本文主要是介绍hbase架构原理之region、memstore、hfile、hlog、columm-family、colum、cell(有时间看),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
hbase架构原理之region、memstore、hfile、hlog、columm-family、colum、cell
2017年11月08日 16:34:52 亚当-adam 阅读数:957
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/zhaojianting/article/details/78480329
Hbase的顶级存储结构是表,Hbase的表可以理解成是行的集合,行(记录)是列族的集合,列族是列的集合。这里有重点介绍几个容易混爻的几个感念!
HBase采用Master/Slave架构搭建集群,它隶属于Hadoop生态系统,由一下类型节点组成:HMaster节点、HRegionServer节点、ZooKeeper集群,而在底层,
它将数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等,总体结构如下: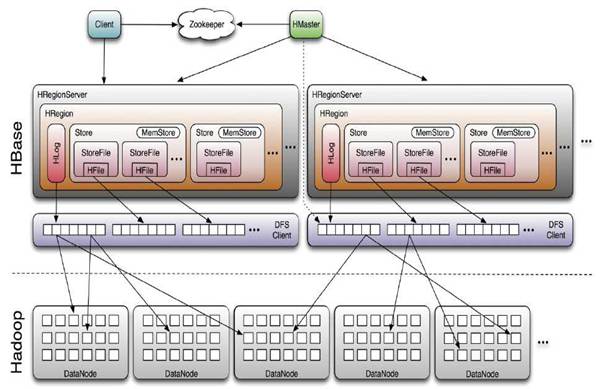
其中HMaster节点用于:
管理HRegionServer,实现其负载均衡。
管理和分配HRegion,比如在HRegion split时分配新的HRegion;
在HRegionServer退出时迁移其内的HRegion到其他HRegionServer上。实现DDL操作(Data Definition Language,namespace和table的增删改,column familiy的增删改等)。
管理namespace和table的元数据(实际存储在HDFS上)。
权限控制(ACL)。
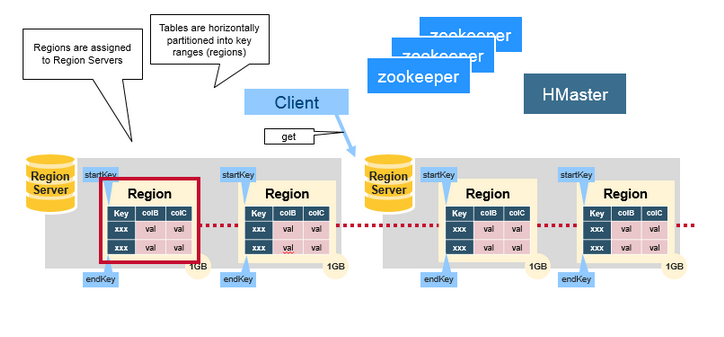
HRegion
假设我们有100亿条数据,这么大的数据无法存储到一台机器上,这时hbase水平切分成不同的分片,分片就是region,一个regionServer包含若干region,由于是水平切分,一条完整的数据一定是只属于一个region,其实hbase底层存存储结构是key-value形式的,key就是row-key!
HBase使用RowKey将表水平切割成多个HRegion,从HMaster的角度,每个HRegion都纪录了它的StartKey和EndKey(第一个HRegion的StartKey为空,
最后一个HRegion的EndKey为空),由于RowKey是排序的,因而Client可以通过HMaster快速的定位每个RowKey在哪个HRegion中。HRegion由HMaster分
配到相应的HRegionServer中,然后由HRegionServer负责HRegion的启动和管理,和Client的通信,负责数据的读(使用HDFS)。
列族column family
它是column的集合,在创建表的时候就指定,不能频繁修改。值得注意的是,列族的数量越少越好,因为过多的列族相互之间会影响,生产环境
中的列族一般是一个到两个。数据的持久化文件HFile中是按照Key-Value存储的,同一个列族的所有列存储在同一个底层存储文件里。每个列族在物理上
有自己的Hfile集合,Hbase的数据在HDFS中的路径结构如下:
hdfs://h201:8020/hbase/data/${名字空间}/${表名}/${区域名称}/${列族名称}/${文件名}
举例:/hbase/data/ns1/t1/a4d63a61a8da24a863bff3c8d7cd20de/f1/c2a7fa8c41304b9e9b8b24b4a89171ce
其中{区域名称}是t1的region, 由每张表切割形成,一张表由若干个region组成,不同的region分到不同的region server以便均衡负载
列column
和列族的限制数量不同,列族可以包含很多个列,前面说的“几十亿行*百万列”就是这个意思。
列的值cell
存在单元格(cell)中。每一列的值允许有多个版本,由timestamp来区分不同版本。多个版本产生原因:向同一行下面的同一个列多次插入数据,
每插入一次就有一个对应版本的value。
MemStore Flush
MemStore是一个In Memory Sorted Buffer,在每个HStore中都有一个MemStore,即它是一个HRegion的一个Column Family对应一个实例。它的排列顺序以
RowKey、Column Family、Column的顺序以及Timestamp的倒序,如下所示: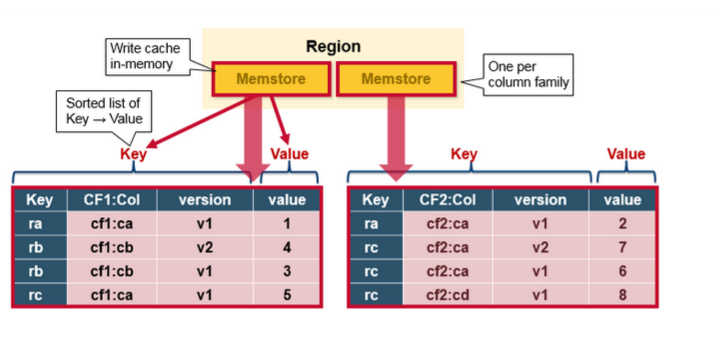
每一次Put/Delete请求都是先写入到MemStore中,当MemStore满后会Flush成一个新的StoreFile(底层实现是HFile),即一个HStore(Column Family)可以有0个或
多个StoreFile(HFile)。有以下三种情况可以触发MemStore的Flush动作,需要注意的是MemStore的最小Flush单元是HRegion而不是单个MemStore。据说这是
Column Family有个数限制的其中一个原因,估计是因为太多的Column Family一起Flush会引起性能问题?具体原因有待考证。
- 当一个HRegion中的所有MemStore的大小总和超过了hbase.hregion.memstore.flush.size的大小,默认128MB。此时当前的HRegion中所有的MemStore会Flush到HDFS中。
- 当全局MemStore的大小超过了hbase.regionserver.global.memstore.upperLimit的大小,默认40%的内存使用量。此时当前HRegionServer中所有HRegion中的MemStore都会Flush到HDFS中,Flush顺序是MemStore大小的倒序(一个HRegion中所有MemStore总和作为该HRegion的MemStore的大小还是选取最大的MemStore作为参考?有待考证),直到总体的MemStore使用量低于hbase.regionserver.global.memstore.lowerLimit,默认38%的内存使用量。
- 当前HRegionServer中WAL的大小超过了hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs的数量,当前HRegionServer中所有HRegion中的MemStore都会Flush到HDFS中,Flush使用时间顺序,最早的MemStore先Flush直到WAL的数量少于hbase.regionserver.hlog.blocksize * hbase.regionserver.max.logs。这里说这两个相乘的默认大小是2GB,查代码,hbase.regionserver.max.logs默认值是32,而hbase.regionserver.hlog.blocksize是HDFS的默认blocksize,32MB。但不管怎么样,因为这个大小超过限制引起的Flush不是一件好事,可能引起长时间的延迟,因而这篇文章给的建议:“Hint: keep hbase.regionserver.hlog.blocksize * hbase.regionserver.maxlogs just a bit above hbase.regionserver.global.memstore.lowerLimit * HBASE_HEAPSIZE.”。并且需要注意,这里给的描述是有错的(虽然它是官方的文档)。
在MemStore Flush过程中,还会在尾部追加一些meta数据,其中就包括Flush时最大的WAL sequence值,以告诉HBase这个StoreFile写入的最新数据的序列,那么在Recover时就直到从哪里开始。在HRegion启动时,这个sequence会被读取,并取最大的作为下一次更新时的起始sequence。
HFile格式
HBase的数据以KeyValue(Cell)的形式顺序的存储在HFile中,在MemStore的Flush过程中生成HFile,由于MemStore中存储的Cell遵循相同的排列顺序,因而Flush过程是顺序写,我们直到磁盘的顺序写性能很高,因为不需要不停的移动磁盘指针。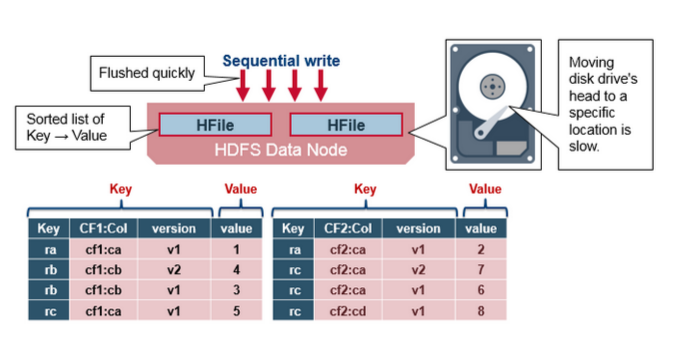
HFile参考BigTable的SSTable和Hadoop的TFile实现,从HBase开始到现在,HFile经历了三个版本,其中V2在0.92引入,V3在0.98引入。首先我们来看一下
V1的格式: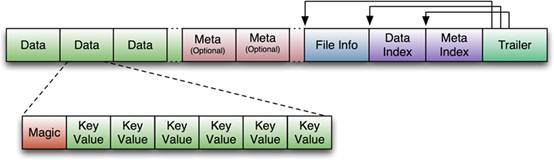
V1的HFile由多个Data Block、Meta Block、FileInfo、Data Index、Meta Index、Trailer组成,其中Data Block是HBase的最小存储单元,在前文中提到的
BlockCache就是基于Data Block的缓存的。一个Data Block由一个魔数和一系列的KeyValue(Cell)组成,魔数是一个随机的数字,用于表示这是一个Data Block
类型,以快速监测这个Data Block的格式,防止数据的破坏。Data Block的大小可以在创建Column Family时设置(HColumnDescriptor.setBlockSize()),默认值
是64KB,大号的Block有利于顺序Scan,小号Block利于随机查询,因而需要权衡。Meta块是可选的,FileInfo是固定长度的块,它纪录了文件的一些Meta信息,
例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。Data Index和Meta Index纪录了每个Data块和Meta块的其实
点、未压缩时大小、Key(起始RowKey?)等。Trailer纪录了FileInfo、Data Index、Meta Index块的起始位置,Data Index和Meta Index索引的数量等。其中
FileInfo和Trailer是固定长度的。
HFile里面的每个KeyValue对就是一个简单的byte数组。但是这个byte数组里面包含了很多项,并且有固定的结构。我们来看看里面的具体结构:
开始是两个固定长度的数值,分别表示Key的长度和Value的长度。紧接着是Key,开始是固定长度的数值,表示RowKey的长度,紧接着是 RowKey,然后是固定长
度的数值,表示Family的长度,然后是Family,接着是Qualifier,然后是两个固定长度的数值,表示Time Stamp和Key Type(Put/Delete)。Value部分没有这么
复杂的结构,就是纯粹的二进制数据了。随着HFile版本迁移,KeyValue(Cell)的格式并未发生太多变化,只是在V3版本,尾部添加了一个可选的Tag数组。
HFileV1版本的在实际使用过程中发现它占用内存多,并且Bloom File和Block Index会变的很大,而引起启动时间变长。其中每个HFile的Bloom Filter可以增长
到100MB,这在查询时会引起性能问题,因为每次查询时需要加载并查询Bloom Filter,100MB的Bloom Filer会引起很大的延迟;另一个,Block Index在一个
HRegionServer可能会增长到总共6GB,HRegionServer在启动时需要先加载所有这些Block Index,因而增加了启动时间。为了解决这些问题,在0.92版本中引
入HFileV2版本: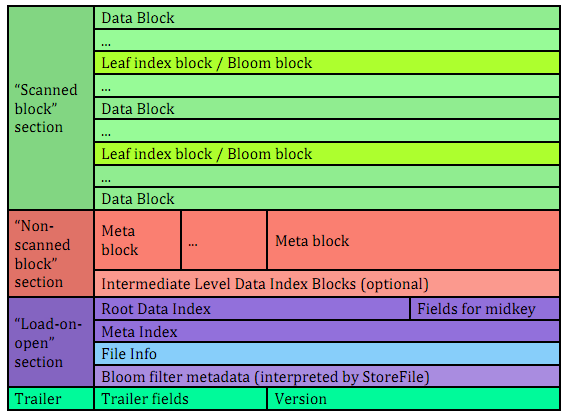
在这个版本中,Block Index和Bloom Filter添加到了Data Block中间,而这种设计同时也减少了写的内存使用量;另外,为了提升启动速度,在这个版本中还引入
了延迟读的功能,即在HFile真正被使用时才对其进行解析。
FileV3版本基本和V2版本相比,并没有太大的改变,它在KeyValue(Cell)层面上添加了Tag数组的支持;并在FileInfo结构中添加了和Tag相关的两个字段。关于具
体HFile格式演化介绍,可以参考其它资料
对HFileV2格式具体分析,它是一个多层的类B+树索引,采用这种设计,可以实现查找不需要读取整个文件: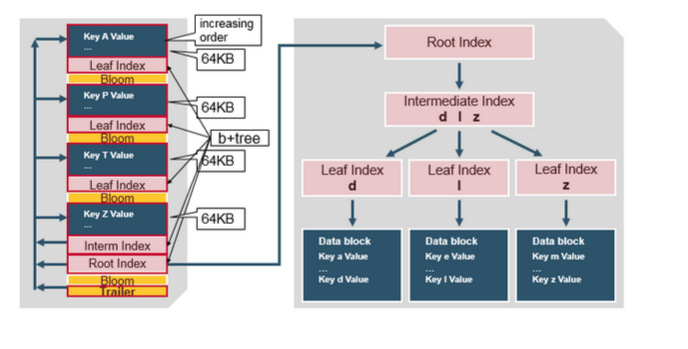
Data Block中的Cell都是升序排列,每个block都有它自己的Leaf-Index,每个Block的最后一个Key被放入Intermediate-Index中,Root-Index指向
Intermediate-Index。在HFile的末尾还有Bloom Filter用于快速定位那么没有在某个Data Block中的Row;TimeRange信息用于给那些使用时间查询的参考。
在HFile打开时,这些索引信息都被加载并保存在内存中,以增加以后的读取性能。
Hlog
hlog是为容易存在的,大型分布式系统中硬件故障很常见,HBase也不例外,如果MemStore还没有刷写到hfile,服务器就崩溃了,内存中没有写到硬盘的数据
就丢失了。hbase的应对办法是在写动作完成之前,先写入hlog,Hbase集群中每台服务器维护一个hlog,直到hlog新记录成功写入后,写动作才被认为是成功完成。
也就是说每个写入到作需要同时得到memstore和hlog的确认,如果在memstore没有写到hfile之前宕机,数据就可以从hlog恢复!
总结一:hbase首先按照row-key按行切分数据,每一份就是一个region(会在适当的时机合并),然后再按照列族切分,每个列族对应硬盘上的一个文件夹。所以说
hbase是面向列存储的,key-value形式的数据库
总结二:在查询数据时,hbase首先根据row-key找到对应的region,然后再根据需要的列族到硬盘上找到对应的文件夹读取数据
这篇关于hbase架构原理之region、memstore、hfile、hlog、columm-family、colum、cell(有时间看)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






