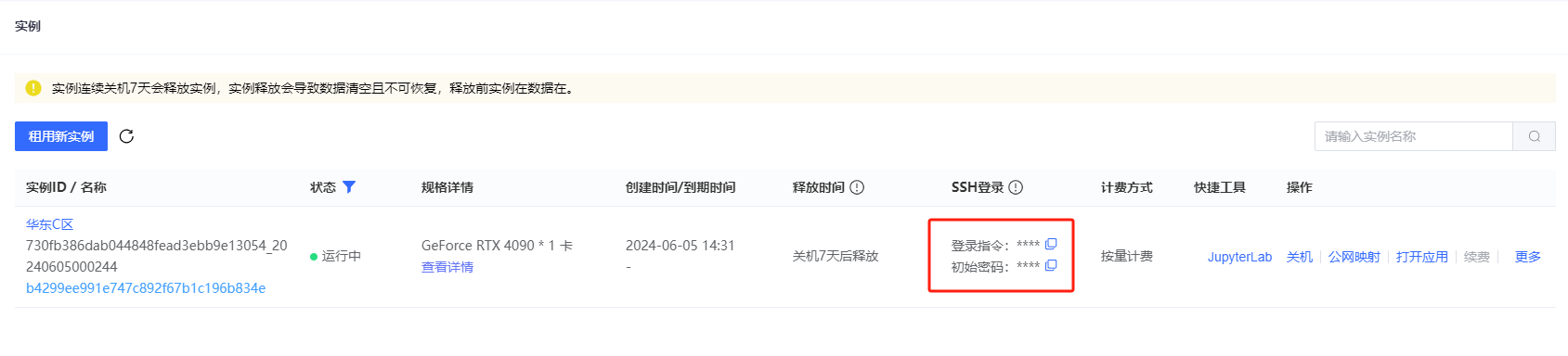
2. 连接到实例
使用SSH远程连接到星鸾云实例。Windows 用户可以使用 PowerShell 或者 XShell,Mac 用户可以直接使用 Terminal。
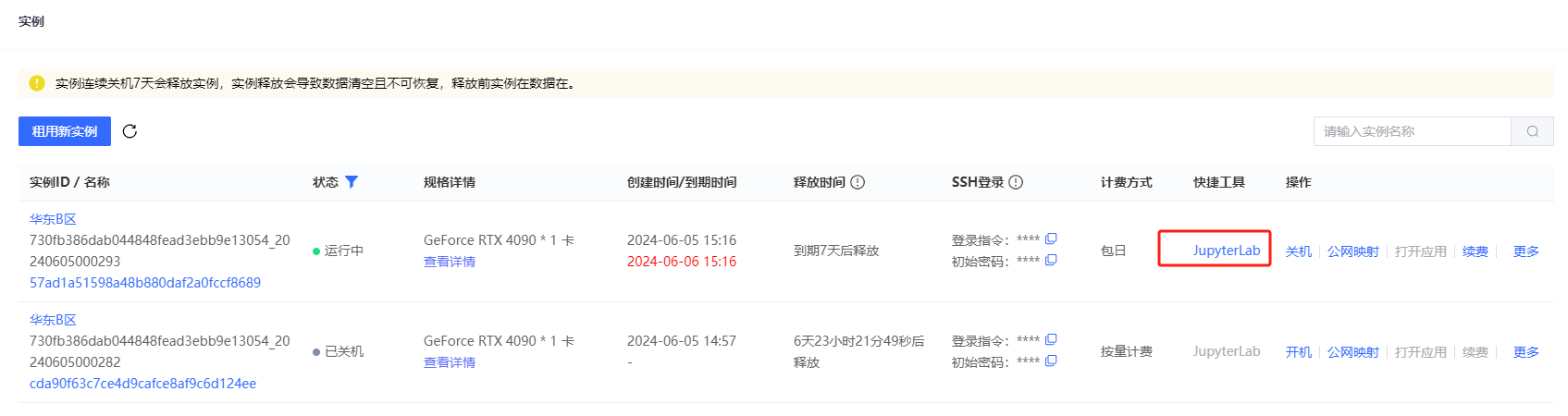
4. 启动登录 JupyterLab
直接在星鸾云实例中打开Jupyter Lab,接着打开终端,登录实例

5. 使用 JupyterLab
接着在 JupyterLab 中创建新的notebook,编写和运行Python代码,开始享受GPU跑算法带来的快乐吧。
我们使用PyTorch在MNIST数据集上训练一个简单的神经网络,来演示下如何使用星鸾云平台+Jupyter Lab来创建AI模型。
MNIST数据集是一个手写数字识别的经典数据集,我们创建神经网络模型用来识别手写数字。

下面是在Notebook中编写的代码:
导入相关库
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
加载和预处理数据
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))])trainset = datasets.MNIST('~/.pytorch/MNIST_data/', download=True, train=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
定义神经网络结构
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(784, 500)self.fc2 = nn.Linear(500, 10)def forward(self, x):x = x.view(-1, 784)x = torch.relu(self.fc1(x))x = self.fc2(x)return xnet = Net()
定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.5)
训练神经网络
for epoch in range(10): # loop over the dataset multiple timesrunning_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = dataoptimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()print(f'Epoch {epoch + 1}, Loss: {running_loss / len(trainloader)}')
保存模型
PATH = './mnist_net.pth'
torch.save(net.state_dict(), PATH)
就这样,我们使用星鸾云GPU训练了一个神经网络模型,用于识别手写数据,虽然很简单,但也是一个地地道道的AI模型了。
接下来我们再尝试使用星鸾云GPU+Jupyter Lab开发一个AI大模型聊天工具,用于回答公司的业务问题。
首先配置环境,登录星鸾云实例,并安装必要的软件和库。
用于训练聊天机器人的问答数据主要包括:
公司FAQs
业务相关文档
公司制度文件
等等
然后对数据进行预处理,在JupyterLab中创建一个新的Notebook,编写代码对数据进行清洗、分词和格式化,准备输入模型训练。
接着,选择一个适合对话系统的预训练模型库,建议使用transformers库,然后在GPU加速下进行模型训练,监控训练过程并调整超参数以获得最佳性能。
以下是在JupyterLab的演示代码:
# 导入所需的库
from transformers import Trainer, TrainingArguments# 定义训练参数
training_args = TrainingArguments(output_dir="./results",evaluation_strategy="epoch",learning_rate=2e-5,per_device_train_batch_size=16,per_device_eval_batch_size=16,num_train_epochs=3,weight_decay=0.01,
)# 定义Trainer对象
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset, # 训练数据集eval_dataset=eval_dataset, # 验证数据集tokenizer=tokenizer,
)# 训练模型
trainer.train()# 保存模型
model.save_pretrained("./ai-chat-model")
tokenizer.save_pretrained("./ai-chat-model")
模型训练好后,你可以部署为API服务,然后集成到公司的内部业务支持平台,比如内网、企微、钉钉等。
使用星鸾云GPU云服务器和JupyterLab可以很轻松的进行大模型的训练和调试,简直是黄金搭档组合。
星鸾云GPU云服务器能很好的帮助个人和企业进行大数据和AI的模型训练,不需要自己采购配置GPU服务器。
它有几个特点,我觉得在同类产品里算是领头羊的存在。
- 超强算力:配备业界领先的GPU计算卡,提供超强的并行计算能力。
- 专业稳定:智能液冷数据中心保障了99.99%的机器稳定性。
- 高性价比:支持按需和包周期计费,避免资源浪费。
- 快速交付:云主机从订购到使用仅需数分钟,提供丰富的AI工具链,实现一键部署。

大家也尝试利用星鸾云GPU云服务器自己开发个AI大模型机器人,赶赶时髦,哈哈。
https://xl.hzxingzai.cn/register?invitation_code=0006407067
这篇关于使用星鸾云GPU云服务器搭配Jupyter Lab,创建个人AI大模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



