本文主要是介绍设计模式和原则系列主题:如何利用迪米特法则实现“高内聚、低耦合”?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文转自:JavaEdge
目录
1 何为“高内聚、低耦合”?
1.1 高内聚
1.2 低耦合
1.3 “内聚”和“耦合”的关系
2 迪米特法则
3 案例
3.1 不该有直接依赖关系的类之间,不要有依赖
3.2 有依赖关系的类之间,尽量只依赖必要的接口。
4 总结
4.1 高内聚、低耦合
4.2 迪米特法则
1 何为“高内聚、低耦合”?
“高内聚、低耦合”能有效地提高代码可读性、可维护性,缩小功能改动导致的代码改动范围。很多设计原则也都以实现代码“高内聚、低耦合”为目的,比如:
-
单一职责原则
-
面向接口,而非面向实现来编程
“高内聚、低耦合”是个通用设计思想,可指导:
-
不同粒度代码的设计与开发
如系统、模块、类,甚至函数
-
不同开发场景
-
如微服务、框架、组件、类库等
本文主要围绕以“类”作为该设计思想的应用对象。
-
“高内聚”,指导类本身的设计
-
“低耦合”,指导类与类之间依赖关系的设计
二者并非完全独立,高内聚有助于低耦合,低耦合又需要高内聚的支持。
1.1 高内聚
-
相近的功能,应放到同一个类
-
不相近的功能,不要放到同一个类
相近的功能往往会被同时修改,放到同一类中,修改会比较集中,代码易维护。单一职责原则就是实现代码高内聚非常有效的设计原则。
1.2 低耦合
在代码中,类与类之间的依赖关系简单清晰。
即使两个类有依赖关系,一个类的代码改动不会或很少会导致依赖类的代码改动。依赖注入、接口隔离、面向接口编程及迪米特法则都是为实现低耦合。
1.3 “内聚”和“耦合”的关系
左边代码结构是“高内聚、低耦合”;右边“低内聚、紧耦合”:

左边的代码设计:
类的粒度较小,每个类的职责都比较单一。相近功能都放到了一个类,不相近功能分割到多个类。这样类更加独立,代码内聚性更好。
因为职责单一,所以每个类被依赖的类就会比较少,代码低耦合。一个类的修改,只会影响到一个依赖类的代码改动。只需要测试这一个依赖类是否还能正常工作即可。
右边代码设计:
类粒度比较大,低内聚,功能大而全,不相近的功能放到了一个类中。导致很多其他类都依赖该类。修改这个类的某功能代码时,会影响依赖它的多个类。我们需要测试这三个依赖类,是否还能正常工作,“牵一发而动全身”。
2 迪米特法则
Law of Demeter,LOD,从名字看不出这是个啥。它还有另外一个名字:最小知识原则。

结合实际,定义描述中的“模块”替换成“类”:
-
不该有直接依赖关系的类之间,不要有依赖
-
有依赖关系的类之间,尽量只依赖必要的接口(“有限知识”)
所以,迪米特法则其实包含两部分,下面用两个案例分别解读。
3 案例
3.1 不该有直接依赖关系的类之间,不要有依赖
简化的搜索引擎爬取网页,包含如下主要类:
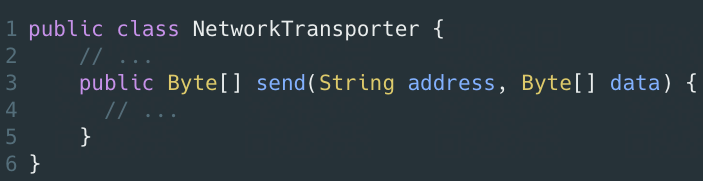
NetworkTransporter,负责底层网络通信,根据请求获取数据:

HtmlDownloader,通过URL获取网页:

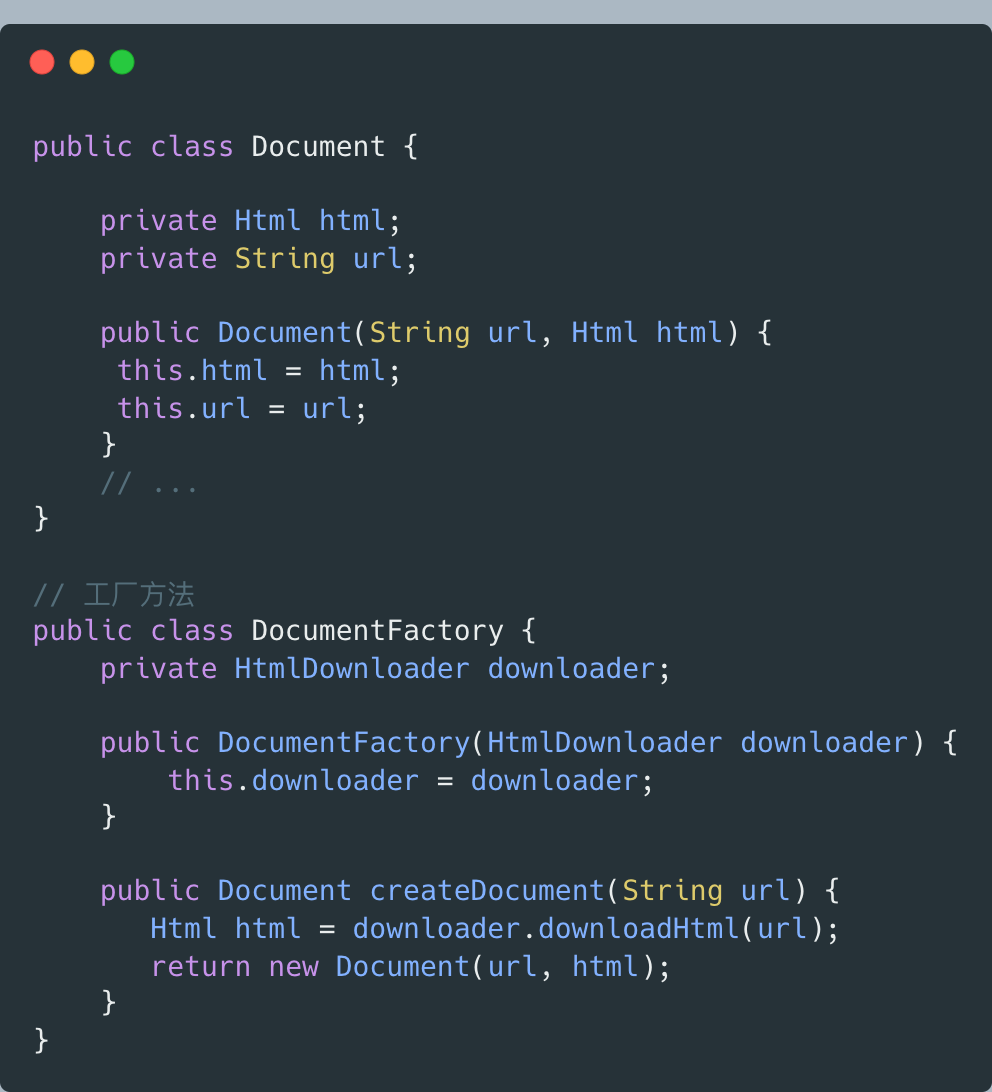
Document,表示网页文档,后续的网页内容抽取、分词、索引都是以此为处理对象:

如何重构?
这段代码虽然“能用”,但不够“好用”。
NetworkTransporter,作为一个底层网络通信类,应该尽可能通用,而不是只能下载HTML。所以,不应该直接依赖太具体的发送对象HtmlRequest,其设计违背迪米特法则,依赖了不该有直接依赖关系的HtmlRequest类。
假如你现在要去买东西,你肯定不会直接把钱包给收银员,让收银员自己从里面拿钱,而是你从钱包里把钱拿出来交给收银员。HtmlRequest对象相当于钱包,HtmlRequest里的address和content对象就相当于钱。
应将address和content交给NetworkTransporter,而非直接把HtmlRequest交给NetworkTransporter:
Document的问题:
-
构造器中的downloader.downloadHtml()逻辑复杂,耗时长,不应放到构造器,影响代码可测试性
-
HtmlDownloader对象在构造器通过new来创建,违反面向接口编程,也影响代码可测试性
-
业务上说,Document网页文档没必要依赖HtmlDownloader类,违背迪米特法则
问题虽多,但修改简单:
3.2 有依赖关系的类之间,尽量只依赖必要的接口。
Serialization类负责对象的序列化和反序列化:

单看类的设计,没问题。但若放到特定应用场景,假设项目中的有些类只用到序列化操作,而另一些类只用到反序列化。那么,基于 有依赖关系的类之间,尽量只依赖必要的接口:
-
只用到序列化操作的那部分类不应依赖反序列化接口
-
只用到反序列化操作的那部分类不应依赖序列化接口
据此,应将Serialization类
方案一:拆分为两个更小粒度的类
-
只负责序列化(Serializer类)
-
只负责反序列化(Deserializer类)

尽管拆分后的代码更能满足迪米特法则,但却违背高内聚。高内聚要求相近功能放到同一类中,方便功能修改时,修改的地方不太散乱。
针对本案例,若业务要求修改序列化实现方式,从JSON换成XML,则反序列化实现逻辑也要一起改。未拆分前,只需修改一个类,拆分后,却要修改两个类!
既不想违背高内聚,也不想违背迪米特法则,怎么办?
方案二:引入两个接口



尽管还是要往Demo1的构造器传入包含序列化和反序列化的Serialization实现类,但依赖的Serializable接口只包含序列化操作,Demo1无法使用Serialization类中的反序列化接口,对反序列化操作无感知,符合迪米特法则的“依赖有限接口”。
也体现了“面向接口编程”,结合迪米特法则,可总结出:“基于最小接口,而非最大实现来编程”。
多想一点点
本案例的重构方案,整个类只包含序列化、反序列化俩操作,只用到序列化操作的使用者,即便能够感知到仅有的一个反序列化方法,问题也不大。为满足迪米特法则,将一个简单的类,拆出两个接口,是过度设计吗?设计原则本身无对错,只有能否用对之说。不要为了用设计原则而用,应该具体问题具体分析。
Serialization类只包含两个操作,确实没啥必要拆成俩接口。但若对Serialization类添加更多功能,实现更多更好用的序列化、反序列化方法,重新考虑该问题:

这种场景下,方案二设计更好。因为本案例的应用场景,大部分代码只用到序列化功能,这些用户无需了解反序列化,而修改后的Serialization类,反序列化的“知识”,从一个方法变成三个。一旦任一反序列化操作有代码改动,都需要检查、测试所有依赖Serialization类的代码是否还能正常工作。
为减少耦合和降低测试的工作量,应按迪米特法则,隔离反序列化和序列化的功能。
4 总结
4.1 高内聚、低耦合
能有效提高代码的可读性和可维护性,缩小功能改动导致的代码改动范围:
-
高内聚,指导类本身的设计
就是指相近的功能应该放到同一个类中,不相近的功能不要放到同一类中。相近的功能往往会被同时修改,放到同一个类中,修改会比较集中
-
低耦合,指导类与类之间依赖关系的设计
在代码中,类与类之间的依赖关系简单清晰。即使两个类有依赖关系,一个类的代码改动也不会或者很少导致依赖类的代码改动。
4.2 迪米特法则
不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口。迪米特法则希望减少类之间的耦合,让类越独立越好。每个类都应该少了解系统的其他部分。一旦发生变化,需要了解这一变化的类就会比较少。
这篇关于设计模式和原则系列主题:如何利用迪米特法则实现“高内聚、低耦合”?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






