本文主要是介绍YOLOv5改进 | Head | 将yolov5的检测头替换为ASFF_Detect,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
在目标检测中,为了解决尺度变化的问题,通常采用金字塔特征表示。然而,对于基于特征金字塔的单次检测器来说,不同特征尺度之间的不一致性是一个主要限制。为此,研究人员提出了一种新颖的、基于数据的策略,用于金字塔特征融合,称为自适应空间特征融合(ASFF)。它学习了一种方法,用以在空间上过滤冲突信息,从而抑制不一致性,提高了特征的尺度不变性,并且几乎不引入额外的推理开销。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址: YOLOv5改进+入门——持续更新各种有效涨点方法 点击即可跳转
目录
1.原理
2. 将ASFF_DETECT代码实现
2.1 ASFF_DETECT添加到YOLOv5中
2.2 新增yaml文件
2.3 注册模块
2.4 执行程序
3. 完整代码分享
4. GFLOPs
5. 进阶
6. 总结
1.原理

论文地址:Learning Spatial Fusion for Single-Shot Object Detection——点击即可跳转
官方代码:官方代码仓库——点击即可跳转
自适应空间特征融合(ASFF)的主要原理旨在解决单次检测器中不同尺度特征的不一致性问题。具体来说,ASFF通过动态调整来自不同尺度特征金字塔层的特征贡献,确保每个检测对象的特征表示是一致且最优的。以下是ASFF的主要原理:
原理概述
-
多尺度特征的融合:
-
传统的特征金字塔网络(FPN)在不同尺度上提取特征,但这些特征在空间位置上可能存在不一致性,导致检测效果不佳。
-
ASFF通过一个自适应融合模块,动态地结合来自不同尺度的特征图,使得每个像素点能够获得来自各个尺度的最优特征表示。
-
-
自适应权重学习:
-
ASFF在训练过程中通过一个轻量级的网络结构(如1x1卷积层)学习自适应权重,这些权重用于加权组合来自不同尺度的特征。
-
这个学习过程是自适应的,即权重会根据输入图像的特征和目标物体的位置进行调整,从而确保融合后的特征在空间和语义上都是最优的。
-
-
特征一致性:
-
通过自适应权重,ASFF能有效地调节各尺度特征的贡献,解决了特征金字塔中不同层次特征之间的空间位置不一致性问题。
-
这种融合方式不仅增强了特征的一致性,还提高了检测器对各种尺度目标的响应能力。
-
具体步骤
-
特征提取:
输入图像通过基础卷积神经网络(如ResNet)提取特征,并通过特征金字塔网络(FPN)生成不同尺度的特征图。 -
权重生成:
对每个尺度的特征图,ASFF使用一个小型网络(如1x1卷积层)生成对应的自适应权重图。 -
特征融合:
将不同尺度的特征图与其对应的权重图逐像素相乘,然后进行加权求和,生成最终的融合特征图。 -
检测输出:
最终的融合特征图输入到检测头中,生成检测结果(如边界框和类别预测)。
优势
-
性能提升:通过自适应融合不同尺度的特征,ASFF显著提升了检测精度,特别是在复杂场景和多尺度目标检测任务中。
-
高效性:ASFF在提高性能的同时,保持了较低的计算开销,仅增加了极少的推理时间,适合实时应用。
ASFF的方法通过动态调整特征贡献,确保每个像素点在不同尺度特征上的最优组合,从而提高了单次检测器的整体检测性能。
2. 将ASFF_DETECT代码实现
2.1 ASFF_DETECT添加到YOLOv5中
关键步骤一:将下面代码粘贴到/yolov5-6.1/models/yolo.py文件中
class ASFF_Detect(nn.Module): #add ASFFV5 layer and Rfb stride = None # strides computed during buildonnx_dynamic = False # ONNX export parameterexport = False # export modedef __init__(self, nc=80, anchors=(), ch=(), multiplier=0.5,rfb=False,inplace=True): # detection layersuper().__init__()self.nc = nc # number of classesself.no = nc + 5 # number of outputs per anchorself.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsself.grid = [torch.zeros(1)] * self.nl # init gridself.l0_fusion = ASFFV5(level=0, multiplier=multiplier,rfb=rfb)self.l1_fusion = ASFFV5(level=1, multiplier=multiplier,rfb=rfb)self.l2_fusion = ASFFV5(level=2, multiplier=multiplier,rfb=rfb)self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor gridself.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output convself.inplace = inplace # use in-place ops (e.g. slice assignment)def forward(self, x):z = [] # inference outputresult=[]result.append(self.l2_fusion(x))result.append(self.l1_fusion(x))result.append(self.l0_fusion(x))x=result for i in range(self.nl):x[i] = self.m[i](x[i]) # convbs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training: # inferenceif self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)y = x[i].sigmoid() # https://github.com/iscyy/yoloairif self.inplace:y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xyy[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # whelse: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0xy = (xy * 2 + self.grid[i]) * self.stride[i] # xywh = (wh * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, conf), 4)z.append(y.view(bs, -1, self.no))return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)def _make_grid(self, nx=20, ny=20, i=0):d = self.anchors[i].devicet = self.anchors[i].dtypeshape = 1, self.na, ny, nx, 2 # grid shapey, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibilityyv, xv = torch.meshgrid(y, x, indexing='ij')else:yv, xv = torch.meshgrid(y, x)grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)#print(anchor_grid)return grid, anchor_grid
2.2 新增yaml文件
关键步骤二:在下/yolov5-6.1/models下新建文件 yolov5_ASFF.yaml并将下面代码复制进去
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, ASFF_Detect, [nc, anchors]], # Detect(P3, P4, P5)]2.3 注册模块
关键步骤三:在yolo.py中注册,
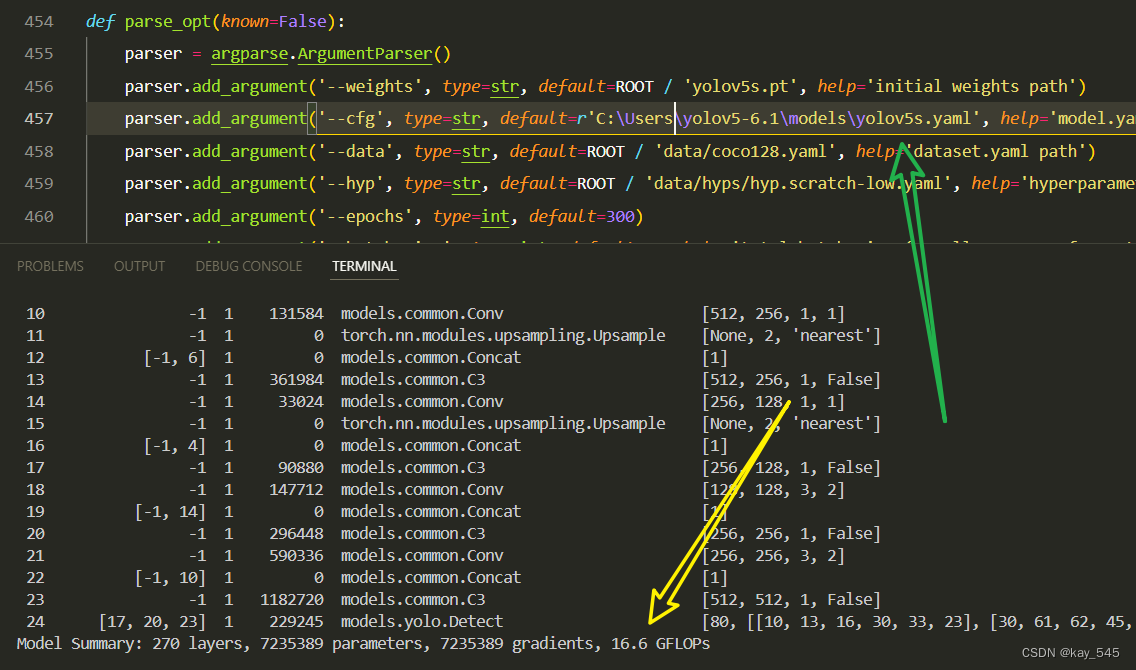
首先在model的类下面添加下面内容,位置如图所示

if isinstance(m, ASFF_Detect):s = 256 # 2x min stridem.inplace = self.inplacem.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forwardm.anchors /= m.stride.view(-1, 1, 1)check_anchor_order(m)self.stride = m.stridetry:self._initialize_biases() # only run once LOGGER.info('initialize_biases done')except:LOGGER.info('decoupled no biase ')然后修改_profile_one_layer函数下的代码为
c = isinstance(m, Detect) or isinstance(m, ASFF_Detect) # is final layer, copy input as inplace fix修改后如下图所示

修改_apply的内容
if isinstance(m, Detect) or isinstance(m, ASFF_Detect):修改后如下

在parse_model函数中注册模块
内容如下位置如下
elif m is ASFF_Detect:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)
2.4 执行程序
在train.py中,将cfg的参数路径设置为yolov5_ASFF.yaml的路径
建议大家写绝对路径,确保一定能找到

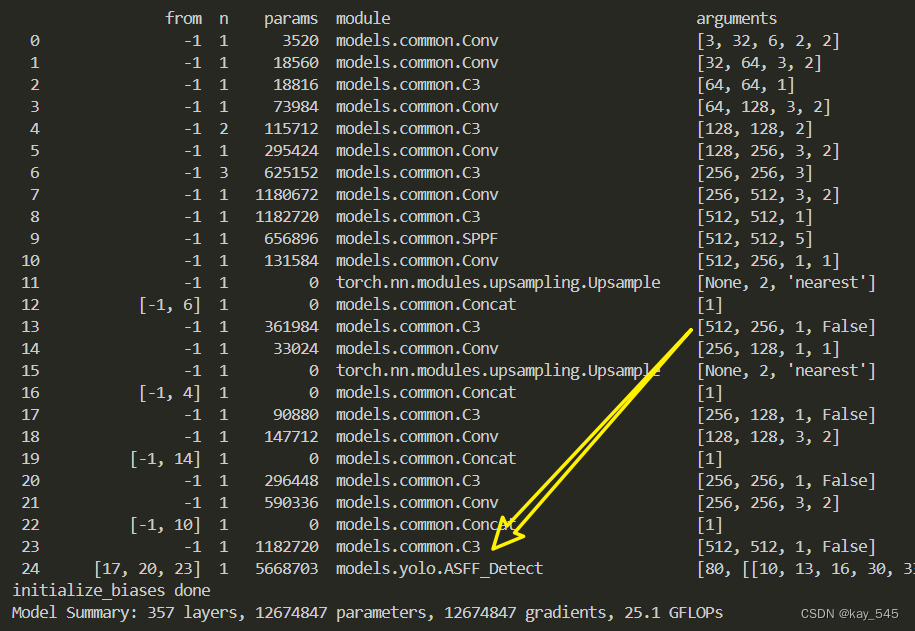
🚀运行程序,如果出现下面的内容则说明添加成功🚀
3. 完整代码分享
https://pan.baidu.com/s/1C98TemcSlia0n4ngAb9guQ?pwd=z6n4提取码: z6n4
4. GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
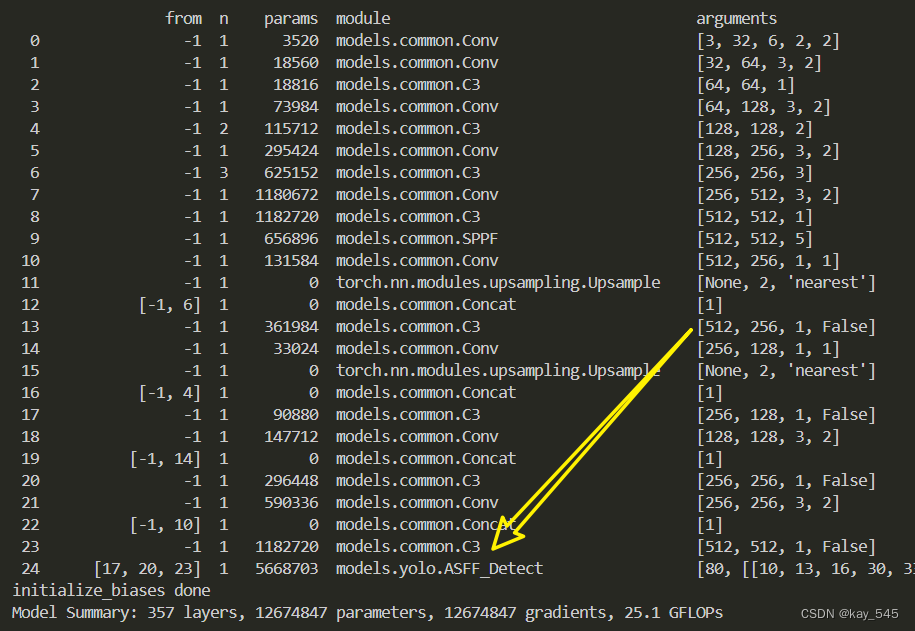
未改进的GFLOPs
改进后的GFLOPs
5. 进阶
现在的代码只能适配yolov5s版本,你能将他们扩展为更大的模型吗?
6. 总结
ASFF检测头的核心在于自适应地融合来自不同尺度的特征,以提高单次检测器的精度和鲁棒性。ASFF检测头首先通过基础卷积神经网络提取输入图像的基本特征,并通过特征金字塔网络(FPN)生成多个尺度的特征图。然后,ASFF模块在每个尺度上使用一个轻量级的网络(例如1x1卷积层)生成自适应权重图,这些权重图用来表示各个尺度特征对最终融合特征的贡献。接下来,不同尺度的特征图与对应的权重图逐像素相乘,再进行加权求和,生成一个融合后的特征图,该特征图在空间和语义上都更加一致。最后,这个融合特征图输入到检测头中,用于生成检测结果,包括物体的边界框和类别预测。通过这种自适应的特征融合方法,ASFF检测头有效地解决了不同尺度特征之间的不一致性问题,显著提高了检测精度,同时保持了较低的计算开销,使其适用于实时应用场景。
这篇关于YOLOv5改进 | Head | 将yolov5的检测头替换为ASFF_Detect的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







