本文主要是介绍GenAI-Arena:首个多模态生成 AI 排名开放平台,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
生成式 AI 指的是能够生成新内容(如图像、视频、文本等)的人工智能技术。近年来,生成式 AI 在图像和视频生成领域取得了突破性进展,例如:
- 艺术创作:生成式 AI 可以根据文本描述生成各种风格的艺术作品,例如风景画、人物肖像、抽象艺术等。
- 视觉内容增强:生成式 AI 可以用于视频剪辑、图像修复、图像风格迁移等,提升视觉内容的品质和效果。
- 医疗影像:生成式 AI 可以用于医学图像的生成和分割,辅助医生进行诊断和治疗。
尽管生成式 AI 取得了显著进展,但评估这些模型的性能仍然是一个挑战。传统的评估指标,例如 PSNR、SSIM、LPIPS、FID 等,虽然在某些方面提供了有价值的洞察,但在提供模型整体性能的全面评估方面往往不足,尤其是在涉及主观质量如美学和用户满意度时。
GenAI-Arena 旨在解决这一问题。它是一个开放的评估平台,允许用户参与评估不同的图像和视频生成模型。用户可以生成图像或视频,将它们并排比较,并为它们投票。通过利用用户的反馈和投票,GenAI-Arena 旨在提供一个更民主、更准确的模型性能评估方法。
1 生成式 AI 评估指标和生成式 AI 评估平台
1.1 生成式 AI 评估指标
- CLIPScore:通过计算图像和文本的 CLIP 嵌入的余弦相似度来衡量图像和文本的一致性。
- IS (Inception Score):衡量图像的多样性和清晰度。
- FID (Fréchet Inception Distance):衡量真实图像分布和生成图像分布之间的差异。
- PSNR (Peak Signal-to-Noise Ratio):衡量图像的重建质量。
- SSIM (Structural Similarity Index):衡量图像的结构相似性。
- LPIPS (Learned Perceptual Image Patch Similarity):衡量图像的感知相似性。
- MLLM (Multimodal Large Language Model) 作为评估指标:例如,T2I-CompBench 使用 miniGPT4 评估文本到图像生成任务,TIFA 使用视觉问答技术评估文本到图像生成任务,VIEScore 使用 MLLM 作为统一的评估指标。
1.2 生成式 AI 评估平台
- T2I-CompBench:评估组合文本到图像生成任务。
- HEIM:提供文本到图像任务的全面评估框架,包括安全性、毒性等方面。
- ImagenHub:评估文本到图像、图像编辑和其他图像生成任务。
- VBench:提供视频生成任务的评估方法。
- EvalCrafter:评估大型视频生成模型。
- Chatbot Arena:评估 LLM 的性能,用户可以通过聊天的方式与 LLM 进行交互并为其投票。
2 平台的设计与实现
GenAI-Arena是首个具有全面评估能力的平台,它不仅支持多种任务,包括文本到图像的生成、文本引导的图像编辑和文本到视频的生成,而且还包括一个公共投票过程,以确保标签的透明度。
2.1 设计概述
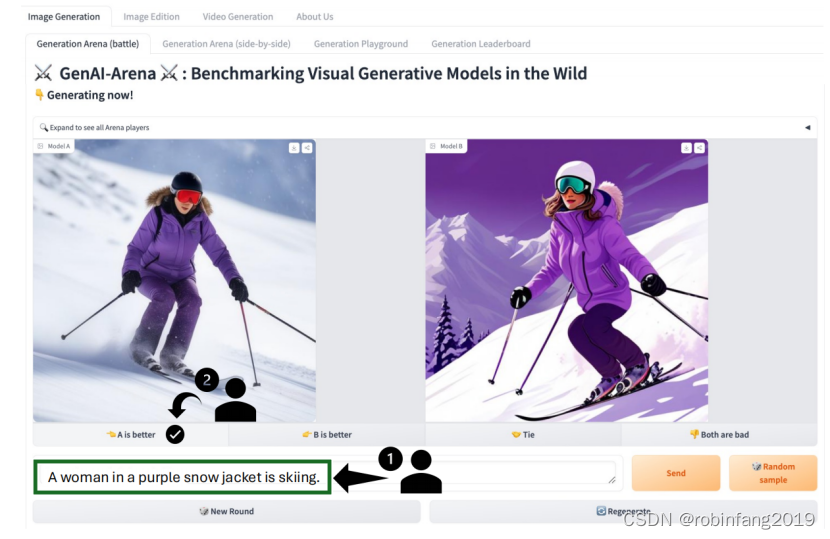
GenAI-Arena 提供一个直观和全面的评估平台,用于生成模型,促进用户交互和参与。平台围绕三个主要任务构建:文本到图像生成、图像编辑和文本到视频生成。每个任务都支持一组特性,包括:
- 匿名并排投票系统:用户可以将两个匿名模型的输出并排比较,并根据偏好进行投票。
- 对战 playground:用户可以输入提示,生成两个模型的输出并进行比较。
- 直接生成标签:用户可以直接生成模型的输出,并进行比较和投票。
- 排行榜:根据用户的投票,为所有评估模型生成 Elo 排行榜。
具体如下图所示:
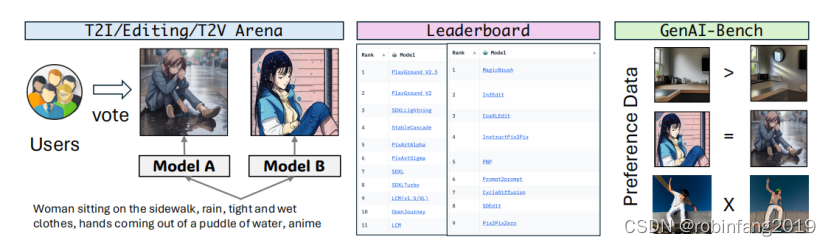
2.2 设计的关键
2.2.1 标准化推理
GenAI-Arena 标准化现有模型的代码库,并固定了超参数和提示格式,这使得不同模型的推理公平且可复现。遵循 ImagenHub 的做法,构建了 VideoGenHub 这个新库,旨在标准化不同文本到视频和图像到视频模型的推理过程。找到了这些模型的最佳超参数,以确保它们的最高性能。
2.2.2 投票规则
匿名战斗部分旨在确保无偏见的投票和对生成模型的准确评估。这部分的规则如下:
- 用户输入一个提示,然后用于从同一任务类别的两个匿名模型生成输出。
- 两个匿名模型生成的输出并排呈现以供比较。
- 用户可以根据他们的偏好进行投票,使用选项:1)左边更好;2)右边更好;3)平局;4)两者都不好。这四个选项用于计算 Elo 排名。
- 用户做出决定后,点击“投票”按钮提交他们的投票。重要的是要确保整个过程中模型的身份保持匿名。如果在互动过程中透露了模型身份,则不会计算投票。
2.2.2 模型集成
GenAI-Arena 集成了各种最先进的生成式 AI 模型,涵盖了不同的任务和技术。
2.2.2.1 文本到图像生成
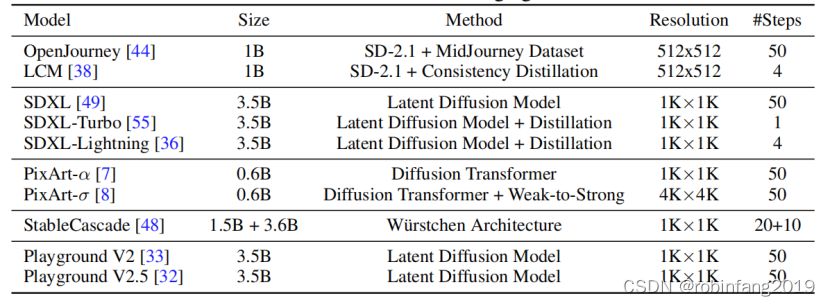
SDXL、SDXL-Turbo 和 SDXL-Lightning 都是基于 SDXL衍生的,而 SDXL-Turbo和 SDXL-Lightning采用了不同的蒸馏方法。
2.2.2.2 图像引导的图像编辑
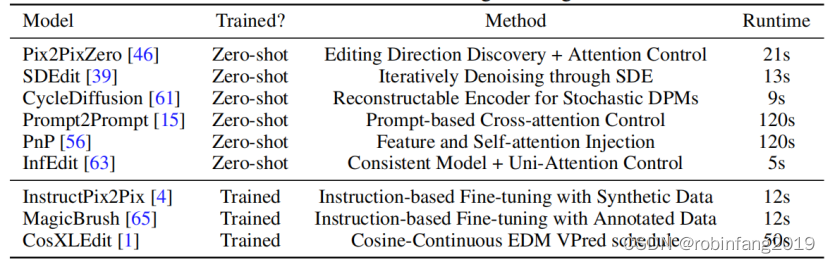
一些是即插即用方法,不需要任何训练,如 Pix2PixZero、InfEdit、SDEdit 等。这些方法可以应用于广泛的扩散模型。一些模型如 PnP 和 Prompt2Prompt 需要 DDIM 反演,这比其他方法需要的时间长得多。模型还包括了专门训练的图像编辑模型,如 InstructP2P 、MagicBrush 和 CosXLEdit 。
2.2.2.3 文本到视频生成
AnimateDiff 、ModelScope 、LaVie 是从 SD-1.5 初始化的,并通过注入运动层来捕获帧之间的时间关系继续训练的。与此相反,StableVideoDiffusion 和 VideoCrafter2是从 SD-2.1 初始化的。除了这些模型,还包括了 OpenSora ,它使用了类似 Sora 的扩散变换器架构进行联合时空注意力。

2.2.3 Bradley-Terry 模型
GenAI-Arena 使用 Bradley-Terry 模型进行统计估计 Elo 排名,以克服直接 Elo 计算的局限性。
2.2.4 置信区间
为了进一步调查估计的 Elo 评分的变异性,GenAI-Arena 使用了 Huber 等人描述的 "三明治" 标准误差。也就是说,对于每一轮,我们记录基于从前一轮中抽取的相同数量的战斗的估计 Elo 评分。这个过程持续了 100 轮。我们选择最低的采样 Elo 评分作为置信区间的下限,最高的采样 Elo 评分作为 Elo 评分的上限。
2.2.5 GenAI-Museum
当前 GenAI-Arena 在 Hugging Face Zero GPU 系统上运行模型,单个生成推理的时间通常在 5 到 120 秒之间。与自回归语言模型不同,后者使用如 VLLM 、SGLang等推理加速技术在不到一秒钟的时间内生成响应,扩散模型社区并没有这样强大的基础设施。因此,预计算成为减轻计算开销和简化用户交互的必要方式。
GenAI-Museum 作为一个预计算数据池,包含来自现有数据集或用户收集的各种输入,以及每个模型的输出。基于此,额外实现了一个 "随机样本" 按钮,以促进随机生成提示并立即检索相应的图像或视频。这个功能通过每次点击 "随机样本" 按钮时向部署的 GenAI-Museum 发送请求,接收输入和两个随机模型的预计算输出来操作。通过这种方式,我们在 GPU 上节省了计算时间,使用户能够在 UI 上进行即时比较和投票,并平衡每个独特输入的投票,以便我们逐渐收集所有模型的完整组合的投票。
3 GenAI-Arena 排行榜
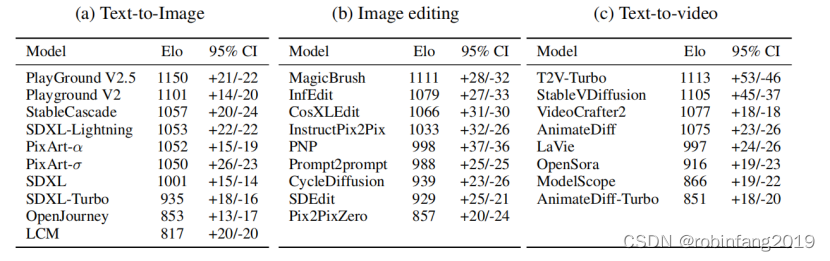
- 在图像生成方面,总共收集了 4443 票。当前排名最高的模型是 Playground V2.5 和 Playground V2,这两个模型都由 Playground.ai 发布,它们遵循与 SDXL 相同的架构,但是使用私有数据集进行训练。相比之下,SDXL 仅排名第七,明显落后。这一发现突显了训练数据集的重要性。在 Playground 模型之后是 StableCascade,它采用了高效的级联架构来降低训练成本。StableCascade 仅需要 SD-2.1 的 10% 训练成本,然而它在我们的排行榜上显著超过了 SDXL。这突显了扩散架构在实现强大性能方面的重要性。
- 在图像编辑方面,总共收集了 1083 票。MagicBrush、InFEdit、CosXLEdit 和 InstructPix2Pix 排名较高,因为它们可以在图像上执行局部编辑。PNP 通过特征注入保留了结构,因此限制了编辑的多样性。像 Prompt-to-Prompt、CycleDiffusion、SDEdit 和 Pix2PixZero 这样的旧方法,在编辑过程中经常导致完全不同的图像,尽管图像质量很高,这也解释了这些模型排名较低的原因。
- 在文本到视频方面,总共有 1568 票。T2VTurbo 以最高的 Elo 得分领先,表明它是最有效的模型。紧随其后的是 StableVideoDiffusion 排名第二。VideoCrafter2 和 AnimateDiff 的 Elo 得分非常接近,显示出几乎等同的能力。LaVie、OpenSora、ModelScope 和 AnimateDiff-Turbo 以递减的得分紧随其后,表明性能逐渐降低。
4 GenAI-Bench数据集
使用 Llama Guard 作为 NSFW 过滤器,以确保用户输入的提示适合广泛的受众,并保护基准测试的用户不接触到可能有害或冒犯的内容。在文本到图像生成任务中,总共收集了 4.3k 匿名投票,在过滤后剩下 1.7k 投票用于安全内容。观察到大量提示因性内容而被过滤掉,这占据了废弃数据的 85.6%。
- 数据集:用户投票数据,包含文本到图像生成、图像编辑、文本到视频生成任务。
- 相关性分析:将用户投票与 CLIPScore, GPT-4o, Gemini-1.5-Pro, Idefics2, Mantis 等指标进行相关性分析。
官网:https://huggingface.co/datasets/TIGER-Lab/GenAI-Bench
5 结论
- 成功构建了第一个基于用户偏好的多模态生成式 AI 排名平台,填补了现有评估平台的空白。
- 通过社区投票和 Elo 排名系统,提供了透明且可持续的评估方式。
- 收集了超过 6000 票,为模型性能提供了可靠的评估结果。
- 通过用户投票分析,揭示了现有 Elo 排名系统的局限性,并展示了用户投票的高质量。
这篇关于GenAI-Arena:首个多模态生成 AI 排名开放平台的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






