本文主要是介绍计算机毕业设计师hadoop+spark+hive知识图谱医生推荐系统 医生数据分析可视化大屏 医生爬虫 医疗可视化 医生大数据 机器学习 大数据毕业设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
流程:
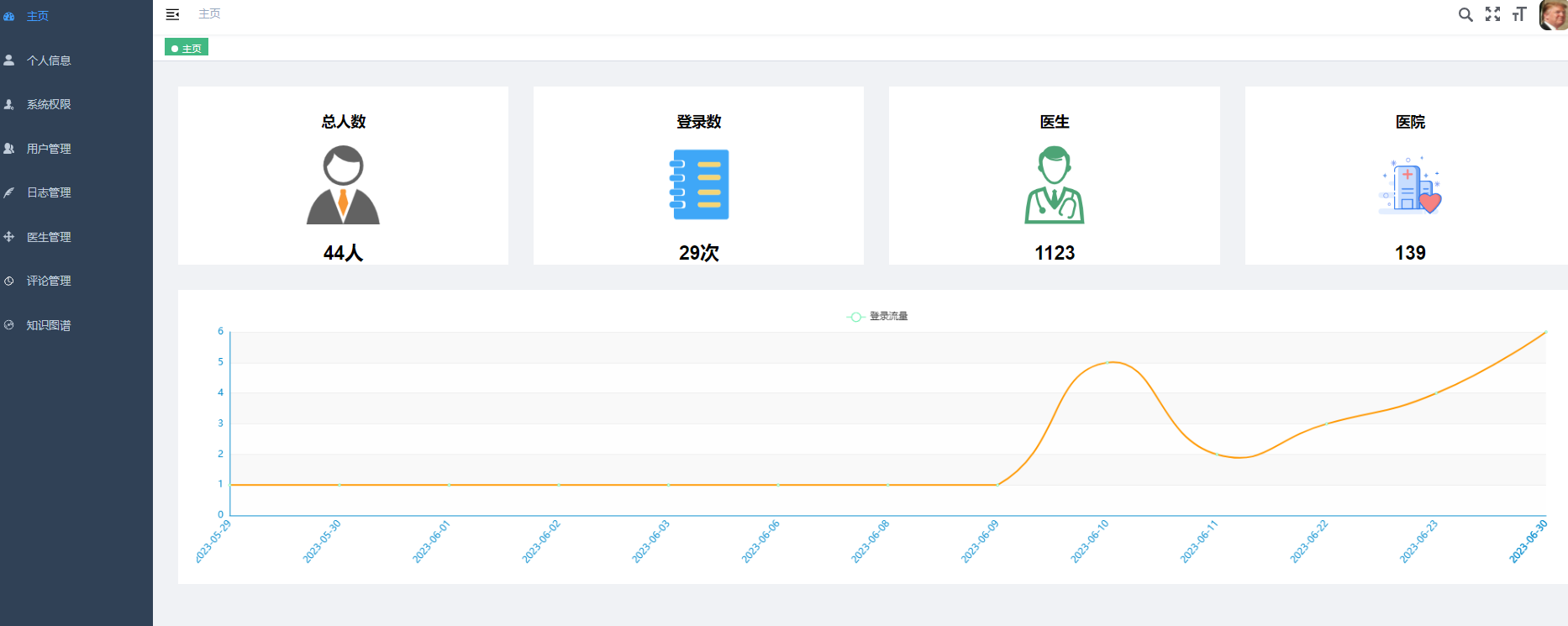
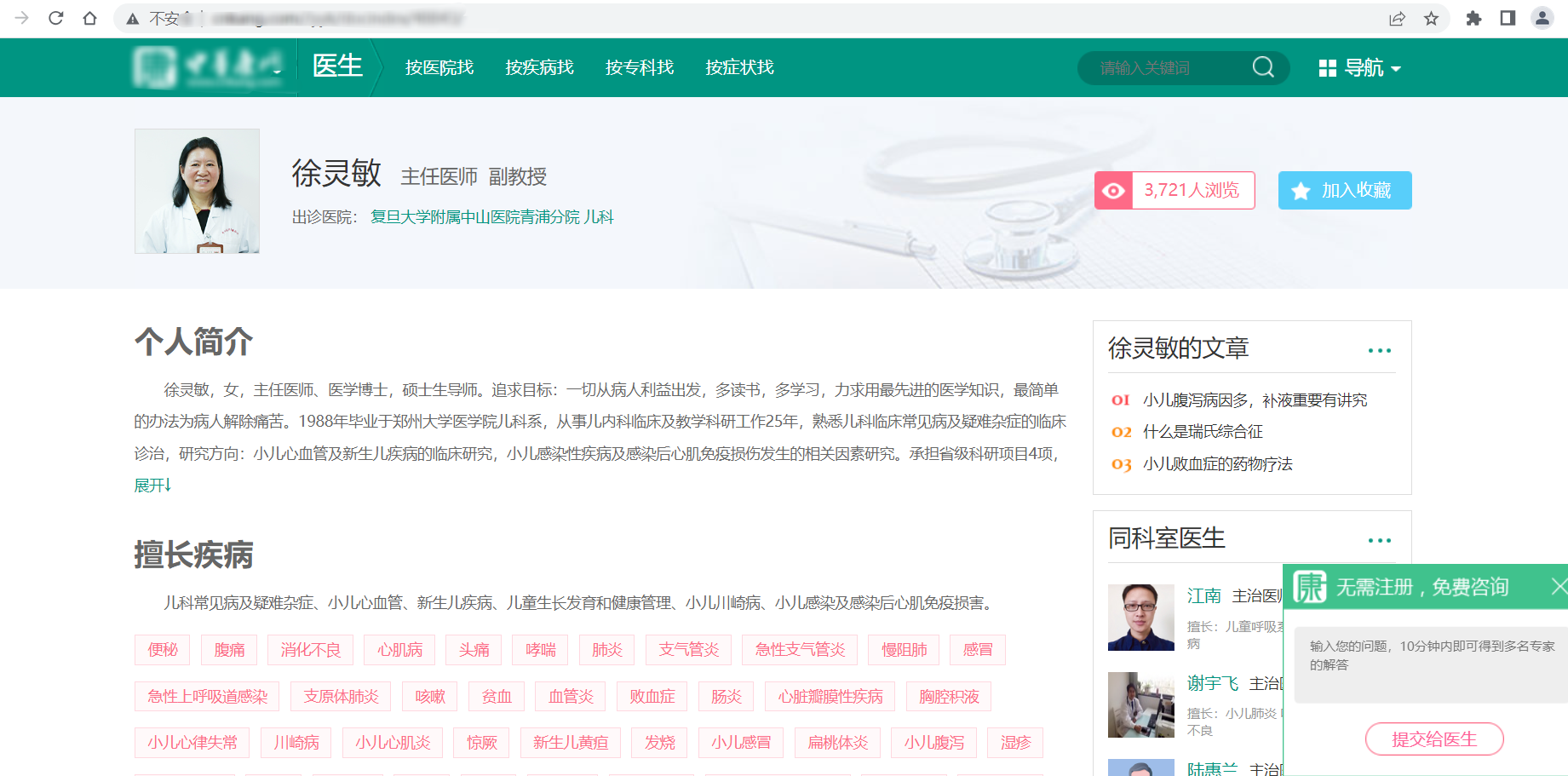
1.Python爬虫采集中华健康网约10万医生数据,最终存入mysql数据库;
2.使用pandas+numpy/hadoop+mapreduce对mysql中的医生数据进行数据分析,使用高德地图解析地理位置,并将结果转入.csv文件同时上传到hdfs文件系统;
3.使用hive建库建表,导入.csv数据集;
4.一半指标使用离线数仓hive_sql分析,一半指标使用实时数仓实时计算Spark之Scala实现;
5.使用sqoop将分析指标导入mysql数据库;
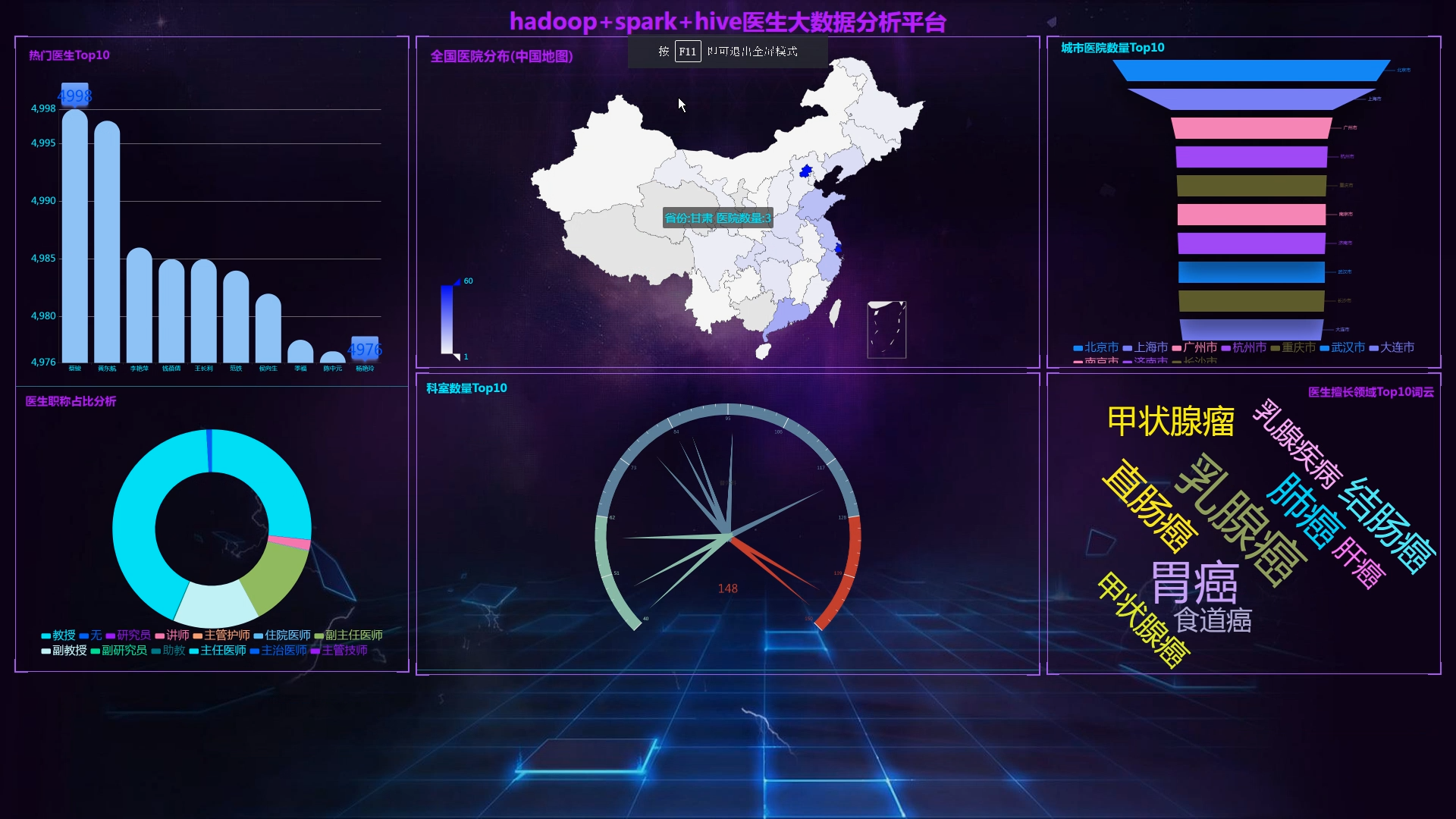
6.使用Flask+echarts实现可视化大屏界面;
创新点:高德地图解析地理位置、海量医生数据、Python爬虫、炫酷可视化大屏
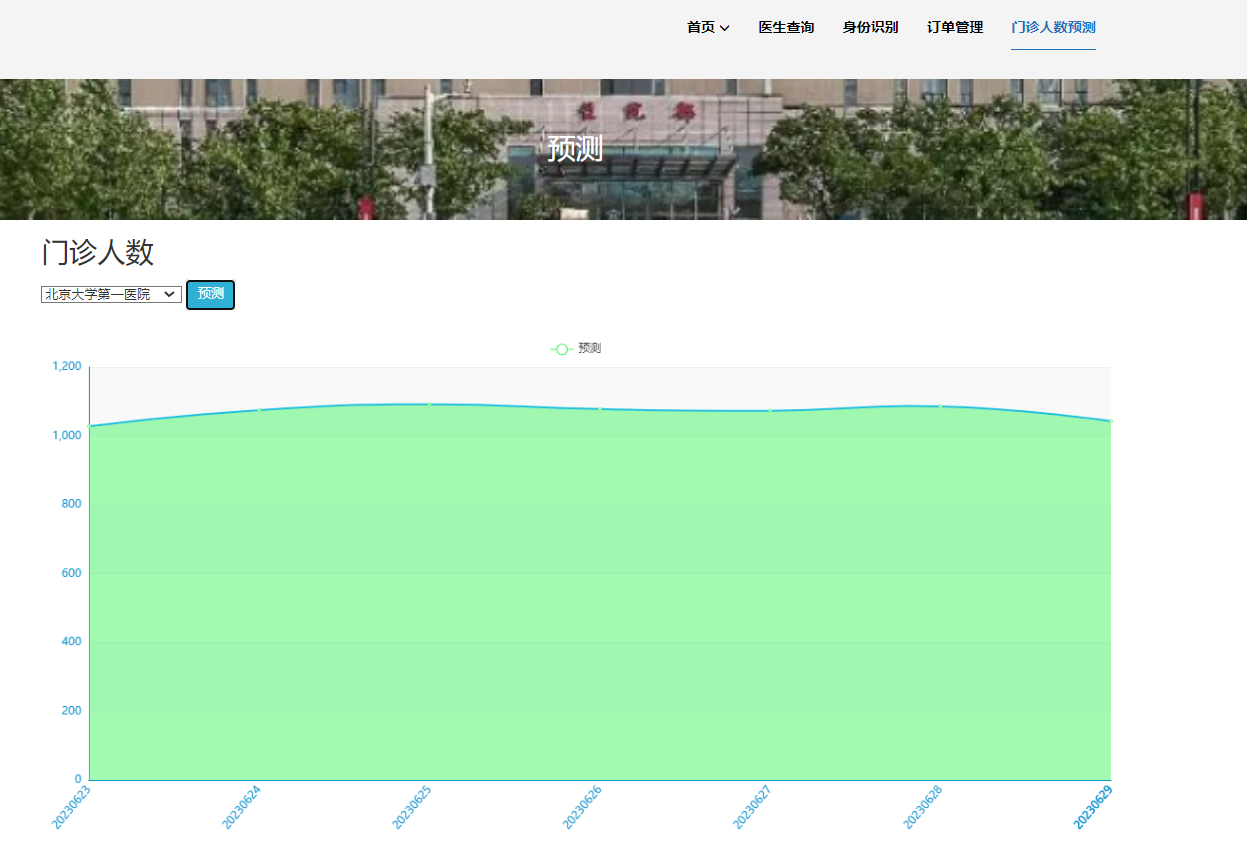
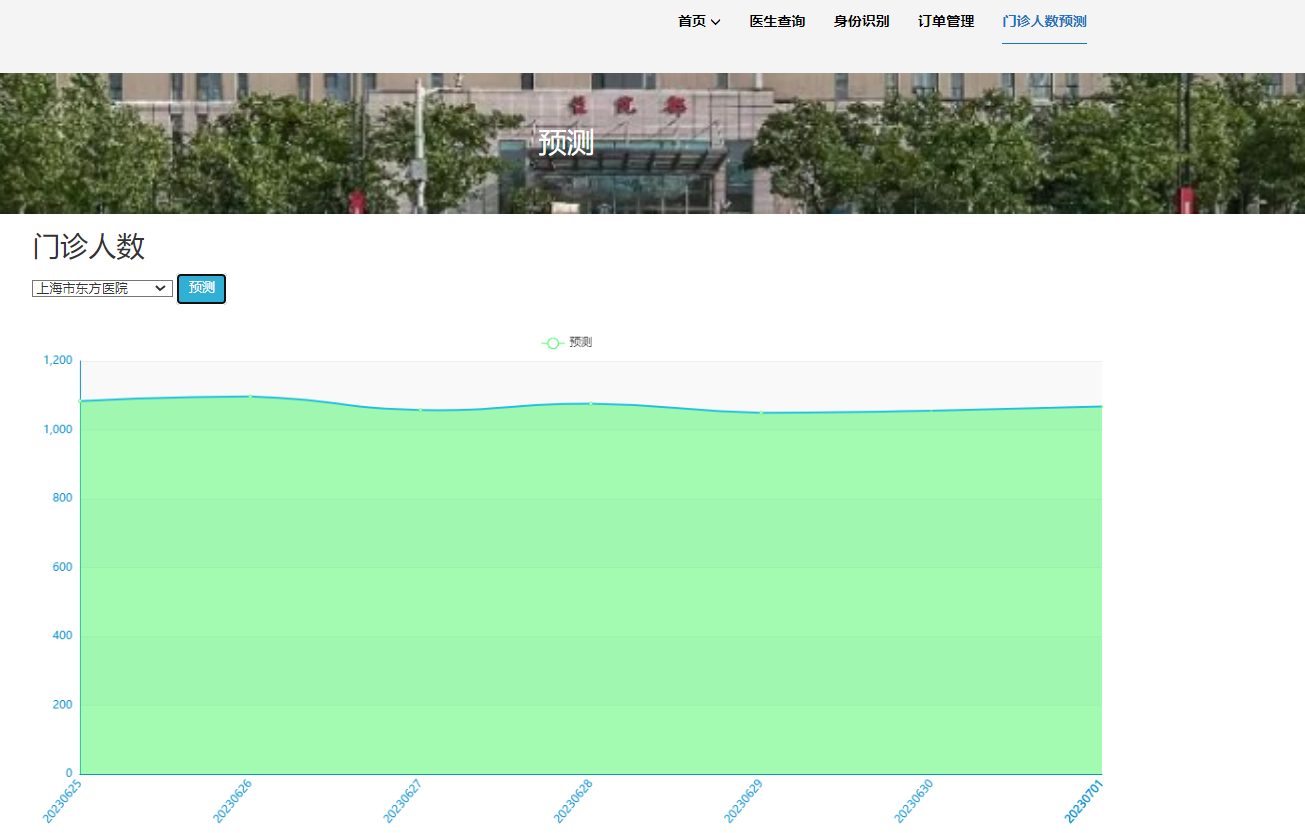
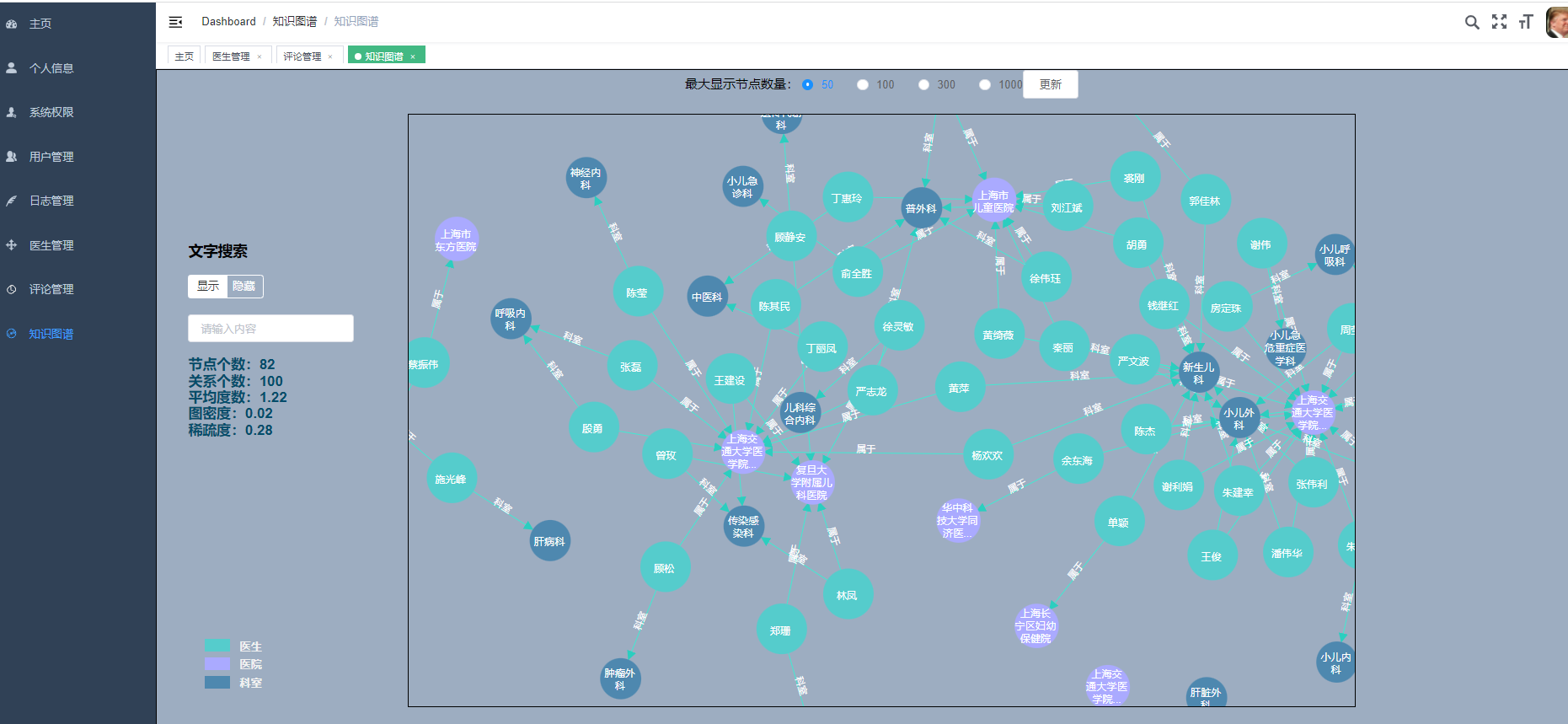
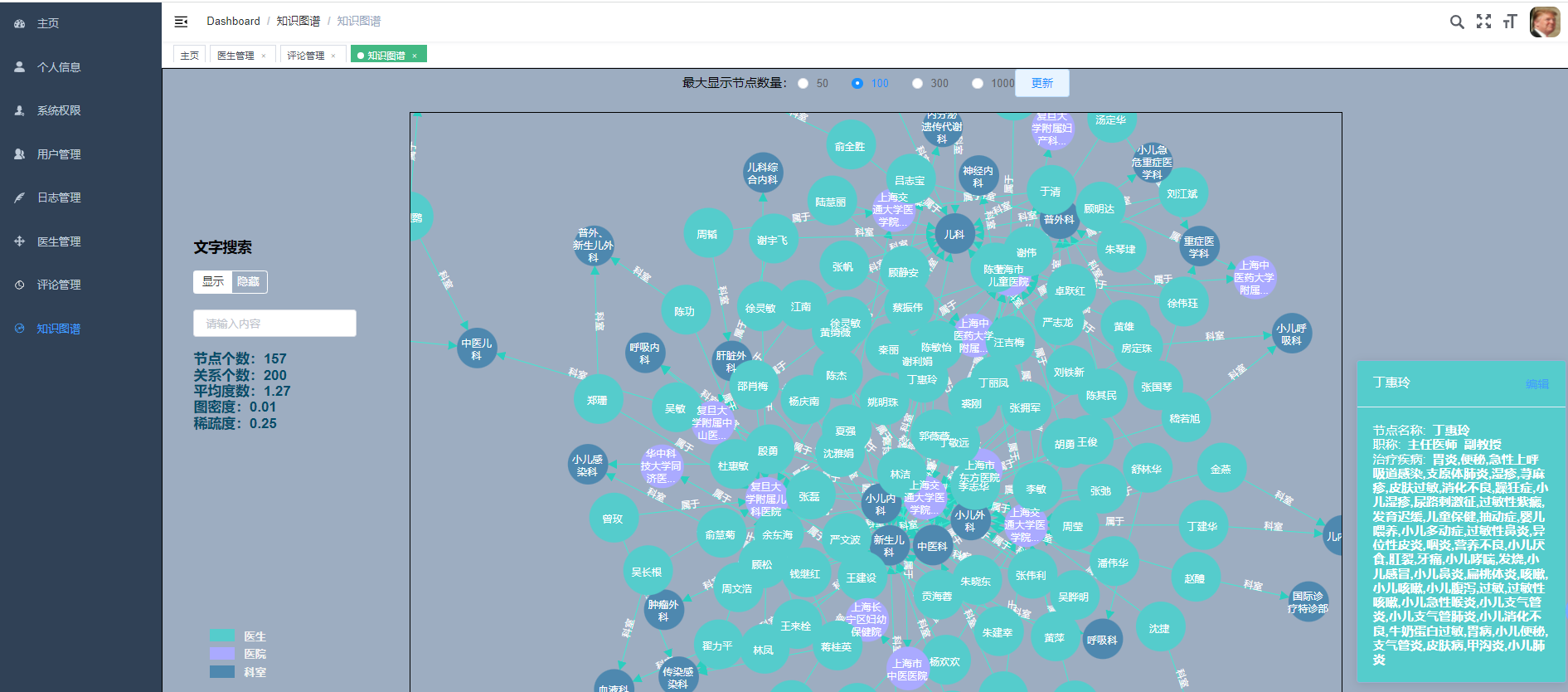
选装:可选装知识图谱、推荐系统、预测系统、后台管理等









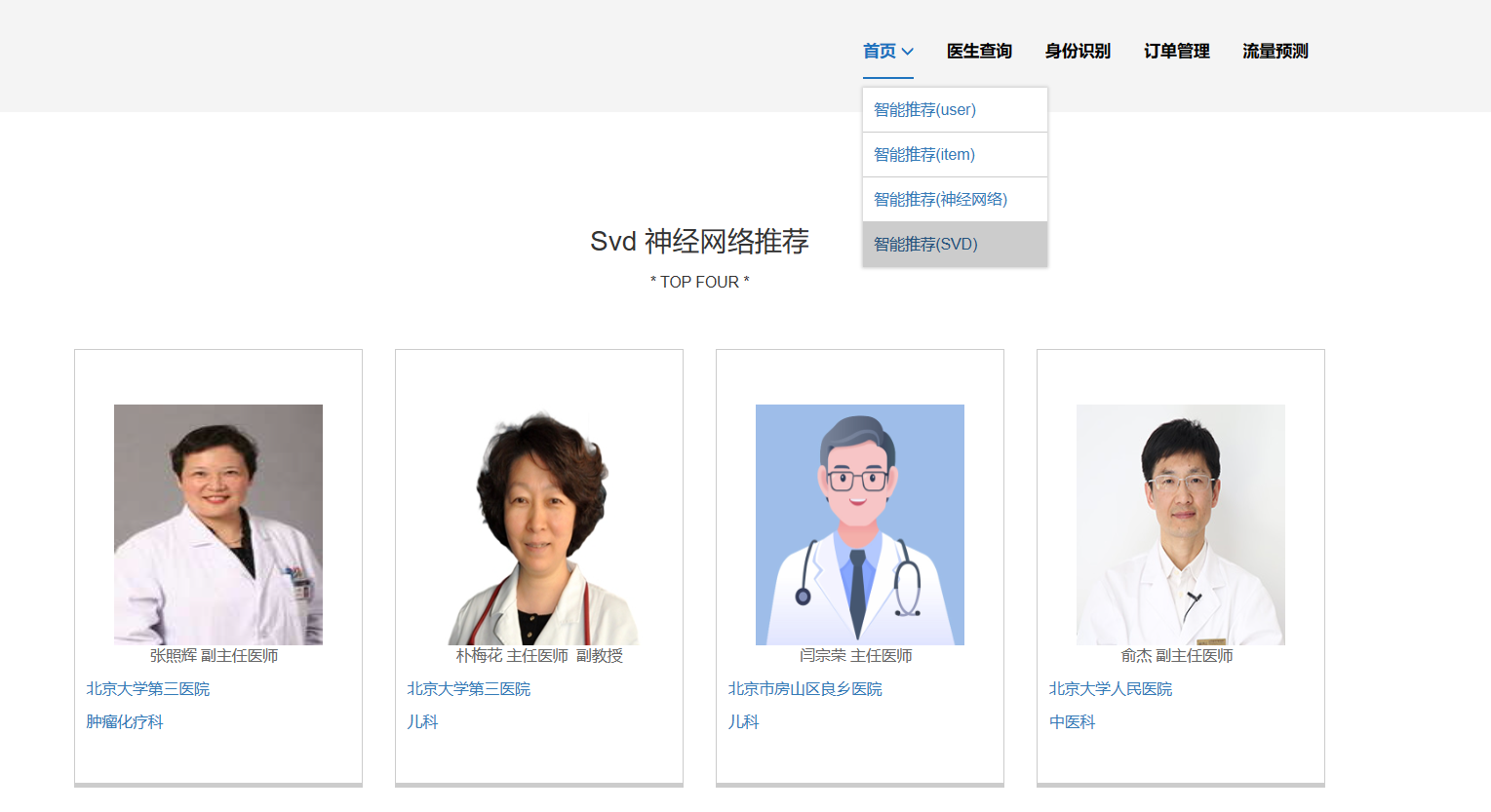
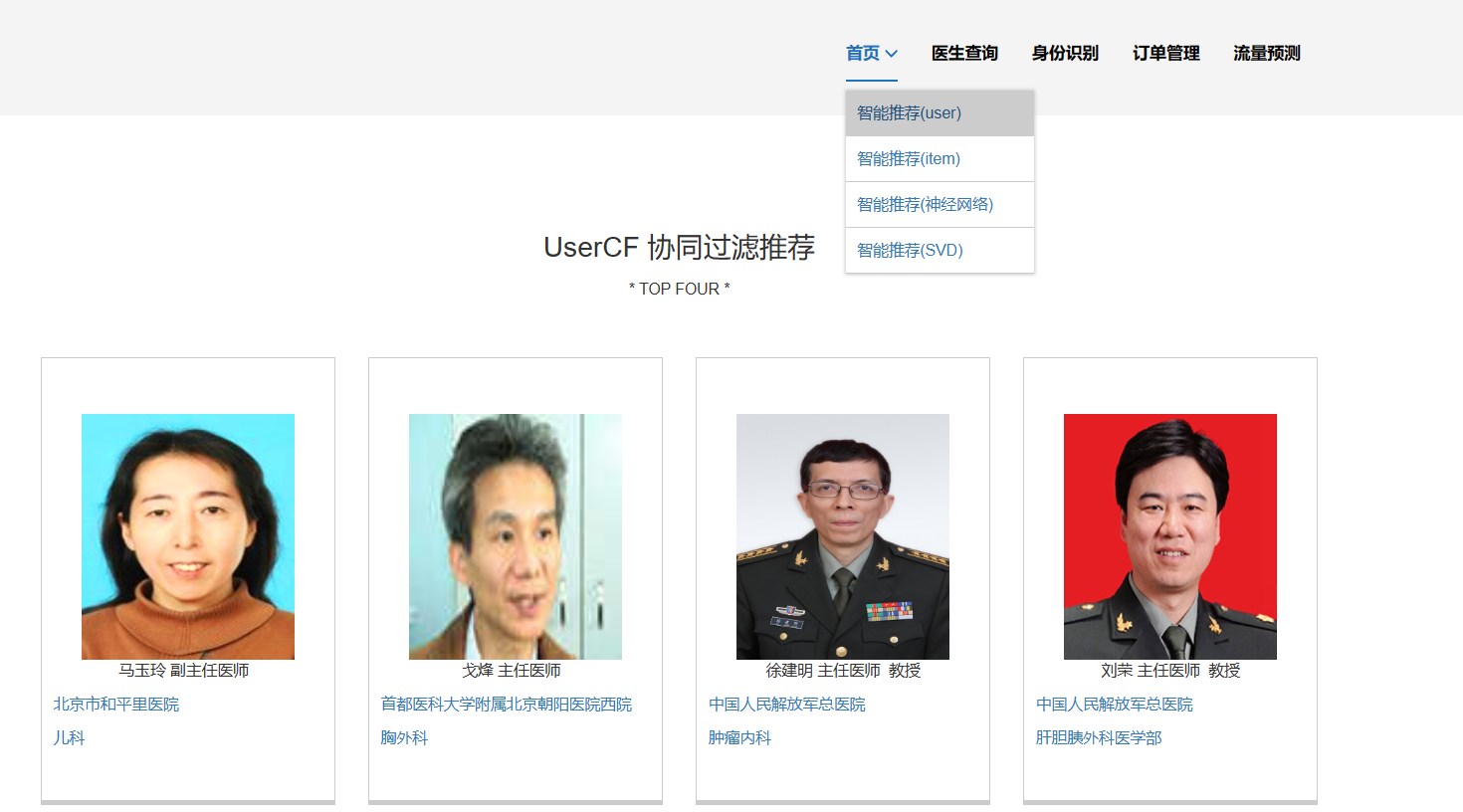




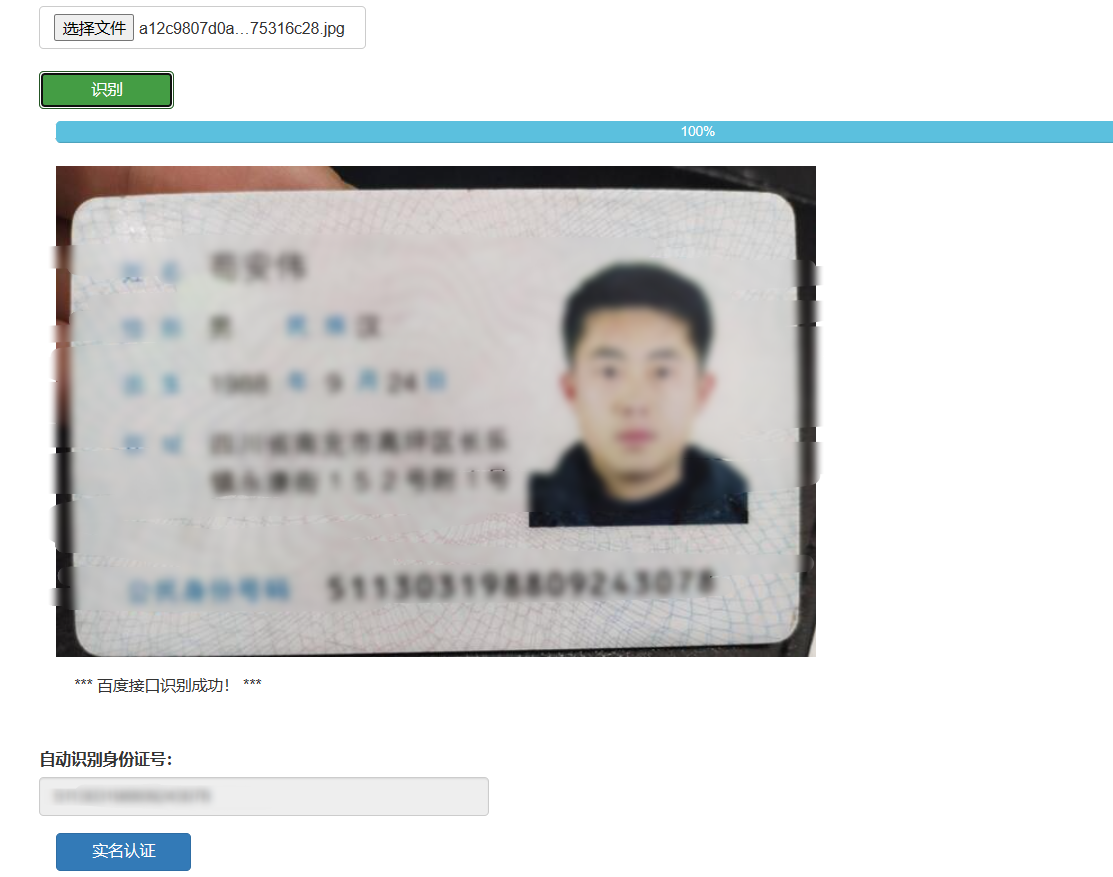

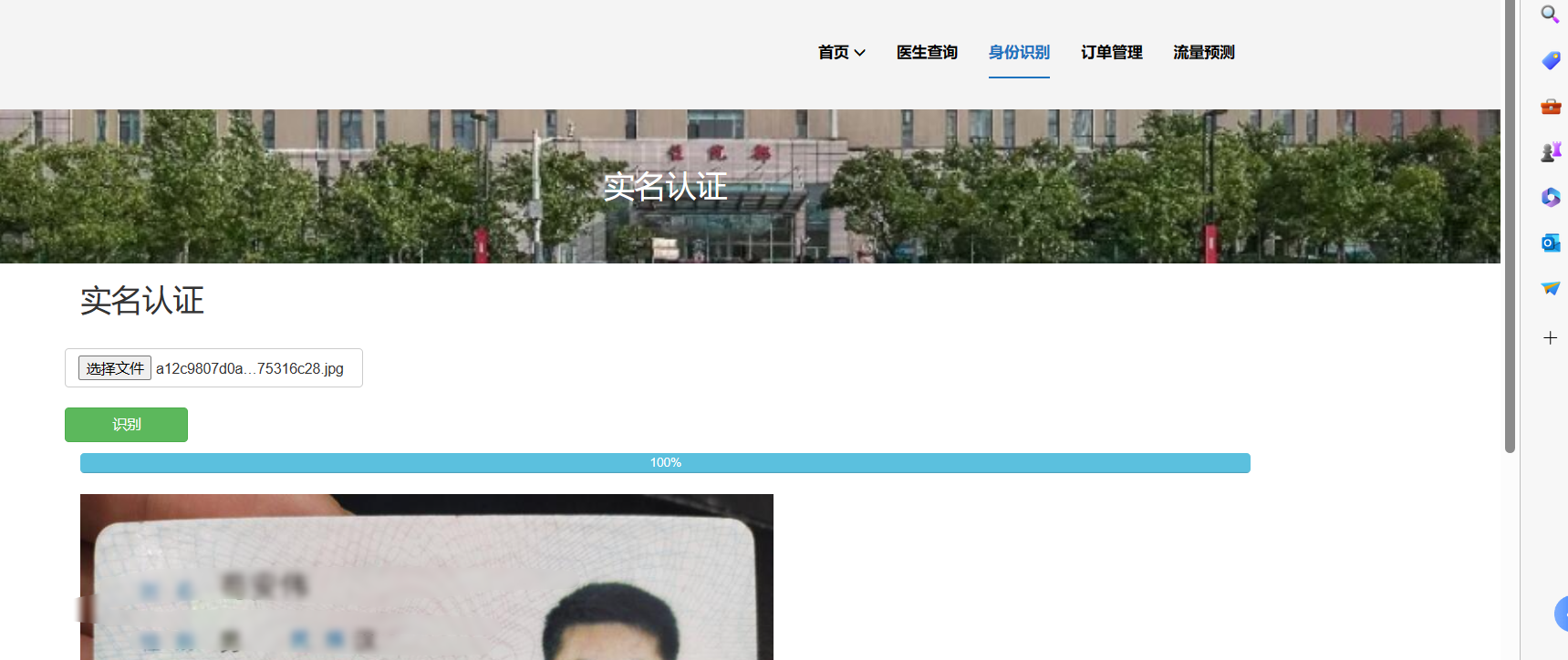












核心算法代码分享如下:
package com.bigdata.storm.kafka.util;import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;/*** @program: storm-kafka-api-demo* @description: redis工具类* @author: 小毕* @company: 清华大学深圳研究生院* @create: 2019-08-22 17:23*/
public class JedisUtil {/*redis连接池*/private static JedisPool pool;/***@Description: 返回redis连接池*@Param: *@return: *@Author: 小毕*@date: 2019/8/22 0022*/public static JedisPool getPool(){if(pool==null){//创建jedis连接池配置JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();//最大连接数jedisPoolConfig.setMaxTotal(20);//最大空闲连接jedisPoolConfig.setMaxIdle(5);pool=new JedisPool(jedisPoolConfig,"node03.hadoop.com",6379,3000);}return pool;}public static Jedis getConnection(){return getPool().getResource();}/* public static void main(String[] args) {//System.out.println(getPool());//System.out.println(getConnection().set("hello","world"));}*/}这篇关于计算机毕业设计师hadoop+spark+hive知识图谱医生推荐系统 医生数据分析可视化大屏 医生爬虫 医疗可视化 医生大数据 机器学习 大数据毕业设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







