本文主要是介绍自然语言处理领域的重大挑战:解码器 Transformer 的局限性,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

自然语言处理(NLP)领域面临的一个主要挑战是解决解码器 Transformer 模型的局限性。这些模型构成了大型语言模型(LLM)的基础,但存在代表性崩溃和过度压缩等重大问题。代表性崩溃是指不同输入序列产生几乎相同的表示,而过度压缩则导致由于信息的单向流动而对特定标记的敏感性丧失。这些挑战严重阻碍了LLM执行准确计数或复制序列等基本任务,这对AI应用中的各种计算和推理任务至关重要。
目前解决这些挑战的方法包括增加模型复杂性和增强训练数据集。已经探索了使用更高精度的浮点格式和更复杂的位置编码等技术。然而,这些方法计算成本高,通常不适合实时应用。现有的方法还包括使用辅助工具来帮助模型执行特定任务。尽管做出了这些努力,由于解码器 Transformer 架构和常用的低精度浮点格式的固有局限性,代表性崩溃和过度压缩等根本问题仍然存在。
研究者们提出了一种理论信号传播分析方法,以研究解码器 Transformer 内部的信息处理方式。他们关注最后一层中最后一个标记的表示,这对下一个标记的预测至关重要。该方法识别并形式化了代表性崩溃和过度压缩现象。研究表明,代表性崩溃发生在由于低精度浮点计算导致不同输入序列产生几乎相同的表示。通过分析早期标记的信息被不成比例地压缩,从而导致模型敏感性降低来解释过度压缩。这种方法提供了一个新的理论框架来理解这些限制,并提供了简单但有效的解决方案来缓解这些问题。
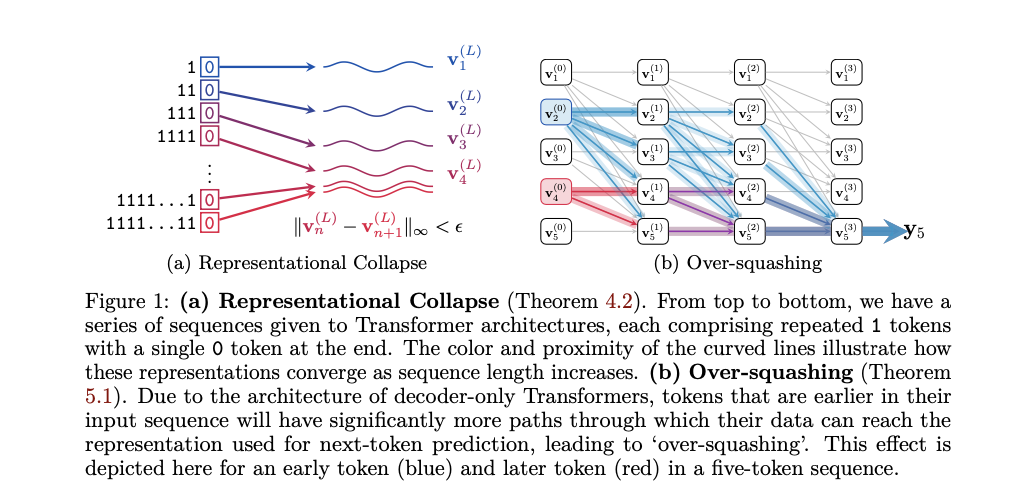
该方法包括详细的理论分析和实证证据。研究者们使用数学证明和实验数据来展示代表性崩溃和过度压缩现象。他们利用当代LLM验证了他们的发现,并说明低浮点精度如何加剧这些问题。分析包括检查注意力权重、层归一化效应和位置编码衰减。研究者们还讨论了实际影响,如量化和标记化对模型性能的影响,并提出在长序列中添加额外标记作为防止代表性崩溃的实际解决方案。
结果表明,由于代表性崩溃和过度压缩,解码器 Transformer 模型在需要计数和复制序列的任务中表现出显著的性能问题。在当代大型语言模型(LLM)上进行的实验显示,随着序列长度的增加,准确性显著下降,模型难以区分不同的序列。实证证据支持理论分析,表明低精度浮点格式加剧了这些问题,导致下一个标记预测中的频繁错误。重要的是,提出的解决方案,如在序列中引入额外标记和调整浮点精度,得到了实验证明,显著提高了模型在处理长序列时的性能和鲁棒性。这些发现强调了需要解决LLM中的根本架构限制,以提高其在实际应用中的准确性和可靠性。
总之,该论文对解码器 Transformer 模型固有的局限性进行了详细分析,特别关注代表性崩溃和过度压缩问题。通过理论探索和实证验证,作者展示了这些现象如何损害LLM在计数和复制序列等基本任务中的表现。研究确定了低精度浮点格式加剧的关键架构缺陷,并提出了有效的解决方案来缓解这些问题,包括引入额外标记和精度调整。这些干预措施显著提高了模型性能,使其在实际应用中更加可靠和准确。这些发现强调了解决这些根本问题的重要性,以推进LLM在自然语言处理任务中的能力。
这篇关于自然语言处理领域的重大挑战:解码器 Transformer 的局限性的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



