本文主要是介绍算法金 | AI 基石,无处不在的朴素贝叶斯算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
历史上,许多杰出人才在他们有生之年默默无闻,
却在逝世后被人们广泛追忆和崇拜。
18世纪的数学家托马斯·贝叶斯(Thomas Bayes)便是这样一位人物

贝叶斯的研究,初看似平凡,其人亦未显赫。
其论文,逝后一年,方由友手于1763年公诸于世。
如梵高之画,生前默默无闻,逝后价值倍增。
贝叶斯定理,两百年沉埋,因违旧学,被疑“非科学”。
但在 20 世纪,这一理论被重新发现并广泛应用于各个领域,如机器学习、医学诊断和金融分析等
它是隐藏在 AI 背后的智能基石。

1. 贝叶斯定理
1.1 基本概念

1.2 数学公式
为了更好地理解贝叶斯定理,我们可以用一个例子来说明。假设我们有一组关于江湖门派的武林高手的信息:

2. 朴素贝叶斯分类器
2.1 概述
朴素贝叶斯分类器是一种基于贝叶斯定理的简单但强大的分类算法。它假设特征之间是独立的,即某一特征的出现与其他特征的出现没有关系。尽管这一假设在实际中很少成立,但朴素贝叶斯分类器在许多实际问题中表现非常出色。简直是神奇绝绝子~
2.2 数学公式
朴素贝叶斯分类器的核心公式如下:

添加图片注释,不超过 140 字(可选)
2.3 应用领域
朴素贝叶斯分类器广泛应用于文本分类、垃圾邮件检测、情感分析等领域。例如,它可以用来根据电子邮件的内容判断一封邮件是否为垃圾邮件。

3. 贝叶斯网络
3.1 概述
贝叶斯网络是一种表示变量之间条件依赖关系的有向无环图。它不仅可以用于概率推断,还能用于决策分析、因果推理等领域。贝叶斯网络的节点表示随机变量,边表示变量之间的条件依赖关系。
3.2 结构与组成
贝叶斯网络由节点和有向边组成。每个节点对应一个随机变量,而有向边表示两个变量之间的条件依赖关系。贝叶斯网络的结构和条件概率分布可以通过观察数据和领域知识来构建。
例如,我们可以构建一个简单的贝叶斯网络来描述武侠门派之间的关系:
- 节点 A:门派(少林、武当、峨眉、华山、丐帮)
- 节点 B:内力水平
- 节点 C:是否为武林高手
节点 A 和 B 之间有一条有向边,表示门派影响内力水平;节点 B 和 C 之间有一条有向边,表示内力水平影响是否为武林高手。
3.3 应用领域
贝叶斯网络广泛应用于医学诊断、风险管理、故障检测等领域。例如,在医学诊断中,贝叶斯网络可以用来推断患者的疾病类型及其可能的病因。
更多应用,见算法金 往期微*公*号 文章: 最经典的一个算法 - 贝叶斯算法,附 Python 代码

4. 贝叶斯推理
4.1 概述
贝叶斯推理是一种基于贝叶斯定理的推理方法,用于更新对某一事件的信念。它在统计推断、机器学习、人工智能等领域具有广泛应用。贝叶斯推理可以根据新证据不断调整对事件的概率估计,使其更符合实际情况。
4.2 贝叶斯更新
贝叶斯更新是贝叶斯推理的核心过程。当新的证据出现时,我们可以使用贝叶斯定理来更新事件的概率。例如,假设我们已经知道某人来自少林派,现在我们得到新的证据,该人具有很高的内力。我们可以使用贝叶斯定理来更新该人是武林高手的概率。

4.3 实际应用
为了使大侠更好地理解贝叶斯推理的实际应用,我们用一个包含武侠元素的数据集来演示贝叶斯推理的过程。
4.4 代码示范
下面,我们使用贝叶斯更新来进行推理,假设我们有一个包含武侠元素的数据集,并使用 scipy 库进行推理。
import scipy.stats as stats# 生成武侠数据集
np.random.seed(42)
data = {'门派': np.random.choice(['少林', '武当', '峨眉', '华山', '丐帮'], 100),'内力': np.random.randint(50, 150, 100),'是否高手': np.random.choice([1, 0], 100, p=[0.3, 0.7])
}
df = pd.DataFrame(data)# 先验概率 P(高手|少林)
prior_prob = df[df['门派'] == '少林']['是否高手'].mean()# 似然函数 P(高内力|高手) 和 P(高内力|少林)
likelihood_high_power_given_master = stats.norm(loc=120, scale=10).pdf(140) # 高手的高内力分布
likelihood_high_power_given_shaolin = df[df['门派'] == '少林']['内力'].mean()# 证据 P(高内力)
evidence = df['内力'].mean()# 贝叶斯更新
posterior_prob = (likelihood_high_power_given_master * prior_prob) / likelihood_high_power_given_shaolinprint(f'更新后的概率: {posterior_prob:.2f}')# 可视化贝叶斯更新过程
labels = ['Prior', 'Likelihood', 'Posterior']
values = [prior_prob, likelihood_high_power_given_master, posterior_prob]plt.figure(figsize=(10, 6))
plt.bar(labels, values, color=['skyblue', 'lightgreen', 'salmon'])
plt.xlabel('阶段')
plt.ylabel('概率')
plt.title('贝叶斯更新过程')
plt.show()
运行后输出:更新后的概率: 0.73
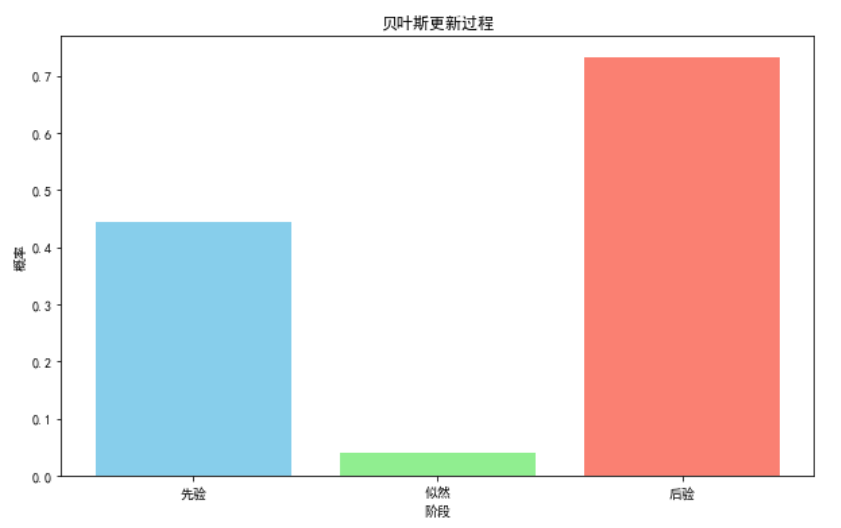
- 先验(Prior):
- 先验概率表示在没有新证据的情况下,我们对某个事件的初始信念。在这个例子中,先验概率是某人是少林派的情况下,他是武林高手的概率。
- 在图中,先验概率的条形显示了我们在新证据(内力水平)出现之前对某人是武林高手的初始信念。
- 似然(Likelihood):
- 似然函数表示在给定条件下某个事件发生的可能性。在这个例子中,似然函数是某人是武林高手的情况下,他具有高内力的概率。
- 图中显示的似然概率条形代表了如果某人是武林高手,他具有高内力的可能性。
- 后验(Posterior):
- 后验概率是结合新证据后更新的信念。在这个例子中,后验概率是某人具有高内力的情况下,他是少林派的武林高手的概率。
- 图中后验概率的条形显示了在考虑新证据(高内力)后,我们对某人是武林高手的更新后的信念。
具体解释
- 先验概率:大约0.5,表示在没有额外信息的情况下,有50%的可能性某人是少林派的武林高手。
- 似然概率:大约0.024,表示如果某人是武林高手,他具有140内力的可能性较低。
- 后验概率:0.73,表示结合新证据(高内力)后,我们更新后的信念,即某人是少林派的武林高手的概率显著提高。
通过这个可视化图表,我们可以清晰地看到贝叶斯更新过程如何结合先验信息和新证据来调整对某个事件的概率估计,从而提供更加合理的决策依据。

5. 贝叶斯算法的优缺点
5.1 优点
大侠,贝叶斯算法有许多优点,使其在各种应用中广受欢迎:
- 处理不确定性:贝叶斯算法可以很好地处理不确定性,更新概率以反映新信息。
- 灵活性:适用于多种数据类型和应用场景,无论是分类、回归还是决策分析。
- 直观性:贝叶斯定理提供了一个清晰的数学框架,使推理过程直观且易于解释。
5.2 缺点
然而,贝叶斯算法也有其局限性:
- 计算复杂性:当涉及多个变量时,计算量可能会迅速增加,尤其是在大数据集上。
- 先验选择:先验概率的选择对结果有较大影响,且在缺乏领域知识时可能难以确定。
- 独立假设:朴素贝叶斯假设特征独立,这在实际中很少成立,可能导致性能下降。
5.3 适用场景
贝叶斯算法适用于以下场景:
- 小数据集:贝叶斯算法在小数据集上通常表现良好,因为它能有效结合先验知识。
- 不确定性高:在需要处理高不确定性的数据时,贝叶斯算法表现出色。
- 解释性要求高:当需要解释模型决策过程时,贝叶斯算法提供了清晰的框架。
6. 贝叶斯算法在机器学习中的应用
6.1 自然语言处理
贝叶斯算法在自然语言处理(NLP)中具有广泛应用。朴素贝叶斯分类器常用于文本分类任务,如垃圾邮件检测和情感分析。它通过计算词语在不同类别中的条件概率来进行分类。
6.2 图像识别
在图像识别领域,贝叶斯算法可用于处理不确定性。例如,在医学影像分析中,贝叶斯网络可以结合多个影像特征来推断疾病的可能性,提供更准确的诊断。
6.3 其他应用领域
贝叶斯算法还应用于金融风险管理、市场营销分析和推荐系统等领域。它能够处理复杂的概率关系,为决策提供强有力的支持。
代码示范
下面,我们将展示贝叶斯算法在垃圾邮件检测中的应用,并进行结果的可视化。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
import random# 生成武侠邮件数据集
emails = []
labels = []# 垃圾邮件样本
spam_phrases = ['免费的', '学会这几招', '武功秘籍', '银行账户有异常活动', '购买武器打折促销','今日特价', '限时优惠', '点击获取', '立即下载', '尊敬的大侠'
]# 正常邮件样本
ham_phrases = ['天气真好', '适合练功', '信用卡账单已生成', '今晚有场比武大赛', '好友邀请你加入','武术交流大会', '闭关修炼活动', '诚邀各位大侠', '本月活动', '成为一名弟子'
]# 生成邮件
for _ in range(1000):if random.random() > 0.5:email = ','.join(random.sample(spam_phrases, 3))emails.append(email)labels.append('垃圾邮件')else:email = ','.join(random.sample(ham_phrases, 3))emails.append(email)labels.append('正常邮件')# 特征提取
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(emails)
y = np.array([1 if label == '垃圾邮件' else 0 for label in labels])# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)# 训练朴素贝叶斯分类器
nb_classifier = MultinomialNB()
nb_classifier.fit(X_train, y_train)# 预测
y_pred = nb_classifier.predict(X_test)# 评估
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)print(f'准确率: {accuracy:.2f}')
print('混淆矩阵:')
print(conf_matrix)# 可视化结果
labels = ['正常邮件', '垃圾邮件']
fig, ax = plt.subplots(figsize=(8, 6))
cax = ax.matshow(conf_matrix, cmap=plt.cm.Blues)
plt.title('垃圾邮件检测的混淆矩阵')
fig.colorbar(cax)
ax.set_xticklabels([''] + labels)
ax.set_yticklabels([''] + labels)
plt.xlabel('预测标签')
plt.ylabel('真实标签')[ 抱个拳,总个结 ]
贝叶斯算法以其处理不确定性的独特优势,在统计推断和机器学习中占据了重要地位。通过结合先验知识和新证据,贝叶斯方法能够动态更新概率,使决策过程更加合理和精确。此外,贝叶斯算法的直观性和解释性也使其在实际应用中非常受欢迎。
贝叶斯算法的应用前景十分广阔。它在自然语言处理、图像识别、医学诊断、金融风险管理等领域已经展现出了巨大的潜力。例如,在自然语言处理中,朴素贝叶斯分类器能够有效地进行文本分类和情感分析;在医学影像分析中,贝叶斯网络能够结合多种特征进行精确的疾病诊断。
祝在武林的征途上,一帆风顺,武运昌隆!
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵 内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
节日安康呀,喵~

全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖
这篇关于算法金 | AI 基石,无处不在的朴素贝叶斯算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









