本文主要是介绍第26讲:Ceph集群OSD扩缩容中Reblanceing数据重分布,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.Reblanceing数据重分布的概念
- 2.验证Reblanceing触发的过程
- 3.Reblanceing细节
- 4.临时关闭Reblanceing机制
1.Reblanceing数据重分布的概念
当集群中OSD进行扩缩容操作后,会触发一个Reblanceing数据重分布的机制,简单的理解就是将扩缩容前后OSD中的PG在每一个OSD中进行均匀分布,如下图所示:
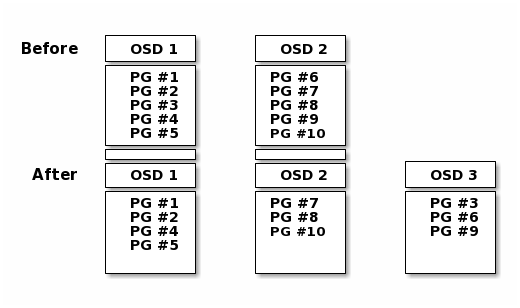
在扩容前集群有两个OSD节点,这两个OSD中分布着十个PG,扩容后,集群中有三个OSD节点,此时就会触发Reblanceing数据重分布机制,将原有的两个OSD中的一部分PG移动到第三个OSD中,使的每个OSD中的PG数量均衡。
Reblanceing数据重分布移动的是PG并不是Object,Object是存放在PG里的,如果要移动Object,数据量是非常大的,并且Object的数据也非常多,严重影响集群的性能,而PG的数量是有限的,移动PG是最好的方式。
Reblanceing数据重分布机制如何触发:
当集群中有新的OSD加入进来后,会将信息上报给Monitor,Monitor就会从Cluster Map中得知OSD Map发送了变化,只要OSD Map发送了变化,就会触发Reblanceing机制,使OSD中的PG平滑的移动到新的OSD。
在实际生产环境中,如果PG中的数据量非常大,在触发Reblanceing机制时,会对集群的性能有所影响,如果一次性增加很多个OSD节点,那么就意味着会有大量的PG被移动,此时就会对集群的性能产生巨大的影响,因此建议,每次在扩容OSD时,只扩容一个OSD。
2.验证Reblanceing触发的过程
向Ceph存储中写入大量数据,然后扩容一个OSD节点,观察Reblanceing的触发过程。
1)在Ceph存储中写入大量的数据
[root@ceph-node-1 ~]# cd /cephfs_data/
[root@ceph-node-1 cephfs_data]# dd if=/dev/zero of=reblanceing-file.txt bs=1M count=8192
2)新加一个OSD
[root@ceph-node-1 ceph-deploy]# ceph-deploy osd create ceph-node-2 --data /dev/sdd
3)观察Reblanceing机制的触发过程
[root@ceph-node-1 ~]# ceph -s
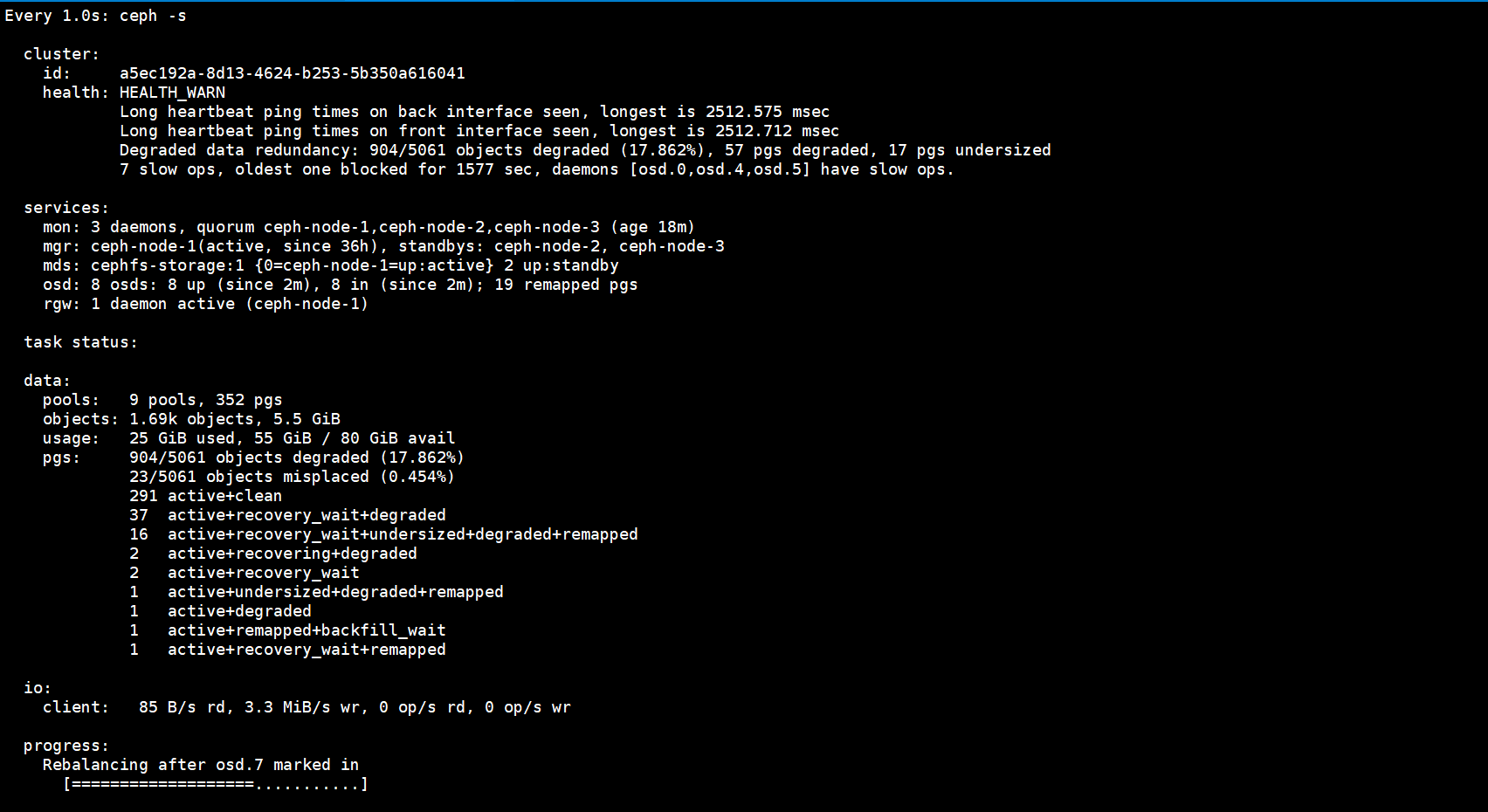
视频:
3.Reblanceing细节
在触发Reblanceing机制后,PG的迁移是比较慢的,那是因为OSD默认情况下只有一个线程,将线程数适当增加,可以提高迁移的速度,但是也会消耗部分的性能。
[root@ceph-node-1 ceph-deploy]# ceph --admin-daemon /var/run/ceph/ceph-mon.ceph-node-1.asok config show | grep max_backfills"osd_max_backfills": "1",
触发Reblanceing机制后,集群是使用配置的cluster_network进行通信的,在实际环境中,一定要将public_network和cluster_network网络分开,并且cluster_network网络要使用万兆口,可以提高速度。
4.临时关闭Reblanceing机制
在做Reblanceing时,如果集群正面临着业务繁忙,此时再使用Reblanceing就会对集群的性能产生影响,可以临时关闭Reblanceing,当业务量较小时,再开启。
1)关闭Reblanceing
1.关闭Reblanceing
[root@ceph-node-1 ~]# ceph osd set norebalance
norebalance is set
[root@ceph-node-1 ~]# ceph osd set nobackfill
nobackfill is setnobackfill也会做数据填充,也需要关闭2.查看集群的状态
[root@ceph-node-1 ~]# ceph -scluster:id: a5ec192a-8d13-4624-b253-5b350a616041health: HEALTH_WARNnobackfill,norebalance flag(s) set #reblanceing处于关闭状态
2)开启Reblanceing
[root@ceph-node-1 ~]# ceph osd unset nobackfill
nobackfill is unset
[root@ceph-node-1 ~]# ceph osd unset norebalance
norebalance is unset
这篇关于第26讲:Ceph集群OSD扩缩容中Reblanceing数据重分布的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





