本文主要是介绍PSENET——OCR文本检测论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 摘要
- 1. 介绍
- 3. 提出的方法
- 3.1 整体框架
- 3.2 网络设计
- 3.3 渐进式尺度扩展算法
- 3.4 目标标签
- 3.5 损失函数
- 4. 实验
摘要
1. 介绍
PSENet的优势有:
- 基于分割的办法,能检测任意形状的文字
- 提出了一种渐进扩张算法,能有效分割位置很近的文本
- 每个文本实例(目标区域)有多个预测的分割实例(如何整合得到输出的?)
- 为了得到最后的文本区域采用了Breadth-First-Search (BFS)。从最小的预测分割实例开始扩张的。因为最小的分割实例map中文字之间的距离是比较大的,容易分割。
如图:

3. 提出的方法
3.1 整体框架
图:

- 采用ResNet做主干网络
- 将低层次的特征和高层次的分割实例特征进行融合
- 这些映射在F中进一步融合,以编码具有各种接受视图的信息
- 在用F产生n个branchs:S1,S2,—Sn,Si整个图片分割结果。S1是最小的分割结果,Sn是最大的分割结果。用递进比例尺展开算法得到最后的文字区域R
3.2 网络设计
PSENet采用特征金字塔网络为主干网络,将P2,P3,P4,P5融合成1024channel的F
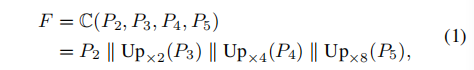
3.3 渐进式尺度扩展算法
示意图:

idea来源于数据结构中的广度优先搜索算法
- 首先是在S1(最小的文字分割map)上可以得到能很好分割开的文本中心区域
- 第二步,利用S2的像素融合到S1中,来扩张S1
- 第三部,用S3来扩张上一步得到的结果
- 最后用上一步得到的结果
这里可能有像素冲突,就是1个点属于两个文字区域,采用谁先扩张就是谁的。
3.4 目标标签
在我们的实践中,通过收缩原始文本实例,可以简单而有效地执行这些基本真值标签。
示意图:

将原始多边形pn缩小di像素,得到缩小后的多边形pi
di的计算规则(没细看):
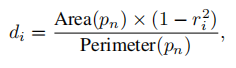
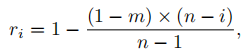
3.5 损失函数
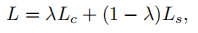
其中Lc和Ls分别表示完整文本实例和收缩文本实例的损失
- 采用dice loss作为损失函数
- 此外,还有许多类似于文本笔画的模式,如栅栏、格,和FOTS一样采用了OHEM(困难样本挖掘)
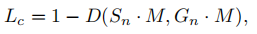
其中,D是dice loss,M是OHEM输出的掩码
- Ls是收缩文本实例的损失。由于它们被完整文本实例的原始区域所包围,为了避免一定的冗余,我们忽略了分割结果Sn中非文本区域的像素。因此,Ls可以表述为

其中W就是原始的文本区域掩码
就是后面的dice loss是在最大文本掩码的基础上计算的
4. 实验
no time to write
这篇关于PSENET——OCR文本检测论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





