局限性专题

reactive() 的局限性
reactive() API 有一些局限性: 有限的值类型:它只能用于对象类型 (对象、数组和如 Map、Set 这样的集合类型)。它不能持有如 string、number 或 boolean 这样的原始类型。 不能替换整个对象:由于 Vue 的响应式跟踪是通过属性访问实现的,因此我们必须始终保持对响应式对象的相同引用。这意味着我们不能轻易地“替换”响应式对象,因为这样的话与第一个引用的响应

C++ 65 之 模版的局限性
#include <iostream>#include <cstring>using namespace std;class Students05{public:string m_name;int m_age;Students05(string name, int age){this->m_name = name;this->m_name = age;}};// 两个值进行对比的函数te
LabVIEW机械设备故障诊断中,振动分析的有效性与局限性如何
LabVIEW作为一种强大的图形化编程工具,在机械设备故障诊断中的振动分析中发挥了重要作用。振动分析通过监测机械设备的振动信号,能够有效地诊断设备故障。然而,尽管其有效性显著,但也存在一些局限性。本文将探讨LabVIEW在振动分析中的优势和局限性。 振动分析的有效性 实时监测和数据采集: 优势:LabVIEW提供了强大的数据采集功能,能够实时监测机械设备的振动信号。通过使用数据采集卡和传感器
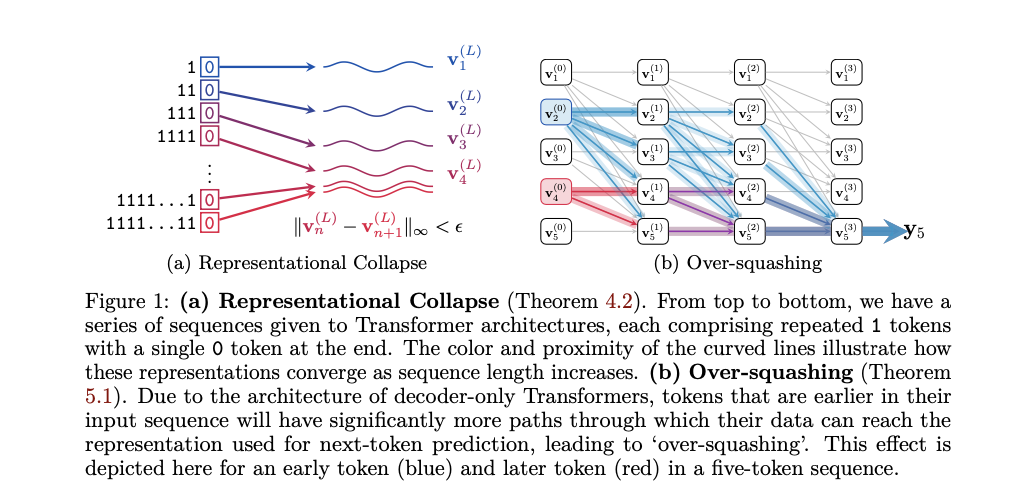
自然语言处理领域的重大挑战:解码器 Transformer 的局限性
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/ 自然语言处理(NLP)领域面临的一个主要挑战是解决解码器 Trans

塔勒布作品集合风险共担来应对不确定性、风险、随机性的局限性
Nassim Nicholas Taleb 是一位著名的风险分析学者和作家,他的主要作品被合称为“Incerto”不确定性系列。这些书籍虽然可以独立阅读,但它们在主题和思想上紧密相连,共同探讨了不确定性、风险、随机性和人类在应对这些方面的局限性。 以下是 Taleb 的主要书籍及其写作逻辑: 《随机漫步的傻瓜》(Fooled by Randomness, 2001) 主要内容:讨论了在生活和

家庭服务机器人应用的局限性
家庭服务机器人应用的局限性主要体现在以下几个方面: 技术成熟度与功能限制: 目前家庭服务机器人大部分仍停留在较为初级的阶段,如扫地机器人,其功能相对单一,主要集中于地面清洁。对于更为复杂的家庭服务需求,如烹饪、洗衣、带娃等,现有的家庭服务机器人尚难以胜任。高端的家庭服务机器人,如综合式家庭服务机器人,虽然理论上可以完成更多任务,但目前仍处于研发阶段,其技术成熟度和稳定性仍有待提高。成本高昂: 家

【文末附gpt升级秘笈】AI热潮降温与AGI场景普及的局限性
AI热潮降温与AGI场景普及的局限性 摘要: 随着人工智能(AI)技术的迅猛发展,AI热一度席卷全球,引发了广泛的关注和讨论。然而,近期一些学者和行业专家对AI的发展前景提出了质疑,认为AI热潮将逐渐降温,且通用人工智能(AGI)在场景普及上将面临诸多挑战。本文基于与《Core Java》作者Cay Horstmann的对话,结合当前AI发展的实际情况,对AI热潮降温的原因以及AGI场景普及的局

清华大学提出IFT对齐算法,打破SFT与RLHF局限性
监督微调(Supervised Fine-Tuning, SFT)和基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)是预训练后提升语言模型能力的两大基础流程,其目标是使模型更贴近人类的偏好和需求。 考虑到监督微调的有效性有限,以及RLHF构建数据和计算成本高昂,这两种方法常常被结合使用。但由于损失函数、数据格式的差异以及对
上门回收小程序:打破传统回收模式的局限性
一、引言 在环保意识日益增强的今天,废品回收已成为我们日常生活中不可或缺的一部分。然而,传统的回收模式存在着效率低下、回收范围有限等局限性。为了打破这些局限,我们推出了上门回收小程序,旨在通过数字化、智能化的方式,为用户提供更加便捷、高效的回收服务。 二、上门回收小程序的特点 便捷性:用户只需通过小程序一键下单,即可享受上门回收服务。无需亲自前往回收站或等待回收人员上门,大大节省了用户的时间
第6章:6.4.4 MATLAB爬虫的局限性和注意事项 (MATLAB入门课程)
讲解视频:可以在bilibili搜索《MATLAB教程新手入门篇——数学建模清风主讲》。 MATLAB教程新手入门篇(数学建模清风主讲,适合零基础同学观看)_哔哩哔哩_bilibili 使用MATLAB爬虫时,有几个局限性和注意事项需要我们留心。了解这些局限性能帮助我们更加合理地选择工具,而对注意事项的关注则确保我们的爬虫操作合法合规。 (1)局限性 动态网页处理能力有限:M

从 Sora 制作的短片看AI生成视频的优势与局限性解析
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/ 在人工智能社区中,OpenAI 的视频生成工具 Sora 以其流畅、逼真
Mysql分区表局限性总结
Mysql5.1已经发行很久了,本文根据官方文档的翻译和自己的一些测试,对Mysql分区表的局限性做了一些总结,因为个人能力以及测试环境的原因,有可能有错误的地方,还请大家看到能及时指出,当然有兴趣的朋友可以去官方网站查阅。 本文测试的版本 mysql> select version(); +————+ | version() | +————+ | 5.1.33-log | +——

泛型局限性和常见错误
泛型主要用于编译阶段,编译后生成的字节码class文件不包含泛型中的类型信息。类型参数在编译后会被替换成Object,运行时虚拟机并不知道泛型。因此,使用泛型时,如下几种情况是错误的: 基本类型不能用于泛型 Test<int> t 这样的写法是错误的,我们可以使用对应的包装类 Test<Integer> t; 不能通过类型参数创建对象

AI Agent目前应用落地有哪些局限性?
谈到AI Agent目前应用落地有哪些局限性,还是要从概念、应用入手。 谈 到 AI Agent, 很多人都认为它是LLM的产物,了解 AI Agent 的人应该知道,Agent 概念并不是当今的产物,而是伴随人工智能而出现的智能实体概念不断进化的结果。 一、要弄懂AI领域的agent是什么意思,就要知道AI Agent的发展脉络: 思想启蒙阶段: 关于 AI Agent 的最早起源,还要
【文末附gpt升级4.0方案】英特尔AI PC的局限性是什么
为什么要推出英特尔AI PC? 英特尔AI PC的推出无疑为AIGC(生成式人工智能)的未来发展开启了一扇新的大门。这种新型的计算机平台,通过集成先进的硬件技术和优化的软件算法,为AIGC提供了更为强大和高效的支持,进一步推动了人工智能的落地和应用。 首先,英特尔AI PC的出色性能为AIGC提供了坚实的基础。其内置的3D性能混合架构集成了CPU、GPU和NPU,使得计算机能够同时处理各种复杂
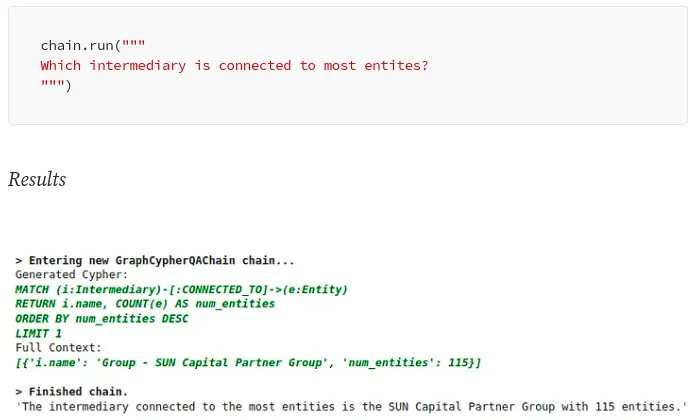
知识图谱与LLMs:微调 VS RAG、LLM的局限性以及如何克服
原文地址:Knowledge Graphs & LLMs: Fine-Tuning Vs. Retrieval-Augmented Generation 2023 年 6 月 6 日 GitHub:https://github.com/neo4j/NaLLM 大型语言模型 (LLM) 的第一波炒作来自 ChatGPT 和类似的基于网络的聊天机器人,相信在座的各位都并不陌生了,甚至不少人也已经
auto的局限性的理解
一、auto不能修饰表达式,但是decltype可以。 先看: 例1: decltype(aa); //编译失败,提示aa没有声明。 如果改为 例2: int aa = 0; decltype(aa); //编译成功。 再看: 例3: auto bb; //编译失败,提示auto需要初始值设定项。 如果改为: 例4: int bb = 0; auto bb; //还是编译失败,理由同例3. 如果

设计模式的局限性与适用性
《设计模式》的出版,是软件开发领域的一个关键转折点。设计模式理论的出现,让我们对软件的关注点,从如何在特定语言中实现最好的算法,提升为如何在特定环境下找到特定软件问题的最佳解决办法。这个转变不是一夜完成的,因为在这本书诞生前,软件模式运动已经进行多年。但这本书引领我们超越了在代码重用上的争议,上升到设计重用的高度;这本书第一次明确宣布了模式时代的到来。 审读此书
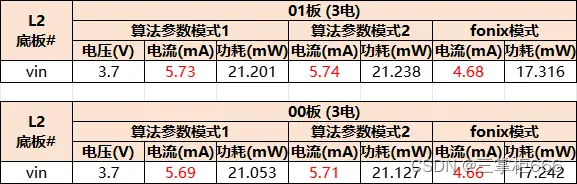
存内计算技术打破常规算力局限性
目录 前言 关于存内计算 1、常规算力局限性 2、存内计算诞生记 3、存内计算核心 存内计算芯片研发历程及商业化 1、存内计算芯片研发历程 2、存内计算先驱出道 3、存内计算商业化落地 基于知存科技存内计算开发板ZT1的降噪验证 (一)任务目标以及具体步骤 1、主模块 2、子模块(烧录时候需要用到) 3、主模块设置 4、连接效果 (二)模拟及验证结果 1、啸叫环境

论AI自动生成游戏的局限性及其意义缺失
近年来,人工智能技术在游戏开发领域的应用日益广泛,包括智能NPC设计、游戏关卡生成、剧情编排等。然而,关于让AI完全自主地编写和设计整个游戏的讨论也日渐兴起。本文旨在探讨为何让AI自己来写游戏在当前阶段并无实质意义,主要从创意、情感共鸣、可控性和市场需求四个维度进行分析。 主体论述一:创意与艺术性的缺失 游戏作为一门综合性的艺术形式,不仅要求逻辑严谨、玩法创

数据可视化软件在大数据时代的局限性
如今,数据可视化软件风靡起来,很多企业认为数据可视化软件是启用先进分析技术的入口。但对一些应用而言,情况并不是这样的。 纽约市的非营利组织DonorsChoose致力于跟踪和分析当地学校获得的财务捐助。在它试图为学校管理者、当地国会议员和记者出具一份报告时,它意识到数据可视化软件并不是万能的。乍一看,数据可视化系统对这种非技术组织来说应该是最好的选择了,不过该组织的数据科学家Vlad Dubov

触摸屏大比拼,各类触摸屏都有什么特点,同时又存在哪些局限性。
电容式的,电阻式的,红外式的……甭管什么式,虽然可能各位读者的手指早已习以为常地在屏幕上划来划去,但最早知道有这么一种屏幕居然能靠触摸操纵,会不会也像笔者一样惊奇? 现在借助下图,让我们一起来看看各类触摸屏都有什么特点,同时又存在哪些局限性。 电阻式触摸屏的代表机型是三星Messager Touch,HTC的Touch Diamond等。这种屏幕由多层材料复合而成,当触摸屏表面受到压力时,顶层
Python接口自动化测试的局限性,该如何破局?
Python接口自动化测试在软件质量保证方面具有显著的优势,如提高测试效率、减少人工错误、支持持续集成和回归测试等。然而,它也存在一些局限性,主要包括以下几点: 1. **初始投入成本高**: - 编写自动化测试脚本需要时间和技术知识,包括对Python语言的掌握以及接口测试框架(如unittest、pytest或requests等)的使用。 - 需要设计和实现用于验证接口响应的
模型评估:评估指标的局限性
“没有测量,就没有科学。”这是科学家门捷列夫的名言。在计算机科学特别是机器学习领域中,对模型的评估同样至关重要。只有选择与问题相匹配的评估方法,才能快速地发现模型选择或训练过程中出现的问题,迭代地对模型进行优化。模型评估主要分为离线评估和在线评估两个阶段。针对分类、排序、回归、序列预测等不同类型的机器学习问题,评估指标的选择也有所不同。知道每种评估指标的精确定义、有针对性地选择合适的评估指标、根
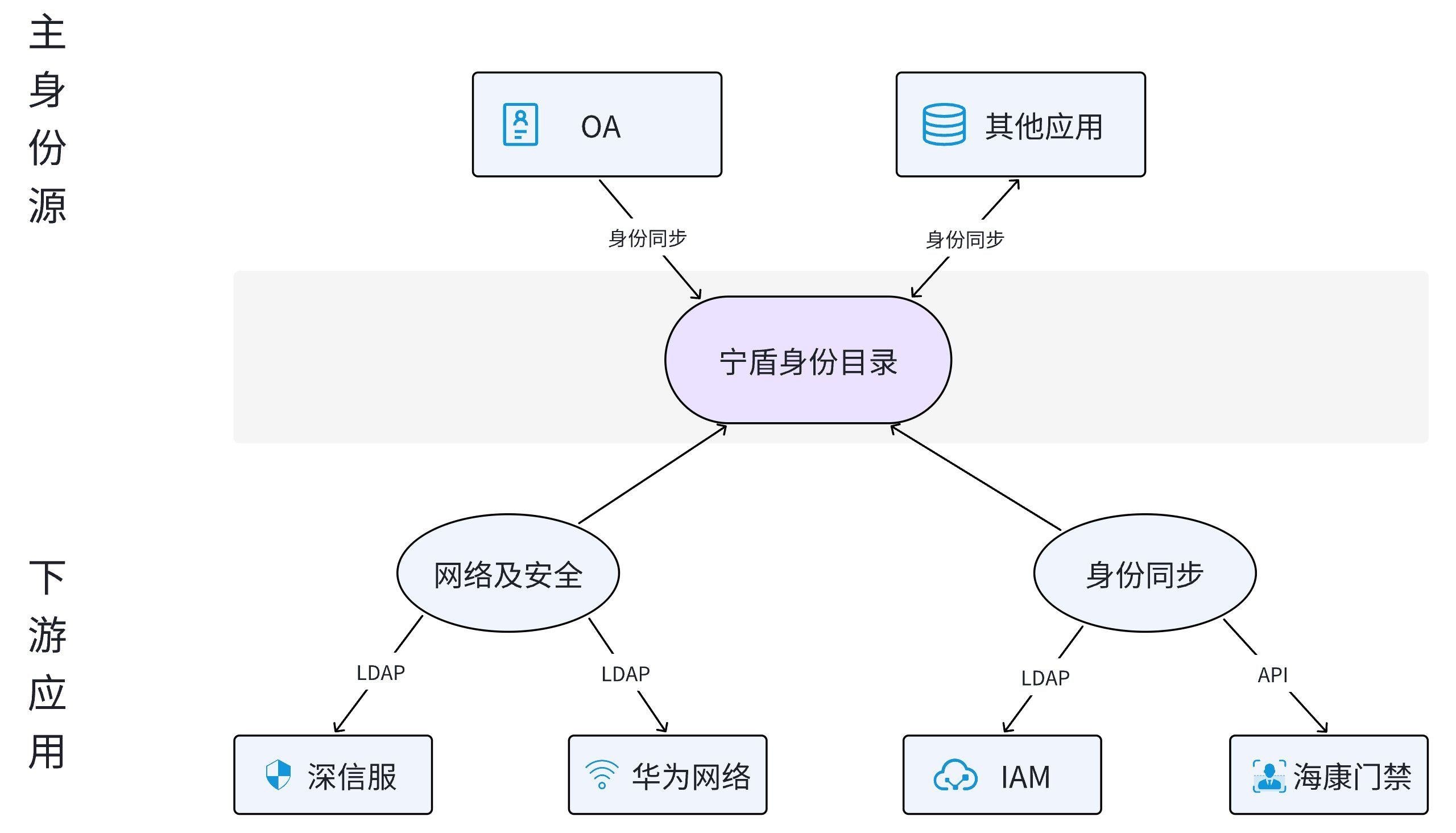
借助统一身份中台来增强传统IAM身份和访问管理系统在单点登录场景的局限性
单点登录(Single Sign-On,简称 SSO)是一种常见的企业身份验证方案,用户通过一次登录即可访问多个应用系统。然而,如果企业没有完成『身份整合与统一』这一步,那么这个单点登录方案就不能算是理想的解决方案。 在探讨这个问题之前,我们需要先理解统一身份的概念。统一身份是指将企业中所有用户的身份信息整合到一个中央数据库或身份提供者(Identity Provider,简称 IDP)中,