本文主要是介绍逻辑这回事(三)----时序分析与时序优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基本时序参数
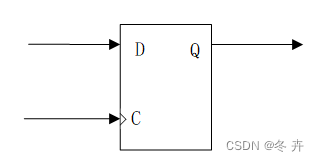
图1.1 D触发器结构

图1.2 D触发器时序
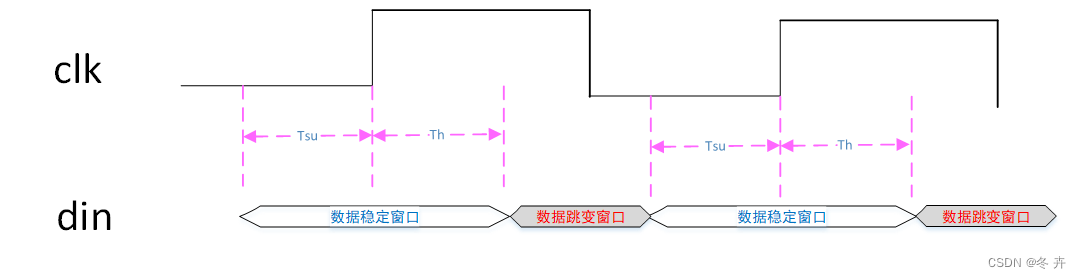
时钟clk采样数据D时,Tsu表示数据前边沿距离时钟上升沿的时间,MicTsu表示时钟clk能够稳定采样数据D的所要求时间,Th表示数据后边沿距离时钟上升沿的时间,MicTh表示时钟clk采样到数据D后,数据D仍然需要保持时间。时钟clk采样到数据D后输出,MicTco表示时钟clk上升沿距离数据Q输出达到稳定的时间。
寄存器的时序分析是最基本的时序分析,对于实际逻辑电路约束中还需要考虑其它参考因素,包含延时、抖动等等。由于实际电路时序约束并直接针对寄存器本身,因为寄存器本身时序MicTsu/MicTh/MicTco是相对固定的,但是端口与寄存器之间的路径或寄存器之间的路径,因为距离不同存在不同的延迟,该部分延时导致端口上实际的采样信号与到达寄存器后的时序特性存在差异,这样我们就需要对端口处的时序特性进行约束,以保证端口上的信号到达寄存器后,能够满足寄存器的采样要求。信号从端口到寄存器的结构图如下:
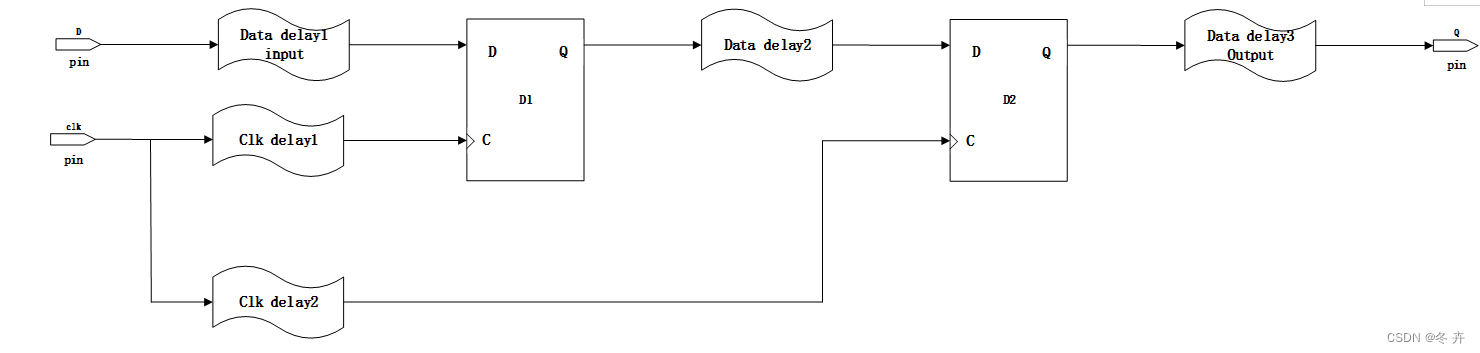
图1.3 基本接口电路时序分析及时序参数
如上图所示,第一级寄存器处,由于存在data delay1和clk delay1,那么对于端口上的数据和时钟的时序要求相对于与寄存器处的时序要求有所区别,保证端口约束后,经过一段延迟到达寄存器时能够满足寄存器的时序要求。
几个术语:
• 源时钟 (source clock) 也称为发送时钟 (launch clock)。
• 目标时钟 (destination clock) 也称为捕获时钟 (capture clock)。
- 发送沿 (launch edge) 表示发送数据的源时钟的处于活动状态的时钟沿。
• 捕获沿 (capture edge) 表示捕获数据的目标时钟的处于活动状态的时钟沿。
• 建立要求 (setup requirement) 表示定义最严格的建立约束的发送沿与捕获沿之间的关系。
• 建立关系 (setup relationship) 表示经时序分析工具验证的建立时间检查。
• 保持要求 (hold requirement) 表示定义最严格的保持约束的发送沿与捕获沿之间的关系。
• 保持关系 (hold relationship) 表示经时序分析工具验证的保持时间检查。
端口建立时间Tsu
对于端口Tsu有:Tsu = data delay1 – clk delay1 + MicTsu
端口建立时间时序:
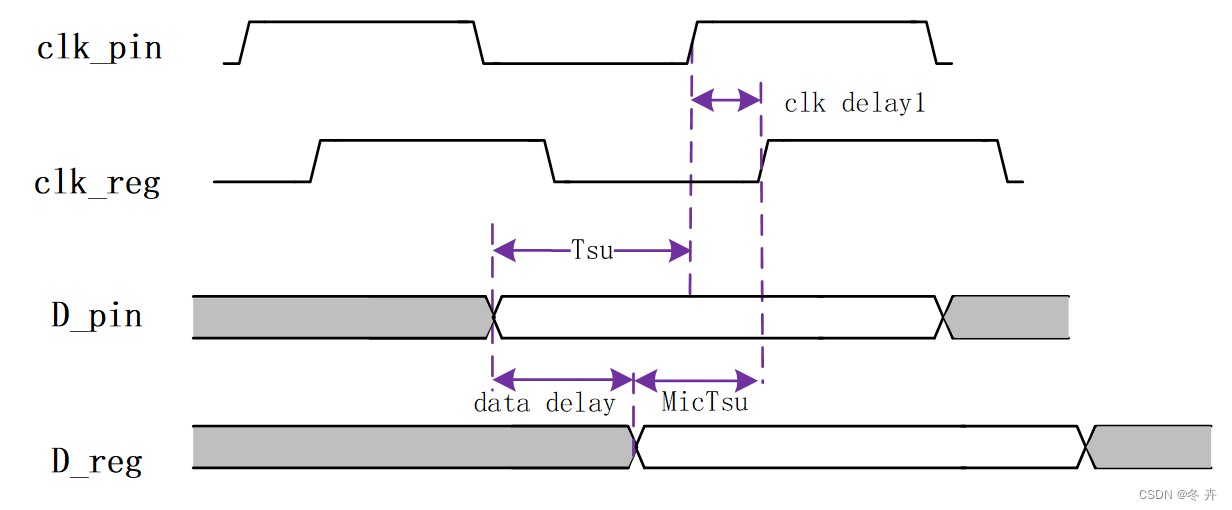
图1.4 端口建立时间
上图clk_delay以及data_delay对应图1.3中的clk_delay1和data_delay1 input,可见时钟延迟越小,数据延迟越大,对建立时间要求越大,即建立时间决定了数据到达的最大延迟,也决定了时钟最高频率。因此在进行set input delay约束时,-max(对setup分析)使用使用最小时钟延迟和最大数据延迟(后面会具体讲怎么约束)。
建立时间计算示例如下图,图上有两个建立时间setup(1)和setup(2):
Setup(1) = 1*Tclk1 – 0*Tclk0 = 4ns
Setup(2) = 2*Tclk1 – 1*Tclk0 = 2ns,setup(2)最小2ns,详细计算如下:
源时钟发数沿时间:0ns + 1*Tclk0 = 6ns;
目的时钟采数沿时间:0ns + 2*Tclk1 = 8ns;
建立时间=采数沿时间 – 发数沿时间 = 8 – 6 = 2ns,这里有两个假设,时钟是理想的,两个时钟初始相位对齐的。
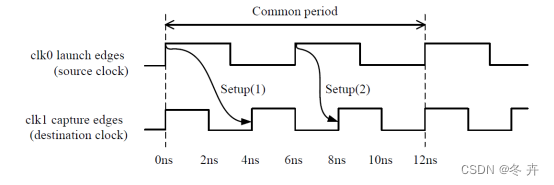
图1.5 建立时间示例
端口保持时间Th
对于端口Th有:Th = clk delay1 – data delay1 + MicTh
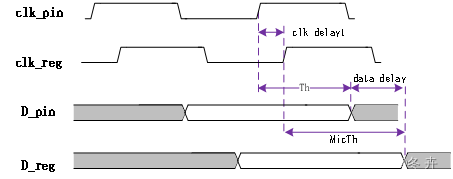
图1.6 端口保持时间
上图clk_delay以及data_delay对应图1.3中的clk delay1和data delay1 input,可见时钟延迟越大,数据延迟越小,对保持时间要求越大,即保持时间决定了数据最早到达的时间。因此在进行set input delay约束时,-min(对hold分析)使用使用最大时钟延迟和最小数据延迟(后面会具体讲怎么约束)。
保持时间计算实例如下图,从图上可以看出,对于每个建立时间有两个保持时间要求:第一,requirement(a):前一个采数沿减去当前发数沿;第二,requirement(b):当前采数沿减去后一个发数沿。
对于setup(1):
H1a = (1-1)*Tclk1 – 0*Tclk0 = 0ns
H1b = 1*Tclk1 – (0+1)Tclk0 = -2ns
对于setup(2):
H2a = (2-1)*Tclk1 – 1*Tclk0 = -2ns
H2b = 2*Tclk1 – (1+1)*Tclk0 = -4ns
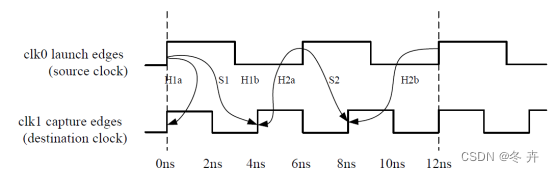
图1.7 保持时间示例
端口输出时间Tco
对于端口Tco有:Tco = clk delay2 + data delay3 + MicTco
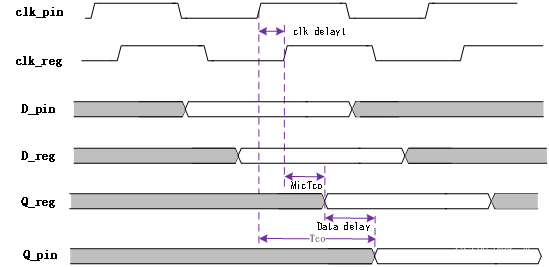
图1.8 端口输出时间
上图clk delay及data delay对于图1.3中的clk delay2和data delay3 output.
时钟偏差(skew)
时钟偏差表示同一时钟到达不同寄存器的时钟端的时钟延迟差,如图1.3所示,对于skew有:skew = clk delay1 – clk delay2或者skew = clk delay2 – clk delay1,可见skew可以是正值,也可以是负值。
时序分析
从路径上看,时序分析可以分4类:

(1)输入端口到内部时序元件路径:由外部器件出发输出数据,经过一段延迟(Input Delay)后进入芯片,再经过器件内部逻辑到达时序元件后,被目的时钟采样。
(2)内部时序元件到内部时序元件路径:数据在芯片内部的时序元件被源时钟触发,经过内部逻辑时序元件后被目的时钟采样。
(3)内部时序元件到输出端口路径:数据在芯片内部的时序元件被源时钟触发,经过器件内部逻辑到达芯片输出端口,经过一段延迟后(Output Delay)被外部器件采样。
(4)输入端口到输出端口路径:数据从输入端口到输出端口没有被寄存过的路径。
其中内部时序元件到内部时序元件路径工具分析的基础,其它3类殊途同归,下面以第2类讲下建立时间和保持时间分析。另外可以把每个时钟沿的邻域划分出一个数据保持稳定窗口,在数据保持稳定窗口是不允许数据跳变的,这就是时序分析的基础。
建立时间Tsu时序分析
时钟建立检查确保在当前发送沿(Current launch edge),源寄存器发送的数据,能够在当前捕获沿(Current capture edge)被目标寄存器正确捕获。时序分析工具使用最长路径确定目标寄存器的数据到达时间,使用最短路径确定目标寄存器的时钟到达时间,分析时钟到达时间与数据到达时间之差是否大于或等于寄存器固有建立时间(Micro Tsu),即Clock Arrival Time – Data Arrival Time >= Micro Tsu .
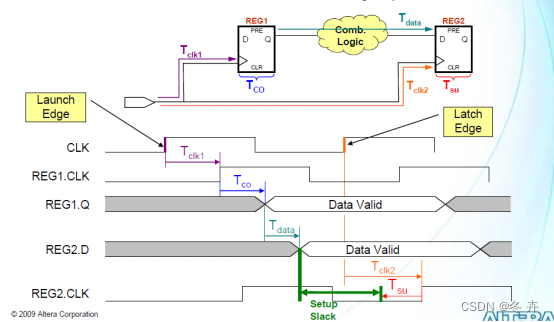
图1.9 建立关系分析
Data Required Time (setup) = 捕获沿时间 (capture edge time) + 最小目标时钟路径延迟 (destination clock path min delay)- 时钟不确定性 (clock uncertainty)- 建立时间 (Micro Tsu);
Data Arrival Time (setup) = 发送沿时间 (launch edge time) + 最长源时钟路径延迟 (source clock path max delay) + MicroTco + 最长数据路径延迟 (datapath max delay);
建立时间裕量 (Clock Setup Slack) = 数据必需时间 (Data Required Time) - 数据到达时间 (Data Arrival Time)
如上述公式所示,当数据到达时间早于必需时间时,建立裕量为正值。恢复检查类似于建立检查,但它适用于异步管脚(如预置或清除)。恢复关系方式与建立相同,裕量公式也相同(只是使用恢复时间取代建立时间)。

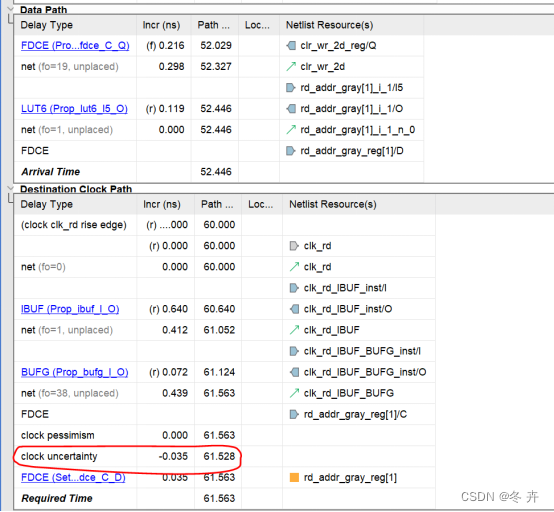
保持时间Th时序分析
时钟保持检查是确保在当前发送沿(Current launch edge),源寄存器发出的数据,在目标寄存器不会被前一个捕获沿(Previous capture edge)采到;并且下一个发送沿(Next launch edge),源寄存器发出的数据,在目标寄存器不会被当前捕获沿(Current capture edge)采到(如图1.7中, setup(1)对应的H1a和H1b或setup(2)对应的H2a和H2b)。时序分析工具使用最短路径确定目标寄存器的数据到达时间,使用最长路径确定目标寄存器的时钟到达时间,分析时钟到达时间与数据到达时间之差是否大于或等于寄存器的固有保持时间(Micro Th),即Data Arrival Time - Clock Arrival Time >= Micro Th。需要注意保持时间分析是数据到达时间减去时钟到达时间,而建立时间分析是时钟到达时间减去数据到达时间。
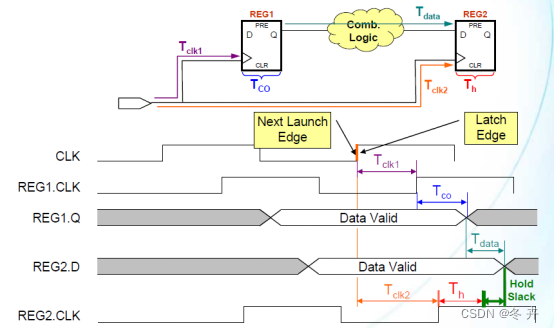
图1.9 保持关系分析
当路径要求已知后,即可引入路径延迟、时钟不确定性和保持时间以计算裕量。典型裕量公式为:
Data Required Time (hold)= 捕获沿时间 (capture edge time) + 最长目标时钟路径延迟 (longest destination clock path delay) + 时钟不确定性 (clock uncertainty) + 保持时间(hold time);
Data Arrival Time (hold)= 发送沿时间 (launch edge time) + 最短源时钟路径延迟 (shortest source clock path delay) + 最短数据路径延迟 (shortest data path delay);
保持时间裕量 (Clock Hold Slack )= 数据到达时间 (Data Arrival Time) - 数据必需时间 (DataRequired Time)
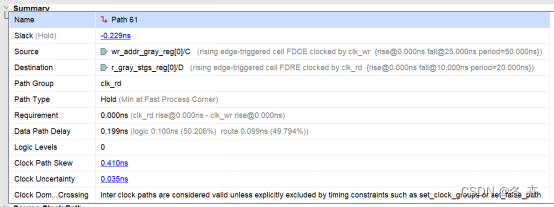
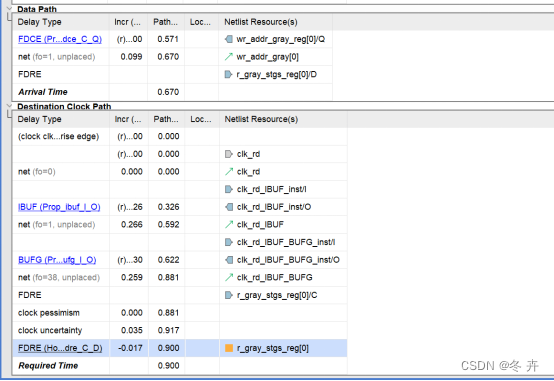
如上述公式所示,当新数据到达时间晚于必需时间时,保持裕量为正值。移除检查类似于保持检查,但它适用于异步管脚(如预置或清除)。关系建立方式与保持相同,裕量公式也相同(只是使用移除时间取代保持时间)。
在芯片pre-CTS (前时钟树综合)的过程中, setup建立时间的不确定性:包含系统时钟的影响(即时间抖动jitter)和时钟偏移(即skew)带来的影响。hold保持时间的不确定性只会由时钟偏移(skew)决定。(如果前后寄存器是同一个时钟,那么保持时间分析的捕获沿和启动沿是同一个沿,jitter是一致的,只用考虑skew;建立时间分析的捕获沿和启动沿是前、后两个沿,jitter是不一样的,skew和jitter都要考虑)。
在芯片post-CTS (后时钟树综合)的过程中,时钟树已经被综合,时钟树的偏移已经明确。setup建立时间的不确定性包含系统时钟的影响(即时间抖动jitter)带来的影响。hold保持时间不受系统时钟影响。
时序约束
我们先看下逻辑开发流程,如图。时钟方案决定了整个工程的时钟网络,是后端实现的关键部分。代码约束是针对当前设计的实现进行限制的约束要求,比如异步处理的打拍寄存器,我们期望这些寄存器必须使用寄存器实现,不能插入组合逻辑,走线足够近,而不能用移位寄存器实现。在vivado工具时,可以代码中在寄存器前添加(*ASYNC_REG = “true” *)约束,例如:
(*ASYNC_REG = “true” *)reg bist_en_dly;
(*ASYNC_REG = “true” *)reg bist_en_2dly;
当然不同的工具其代码约束语法不同,类似约束还有最大扇出约束、寄存器保留约束等。
物理约束和时序约束是指导工具实现后端的关键输入,包含管脚约束,位置约束,时钟约束,内部时序要求等,后面会重点讲时序约束。
综合,布局布线是最后的后端实现,器件和工具版本,设置等的配合都可能较大的差异,所以需要提前了解相应的器件和优选的工具版本及选型设置。
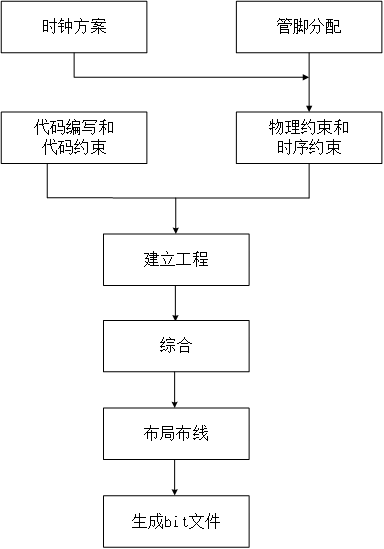
FPGA开发流程
时序约束的关系
时序约束有3大部分:时钟约束、IO接口input/output delay约束、例外约束,三者分工如下,后面以约束命令为例详细讲解。
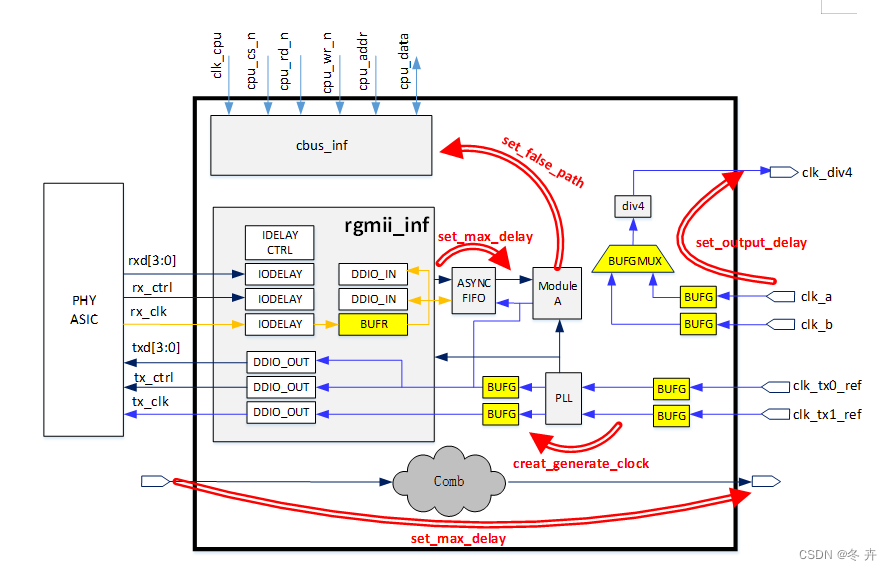
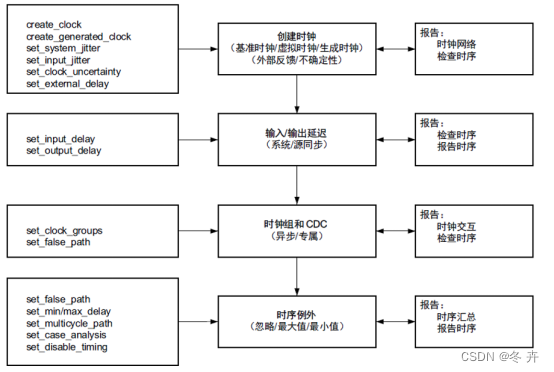
在约束时,一定先需要了解网表中的一些专用术语,如下表:
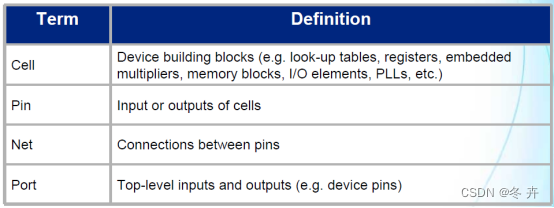
举例如下:

时钟约束
create_clock
基准时钟是指用于为设计定义时序参考的时钟,而时序引擎可利用基准时钟衍生出时序路径要求以及与其他时钟的相位关系。主时钟插入延迟的计算范围是从时钟源点(用于定义时钟的驱动管脚/端口)到时序单元(作为时钟扇出目标)的时钟管脚。因此,重要的是在对应于设计边界的对象上定义基准时钟,以便准确计算其延迟并间接计算其偏差。用create_clock 定义的基准时钟的起点即时序的“零起点” ,在这之前的上游路径延时都被工具自动忽略。管脚输入时钟,声明了时钟周期,对应上下沿相位关系。时钟的定义也遵从Tcl 的一般优先级,即:在同一个点上,由用户定义的时钟会覆盖工具自动推导的时钟,且后定义的时钟会覆盖先定义的时钟。若要二者并存,必须使用-add 选项。
Command: create_clock
Options :
[-name <clock_name>]
-period <time>
[-waveform {<rise_time> <fall_time>}]
[<targets>]
[-add]
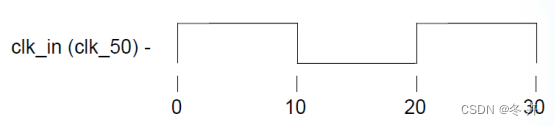
create_clock –period 20.0 –name clk_50 [get_ports clk_in]
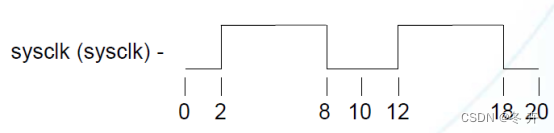
create_clock –period 10.0 –waveform {2.0 8.0} [get_ports sysclk]
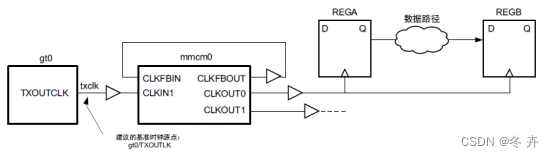
create_clock -name txclk -period 6.667 [get_pins gt0/TXOUTCLK]
建议:对于面向 7 系列器件的设计,xilinx还建议定义 GT 输入时钟,因为 Vivado 工具会计算 GT 输出管脚上期望的时钟,并将这些时钟与用户创建的时钟进行比较。如果时钟不同或者到 GT 的输入时钟丢失,工具会发出方法论检查警告。但值得注意的是,如果时钟输入管脚是差分时钟,那么在P端约束即可。如果在P/N输入上都创建主时钟,将导致过约束,产生不符合实际的CDC路径。
create_clock -name sysclk -period 3.33 [get_ports SYS_CLK_clk_p]
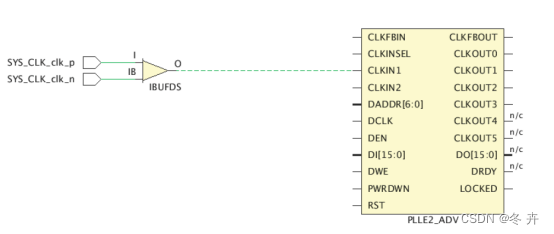
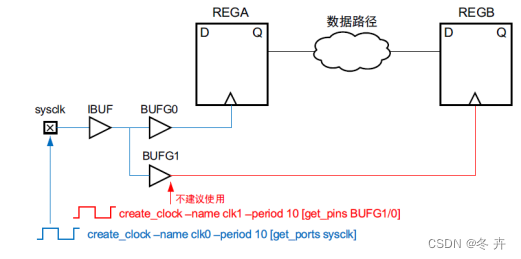
重要提示!在基准时钟传递扇出中不应定义另外 1 个基准时钟,因为这种情况不但不符合任何硬件现实,还会妨碍完整的时钟插入延迟计算,从而阻碍正确的时序分析。如果发生这种情况,必须重新修改并修正约束。下图显示的示例中,时钟 clk1 是在时钟 clk0 的传递扇出中定义的。时钟 clk1 会从 BUFG1 输出开始覆盖此输出处所定义的 clk0。因此,由于 clk0 与 clk1 之间skew,导致 REGA 与 REGB 之间的时序分析并不准确(不建议在另一个时钟的扇出中使用 create_clock)。
creat_generated_clock
生成时钟 (generated clock) 是从先有的主时钟 (master clock) 衍生的,它通常用于描述对主时钟执行的波形变换。由于生成时钟定义取决于主时钟特性,因此必须首先定义主时钟。为显式定义生成时钟,必须使用create_generated_clock 命令。create_generated_clock能够定义设计中内部生成的时钟的属性和约束,可以为修改时钟信号任何节点的属性,重新定义生成的时钟,包括修改相位,频率,偏移或占空比,同时能够保留主时钟的属性,如uncertainty等。生成的时钟最常应用于PLL的输出,寄存器时钟分频器,时钟多路复用器。
自动衍生时钟:大部分生成时钟都是由 Vivado 时序引擎自动衍生的,该引擎可识别时钟修改块 (CMB) 及其对主时钟执行的变换。
在 xilinx 7 系列器件中,CMB 包括:
• MMCM*/PLL*
• BUFR
• PHASER*
在 xilinx UltraScale 系列器件中,CMB 包括:
• MMCM*/PLL*
• BUFG_GT/BUFGCE_DIV
• GT*_COMMON/GT*_CHANNEL/IBUFDS_GTE3
• BITSLICE_CONTROL/RX*_BITSLICE
• ISERDESE3
对于时钟树上的任何其他组合单元而言,时序时钟可通过这些单元进行传输,且无需在输出端重新定义,除非此类单元已进行波形变换。
Command: create_generated_clock
Options
[-name <clock_name>]
-source <master_pin>
[-master_clock <clock_name>]
[-divide_by <factor>]
[-multiply_by <factor>]
[-duty_cycle <percent>]
[-invert]
[-phase <degrees>]
[-edges <edge_list>]
[-edge_shift <shift_list>]
[<targets>]
[-add]
create_generated_clock –name clk_div \
–source [get_pins inst|clk] -divide_by 2 [get_pins inst|regout]
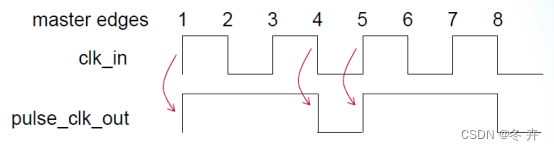
create_clock –period 10 [get_ports clk_in]
create_generated_clock –name pulse_clk_out -source clk_in \
–edges {1 4 5} [get_pins pulse_logic|out]
edges编号为1...<n>,在列表中,第一个数字对应于生成时钟的第一个上升沿,第二个数字是第一个下降沿,第三个数字是第二个上升沿。因此,产生了占空比为75%的源周期的一半的时钟。

create_clock –period 10 [get_ports clk_in]
create_generated_clock –name pulse_clk_out -source clk_in \
–edges {1 4 5} -edge_shift {2.5 2.5 0} [get_pins pulse_logic|out]
与上一个示例相同,不同之处在于-edge_shift移动每个边缘指示的时间量。
set_clock_uncertainty
clock uncertainty包括Clock jitter、skew 、Phase error和自定义的uncertainty。对于FPGA,抖动特性是可预测的;它们可以由Vivado IDE 时序引擎自动计算,也可以单独指定。对于由MMCM或PLL驱动的衍生时钟,输入抖动被计算的离散抖动代替。对于生成的时钟由组合或时序单元创建的情况,生成的时钟抖动与其主时钟抖动相同。
如果需要在某个时钟的时序路径上或 2 个时钟之间的时序路径上添加额外裕度,必须使用set_clock_uncertainty 命令。这也是对部分设计进行过约束而不必修改实际时钟沿和总体时钟关系的最佳且最安全的途径。定义的时钟不确定性是在综合工具计算所得抖动的基础上附加的,并且可为建立时间和保持时间分析单独指定此不确定性。
Command: set_clock_uncertainty
Use to model jitter, guard band, or skew
− Allows generation of clocks that are non-ideal
Options
− [-setup | -hold]
− [-fall_from <fall_from_clock>]
− [-fall_to <fall_to_clock>]
− [-from <from_clock>]
− [-rise_from <rise_from_clock>]
− [-rise_to <rise_to_clock>]
− [-to <to_clock>]
− <value>
例如,设计时钟 clk0 的所有时钟间路径上的裕度需收紧,幅度为 500 ps,以使设计更稳健,承受建立时间和保持时间噪声的能力更强(可以使用250 ps的setup uncertainty和250 ps的hold uncertainty):
set_clock_uncertainty -from clk0 -to clk0 -setup 0.2500
set_clock_uncertainty -from clk0 -to clk0 -hold 0.2500
Setup uncertainty会减少setup分析的data require time,Hold uncertainty 会增加 hold分析的data required time。

注释:收紧设计上的保持时间裕度可能导致专用站点内部路径和级联路径上出现保持时间违例,并且布线器无法通过绕行站点内部信号线来解决此类违例。
如果在 2 个时钟之间指定额外的不确定性,那么必须应用双向约束(假定数据流为双向)。以下示例演示了如何在clk0 和 clk1 之间仅针对建立时间将不确定性增加 250 ps:
set_clock_uncertainty -from clk0 -to clk1 0.250 -setup
set_clock_uncertainty -from clk1 -to clk0 0.250 -setup
IO约束
用于IO约束的命令包括set_input_delay/set_output_delay和set_max_delay/set_min_delay。其中,只有那些从芯片管脚进入,一直到芯片管脚输出,中间都不经过任何时序元件的纯组合逻辑路径,可以使用set_max_delay/set_min_delay来约束,其余I/O时序路径都必须由set_input_delay/set_output_delay来约束。
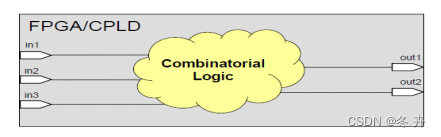
set_max_delay –from [get_ports in1] –to [get_ports out*] 5.0
set_max_delay –from [get_ports in2] –to [get_ports out*] 7.5
set_max_delay –from [get_ports in3] –to [get_ports out*] 9.0
set_min_delay –from [get_ports in1] –to [get_ports out*] 1.0
set_min_delay –from [get_ports in2] –to [get_ports out*] 2.0
set_min_delay –from [get_ports in3] –to [get_ports out*] 3.0
如果对FPGA的I/O不加任何约束,vivado会缺省认为时序要求为无穷大,不仅综合和时序不会考虑I/O时序,而且时序分析时也不会报这些未约束的路径。
Input Delay
Input Delay用来表示芯片输入接口的数据和其参考时钟之间的相位关系。因为工具本身不知道芯片输入接口的时序(上游器件输出),所以需要我们通过input delay告诉工具,在芯片IO入口,数据与时钟的相对相位关系。Input Delay和Output Delay都需要考虑系统同步和源同步两种方式。
系统同步接口
对系统同步接口做input约束相对容易,只需要考虑上游器件的Tco和数据在板级的时延即可。下图是一个SDR上升沿采样系统同步接口的input约束示例。
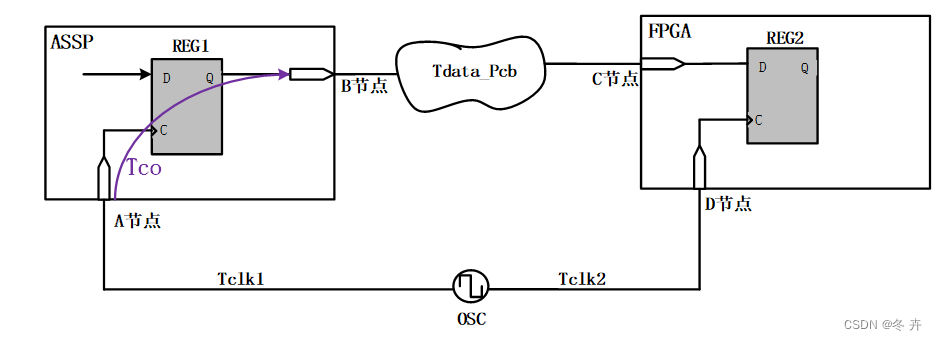
约束FPGA中REG2的Tsu时延“-max”:
Input delay max = Tclk1(max) + Tco(max)+Tdata_Pcb(max)-Tclk2(min)
= Tdata_Pcb(max) – (Tclk2(min) – Tclk1(max)) + Tco(max)
= Tdata_Pcb(max) – Tclk_skew(min)+ Tco(max)
约束FPGA中REG2的Th时延“-min”:
Input delay min = Tclk1(min) + Tco(min)+Tdata_Pcb(min)-Tclk2(max)
= Tdata_Pcb(min) – (Tclk2(max) – Tclk1(min)) + Tco(min)
= Tdata_Pcb(min) – Tclk_skew(max) + Tco(min)
一条完整的时序路径,从源触发器的Clk端开始,经过Tco和路径传输延时,再到目的触发器的D端结束。放在系统同步的接口时序上,传输延时则变成板级传输延时(要考虑skew),所以上述-max后的数值是Tco的最大值加上板级延时的最大值而来,而-min后的数值是两个最小值相加而来。
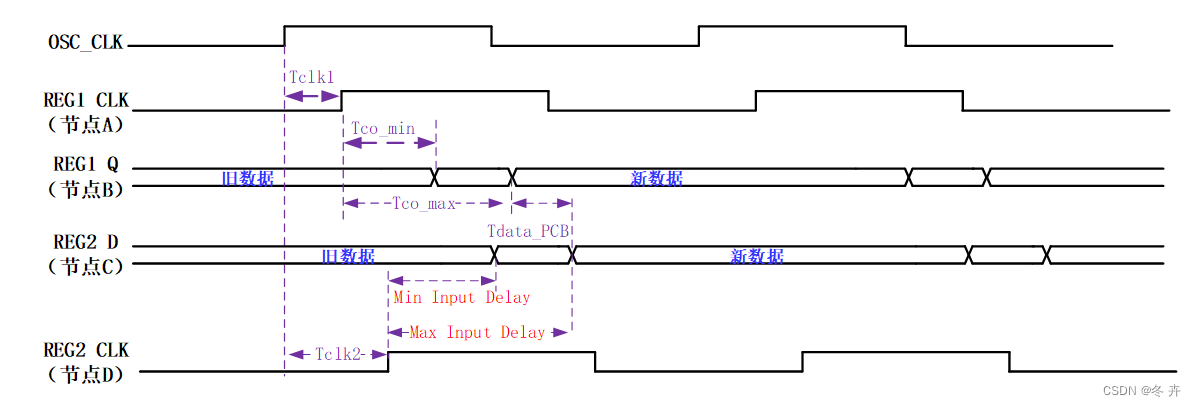
上面结果出现负值并不代表延时真的为负数,而是跟数据相对于时钟沿的方向有关。请一定要牢记set_input_delay中的“-max/min”的定义,即时钟采样沿到达之后最大与最小的数据有效窗口,如下图所示。
源同步接口
为了改进系统同步接口中的时钟频率受限的弊端,一种针对高速I/O的同步时序接口应运而生,在发送端将数据和时钟同步传输,在接收端用时钟沿脉冲来对数据进行锁存,重新使数据与时钟同步,这种电路就是源同步接口电路( Source Synchronous Interface )。
源同步接口最大的优点就是大大提升了总线的速度,在理论上信号的传送可以不受传输延迟的影响,所以源同步接口也经常应用DDR 方式,在相同时钟频率下提供双倍于SDR 接口的数据带宽。源同步接口的约束设置相对复杂,一则是因为有SDR 、DDR 、中心对齐( Center Aligned )和边沿对齐( Edge Aligned )等多种方式,二者可以根据客观已知条件,选用与系统同步接口类似的系统级视角的方式,或是用源同步视角的方式来设置约束。

如上图所示,对源同步接口进行Input 约束可以根据不同的已知条件,选用不同的约束方式。一般而言,对于芯片输入接口,数据有效窗口是已知条件,所以方法2 更常见。但不论以何种方式来设置Input 约束,作用是一样,时序报告的结果也应该是一致的。
Datain相对于clkin的input delay(源同步理想情况下Tdata_PCB和Tclk_skew是一致的):
Input delay max = Tdata_PCB(max) – Tclk_skew(min) + Tco(max)
= Tco(max)
Input delay min = Tdata_PCB(min) – Tclk_skew(max) + Tco(min)
= Tco(min)
SDR接口的约束设置
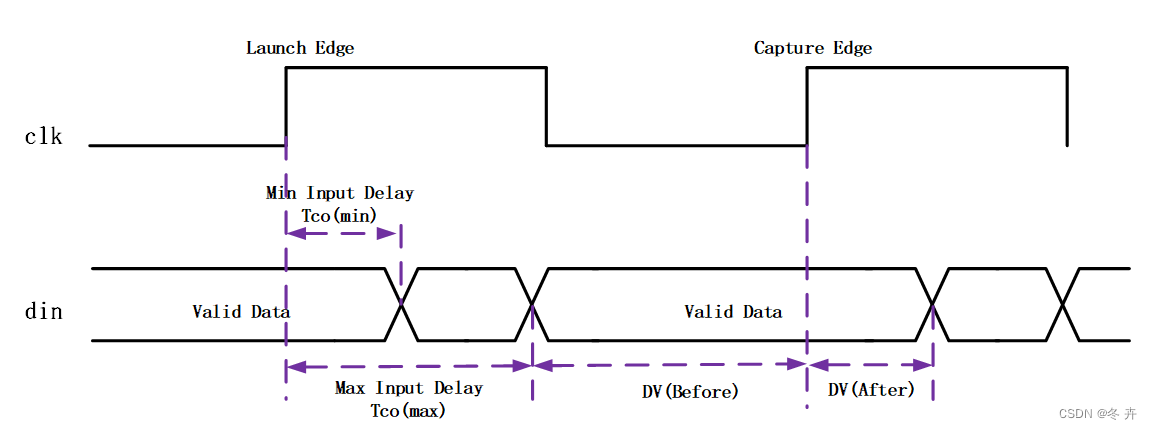
针对上图所示的对齐源同步SDR接口时序,分别按照两种方式来约束,需要已知条件和计算方式虽然不同,却可以得到完全一样的结果。


DDR 接口的约束设置
DDR 源同步接口的约束稍许复杂,需要将上升沿和下降沿分别考虑和约束,以下以源同步接口为例,分别就输入接口数据为中心对齐或边沿对齐的方式来举例。
方法一:Setup/Hold Based Method
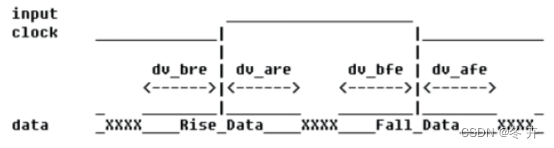
图 x DDR源同步中心对齐输入接口
已知条件如下:
时钟信号src_sync_ddr_clk 的频率: 100 MHz
数据总线: src_sync_ddr_din[3:0]
上升沿之前的数据有效窗口( dv_bre ) : 0.4 ns
上升沿之后的数据有效窗口( dv_are ) : 0.6 ns
下降沿之前的数据有效窗口( dv_bfe ) : 0.7 ns
下降沿之后的数据有效窗口( dv_afe ) : 0.2 ns
可以这样计算输入接口约束: DDR 方式下数据实际的采样周期是时钟周期的一半;上升沿采样的数据( Rise Data )的-max 应该是采样周期减去这个数据的发送沿(下降沿)之前的数据有效窗口值dv_bfe ,而对应的-min 就应该是上升沿之后的数据有效窗口值dv_are ;同理,下降沿采样的数据( Fall Data )的-max应该是采样周期减去这个数据的发送沿(上升沿)之前的数据有效窗口值dv_bre ,而对应的-min 就应该是下降沿之后的数据有效窗口值dv_afe 。
所以最终写入XDC 的Input 约束应该如下所示:
set period 10.0;
create_clock -period $period -name clk [get_ports src_sync_ddr_clk];
set_input_delay -clock clk -max [expr $period/2 – 0.7] [get_ports src_sync_ddr_din[*]] ;
set_input_delay -clock clk -min 0.6 [get_ports src_sync_ddr_din[*]] ;
set_input_delay -clock clk –max [expr $period/2 – 0.4] \
[get_ports src_sync_ddr_din[*]] -clock_fall -add_delay ;
set_input_delay -clock clk -min 0.2 [get_ports src_sync_ddr_din[*]] -clock_fall -add_delay;
方法二:Skew Based Method
边缘对齐是指时钟和数据到达后级时序单元时,时钟沿与数据变化沿重合,如图所示(如IMX222视频传感器的的DDR)。
由于是随路时钟的关系,时钟和数据极有可能同时达到FPGA的输入端口,这样很明显不能满足目的端寄存器的时序要求,通常的做法是通过逻辑或锁相环对时钟和数据的关系进行相位调整,这样就能正确采集数据了,之后在以调整后的相位进行时序约束即可。
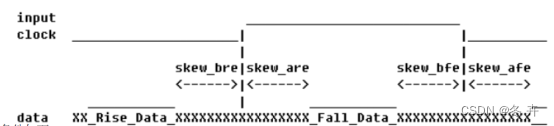
图x DDR 源同步边沿对齐输入接口
已知条件如下:
时钟信号src_sync_ddr_clk 的频率: 100 MHz
数据总线: src_sync_ddr_din[3:0]
上升沿之前的数据skew (skew_bre ) : 0.6 ns
上升沿之后的数据skew (skew_are ) : 0.4 ns
下降沿之前的数据skew (skew_bfe ) : 0.3 ns
下降沿之后的数据skew (skew_afe ) : 0.7 ns
可以这样计算输入接口约束:因为已知条件是数据相对于时钟上升沿和下降沿的skew ,所以可以分别独立计算;上升沿的-max 是上升沿之后的数据skew (skew_are ) ,对应的-min 就应该是负的上升沿之前的数据skew (skew_bre ) ;下降沿的-max 是下降沿之后的数据skew (skew_afe ) ,对应的-min 就应该是负的下降沿之前的数据skew (skew_bfe ) 。
所以最终写入XDC 的Input 约束应该如下所示:
create_clock -period 10.0 -name clk [get_ports src_sync_ddr_clk];
set_input_delay -clock clk -max 0.4 [get_ports src_sync_ddr_din[*]] ;
set_input_delay -clock clk -min -0.6 [get_ports src_sync_ddr_din[*]] ;
set_input_delay -clock clk -max 0.7 [get_ports src_sync_ddr_din[*]] -clock_fall -add_delay ;
set_input_delay -clock clk -min -0.3 [get_ports src_sync_ddr_din[*]] -clock_fall -add_delay;
出现负值并不代表延时真的为负,而是跟数据相对于时钟沿的方向有关。请一定牢记set_input_delay 中-max/-min 的定义,即时钟采样沿到达之后最大与最小的数据有效窗口,切记切记!!( set_output_delay 中-max/-min 的定义与之正好相反,详见后续章节举例说明)。
Output Delay
Output Delay的定义:用来表示芯片输出接口的数据与参考时钟之间的相位关系。因为工具不知道芯片输出接口的时序(下游器件输入),所以需要我们通过output delay告诉工具,在芯片IO出口,数据与时钟需要满足的的相对相位关系。Output 的接口时序同样也可以分为系统同步与源同步。在设置约束时,总体思路与Input 类似,只是换成要考虑下游器件的时序模型。
系统同步接口
与Input 的系统同步接口一样, FPGA 做Output 接口的系统同步设计,芯片间只传递数据信号,时钟信号的同步完全依靠板级设计来对齐。所以设置约束时候要考虑的仅仅是下游器件的Tsu/Th 和数据在板级的延时。下图是一个SDR上升沿采样系统同步接口的output约束示例。
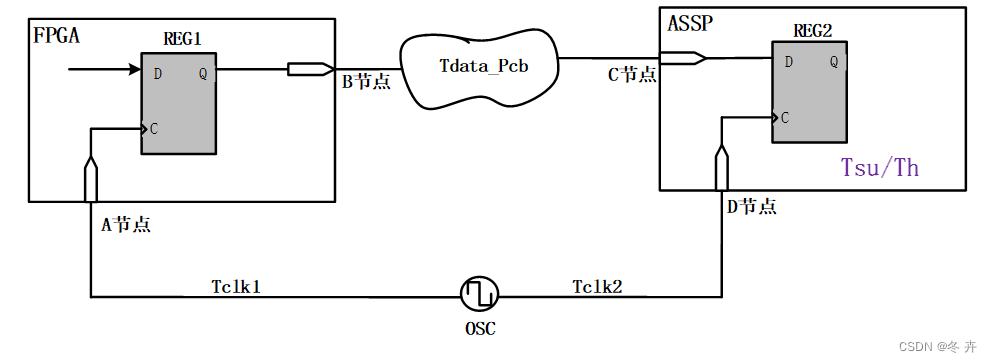
约束下级芯片(ASSP)REG2的Tsu使用”-max”:
Output delay max = Tdata_Pcb(max) + Tsu + Tclk1(max) – Tclk2(min)
=Board Delay(max) + Tsu – Board clock skew(min)
Output delay min = Tdata_Pcb(min) - Th- Tclk1(min) + Tclk2(max)
=Board Delay(min) - Th – Board clock skew(max)
上图是一个SDR 上升沿采样系统同步接口的Output 约束示例。其中, -max 后的数值是板级延时的最大值与下游器件的Tsu 相加而得出,-min 后的数值则是板级延时的最小值减去下游器件的Th 而来。
源同步接口
与源同步接口的Input 约束设置类似, 芯片做源同步接口的Output 也有两种方法可以设置约束。方法一我们称作Setup/Hold Based Method ,与上述系统同步接口的设置思路基本一致,仅需要了解下游器件用来锁存数据的触发器的Tsu 与Th 值与系统板级的延时便可以设置。方法二称作Skew Based Method ,此时需要了解芯片送出的数据相对于时钟沿的关系,根据Skew 的大小和时钟频率来计算如何设置Output约束。
具体约束时可以根据不同的已知条件,选用不同的约束方式。一般而言, 芯片作为输出接口时,数据相对时钟的Skew 关系是已知条件(或者说,把同步数据相对于时钟沿的Skew 限定在一定范围内是设计源同步接口的目标),所以方法二更常见。
SDR接口的约束设置
Setup/Hold Based Method 的计算公式如下,可以看出其跟系统同步输出接口的设置方法完全一样。如果换成DDR 方式,则可参考上一篇I/O 约束方法中关于Input 源同步DDR 接口的约束,用两个可选项-clock_fall 与-add_delay 来添加针对时钟下降沿的约束值。
方法一Setup/Hold Based Method(以下游寄存器位参照,反推到FPGA输出管脚时序)
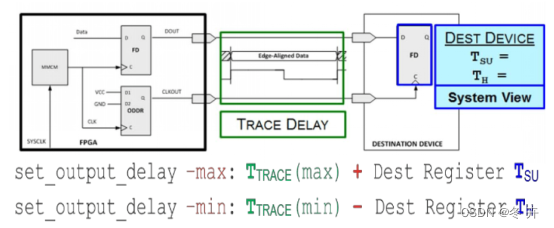
如果板级延时的最小值(在源同步接口中,因为时钟与信号同步传递,所以板级延时常常可以视作为0)小于接收端寄存器的Th,这样计算出的结果就会在-min 后出现负数值,很多时候会让人误以为设置错误。其实这里的负数并不表示负的延迟,而代表最小的延迟情况下,数据是在时钟采样沿之后才有效。同样的, -max后的正数,表示最大的延迟情况下,数据是在时钟采样沿之前就有效了。
这便是接口约束中最容易混淆的地方,请一定牢记set_output_delay 中-max/-min 的定义,即时钟采样沿到达之前,数据的最大与最小的数据有效窗口,如下图所示。
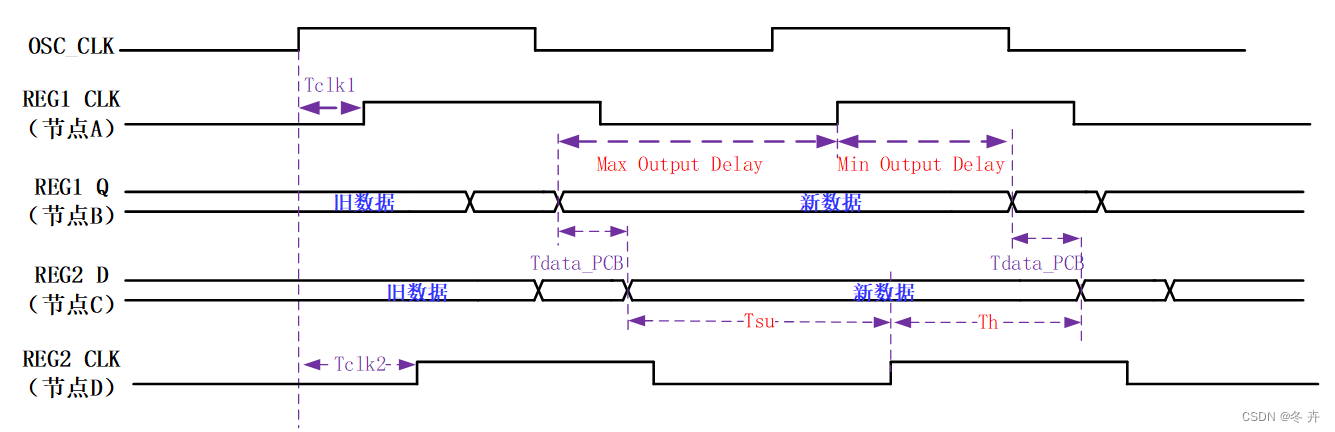
如果我们在纸上画一下接收端的波形图,就会很容易理解:用于setup 分析的-max 之后跟着正数,表示数据在时钟采样沿之前就到达,而用于hold 分析的-min 之后跟着负数,表示数据在时钟采样沿之后还保持了一段时间。只有这样才能满足接收端用于锁存接口数据的触发器的Tsu 和Th 要求。
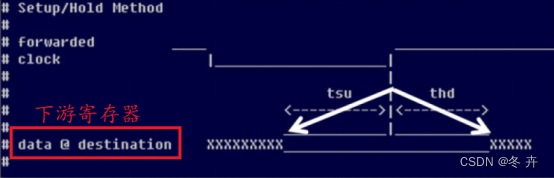
方法二Skew Based Method(以FPGA寄存器为参照)
为了把同步数据相对于时钟沿的Skew 限定在一定范围内,我们可以基于Skew 的大小来设置源同步输出接口的约束。此时可以不考虑下游采样器件的Tsu 与Th 值。
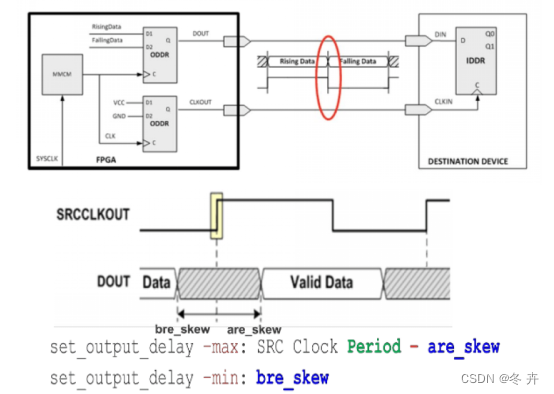
我们可以通过波形图来再次验证set_output_delay 中-max/-min 的定义,即时钟采样沿到达之前最大与最小的数据有效窗口。
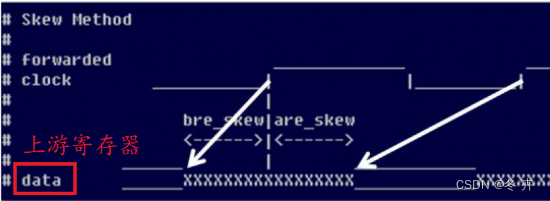
DDR接口的约束设置
DDR 接口的约束稍许复杂,需要将上升沿和下降沿分别考虑和约束,以下以源同步接口为例,分别就Setup/Hold Based 方法和Skew Based 方法举例。
方法一Setup/Hold Based Method

已知条件如下:
时钟信号src_sync_ddr_clk 的频率: 100 MHz
随路送出的时钟src_sync_ddr_clk_out 的频率: 100 MHz
数据总线: src_sync_ddr_dout[3:0]
接收端的上升沿建立时间要求( tsu_r ) : 0.7 ns
接收端的上升沿保持时间要求(thd_r ) : 0.3 ns
接收端的下降沿建立时间要求(tsu_f) : 0.6 ns
接收端的下降沿保持时间要求(thd_f ) : 0.4 ns
板级走线延时: 0 ns
可以这样计算输出接口约束:已知条件包含接收端上升沿和下降沿的建立与保持时间要求,所以可以分别独立计算。上升沿采样数据的-max 是板级延时的最大值加上接收端的上升沿建立时间要求( tsu_r ),对应的-min 就应该是板级延时的最小值减去接收端的上升沿保持时间要求( thd_r );下降沿采样数据的-max 是板级延时的最大值加上接收端的下降沿建立时间要求( tsu_f ),对应的-min 就应该是板级延时的最小值减去接收端的下降沿保持时间要求( thd_f )。所以最终写入XDC 的Output 约束应该如下所示:
create_clock -period 10.0 -name clk [get_ports src_sync_ddr_clk];
create_generated_clock -name clk_out [get_ports ddr_src_sync_clk_out] \
-source [get_ports src_sync_ddr_clk] -divide_by 1;
set_output_delay -clock clk_out -max 0.7 [get_ports src_sync_ddr_dout[*]] ;
set_output_delay -clock clk_out -min -0.3 [get_ports src_sync_ddr_dout[*]] ;
set_output_delay -clock clk_out -max 0.6 [get_ports src_sync_ddr_dout[*]]-clock_fall -add_delay;
set_output_delay -clock clk_out -min -0.4 [get_ports src_sync_ddr_dout[*]] -clock_fall -add_delay;
方法二Skew Based Method
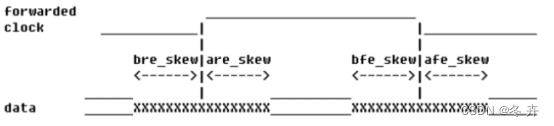
已知条件如下:
时钟信号src_sync_ddr_clk 的频率: 100 MHz
随路送出的时钟src_sync_ddr_clk_out 的频率: 100 MHz
数据总线: src_sync_ddr_dout[3:0]
上升沿之前的数据skew ( bre_skew ) : 0.4 ns
上升沿之后的数据skew ( are_skew ) : 0.6 ns
下降沿之前的数据skew ( bfe_skew ) : 0.7 ns
下降沿之后的数据skew ( afe_skew ) : 0.2 ns
可以这样计算输出接口约束:时钟的周期是10ns ,因为是DDR 方式,所以数据实际的采样周期是时钟周期的一半;上升沿采样的数据的-max 应该是采样周期减去这个数据的发送沿(下降沿)之后的数据skew 即afe_skew ,而对应的-min 就应该是上升沿之前的数据skew 值bre_skew ;同理,下降沿采样数据的-max应该是采样周期减去这个数据的发送沿(上升沿)之后的数据skew 值are_skew ,而对应的-min 就应该是下降沿之前的数据skew 值bfe_skew 。
所以最终写入 的Output 约束应该如下所示:
set period 10.0;
create_clock -period $period -name clk [get_ports src_sync_ddr_clk];
create_generated_clock -name clk_out [get_ports ddr_src_sync_clk_out] \
-source [get_ports src_sync_ddr_clk] -divide_by 1;
set_output_delay -clock clk_out -max [expr $period/2 – 0.2] [get_ports src_sync_ddr_dout[*]] ;
set_output_delay -clock clk_out -min 0.4 [get_ports src_sync_ddr_dout[*]] ;
set_output_delay -clock clk_out -max [expr $period/2 – 0.6] [get_ports src_sync_ddr_dout[*]] \
-clock_fall -add_delay ;
set_output_delay -clock clk_out -min 0.7 [get_ports src_sync_ddr_dout[*]] -clock_fall -add_delay;
对以上两种方法稍作总结,就会发现在设置DDR 源同步输出接口时,送出的数据是中心对齐的情况下,用Setup/Hold Based 方法来写约束比较容易,而如果是边沿对齐的情况,则推荐使用Skew Based 方法来写约束。

例外约束
什么是时序例外?时序例外用于修改对特定路径执行时序分析的方式。默认情况下,时序引擎假定所有路径都应通过单一建立时间分析周期要求来完成时序约束,以便覆盖大部分消极的时钟设置场景。对于某些路径,并非如此。以下提供一些示例:
- 由于时钟间缺乏固定的相位关系,导致无法安全完成异步 CDC 路径的时序约束。此类状况应予以忽略(时钟组,伪路径),或者只需设置数据路径延迟约束(仅最大延迟数据路径)即可
- 时序单元发送沿和捕获沿并非在每个时钟周期内都处于活动状态,因此可相应降低路径要求(多周期路径)
- 路径延迟要求需收紧,以增加硬件中的设计裕度(最大延迟)
- 通过组合单元的路径为静态路径,无需时序约束(伪路径,案例分析)
- 应仅限对多路复用器驱动的特定时钟执行分析(案例分析)。
无论在任何情况下,都必须谨慎使用时序例外,并且不得为了隐藏实际时序问题而添加例外。常用的时序例外命令如下:
| 命令 | 功能简介 |
| set_clock_group | 建立时钟组,组间时序路径不进行分析 |
| set_false_path | 指示某条路径不进行时序分析 |
| set_multicycle_path | 设置路径上从起点到终点的传递数据需要的时钟周期数 |
| set_max/min_delay | 设置最大和最小的延迟值,会重写默认的建立/保持约束 |
Clock Group
在硬件设计中,没有设置clock groups前,综合工具是把所有的时钟作为同步时钟来处理,工具会分析所有时钟下的所有路径。具体的表现是工具会分析任意两两时钟间的timing。可以理解为:增加group 是在原来同步的基础上增加异步描述,不在描述中的还保持同步关系。默认情况下时钟组约束set_clock_groups将关断指定时钟组之间的时序分析,但并不关断时钟组内各个时钟之间的时钟约束。set_false_path约束是单向的,set_clock_groups时序分析忽略是双向的。使用-group选项定义组,工具会排除每个独立组的时钟之间的时序路径。下表显示了set_clock_groups的影响。
- set_clock_groups -group A
| Dest\Source | A | B | C | D |
| A | Analyzed | Cut | Cut | Cut |
| B | Cut | Analyzed | Analyzed | Analyzed |
| C | Cut | Analyzed | Analyzed | Analyzed |
| D | Cut | Analyzed | Analyzed | Analyzed |
- set_clock_groups -group {A B}
| Dest\Source | A | B | C | D |
| A | Analyzed | Analyzed | Cut | Cut |
| B | Analyzed | Analyzed | Cut | Cut |
| C | Cut | Cut | Analyzed | Analyzed |
| D | Cut | Cut | Analyzed | Analyzed |
- set_clock_groups -group A -group B
| Dest\Source | A | B | C | D |
| A | Analyzed | Cut | Cut | Cut |
| B | Cut | Analyzed | Cut | Cut |
| C | Cut | Cut | Analyzed | Analyzed |
| D | Cut | Cut | Analyzed | Analyzed |
- set_clock_groups -group {A C} -group {B D}
| Dest\Source | A | B | C | D |
| A | Analyzed | Cut | Analyzed | Cut |
| B | Cut | Analyzed | Cut | Analyzed |
| C | Analyzed | Cut | Analyzed | Cut |
| D | Cut | Analyzed | Cut | Analyzed |
- set_clock_groups -group {A C D}
| Dest\Source | A | B | C | D |
| A | Analyzed | Cut | Analyzed | Analyzed |
| B | Cut | Analyzed | Cut | Cut |
| C | Analyzed | Cut | Analyzed | Analyzed |
| D | Analyzed | Cut | Analyzed | Analyzed |
n set_clock_groups可以接三个参数asynchronous/logically_
exclusive/physically_exclusive,这三个参数区别:
- asynchronous:多个时钟之间相位关系不确定,就可以将这两个(或多个)时钟设置为asynchronous。一般而言当时钟来自于不同的PLL或者晶振时,时钟之间的相位是不固定的,此时就用asynchronous来设置异步时钟分组。
- logically_exclusive: 两个时钟在传播路径上没有相互的path,可以设置设logically_exclusive。例如下图,mux的两个输入端(pin2、pin3)通过pin0 generated 新的时钟,并设为logically_exclusive,那么路径上寄存器就不会检查这两个新的衍生时钟之间的timing。注意,不能将pin0和pin1上的时钟设为logically_exclusive。pin0和pin1的时钟是有path的,而且不是异步电路 是需要收timing的。
- physically_exclusive:如果两个时钟定义在同一个端口上,那么这两个时钟在物理层面就是不可能同时存在的(对同一时钟节点定义不同的时钟频率,两个时钟在物理上不会共存),此时就需要声明成 physically_exclusive。如下图,pin4会流过两个时钟,一个是clk,一个是clk经过PLL的二分频时钟。这两个频率是准静态或静态切换的,那么可以在pin4(mux的输出端,物理上只有一个节点)上分别generated来源于pin2和pin3的时钟,把这两个衍生时钟设为physically_exclusive。

如果有 2 个或更多个时钟驱动到某 1 个多路复用器(或者更普遍的情况下,驱动到组合单元内)中,这些时钟全部都能顺利完成传输,并在单元扇出上重叠。实际上,每次只能传输 1 个时钟,但时序分析允许同时报告多种时序模式。因此,必须审查 CDC 路径,并添加新约束,以忽略部分时钟关系。正确的约束取决于设计中时钟交互的方式和位置。下图演示了 2 个时钟驱动到同一个多路复用器中的示例,并演示了在此多路复用器前后这 2 个时钟之间可能发生的交互。
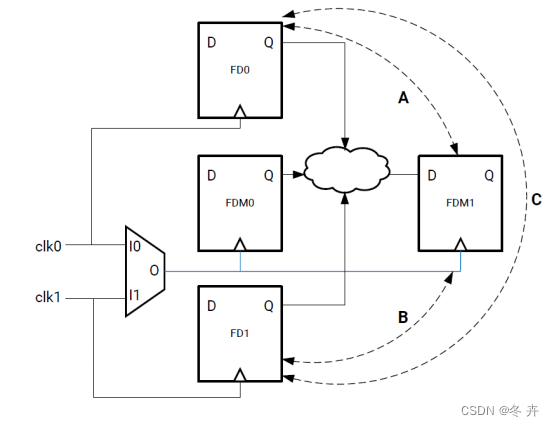
- 路径 A、B 和 C 都不存在的情况
clk0 和 clk1 仅在多路复用器(FDM0 和 FDM1)的扇出中交互。毋庸置疑,时钟组约束可直接应用到 clk0 和clk1 中。
set_clock_groups -logically_exclusive -group clk0 -group clk1
- 仅存在路径 A、B 或 C 之一的情况
clk0 和/或 clk1 与多路复用时钟直接交互。为了保留时序路径 A、B 和 C,无法直接向 clk0 和 clk1 直接应用约束。而是改为必须将其应用于多路复用器的扇出中需要额外的时钟定义的时钟部分。
create_generated_clock -name clk0mux -divide_by 1 \
-source [get_pins mux/I0] [get_pins mux/O]
create_generated_clock -name clk1mux -divide_by 1 \
-add -master_clock clk1 -source [get_pins mux/I1] [get_pins mux/O]
set_clock_groups -physically_exclusive -group clk0mux -group clk1mux
Clock Group举例1:
一个primary clock clk0到达MMCM0产生usrclk和itfclk,另一个primary clk1到达MMCM0产生了gtclkrx和gtclktx.
第一种约束方法:
set_clock_groups -name async_clk0_clk1 -asynchronous -group {clk0 usrclk itfclk} -group {clk1 gtclkrx gtclktx}
如果对于generated clock的名字无法预期,那么使用第二种方法:
set_clock_groups -name async_clk0_clk1 -asynchronous \
-group [get_clocks -include_generated_clocks clk0] \
-group [get_clocks -include_generated_clocks clk1]
Clock Group举例2:相同时钟源上定义的重叠时钟
在相同网表对象上使用 create_clock -add 命令定义两个时钟,并表示单一应用的多种模式时,会出现此情况。在此情况下,可在两个时钟之间安全应用时钟组约束。例如:
create_clock -name clk_mode0 -period 10 [get_ports clkin]
create_clock -name clk_mode1 -period 13.334 -add [get_ports clkin]
set_clock_groups -physically_exclusive -group clk_mode0 -group clk_mode1
如果 clk_mode0 和 clk_mode1 时钟生成其他时钟,那么还需对其生成时钟应用相同的约束,操作方式如下所述:
set_clock_groups -physically_exclusive \
-group [get_clocks -include_generated_clock clk_mode0] \
-group [get_clocks -include_generated_clock clk_mode1]
Clock Group举例3:
一个输入时钟管脚上会有两种频率的时钟输入(如果clk_100 和clk_66 除了通过clock control block 后一模一样的扇出外,没有驱动其它时序元件,我们要做的仅仅是补齐时钟关系的约束),采用如下约束:
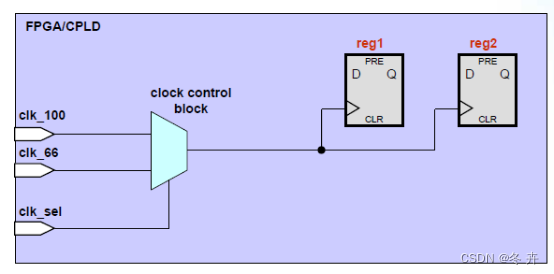
create_clock –period 10.0 [get_ports clk_100]
create_clock –period 15.0 [get_ports clk_66]
set_clock_groups –logically_exclusive –group {clk_100} –group {clk_66}
如果一个mux的输入是可变时钟:
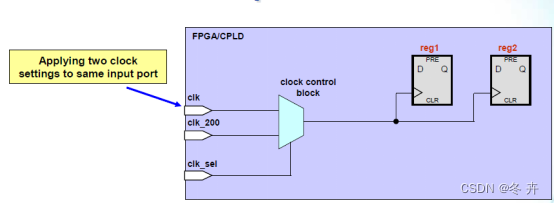
create_clock –name clk_100 –period 10.0 [get_ports clk]
create_clock –name clk_66 –period 15.0 [get_ports clk] –add
create_clock –name clk_200–period 5.0 [get_ports clk_200]
set_clock_groups –physically_exclusive –group {clk_100} \
–group {clk_66}
set_clock_groups –logically_exclusive –group {clk_100} \
–group {clk_200}
set_clock_groups –logically_exclusive –group {clk_66} –group {clk_200}
说明:“-add”是用来对已添加约束的节点再添加新的约束,使得多个约束同时生效。如果不使用“-add”,那么最后一句约束将覆盖前面的约束。
Clock Group举例4:
在很多情况下,除了共同的扇出,其中一个时钟或两个都还驱动其它的时序元件,此时建议的做法是再创建两个重叠的衍生钟,并将其时钟关系约束为-physically_exclusive 表示不可能同时通过,这样做可以最大化约束覆盖率。
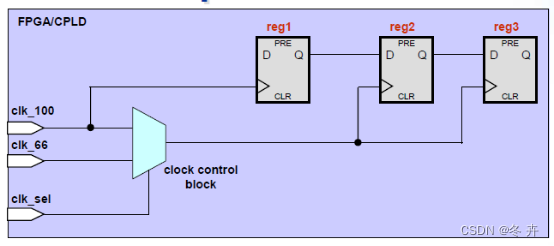
create_clock –period 10.0 [get_ports clk_100]
create_clock –period 15.0 [get_ports clk_66]
create_generated_clock –name clkmux_100 –source clk_100 \
[get_pins clkmux|clkout]
create_generated_clock –name clkmux_66 –source clk_66 \
[get_pins clkmux|clkout] –add
set_clock_groups –physically_exclusive –group {clkmux_100} –group {clkmux_66}
注意,不能直接将clk_100和clk_66设成logically_exclusive,因为这两个时钟是有path的,并不是互斥的。只有mux之后的path,两个时钟才是互斥的。
Clock Group举例5:
在某芯片中,输入时钟clk_640m为定频640M,在phy_top层根据phy_mode进行CG得到clk_4x_phy_mode时钟,支持频率80/160/320/640MHz;在txdfe_top根据tx_en对clk_4x_phy_mode进行CG得到clk_tx,支持频率80/160/320/640MHz;根据dpd_en对clk_4x_phy_mode进行CG得到clk_dpd,由于dpd模块不支持640M应用场景,即clk_dpd只支持频率80/160/320MHz,如何进行时钟约束?
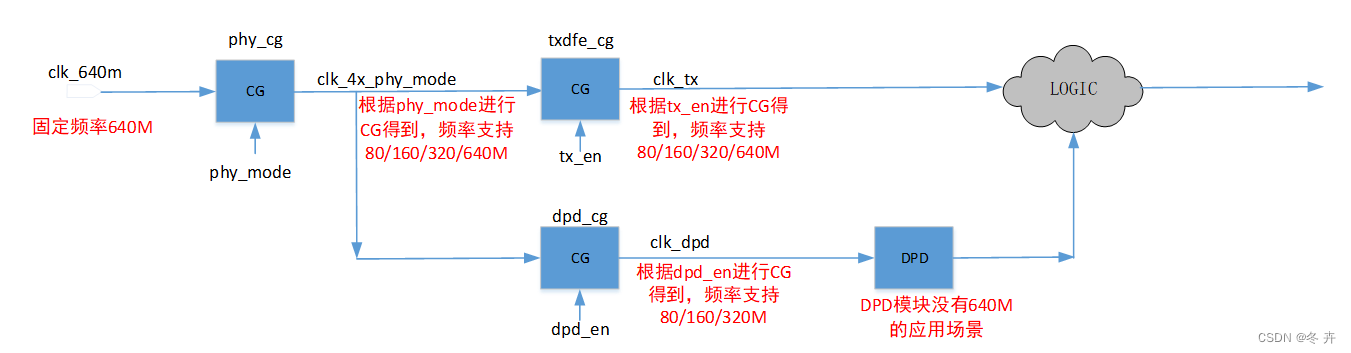
create_clock –period 1.5625 [get_ports clk_640m]
create_generated_clock –name clk_phy_640m –source clk_640m \
[get_pins phy_cg|Q]
create_generated_clock –name clk_phy_320m -edges {1 2 5}–source clk_640m [get_pins phy_cg|Q] -add
create_generated_clock –name clk_dpd –source clk_phy_320m \
[get_pins dpd_cg|Q]
set_clock_groups –physically_exclusive –group { clk_phy_320m } –group { clk_phy_640m }
我们再总结一下logically_exclusive和physically_exclusive的区别:
- Logically_exclusive用于在不同源根上定义的两个时钟;时钟之间没有任何功能路径,但它们之间可能有耦合交互。logically_exclusive时钟的一个例子是MUX输入端口的多个时钟,但仍然可以通过MUX单元的上游耦合进行交互。当两个时钟之间存在物理上存在但逻辑上例外的路径时,使用“set_clock_groups -logical_exclusive”。
- physically_exclusive用于在同一个源根节点上通过create_clock/create_generated_clock -add定义的两个时钟,两个时钟物理上不存在时序路径;使用set_clock_groups -physically_exclusive进行时序例外。
简而言之,logical_exclusive用于选择器的电路,两个时钟的source不一样;而physical_exclusive两个时钟的source是一样,比如在同一个时钟输入口,但可能会输入两个不同的时钟。
False Paths
False Paths(伪路径)的定义:不希望工具进行分析的那些路径,在设计中形式存在,但没有功能性或不需要被时序分析的路径。例如:跨时钟域处理的电路、静态配置寄存器、复位或测试逻辑、异步双端口RAM。
伪路径的优势:减少工具进行优化的时间,增强实现结果,避免在不需要进行时序约束的地方花较多的时间,而忽略了真正需要进行优化的地方。
False Paths举例1

显然MUX1和MUX2不可能同时选通。因此Q到D路径不存在,可以约束为:
set_false_path -through [get_pins MUX1/a0] -through [get_pins MUX2/a1]
注意:“-through”选项至关重要,表示通过此节点的路径。如果没有“from”和“to”,则表示所有通过此节点的路径。
set clock group和set_false_path的关系:
set_clock_group -asyncronous -group CLKA -group CLKB
等效于:
set_false_path -from [get_clocks CLKA] -to [get_clocks CLKB]
set_false_path -from [get_clocks CLKB] -to [get_clocks CLKA]
set_clock_groups -asyncronous -name MY_ASYNC -group {CLKA CLKA_DIV2} -group{CLK_OSC}
等效于:
set_false_path -from [get_clocks CLKA] -to [get_clocks CLK_OSC]
set_false_path -from [get_clocks CLKA_DIV2] -to [get_clocks CLK_OSC]
set_false_path -from [get_clocks CLK_OSC] -to [get_clocks CLKA]
set_false_path -from [get_clocks CLK_OSC] -to [get_clocks CLKA_DIV2]
False Paths举例2
忽略设计中的静态路径。有些寄存器在应用的初始化阶段接收 1 个值后,就不再切换。当这些寄存器出现在设计的关键路径上时,可以忽略其时序,以放宽对实现工具的约束,从而有助于实现时序收敛。仅定义伪路径约束始于静态寄存器即可,无需明确指定路径端点。例如,通过添加如下伪路径约束,便可忽略从 32 位配置寄存器config_reg[31:0] 到其余部分的路径:
set_false_path -from [get_cells config_reg[*]]
False Paths举例3
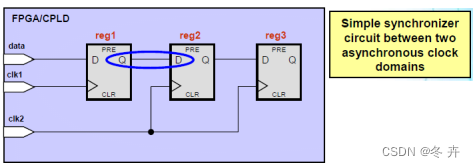
set_false_path –from [get_pins reg1|clk] –to [get_pins reg2|datain]
False Paths举例4

set_false_path –fall_from clk1 –to [get_pins test_logic|*|datain]
set_false_path –from [get_pins test_logic|*|clk] -to [get_pins \ test_logic|*|datain]
set_false_path –from [get_pins test_logic|*|clk] \
-to [get_ports test_out]
Multi-cycles Paths
对于我们的设计,如果有些信号采样是同步的,但是扇出多,走线长,组合逻辑网络的最大延时超过一个时钟周期,我们就需要修改我们的设计,减小组合逻辑的延时;或者如果信号是多周期的电平信号,确实对时序没有严格要求,我们也可以通过Multi-Cycles约束来放松。
Multi-Cycles path 意思是多周期的数据路径,即一个时钟周期不能完成数据传输的路径。一般是由于大的逻辑电路的存在,导致数据的最大延迟可能超过一个时钟周期,这时就需要指明该路径为Multi-Cycles path。因为一般的时序检查工具,默认按单周期的约束对数据路径进行检查,从有效的launch edge 到有效的 capture edge。
标准电路的建立保持时间关系是:setup检查是从source clk的一个上升沿(Current Launch Edge)到下一个destination clk的上升沿(Current Capture Edge),即Multicycle Setup = 1(default);hold检查是从source clk的一个上升沿(Current Launch Edge)到下一个destination clk的前一个上升沿(Previous Capture Edge)或者source clk的下一个上升沿(Next Launch Edge)到下一个destination clk的上升沿(Current Capture Edge),即Multicycle Hold= 0(default)。

图xx 默认情况下建立保持关系
说白了,设置setup多周期,就是修改Current Launch Edge和Current Capture Edge的位置;设置hold多周期,就是修改Previous Capture Edge和Next Launch Edge的位置(hold分析绑定到了setup分析,先由setup确定Current Launch Edge和Current Capture Edge;再根据hold确定Previous Capture Edge和Next Launch Edge,是相对于Current Launch Edge和Current Capture Edge的。也就是说设置setup多周期约束,会影响hold多周期分析)。默认情况下,setup多周期检查是改变destination clk的Capture Edge,如果要改变source clk的Launch Edge,需要增加-start选项。同理,hold多周期检查是改变source clk的Launch Edge,如果要改变destination clk的Capture Edge,需要增加-end选项。
同频时钟的多周期约束
如下图所示,enable_reg每个clk翻转一次,连接到data0_reg、data1_reg寄存器的使能端。因此,在data1_reg的第一个上升沿不采样,只在第二个上升沿采样新数据,即源触发器每隔两拍打出一个数据,下游触发器也是每隔两拍接收源触发器打出的数据。这时定义data0_reg到data1_reg路径多周期约束,电路是安全的。那如何进行多周期约束呢?
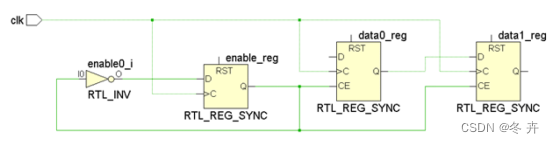
由前面章节分析可知默认约束下的建立/保持时间裕量如下(未考虑时钟skew):
Setup Slack = T-Tsu – (Tco+Tdata)
Hold Slack = (Tco+Tdata) - Th
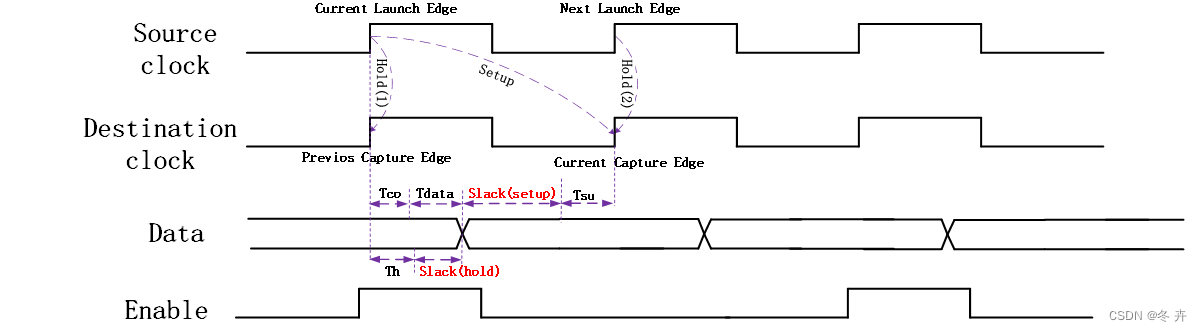
图xx 默认建立/保持关系(setup = 1,hold = 0)
如果对建立时间进行多周期约束:
set_multicycle_path 2 -setup -from [get_pins data0_reg/C] -to [get_pins data1_reg/D]
这时的建立/保持时间裕量如下(未考虑时钟skew):
Setup Slack = 2T-Tsu – (Tco+Tdata)
Hold Slack = (Tco+Tdata) – Th – T
可以看出,在增加建立时间多周期约束后,建立时间检查的current capture edge往后移了一个时钟,但保持时间检查的previous capture edge还是current capture edge的前一个时钟沿,保持时间检查的next launch edge还是current launch edge的后一个时钟沿。这时的建立时间裕量增加了一个时钟周期,保持时间裕量却缩减了一个时钟周期,这时就需要再对保持时间做多周期约束,来改变previous capture edge和next launch edge的位置。

图xx 建立/保持关系(setup = 2,hold = 0)
约束命令如下:
set_multicycle_path 1 -hold -end -from [get_pins data0_reg/C] \
-to [get_pins data1_reg/D]
这时的建立/保持时间裕量如下(未考虑时钟skew):
Setup Slack = 2T-Tsu – (Tco+Tdata)
Hold Slack = (Tco+Tdata) – Th
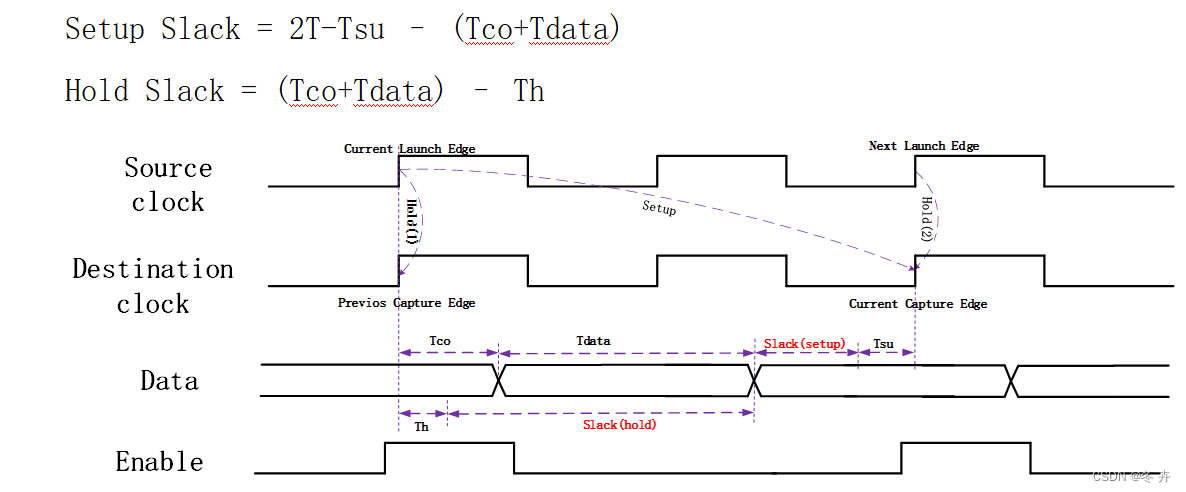
图xx 建立/保持关系(setup = 2,hold = 1)
慢时钟域到快时钟域多周期约束
如图所示,Launch Edge是慢时钟域,Capture Edge是快时钟域。

假设clk2的频率是clk1的三倍,那么不添加约束的话,工具默认进行分析采样关系如下:
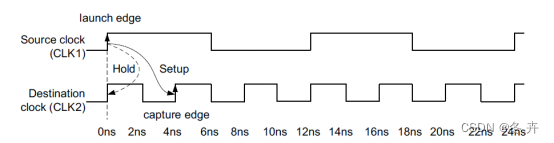
图xx 默认建立/保持关系(setup = 1,hold = 0)
如果只添加建立检查多周期约束,即
set_multicycle_path 3 -setup -from [get_clocks CLK1] -to [get_clocks CLK2]
由于setup检查添加了多周期约束,setup检查相应的Capture Edge右移了2个时钟周期。但hold检查没有添加多周期约束,会使用相对应setup的Launch Edge。
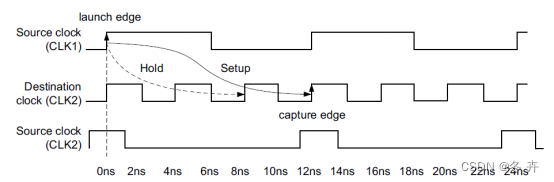
图xx 建立/保持关系(setup = 3,hold = 0)
由上一小节可知,此时建立时间裕量放松了,但保持时间裕量缩减了。所以还要对hold进行多周期约束:
set_multicycle_path 2 -hold -end -from [get_clocks CLK1] -to [get_clocks CLK2]
值得注意的是:hold多周期检查默认是改变Source Clk的Launch Edge,如果这条命令没有-end选项,是达不到放松保持时间裕量的目的的。
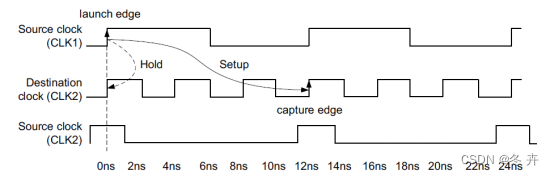
图xx 建立/保持关系(setup = 3,hold = 2)
此时建立时间裕量和保持时间裕量都放松了。
快时钟域到慢时钟域多周期约束
如图所示,Launch Edge是快时钟域,Capture Edge是慢时钟域。
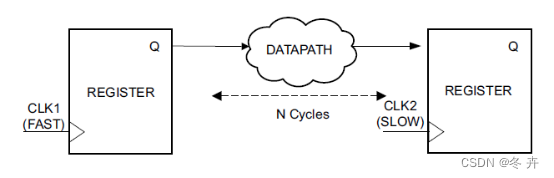
假设clk1的频率是clk2的三倍,那么不添加约束的话,工具默认进行分析采样关系如下:
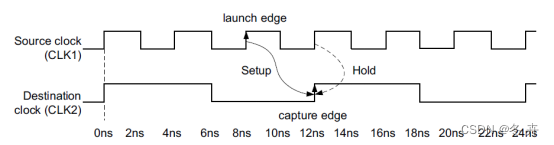
图xx 默认建立/保持关系(setup = 1,hold = 0)
此时需要添加多周期约束:
set_multicycle_path 3 -setup -start -from [get_clocks CLK1] -to [get_clocks CLK2]
set_multicycle_path 2 -hold -from [get_clocks CLK1] -to [get_clocks CLK2]
思考:下图电路中,从触发器FF3的输出能否设置多周期约束?
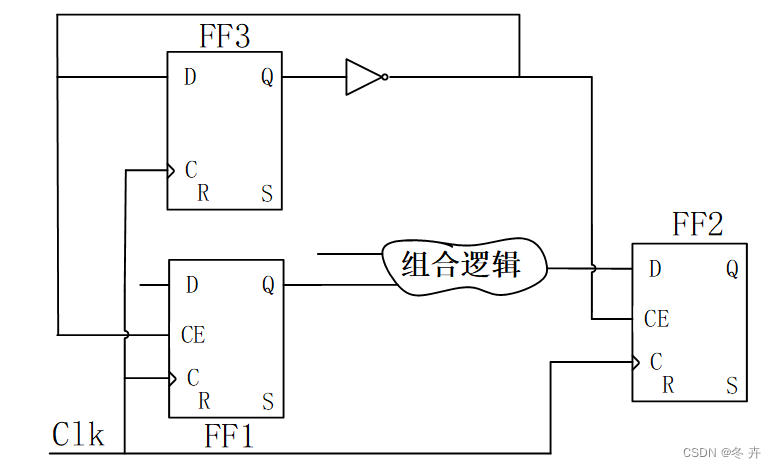
图xx 电路结构图
答案是不能的,并不是触发器每隔两拍(或者以上)变化输出数据,或者接收触发器每隔两拍(或者以上)接收数据,或者两者的组合,就可以设置为多周期约束的。而是应该从Launch Edge到有效的Capture Edge这一段时间内(设置多周期约束后),Launch的数据不发生变化,才能设置为多周期约束,例如上述电路变形后:
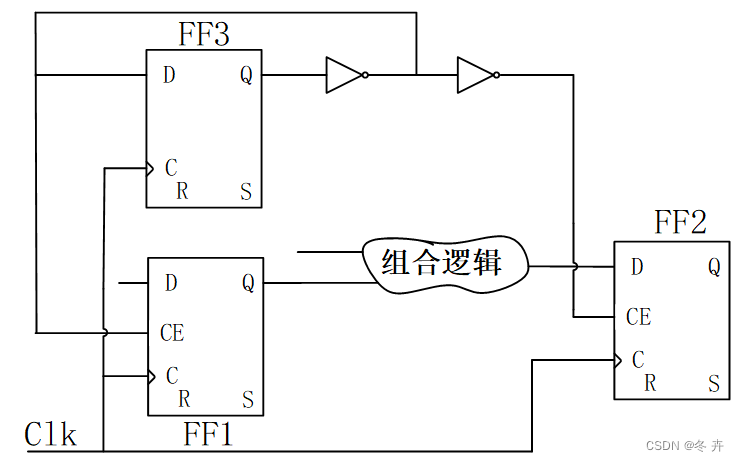
图xx 电路结构图
触发器FF1每两拍打出数据,FF2每两拍接收数据,但是从FF1到FF2不能设置为多周期约束。我们画出设计多周期约束后,时序检查和实际数据变化关系如下:
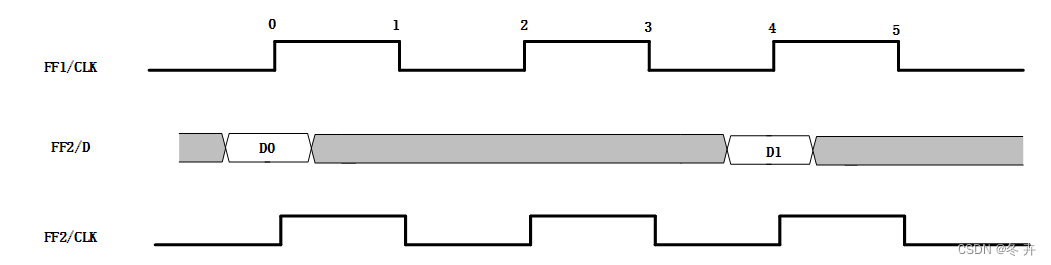
图xx 电路时序检查示意图
在上面电路中,源触发器FF1在0,4,8,…等位置打出数据,那么FF2触发器就在2,4,6,…等位置接收数据,这样的电路是不能设置多周期约束的(必须在4,8,…等位置接收数据)。
在上面说的Capture Edge时,我们说有效的Capture Edge。有效的含义是只关心该拍输出的数据,而其它沿打出的数据是不关心的。例如上面电路再变化一下:

图xx 电路结构图
如果触发器FF2的输出只有到FF4,尽管每拍FF2都采样,但是对于FF4来讲,只关心FF1输出变化数据那拍FF2对应的输出数据。因此,对于这样的电路,也是满足多周期约束的,我们可以设置从FF1到FF2两拍的多周期约束。
总结一下:
- Multi-cycles是放松Data require time达到放松时序的目的,Data arrival time是不变的。
- Multi-cycles Paths设置方法有两种:“-start”和”-end”。“-start”指定source clock的移动时钟数量;“-end”指定destination clock的移动时钟数量,Multi-cycles Paths设置总是相对于参考较快频率的时钟。在setup分析时,默认为“-end”;在hold分析时,默认为“-start”。常用命令总结:
| 同步时钟域场景 | 约束 |
| 同频 | set_multicycle_path N -setup -from CLK1 -to CLK2 set_multicycle_path N-1 -hold -from CLK1 -to CLK2 说明:因为同频,“-start”和“-end”是一样的。 |
| 慢速到快速 | set_multicycle_path N -setup -from CLK1 -to CLK2 set_multicycle_path N-1 -hold -end -from CLK1 -to CLK2 |
| 快速到慢速 | set_multicycle_path N -setup -start -from CLK1 -to CLK2 set_multicycle_path N-1 -hold -from CLK1 -to CLK2 |
- 对于多周期电路,电路设计人员应该特别注意,它是RTL代码设计出来的,并不是最大延迟超过一个周期就可以设置为多周期约束。另外,从DFT角度来看,不建议做多周期约束,否则会带来测试困难,降低覆盖率。对于我们自己设计比较复杂的单元,尽量中间插入触发器,进行Pipeline设计。
Min/Max Delay
Min/Max Delay的用途:用来修改某路径默认的setup和hold时序要求。
set_max_delay <delay> [-datapath_only] [-from <node_list>]
[-to <node_list>] [-through <node_list>]
set_min_delay <delay> [-from <node_list>]
[-to <node_list>] [-through <node_list>]
Min/Max Delay和Input/Output Delay的区别:
set_max/min_delay命令典型应用不是约束input/outpu逻辑的。输入端口到第一级寄存器间的逻辑路径是用set_input_delay命令,最后一级寄存器到输出端口间的逻辑路径是用set_output_delay命令。set_max/min_delay典型应用是约束输入端口到输出端口间的纯组合逻辑路径。可以用来作为Min/Max Delay的Satrtpoint是时序元件的时钟端或FPGA的输入端口,用来作为Min/Max Delay的Endpoint是时序元件(reg/ram)的输入数据端或FPGA的输出端口。如果不是用上述端口作为Satrtpoint或Endpoint,则会出现路径分割,这对时序分析很不利的。
举例1:

正常情况下,set_max_delay 5 -from [get_pins FD1/C]进行约束,但如果set_max_delay 5 -from [get_pins FD1/Q],则FD1/Q到FD2/D成为Path Segmentation。导致在计算FD2的setup时,不会计算FD1/Q的时钟延迟,但FD2/D的时钟延迟仍然会被计算,因此造成很大的skew。
举例2:

建议的做法不是设置set_clock_groups约束,转而采用set_max_delay来约束这些跨时钟域路径。以写入侧为例,一个基本原则就是约束cell1到cell2的路径之间时延等于或小于cell2的驱动时钟一个周期,读出侧同理约束。
编写 CDC 约束时,需要验证是否遵循相应的优先顺序。如果在 2 个时钟之间至少 1 条路径上使用 set_max_delay –datapath_only,那么无法在相同时钟之间使用 set_clock_groups 约束,并且只能在 2 个时钟之间的其他路径
上使用 set_false_path 约束。在下图中(将上图的cell2展开),时钟 clk0 的周期为 5 ns,并且与 clk1 之间处于异步关系。从 clk0 域到 clk1 域存在两条路径。第 1 条路径为 1 位数据同步。第 2 条路径为多位格雷编码总线传输。判定格雷编码总线传输需要“Max Delay Datapath Only”(仅最大延迟数据路径)来限制比特间延迟变动,因此无法在时钟之间直接使用“Clock Group”(时钟组)或“False Path”(伪路径)约束。而改为必须定义以下 2 个约束:
Set_max_delay -from [get_cells GCB0[*]] -to [get_cells [GCB1a[*]] \
-datapath_only 5
Set_false_path -from [get_cells REG0] -to [get_cells REG1a]
无需设置从 clk1 到 clk0 的伪路径,因为在此示例中不含任何路径。
|
|

时序例外准则
尽量限制使用的时序例外的数量,并使时序例外尽可能保持简单。否则,将面临下面挑战:
- 如果过多使用例外,实现编译时间将显著增加,当这些例外与大量网表对象相关联时尤其如此。
- 当多个例外覆盖相同路径时,约束调试会变得极为复杂。
- 对信号施加约束会阻碍该信号的最优化。因此无论是包含非必要的例外还是在例外命令中包含非必要的点,都会妨碍信号最优化。以下是可能会对运行时间产生不利影响的时序例外示例:
set_false_path -from [get_ports din] -to [all_registers]
如果 din 端口没有输入延迟,那么它将不受约束,因此无需添加伪路径。如果 din 端口仅供给时序元件,那么无需对时序单元显式指定伪路径。按如下方法编写此约束更有效:
set_false_path -from [get_ports din]
如果需要伪路径,但从 din 端口到设计中的任意时序单元之间仅存在几条路径,那么约束可以更明确(all_registers 可能会返回数千个单元,这取决于设计中使用的寄存器数量):
set_false_path -from [get_ports din] -to [get_cells \ blockA/config_reg[*]]
时序例外优先级规则
时序例外需遵循严格的优先级规则。最重要的规则包括:
- 约束越具体,优先级越高。例如:
Set_max_delay -from [get_clocks clkA] -to [get_pins inst0/D] 12
Set_max_delay -from [get_clocks clkA] -to [get_clocks clkB] 10
第一条set_max_delay 约束优先级更高,因为 -to 选项使用管脚,这比时钟更为具体。
- 例外优先级如下所示:
- set_false_path
- set_max_delay 或 set_min_delay
- set_multicycle_path
set_clock_groups 命令不视为时序例外,即使它等同于 2 个时钟之间的 2 条 set_false_path 命令也是如此。它的优先级高于时序例外set_case_analysis 命令和 set_disable_timing 命令用于禁用特定设计部分上的时序分析。其优先级高于时序例外。
建议的约束顺序
约束语言 (无论是XDC还是SDC) 基于 Tcl 语法和解读规则。与 Tcl 一样,属于顺序语言:
- 必须先定义变量,然后才能加以使用。同样,必须先定义时序时钟,然后才能将其用于其他约束中。
- 对于覆盖相同路径并具有相同优先级的等效约束,使用最后一项约束。
- 当多个时序例外覆盖同一条路径时,使用具有更高优先级的约束。
- 当考虑以上优先规则时,时序约束总体上应遵循以下顺序:
## Timing Assertions Section
# Primary clocks
# Virtual clocks
# Generated clocks
# Delay for external MMCM/PLL feedback loop
# Clock Uncertainty and Jitter
# Input and output delay constraints
# Clock Groups and Clock False Paths
## Timing Exceptions Section
# False Paths
# Max Delay / Min Delay
# Multicycle Paths
# Case Analysis
# Disable Timing
当使用多个约束文件时,必须特别留意时钟定义,并确认从属关系排序是否正确。物理约束可能位于任意约束文件中的任意位置。
FPGA
|
|

分析并解决时序违例
- 了解当前设计资源情况,当前应用器件资源比例,识别资源瓶颈。
- 了解当前时钟的分布情况与量级,组合逻辑情况,扇出情况,是否应用全局时钟资源。
- 设计时要根据当前工作频率,减少组合逻辑级数设计和高扇出设计。说明:组合逻辑级数可以根据30/70原则计算,30/70原则是指组合逻辑延时<(Tclk -Tco)*30%,其它用于走线延迟,基于此,组合逻辑最大LUT级数<(Tclk -Tco)*30%/一级LUT的平均延迟,Tco和一级LUT的平均延迟可以查手册得到,由于这里不精确计算,所以未考虑时钟抖动和延迟。假设基于4输入LUT的FPGA器件进行开发,工作时钟为370MHz,查器件资料获得Tco = 0.3ns,一级LUT平均延迟为0.33ns,则该设计下最大组合逻辑LUT级联数位2 (计算公式为:(1000/370-0.3)*30%/0.33 = 2.18)。根据这个计算结果,再编码时,应控制逻辑LUT级联数尽量不要超过2级,少量因设计困难(如时序匹配)而达到3级LUT级联是允许的,最终以时序收敛情况判断是否要进行优化。也就是说违背该规则的编码越多,合版本时,投入时序收敛优化的代价越大。
- DSP/RAM的输入先寄存,输出信号寄存后再使用,避免RAM-RAM的路径。
- 模块之间的输入/输出信号寄存(至少输出需要寄存)。
- 时序与资源平衡,小块的RAM请用分布式RAM,大深度大位宽高频RAM提前考虑地址MUX选择,考虑地址多打1-2拍。
- 查看时序分析报告时,不要只关注当前不满足要求的时序,需要从这个时钟出发,工具会先满足一些组合逻辑级数高、扇出大的路径。需要线检查设计中是否存在高组合逻辑高扇出的设计,先将这些组合逻辑级数降低,高扇出信号做适当的复制。
- 适当的将以下可以放松的路径放松约束,比如max_delay和false约束。
FPGA时序优化
时序优化的动机
逻辑设计的主体一般是时序逻辑,若时序不满足会导致功能不正常。一般遇到以下情况,会进行时序优化:
- 资源将满,布局布线裕量小,开始出现时序问题;
- 改用低速器件,本来没有时序问题的代码开始出现时序问题;
- 有新设计需求,功能提速后,开始出现时序问题;
- 因裕量小导致跑版本速度慢,希望通过时序优化来提速;
- 接口时序不当,导致时序不过;
- 存在多周期情形,希望提供更精细的时序描述让工具布线更快更轻松。
时序优化的途径
代码修改
在设计上保证FPGA器件跑出好时序,代码途径有两种操作思路:
- 被动式
时序驱动法,出了时序问题就去优化出问题的地方;
- 主动式
裕量驱动法,分析裕量最小的节点;扇出驱动法,分析扇出大的节点。
各方法的优缺点为
- 问题驱动法
优点:见效快,改好后马上就能出无时序问题的版本。除了有问题的地方,还能识别出当前时序裕量最小的地方加以优化;
缺点:可能不彻底,比如按下这个问题,另一个时序问题又冒出来了,增加一点资源又出问题了。
- 裕量驱动法
优点:时序问题挖掘较全面,能找到未来可能优先冒出来的时序问题;
缺点:版本变动后,可能最小时序点不同。
- 扇出驱动法
优点:可一次性挖掘出较多的问题;
缺点:可能工作量比较大,需要权衡成本;一次改动得多可能对资源影响大;不一定挖掘出全部时序问题,比如资源紧张时,硬core的放置位置对时序的影响;可能报出来的时序最差地方并不是扇出大的地方。
约束优化
通过合理约束,固化工具的已有成果,让工具有正确的时序目标。
增加工具的努力程度
增加努力程度,让工具更努力、更优化的去布线;通过位置约束固化最优的布局。
时序优化的策略
| 代码修改 | 约束优化 | 增加工具努力程度 | |
| 工作量 | 大 | 大 | 小 |
| 布线时间 | 短 | 短 | 长 |
| 演进效果 | 好 | 好 | 查 |
如果时间精力有限,可以采取以下策略:
首先,将工具的努力程度降到最低,解决报出的时序问题;
其次,解决时序裕量较小且好改的地方,有余力就优化;
若由于代码变更导致新的时序问题且需要紧急出版本的,用工具方法实现时序问题的快速消除。
FPGA高速设计
简介
什么是高速设计?
FPGA高速设计可以从广义和狭义两个角度进行定义。狭义上,FPGA的主时钟频率要求很高,如FPGA主时钟工作频率要求大于350MHz。广义上,满足一定苛刻条件下(器件等级,资源占用率)的FPGA设计,不一定都是350MHz。
无论从广义还是狭义角度定义的FPGA高速设计,其基本原理均是通过从前端布局优化、方案设计、到后端的一些列策略方法,来保证高速时钟域下,两个相邻触发器之间的组合逻辑延迟Tcomp与走线延迟Tnet之和小于该时钟周期(或Tcomp+Tnet≈T-Tco).
基础知识范围
- 器件知识(后面章节会介绍):器件厂商、等级;器件资源(REG、LUT、BRAM、DRAM、DSP、BUFG…);器件结构等。
- 布局规划:PINMAP布局;模块预布局;时钟规划等
- 设计实现:方案设计;代码实现;设计资源评估;组合逻辑级数评估;
- 后端(前面章节已讲):时钟约束;异步路径约束;Multicycle/false path约束;位置约束;后端时序分析。
逻辑高速设计
高速设计流程

布局规划
2W1H
What:布局规划包括PINMAP分配、LE/DSP/BRAM/硬core按一级模块划分区域,理顺数据流走向、布线资源的规划(全局布线资源(全局时钟、复位)、长线资源(bank间、一级模块间信号传递,全局控制信号等)、分布式的布线资源(专有时钟、复位、控制信号线))。
Why:从宏观上看,布局规划目的是平衡FPGA芯片内各类资源使用及分布,减少拥塞(congestion);从微观上看,布局规划目的是要缩短reg-to-reg间路径delay。提前做好布局规划,有利于优化FPGA的整体布局,减少数据交叉及长线资源,让时序问题止于前端。例如右图的布局规划明显优于左边的。

How:要做好布局规划,需要掌握备选器件整体架构、资源分布结构、逻辑资源固有特性;熟悉逻辑设计总体方案、功能模块数据流关系,各模块资源情况。
模块规划
基本原则:
- 高内聚,低耦合。各个模块功能内聚,最好功能单一(尽量一个模块一个功能),模块间接口简洁;
- 资源均衡。各一级模块的资源均衡,最大不能超过总资源的35%。功能分配合理,一级模块内REG/LUT/RAM/DSP保持均衡,如REG:LUT控制在1.2~1.6间。
- 功能模块接口定义合理,模块间的连线最少,避免强时序要求握手接口;
- 模块时钟域最少;
- 主体数据流向单调,尽量不要出现反馈结构、环状结构;
- 一级模块间不允许存在功能性代码(接口间打拍可以),模块输入、输出信号寄存;

- 复位及CPU接口采用分布式处理(避免复位信号扇出太大),如下图;

时钟规划
时钟、复位网络的global、regional资源使用和规划原则:
- 专用的时钟管脚必须通过专用走线驱动其专用的时钟资源(GCLK/BUFG/MMCM等)
- 尽量保证时钟通过专用时钟管脚驱动内部逻辑;
- 根据时钟驱动范围及扇出能力,决定时钟管脚驱动的时钟资源(BUFG、BUFR、BUFH);
- 单个BANK(CLOCK REGION)的时钟数量必须遵循器件的要求,不能超过器件的上限;
- 避免时钟驱动器级联。

PINMAP规划
PINMAP布局要充分考虑片上系统数据流走向,减少交织、耦合。外围接口(尤其高速接口)在bank选择时,成组的管脚(如CPU/RGMII等)必须分布在同一个bank上或者相邻bank上;控制信号管脚及其相关联的数据管脚一起分布;多die器件时钟和IO尽量放在使用模块所在的die上。对于硬core的管脚以及相关逻辑region划分,要遵守就近原则。
Routing resource
交通规划时,不要出现局部走线资源超负荷导致拥塞(congrestion),布局要提前考虑一级模块区域划分,均衡不同routing resource的占用情况;高内聚,尽可能提高local interconnects/direct links使用率。
模块方案实现
模块设计流程

资源要关注总资源是否符合预期;REG/LUT比是否均衡,通常1.2~1.6间,超过1.8就要关注了;另外是否有某项资源使用特别突出(BRAM/DSP…)。时序要关注组合逻辑级数和高扇出信号。
组合逻辑级数处理
如何控制逻辑级数(logic-level)?第一,要了解SLICE内部结构,Xilinx从6系列器件开始,SLICE中REG和LUT的比例提升至2:1,对于高速设计需要适当增加打拍流水,使得所有逻辑尽量满足逻辑级数限制(对于350MHz设计,逻辑级数一般不能超过4级);第二,逻辑级数估计及检查,通过计算组合逻辑函数输入变量个数,可以大致估算出逻辑级数;通过实际综合布线之后相关命令可以报出最大逻辑级数。
方法1:pipeline
pipeline时序优化方法,其本质是在一个较长的组合逻辑路径中,增加寄存器,用寄存器合理分割该组合逻辑的路径,从而降低路径Clock-To-Output和setup等时间参数的要求,达到提高设计频率的目的。Pipeline提升性能的方法是对具有多个逻辑层次的长数据路径进行重构,并将其分布在多个时钟周期中。此方法可加速时钟周期并增加数据吞吐量,但代价是时延和流水线开销逻辑管理工作增加。由于器件包含许多寄存器,因此通常额外的寄存器和开销逻辑不足为虑。但是,数据路径将跨多个周期,需特别留意设计其余部分,并考量路径时延增加的问题。

如下图,CIC滤波器会有很多级加法器级联,而且位宽很大,尤其在积分器侧,速率也高,容易成为关键路径。可以把加法器和寄存器位置交换实现pipeline,但滤波器延迟会增大;可以折中只在积分器侧加pipeline(无论抽取,还是插值,都是积分器工作在高速侧)。
一定要提前考量流水打拍。提前而非滞后考量流水线有助于改进时序收敛。在后期对某些路径添加流水线通常会导致在电路中产生传输时延差异。这可能导致看似微小的更改需要对部分代码进行大幅重新设计。在设计中提前识别是否有机会添加流水线可以显著改进时序收敛、实现运行时间(因为时序问题变得更易于解决)和器件功耗(因为相关逻辑切换次数减少)。某个项目上接收链路前端使用了4级CIC抽取滤波器,前期未加pipeline,到后期综合时加法器处于关键路径上,此时再加pipeline的话,DV环境上所有接收链路的时延都要调整,所有case都要重新回归,代价非常大。

另外要通过添加pipeline来平衡时延,可以添加到控制路径中,而不是数据路径中。数据路径包含更宽的总线,这可增加所使用的触发器和寄存器资源的数量。
例如,如果有一条 128 位数据路径、2 个寄存器阶段并且需要 5 个时延周期,插入 3 个寄存器阶段会导致额外产生 3x128 = 384 个触发器。或者,可以使用寄存器来控制启用数据路径的逻辑。使用 5 个阶段的单比特寄存器可分别控制数据路径触发器的使能信号和多周期路径时序例外。
注意:此示例仅适用于某些设计。例如,如果在中间数据路径触发器中存在扇出,那么仅采用 2 个阶段是无效的。
方法2:retiming
由于触发器与函数发生器包含在相同 slice 内,时钟速度受到下列要素的限制:源触发器的时钟输出时间、贯穿 1 个逻辑层次的逻辑延迟、布线延迟,以及目标寄存器的建立时间。在此示例中,完成流水打拍和重定时之后,系统时钟运行速度比原始设计中更快,但总的延迟未变化。

方法3:面积换时序--one-hot
将关键路径的优先级路径(多级mux级联)转换成one-hot逻辑,以面积换时序。

方法4:分支判断优化
分支判断优化,用casex/casez替换优先级判断

方法5:计数器优化
计数器优化,提前产生判断条件,减少大位宽比较器的组合逻辑延迟。

方法6:partial case
Xilinx 7系列FPGA中,一个6输入LUT最大只支持4MUX1,超过4个输入将用多级LUT级联。


方法7:priority

其中critial信号到寄存器D端是时序的关键路径,通过变化代码风格,时序路径中的组合逻辑从2级减小到1级。

方法8:反馈环优化
反馈环优化,非反馈部分电路提前计算,插入流水(适用CRC/PRBS/扰码等带有反馈的电路)

高fanout信号处理
如何控制扇出(fanout)?需要考虑寄存器和网线两种类型的扇出。Reg信号加max_fanout约束,对模块总体加max_fanout约束,总体max_fanout约束值不宜设置太小,否则容易使资源增加,对时序产生负面影响;复制信号时,需要加keep约束,对reg和wire扇出过大都有效,需要人工分配复制的信号。
高fanout信号是高速设计的关键点之一。第一,在设计中减少不必要的负载。对于高扇出控制信号,请评估是否设计的所有编码部分都需要该信号线。减少负载数量可以大幅度减少时序问题。第二,高fanout信号尽可能放在芯片die中间,或者其扇出逻辑区域的中心(对于时钟信号网络,不关心走线的绝对时延,只关心相对的skew,而一般的高fanout信号还要关注到各扇出点的绝对时延大小)。第三,全局复位信号走全局时钟网络,区域复位信号走区域时钟网络。第四,要根据不同时钟域,扇出资源,约束合理的fanout值;一般寄存器扇出控制到200以内,BRAM控制到4~8,LUT控制到20以内;
第五,增加适当的pipeline,或复制,避免long heavy local routing。

对于扇出大,时序耦合紧或用 CBB不便修改的,可以加综合扇出域值约束,以通过寄存器复制来分流。寄存器保留用于代码明确分流时不让工具优化;寄存器复制用于代码中不明写,而用工具产生复制的寄存器,从而提升关键路径的速度。这便于实现工具更加灵活地对各类不同负载和相关逻辑进行布局布线。综合工具广泛采用了这种方法。大多数综合工具使用扇出阈值限值来自动判定是否需要复制寄存器。降低此全局阈值即可自动复制高扇出信号线。但这样就无法控制需复制的寄存器范围以及这些寄存器的负载分组方式。此外,全局复制机制无法准确评估时序裕量,导致不必要的复制单元、逻辑占用率增加以及潜在功耗增加。对于高频率设计,要减少扇出,最好对高扇出信号使用平衡树。可考虑根据设计层级手动复制寄存器,因为层级中包含的单元通常布局在一起。例如,在下图所示的平衡复位树中,在 RTL 中复制高扇出复位 FF RST2 以平衡不同模块之间的扇出。如果需要,物理综合可以基于布局信息执行进一步的复制以改进 WNS。
注意:要在综合中保留重复寄存器,请使用 KEEP 属性,而不是 DONT_TOUCH。在实现流程后期进行物理优化期间,DONT_TOUCH 属性会阻止进行进一步最优化。注释:如果复制的是 LUT而不是寄存器,表明应用的属性或约束错误。
|
|

切勿复制用于同步跨时钟域的信号的寄存器。如果这些寄存器上存在 ASYNC_REG 属性,将导致工具无法复制这些寄存器。如果同步链扇出极高且复制必须满足时序要求,那么要在不含 ASYNC_REG 约束的同步链之后添加额外的寄存器(后面跨时钟域章节再细讲)。下表提供了适用于中等性能的 7 系列器件的扇出指南:
|
|

第六,避免高fanout信号级联耦合。

专用资源处理
- 全局布线资源
时钟,复位等高扇出信号等使用全局布线资源。全局网络的驱动能力强,时延小,利于连接到多扇出。采用全局时钟网络,可以减小时钟网络的时延和相差,有利于同步,提高系统性能。尽量减少不必要的复位信号,对于数据的流水,建议不做复位处理或采用同步复位。若时钟资源不足导致某时钟无法上全局,可分析是否通过共享时钟资源解决。
- SRL用于延迟处理
能采用SRL进行延迟处理的地方尽量使用SRL,一方面降低资源占用,更重要的是可以减少走线资源的占用,提高版本时序。SRL为纯组合逻辑单元,使用时要遵守“三明治”原则:REG-SRL-REG,SRL的输入输出都要寄存器打拍。
- BRAM
BRAM资源充足的情况下,优先使用BRAM。RAM深度很小时,也可以考虑用分布式RAM,但输入输出均要用寄存器打拍。大RAM建议用拼接深度的方式,有利于功耗优化,地址译码部分一般需要加max_fanout约束,必要时,采用手工复制分配不同地址copy到各个BRAM单元。BRAM输出要寄存,对应原语的DOA_REG/DOB_REG参数要配置1’b1.
RAM硬core的放置导致时序问题,若时序耦合紧,不易打拍,如果RAM是打2拍的,可将RAM改为1拍,在外部输出再打1拍。FIFO硬core的放置导致的时序问题,若时序耦合紧,不易打拍,如果FIFO是打2拍的,可将FIFO改为1拍,在外部将输出再打拍;如果FIFO是1拍的,就改为预读的0拍FIFO,用读使能去锁存FIFO输出。
- DSP
DSP SLICE为器件内部重要的高速单元,要充分利用其特性。大位宽(超过30bit)加减法建议使用DSP SLICE实现。在资源允许的情况下,尽量可能多的使用DSP SLICE用于设计,并且尽可能多的使用DSP内部资源完成特定功能(如预加、累加、寄存器等)。DSP SLICE尽可能采用级联方式,级联时,使用DSP专用高速走线资源,采用级联方式可以大大降低逻辑走线资源占用(如复乘器,根据需要可以采用三DSP级联或四DSP级联的方式,三DSP级联使用的DSP资源更少,四DSP复乘级联可以实现更高的速度)。DSP SLICE内部寄存器开关要参考器件用户手册fmax的说明,一般来讲MREG、PREG需要使能,A/B/D端至少需要一拍寄存。
代码设计不易跑出好时序(硬CORE的输出直接被大组合逻辑使用,硬CORE中未配置多余的寄存器流水),同时时序耦合紧不易修改。此时,在资源充裕的条件下,可考虑添加冗余硬CORE来进行分流,实现面积换时序。
- IOB
XILINX三态信号是否成功锁IOB(若不成功需要对使能信号进行复制,并对使能寄存器设置综合时不优化)。要锁IOB的信号是否已锁成功(输入信号必须打一拍后再使用,输出的PIN管脚寄存器不能再使用,否则会导致锁不了IOB)。使用管脚寄存器(I/O Registers),了解器件的IO特性与结构,I/0的应用尽量例化器件的IOB模块,采用IO pad上的寄存器。
可重用设计重点语法
【向量及索引部分选择】
Verilog语法中没有向量的语法描述,简单的说就是将位宽等分成多个部分形成一个向量。对于参数、模块端口等不支持多维数组的情况可以考虑使用向量来增加设计的可重用性,如input wire [DW_IN*CHANNEL-1:0] din,din[DW_IN-1:0]为channel 0的输入,din[2*DW_IN-1:DW_IN]为channel 1的输入...。索引部分选择是Verilog2001的语法,在向量索引中使用索引部分选择更加简洁方便有利于代码的可重用设计。
【参数】
通过使用参数向量可以方便实现可变数目模块的参数化,比如用参数向量来实现任意阶滤波器系数的参数化。通过使用参数向量可以实现不同位宽信号的参数化处理。通过对参数进行复杂运算以及调用常数函数计算参数来增加设计的可重用性。
【常数函数】
常数函数是Verilog函数的一个可综合子集,对于参数化设计非常重要,如parameter DW_B = $clog2(DW_A)。常数函数跟参数配合使用,用于复杂参数化设计。
【Generate语句】
通过generate-if和参数的配合替代可重用性较差的ifdef语句。灵活使用generate-if/generate-for以及各种嵌套方式有利于提高代码可重用性。
子模块综合布线
解决时序问题的阶段越早越好,子模块代码风格、质量对后端综合布线结果影响很大,做好模块的综合布线检查对于大版本时序收敛非常重要。
【子模块综合布线工具设置】
对于子模块端口数超过FPGA器件管脚的情况需要对ISE或者VIVADO进行设置。ISE 中Xilinx Specific Options中去掉Add I/O Buffer, Map Properties(Advanced)中去掉Trim Unconnected Signals;VIVADO中需要在综合设置的More Options中加入-mode out_of_context。加入时序约束,最好同时加入位置约束限制布局布线的范围。
【子模块综合布线检查项】
时序裕量是否足够;是否存在较大级数(logic-level)路径,超过350M设计逻辑级数一般不宜超过4级是否存在较大扇出信号,一般扇出超过50都需要进行Review。子模块综合布线修改后需要重新综合布线确认直至闭环。
【将逻辑从控制管脚推送到数据管脚】
分析关键路径期间,可能会发现有多条路径止于控制管脚。必须对这些路径进行分析,以判定是否能够将逻辑推送到数据路径中,同时避免发生惩罚(例如,额外的逻辑层次)。相同逻辑层次的前提下,相比于指向 CE/R/S 管脚的路径,指向 D 管脚的路径的延迟较小,因为从最后一个 LUT 的输出到 FF 的 D 输入之间存在直接连接。以下编码示例显示了如何将逻辑从控制管脚推送到寄存器的数据管脚。在以下示例中,dout_reg[0] 的使能管脚的逻辑层次数为 2,而数据管脚的逻辑层次数则为 0。在此情况下,可通过将使能逻辑移至 D 管脚来改进时序,方法是在 RTL 文件中的 dout 寄存器定义上将 EXTRACT_ENABLE 属性设置为“no”。

止于寄存器控制管脚(使能)的关键路径
以下示例显示了如何拆分组合逻辑和顺序逻辑以及如何将完整逻辑映射到数据路径中。这将把逻辑推送到仍含 2 个逻辑层次的 D 管脚中。可通过将 EXTRACT_ENABLE 属性设置为“no”来实现相同的结构。

止于寄存器的数据管脚(禁用使能提取)的关键路径
后端设计
工具的综合选项
XST为例:
- 设置“Optimization Goal”为“Speed”,XST会尽量减少逻辑级数来改进时序;
- 设置“Max Fanout”为“200~1000”。默认的值是“100000”。这是一个全局的扇出约束,会影响所有信号。如果个别关键信号需要更低的扇出,请在RTL代码里单独设置扇出约束;
- 使能“Read Cores”可以使XST读入EDIF或者NGC格式的Core,于是XST可以看到逻辑是如何互连的,因此可以优化Core接口的逻辑来获得更好的Timing;
- 在大多数情况下,使能“Register Duplication”可以提高Timing;
- 在大多数情况下,使能”Register Balance可以提高Timing;
- 设置“LUT Combining”为“No”。在大多数情况下,将“LUT Combining”设置为"Area”会降低Timing;
- Pack I/O Registers/Latches into IOBs对于I/O时序敏感的设计,推荐设置为“Yes”。这是一个全局的设置,会影响所有I/O。如果不同的IO需要不同的设置,推荐在UCF里单独设置。
后端约束
【False-path使用原则】
不相关时钟域信号或者静态配置信号,可以对其进行false-path约束,确保布局布线不会分析这些路径。而对于静态配置信号,尽管这些路径不一定会成为关键路径,但还是要约束,因为工具布线时会把其他路径布完之后最后再布false-path,这就避免了这些路径和其他时序更紧张的路径抢夺宝贵的布线资源。写代码时可以有意将静态配置奇存器用特定规则命名,比如加上_cfg的后缀,这样在约束时一个通配符就搞定了,而不需要一条条列举出来。
【multi-cycle使用原则】
识别并约束multi-cycle路径,减小时序压力。通过加上multi-cycle约束来让总线的时序在满足要求的基础上,尽可能的让位于其他工作逻辑的时序收敛。比如CPU总线通常可增加multi-cycle约束。加该约束主要注意不要有遗漏,包括CPU总线译码模块内部路径、各总线子译码模块内部总线到配置寄存器的路径、配置寄存器到读总线的路径。CPU总线译码模块可以配合加上位置约束,将其位置约束在FPGA的中心,使其到各模块的走线均不会太长。
【位置约束使用原则】
复位信号的BUFG及前级寄存器、与serdes相连的寄存器、RAM及DSP的位置反标等。复位信号的路径可以分成两段,从复位信号寄存器到BUFG是前半段,以及从BUFG到目标寄存器是后半段。后半段路径主要是通过不同的种子跑时序,将复位信号时序较好的种子对应的BUFG的位置固定反标;前半段路径主要是手动将复位信号寄存器的位置固定在相应的BUFG旁边,以尽量减少走线延时。与SERDES相连的FF最好做位置约束,约束到SERDES附近。通过约束RAM和DSP位置,疏导后端布局,提升工具布局效率
这篇关于逻辑这回事(三)----时序分析与时序优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







