本文主要是介绍Faster-RCNN/SSD/训练将数据集做成VOC2007格式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
reference:
http://blog.csdn.net/sinat_30071459/article/details/50723212
0.文件夹名
首先,确定你的数据集所放的文件夹名字,例如我的叫logos。
(或者和voc2007一样的名字:VOC2007)
1.图片命名
虽然说图片名对训练没什么影响,但建议还是按VOC2007那样,如“000005.jpg”这种形式。至于图片格式,代码里是写的jpg,其他格式行不行我没有试过,我的训练集也是jpg格式的。
批量修改图片名字为VOC2007格式可以参考以下Matlab代码:
- %%
- %图片保存路径为:
- %E:\image\car
- %E:\image\person
- %car和person是保存车和行人的文件夹
- %这些文件夹还可以有多个,
- %放在image文件夹里就行
- %该代码的作用是将图片名字改成000123.jpg这种形式
- %%
- clc;
- clear;
-
- maindir='E:\image\';
- name_long=5; %图片名字的长度,如000123.jpg为6,最多9位,可修改
- num_begin=1; %图像命名开始的数字如000123.jpg开始的话就是123
-
- subdir = dir(maindir);
- n=1;
-
- for i = 1:length(subdir)
- if ~strcmp(subdir(i).name ,'.') && ~strcmp(subdir(i).name,'..')
- subsubdir = dir(strcat(maindir,subdir(i).name));
- for j=1:length(subsubdir)
- if ~strcmp(subsubdir(j).name ,'.') && ~strcmp(subsubdir(j).name,'..')
- img=imread([maindir,subdir(i).name,'\',subsubdir(j).name]);
- imshow(img);
- str=num2str(num_begin,'%09d');
- newname=strcat(str,'.jpg');
- newname=newname(end-(name_long+3):end);
- system(['rename ' [maindir,subdir(i).name,'\',subsubdir(j).name] ' ' newname]);
- num_begin=num_begin+1;
- fprintf('当前处理文件夹%s',subdir(i).name);
- fprintf('已经处理%d张图片\n',n);
- n=n+1;
- pause(0.1);%可以将暂停去掉
- end
- end
- end
- end
图片名如果比较特殊或者像1(1).jpg等这类可能无法重命名,可以使用imwrite,如:
- imwrite(img,strcat(save_path,newname));%改名后保存到另一文件夹,原图片不变
也可以使用Total Commander来批量重命名,非常方便,推荐使用这个工具。
2.打框
就是所谓的包围框,将图片的中所框的目标信息保存起来,我的是保存到txt里,如下:
- 000002.jpg car 44 28 132 121
- 000003.jpg car 54 19 243 178
- 000004.jpg car 168 6 298 164
前面是图片名,中间是目标类别,最后是目标的包围框坐标(左上角和右下角坐标)。
3.做xml
将第2步得到的txt转成xml。 如果每张图片有一个或多个包围框,可参考代码: VOC2007xml(这份代码生成的xml训练Matlab版本的FRCNN可能会出错,最好用下面修改过的)
这份代码生成的xml第一行含有版本和编码信息:<?xml version="1.0" encoding="utf-8"?>,并且含有空格,用来训练Faster RCNN可能会有问题,如下:
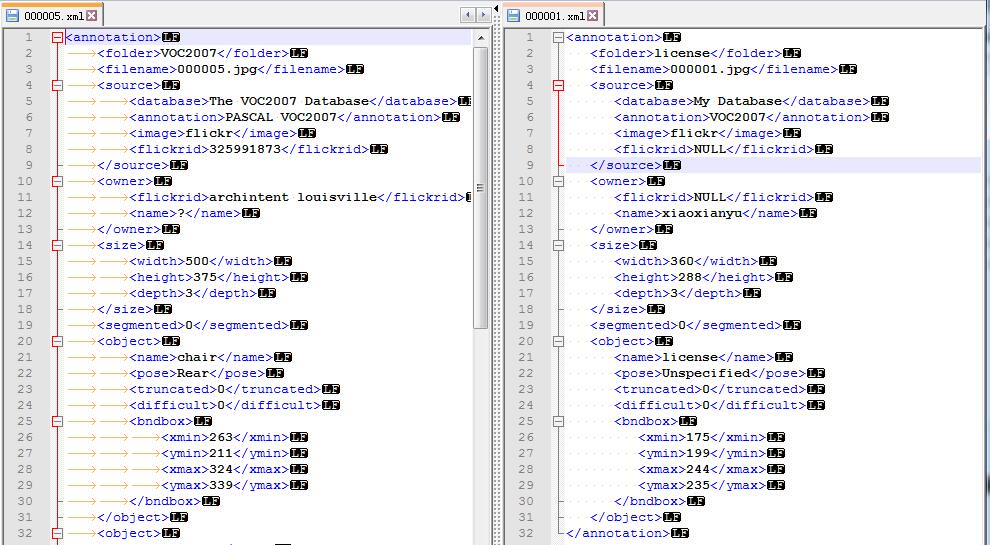
(左边是VOC2007数据集中的xml,右边是上面代码生成的xml(第一行我删掉了),用Notepad打开就可以看到)
VOC2007中的xml前面是tab字符(左边那些箭头),上面代码生成的xml是空格(那些小黄点),所以,必须将空格转换成tab,下载修改过的代码: VOC2007xml_new
(下载VOC2007xml_new就可以了,不用下载VOC2007xml,不过如果xml用作其他用途还是可以的)
最终,得到的xml就和VOC一样。
4.保存xml到Annotations
新建一个文件夹,名字为Annotations,将xml文件全部放到该文件夹里。
5.将训练图片放到JPEGImages
新建一个文件夹,名字为JPEGImages,将所有的训练图片放到该文件夹里。
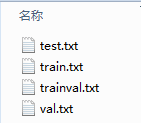
6.ImageSets\Main里的四个txt文件
新建文件夹,命名为ImageSets,在ImageSets里再新建文件夹,命名为Main。
我们可以通过xml名字(或图片名),生成四个txt文件,即:
txt文件中的内容为:
- 000005
- 000027
- 000028
- 000033
- 000042
- 000045
- 000048
- 000058
即图片名字(无后缀),test.txt是测试集,train.txt是训练集,val.txt是验证集,trainval.txt是训练和验证集.VOC2007中,trainval大概是整个数据集的50%,test也大概是整个数据集的50%;train大概是trainval的50%,val大概是trainval的50%。可参考以下代码:
- %%
- %该代码根据已生成的xml,制作VOC2007数据集中的trainval.txt;train.txt;test.txt和val.txt
- %trainval占总数据集的50%,test占总数据集的50%;train占trainval的50%,val占trainval的50%;
- %上面所占百分比可根据自己的数据集修改,如果数据集比较少,test和val可少一些
- %%
- %注意修改下面四个值
- xmlfilepath='E:\Annotations';
- txtsavepath='E:\ImageSets\Main\';
- trainval_percent=0.5;%trainval占整个数据集的百分比,剩下部分就是test所占百分比
- train_percent=0.5;%train占trainval的百分比,剩下部分就是val所占百分比
-
-
- %%
- xmlfile=dir(xmlfilepath);
- numOfxml=length(xmlfile)-2;%减去.和.. 总的数据集大小
-
-
- trainval=sort(randperm(numOfxml,floor(numOfxml*trainval_percent)));
- test=sort(setdiff(1:numOfxml,trainval));
-
-
- trainvalsize=length(trainval);%trainval的大小
- train=sort(trainval(randperm(trainvalsize,floor(trainvalsize*train_percent))));
- val=sort(setdiff(trainval,train));
-
-
- ftrainval=fopen([txtsavepath 'trainval.txt'],'w');
- ftest=fopen([txtsavepath 'test.txt'],'w');
- ftrain=fopen([txtsavepath 'train.txt'],'w');
- fval=fopen([txtsavepath 'val.txt'],'w');
-
-
- for i=1:numOfxml
- if ismember(i,trainval)
- fprintf(ftrainval,'%s\n',xmlfile(i+2).name(1:end-4));
- if ismember(i,train)
- fprintf(ftrain,'%s\n',xmlfile(i+2).name(1:end-4));
- else
- fprintf(fval,'%s\n',xmlfile(i+2).name(1:end-4));
- end
- else
- fprintf(ftest,'%s\n',xmlfile(i+2).name(1:end-4));
- end
- end
- fclose(ftrainval);
- fclose(ftrain);
- fclose(fval);
- fclose(ftest);
这四个txt放在ImageSets\Main中。
这样,数据集就基本做好了。然后新建文件夹,名字为logos(第0步确定的名字),将上面三个文件夹放到这里,即logos文件夹里有三个文件夹:
将logos文件夹拷贝到datasets\VOCdevkit2007里就可以了。
(或者替换voc2007数据集中的Annotations、ImageSets和JPEGImages,免去一些训练的修改)
Matlab版本faster-rcnn训练过程看 http://blog.csdn.net/sinat_30071459/article/details/50546891;
python版本faster-rcnn训练过程看 http://blog.csdn.net/sinat_30071459/article/details/51332084。
这篇关于Faster-RCNN/SSD/训练将数据集做成VOC2007格式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!