本文主要是介绍5.31.15 使用图像到图像转换和 YOLO 技术对先前的乳房 X 光检查结果中的异常进行早期检测和分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在本研究中,我们研究了基于 You-Only-Look-Once (YOLO) 架构的端到端融合模型的有效性,该模型可同时检测和分类数字乳房 X 光检查中的可疑乳腺病变。包括四类病例:肿块、钙化、结构扭曲和正常,这些病例来自包含 413 个病例的私人数字乳房 X 光检查数据库。
对于所有病例,先前的乳房 X 光检查(通常是 1 年前扫描的)均报告为正常,而当前的乳房 X 光检查被诊断为癌变(经活检证实)或健康。 方法:建议将基于 YOLO 的融合模型应用于当前的乳房 X 光检查,以检测和分类乳房病变。然后将同一模型回顾性地应用于合成乳房 X 光片以进行早期癌症预测,其中合成乳房 X 光片是使用图像到图像转换模型 CycleGAN 和 Pix2Pix 从 Prior 乳房 X 光片生成的。
结果:评估结果表明,我们的方法可以显著检测和分类当前乳房 X 光片上的乳腺病变,肿块病变的最高率为 93% ± 0.118,钙化病变的最高率为 88% ± 0.09,结构扭曲病变的最高率为 95% ± 0.06。此外,报告了对 先前 乳房 X 光片的评估结果,肿块病变的最高率为 36% ± 0.01,钙化病变的最高率为 14% ± 0.01,结构扭曲病变的最高率为 50% ± 0.02。因此,在当前和先前检查中,对正常乳房 X 光检查的分类准确率分别为 92% ± 0.09 和 90% ± 0.06。
结论:提出的框架最初是为了帮助在当前筛查中检测和识别 X 光乳房 X 光检查中的可疑乳腺病变而开发的。建议减少先前和后续筛查之间的时间变化,以便尽早预测先前乳房 X 光检查中异常的位置和类型。
1. 介绍
乳腺癌最常见的症状是乳腺结构和组织外观的严重变化,还伴有乳腺肿瘤和细胞簇的快速形成。
乳房 X 线检查是早期检测和诊断乳腺癌的有效医学影像工具之一,可降低早期乳腺癌的晚期和致死率。为了检查潜在病变(如肿块、钙化、结构扭曲),放射科医生依靠人类的视觉理解来检测和提取乳房 X 线照片中的所有诊断信息。然而,已证明大约 10% 到 30% 的癌症病例在筛查乳房 X 线照片中被漏掉,这会产生高达 50% 的假阴性率,具体取决于病变类型和乳腺密度 [6]。随着后续随访和诊断期间筛查的增加,已经证明大约 50% 的先前乳房 X 线照片在回顾时有可见的病变 [7]。因此,这让放射科医生怀疑,没有任何类型病变明显迹象的正常先前乳房 X 线照片是否可能含有表明未来出现肿瘤风险的隐藏信息。
CAD 被开发用于定位筛查乳房 X 线摄影中存在的病变可疑区域。CAD 方法通常基于提取图像特征(例如灰度、纹理和形状)以通过简单的机器学习技术识别感兴趣区域 (ROI) 。到目前为止,这些技术尚未降低高假阳性率,也未克服肿瘤形状、大小和纹理的高度变化。
文献中广泛使用的此类模型被认为是卷积神经网络 (CNN) 模型的变体,即 R-CNN、快速 CNN 和更快的 R-CNN 模型 [16]。然而,一种名为 You-Only-LookOnce (YOLO) 的单一模型被建议同时进行检测和分类任务,具有低内存依赖性和快速结果,这使其便于 CAD 应用 [17, 18]。
首先提出使用基于 YOLO 的模型,同时检测当前乳房 X 光检查中的异常病变并将其分类为肿块、钙化或结构扭曲。其次,研究了训练后的模型在先前乳房 X 光检查中定位和标记异常区域的潜在性能,这些区域被报告为正常,但后来在后续筛查中被诊断为异常。
为此,我们的方法使用图像到图像的转换技术,在第一阶段学习乳房 X 光检查对之间的图像映射,从而生成转换后的先前乳房 X 光检查以克服筛查之间的错位,在第二阶段,预测未来病变在早期筛查中出现的位置和性质。
2. 背景
许多研究表明 CAD 系统能够有效地从原始筛查乳房 X 线照片中自动检测可疑病变。神经网络模型的引入改变了 CAD 的方法,用能够学习不同尺度复杂特征的深度学习架构取代了手工提取特征。
最近的研究尝试使用不同的神经网络开发 CAD 模型来快速准确地定位现有病变。Ribli 等人[23] 开发了一种 CAD 系统,使用 Faster R-CNN 模型检测 INbreast 数据集的乳腺病变并将其分类为恶性或良性,并获得 0.95 的 AUC 评分。同样地,Peng 等人[24] 提出了一种结合 Faster R-CNN 架构和多尺度特征金字塔网络的自动肿块检测方法。该研究在 CBIS-DDSM 和 INbreast 数据集上分别取得了 0.93 和 0.95 的真阳性率。该研究在 DDSM 数据集上的检测准确率高达 90%,分类准确率达到 93.5%。在 Li 等人[25] 的另一项研究中,他们使用两个网络介绍了一种双侧肿块检测方法:左右乳房之间的配准网络和 Siamese-Faster-RCNN 网络,用于从已配准的乳房 X 光片对中检测肿块。报告的结果显示,在 INbreast 数据集上的真实阳性率为 0.88,在私有数据集上的真实阳性率为 0.85。Vivek 等人的另一项尝试 [26] 使用了 [27] 中提出的单次检测器 (SSD) 模型,首先定位乳腺肿瘤,然后分割和分类感兴趣的区域。这项工作在 INbreast 数据集上实现了 0.97 的真实阳性率。
随着用于乳房 X 线摄影中物体检测的深度学习架构的进步,YOLO(You-Only-Look-Once)模型已被引入,与最先进的方法相比,它在实现快速准确的检测和分类方面表现出色。Al-masni 等人 [28] 使用基于 YOLO 的模型开发了一个 CAD 系统,在 DDSM 数据集上实现了 85.52% 的检测准确率。此外,Hamed 等人 [29] 提出了一种基于 YOLOV4 的 CAD 系统,可以对完整和裁剪的乳房 X 线摄影中的肿块进行双路径检测,然后将其分类为良性和恶性。该系统的总体检测率为 98%,分类准确率为 95%。在同一背景下,Al-masni 等人 [30] 提出了一个 CAD 系统框架,该系统使用基于 YOLO 的模型在完整图像中检测乳房肿块,总体准确率为 99.7%。因此,Baccouche 等人 [31] 最近提出了一种基于 YOLO 的融合模型来检测乳腺病变并将其分类为肿块或钙化。该工作在 INbreast 数据集上实现了 98.1% 的检测准确率,在 CBIS-DDSM 数据集上实现了 95.7% 的检测准确率
使用基于深度学习的 CAD 系统在乳房 X 线摄影中对乳腺癌进行早期检测和诊断可以通过标记病变来帮助预防肿瘤的发展,从而有效降低死亡率。Timp 等人 [34] 最近的一项研究试图通过添加有关肿瘤随时间变化的行为信息来改善肿块病变的表征。使用区域配准方法检测两个连续筛查图像之间的时间变化,以便定位在当前视图上检测到的病变及其在先前视图上的对应病变。之后,应用支持向量机 (SVM) 分类器来显示时间特征的有效性。
另一项研究中,Timp 等人 [35] 尝试通过在 CAD 系统中加入时间信息来改进检测方法。采用沿特征空间的区域配准技术将当前乳房 X 光检查上的可疑位置与先前乳房 X 光检查上的相应位置进行映射,准确率为 72%。因此,Loizidou 等人 [36] 尝试在应用 SVM 分类器之前在乳房 X 光检查对之间添加时间减法,将微钙化检测准确率提高到 99.2%。Loizidou 等人 [37] 最近的一项研究扩展了他们之前的乳腺微分类检测和分类工作,在应用对的时间减法之前添加了先前乳房 X 光检查的图像配准步骤。在 Zheng 等人的另一项工作中,将后续数字乳房 X 光检查图像整合在一起,开发了一种用于乳腺癌检测的 CAD 方法。所有区域图像均通过 AdaBoost 方法使用 Haar 特征、局部二值模式和方向梯度直方图进行检测,然后输入 CNN 以滤除误报情况。
随着深度卷积神经网络的出现,图像到图像的转换(主要是图像的合成和重建)已用于解决医学成像中的许多计算机视觉应用。基于两种基本架构,称为 Pix2Pix 和 CycleGAN,具体取决于图像的数据形式、成对或非成对的数据集。
Shen 等人 [40] 最近的一项应用使用 Pix2Pix 网络进行乳房 X 线摄影中的图像到掩模分割。Liao 等人 [41] 还使用 Pix2pix 来人工去除 CT 扫描中的伪影,该方法在临床图像重建方面显示出改进。此外,Modanwal 等人 [42] 成功使用 CycleGAN 重建和协调乳腺癌的 MRI 图像,而无需成对对齐的图像。Baccouche 等人 [43] 的一项研究采用了 CycleGAN 的有效性,他们尝试使用 CycleGAN 模型在两个不成对的乳房 X 线摄影数据集之间生成合成图像来增强乳房 X 线摄影数据。Hammami 等人 [44] 的一项研究也通过结合 CycleGAN 和 YOLO 增强了多器官检测性能。
首先尝试使用基于 YOLO 的融合模型解决在最近的筛查乳房 X 光检查中检测和分类三种类型的乳腺病变(即肿块、钙化、结构扭曲)的任务。其次,建议复制早期筛查的乳房 X 光检查,诊断结果健康,并保持先前的形状和外观,同时预测与当前乳房 X 光检查相似的可疑发现。评估了两种最先进的图像到图像转换技术 CycleGAN 和 Pix2Pix,并比较了它们在早期筛查时预测先前乳房 X 光检查中病变位置和类型的性能。
3. 方法和材料
3.1 基于 YOLO 的融合模型:概述
YOLO 是一种深度学习网络,其中单个卷积神经网络 (CNN) 架构模型可同时定位物体的边界框并从整个图像中对其类别标签进行分类。基于 YOLO 的模型已有四个版本,在我们最近的研究发表时,最新版本是 YOLO-V3,它被用于使用 DarkNet 主干框架检测不同比例的物体。
基本模型最初使用不同的配置(即目标类别标签)进行训练。 然后,通过在所有增强图像(即原始图像和旋转图像)中选择具有最高置信度得分的最佳预测边界框来评估每个实验。事实证明,该技术可以精确检测和分类每个乳房 X 光检查中的乳腺病变。之后,如下图所示,实施了基于 YOLO 的融合模型的理念,以改善最终预测结果。将不同的预测结合起来以降低最终错误率并结合不同配置的模型。在这项工作中,使用相同的符号,将模型 1 经过训练并配置为一个类,即肿块、钙化或结构扭曲。因此,模型 2 配置为多个类训练(即所有三个类一起)。最后,融合模型是指对模型1和模型2进行综合评估,以提高整体的检测性能。最终的模型选择阈值为0.5。
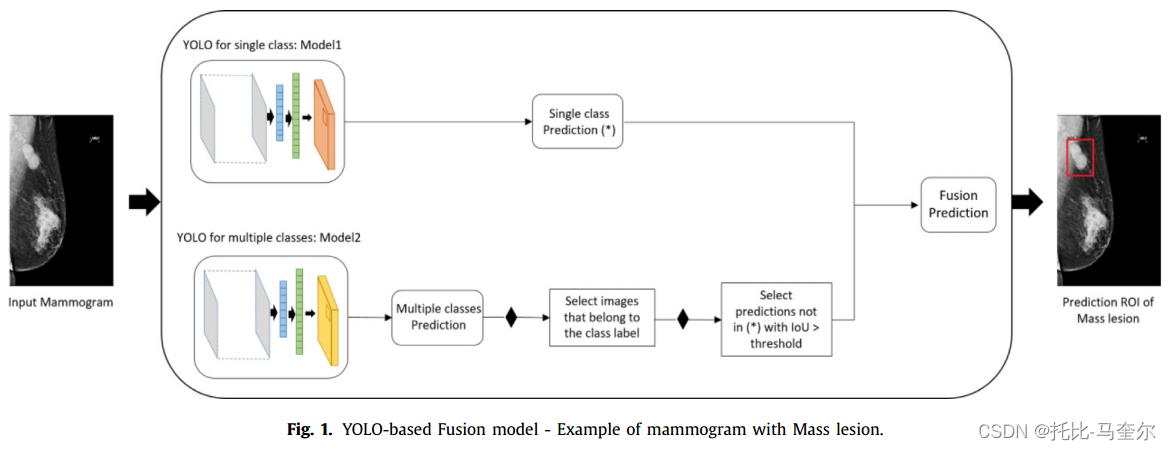
所有模型都是在当前最新的乳房X光图像上进行开发和测试的。这些图像要么显示了肿块(Mass)、钙化(Calcification)或结构扭曲(Architectural Distortion)等病变。与之前的工作不同,这次为当前最新的乳房X光图像添加了一个类别标签:“Normal”。这个标签用于标记在后续筛查中未被诊断为异常发现的乳房X光图像。
训练一个基于YOLO(You Only Look Once,一种实时目标检测算法)的模型来识别异常的乳房X光图像。然后,将这个训练好的模型应用到了标记为“Normal”的乳房X光图像上。当将YOLO模型应用于 “Normal” 乳房X光图像时,确保模型不会预测任何边界框(bounding boxes)。意味着模型不会在这些看似正常的图像上检测到任何潜在的病变区域。由于模型在“Normal”乳房X光图像上没有预测到任何边界框,因此他们将这些图像分类为“Normal”。利用了YOLO模型的目标检测能力来间接地进行分类。
3.2 图像到图像的转换技术
能够处理图像以完成与图像相关的复杂任务,例如图像合成、图像重建、图像转换等。由于生成对抗网络 (GAN) 的发现,这些任务得到了显著处理。
标准 GAN 包含两个模型,一个生成器和一个鉴别器。这些模型相互竞争,以生成足够逼真的虚假数据来欺骗鉴别器。该架构在医学成像应用中取得了成功,并且引入了许多变体,例如条件 GAN (cGAN)、Wasserstein 生成对抗网络 (WGAN) 等。
进一步的工作扩展了这个想法,创建了多个 GAN,可用于合成数据增强、领域自适应和风格转换。 允许使用一对生成器来学习图像的映射,使用一对鉴别器来学习两种不同类型的图像。这个想法强调了图像到图像的转换,利用外部标记数据集有效地重建源域图像,并附加目标域的附加特征,例如像素、颜色分布、形状和纹理。
Pix2Pix 和 CycleGAN 是两种常见的模型,它们被开发用于应用图像到图像的转换技术。如下图所示,与标准 GAN 类似,这两个模型的目标是在两个域之间转换图像,但不同之处在于 Pix2Pix 模型适用于配对数据集,但只接受来自源域 (A) 的一张图像,使用来自目标域 (B) 的相应图像来校正和更新训练。不同的是,CycleGAN 模型适用于不成对的数据集,接受两张图像,并跨域执行循环转换以返回新的合成图像。
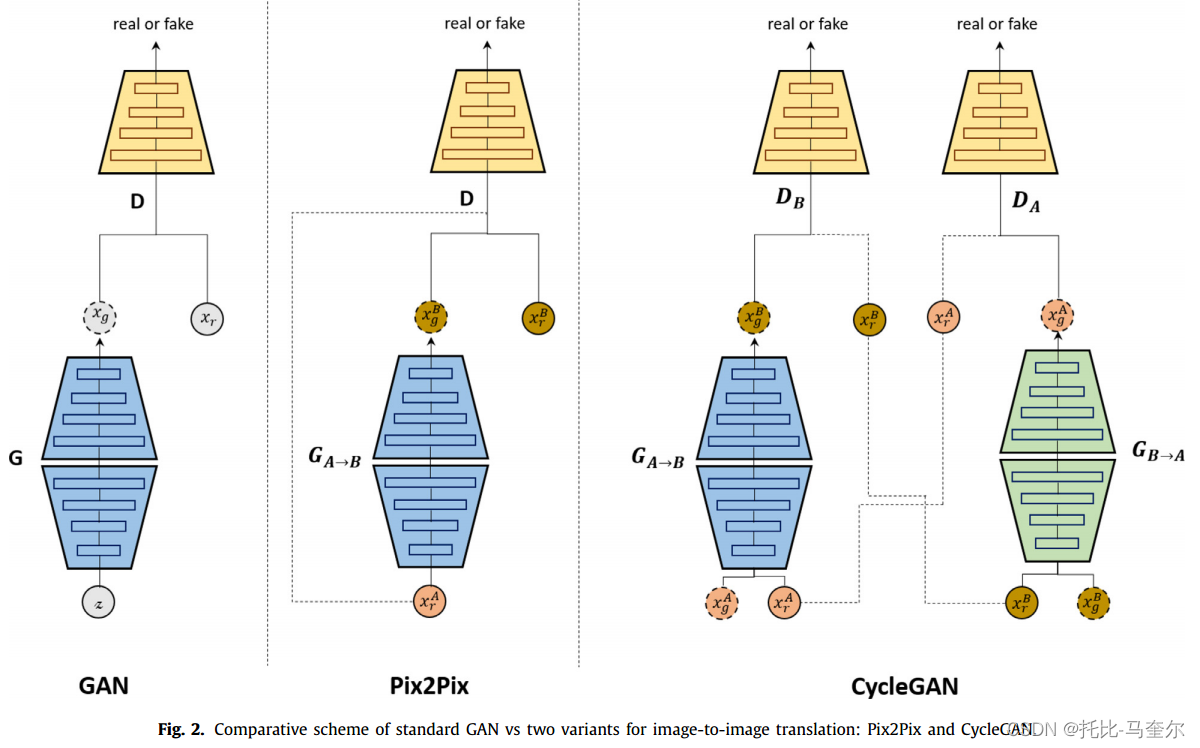
Pix2Pix 基于条件 GAN(cGAN)架构来学习图像之间的映射,其中网络由生成器 和鉴别器 D 组成。生成器具有编码器-解码器结构,尝试迁移输入图像
的特殊特征以获得输出图像
。鉴别器使用 PatchGAN 架构,它一次将输入图像与生成的图像进行比较,另一次将输入图像与外部数据集
中的相应图像进行比较,以更新生成器学习。
循环生成对抗网络(称为 CycleGAN [47])旨在学习图像之间的映射,而无需相关性和一对一匹配。想法建立在 Pix2Pix 架构之上,但使用两个生成器 和
进行循环图像映射,并使用两个鉴别器
和
来区分真实图像和合成图像。此外,CycleGAN 技术对生成器采用循环一致性,以确保将新图像很好地重建回其原始外观。
3.3 早期检测和分类框架
首先在当前的乳房 X 光照片上应用并评估 YOLO 技术,以检测不同的乳腺病变并将其分为肿块、钙化或结构扭曲,其余为正常。其次,考虑两种图像到图像技术 Pix2Pix 和 CycleGAN,以学习当前乳房 X 光照片与其对应的先前乳房 X 光照片之间的映射。如下图所示,生成新的合成先前乳房 X 光照片以克服由于时间和纹理变化导致的筛查之间的错位。
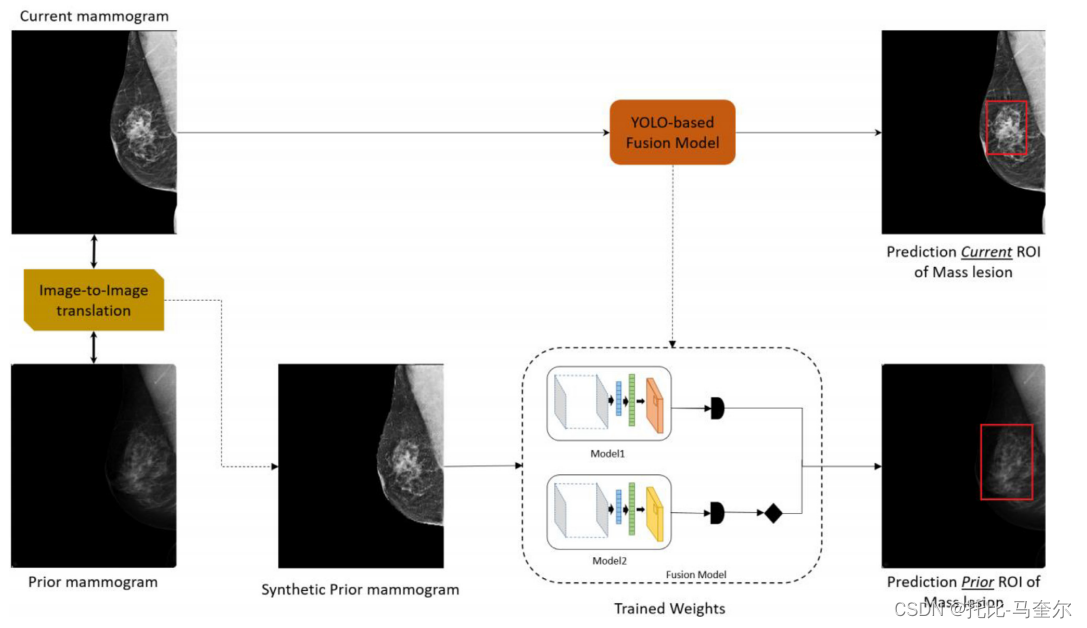
接下来,使用第一步训练的模型来预测平移后的先前乳房 X 光照片上乳房病变的位置和类型。预测先前乳房 X 光照片中“未来癌症”可疑病变的边界框具有挑战性。因此,将所有诊断信息整合到一个框架中,该框架探索可能表明“未来癌症”风险的隐形模式证据。推理模型直接应用于翻译后的先前乳房 X 光照片,并使用 真实边界框的位置 及其 对应的当前乳房 X 光照片的类标签 进行评估。
4. 结果
4.1 数据集
在本研究中,我们使用了康涅狄格大学中心 (UCHC) 的一组私人数据集,名为 UCHC DigiMammo (UCHCDM) 数据库。该数据集包含 230 名患者的筛查乳房 X 线照片,其中每个病例都有一次初步筛查,称为先前检查,以及 1 至 6 年之间的第二次随访筛查,称为当前检查。
数据集中的每次筛查都会获取两个不同的视图,即 CC 和 MLO。所有图像均以医学数字成像和通信 (DICOM) 格式保存,由专业放射科医生在描述文本文件中注释,并附上乳房 X 线检查发现的相应病理(即肿块、钙化、结构扭曲、正常)。总共考虑了 413 张乳房 X 线照片,分别用于当前检查和先前检查,它们的平均尺寸为 2950 × 3650 像素。
4.2 数据准备
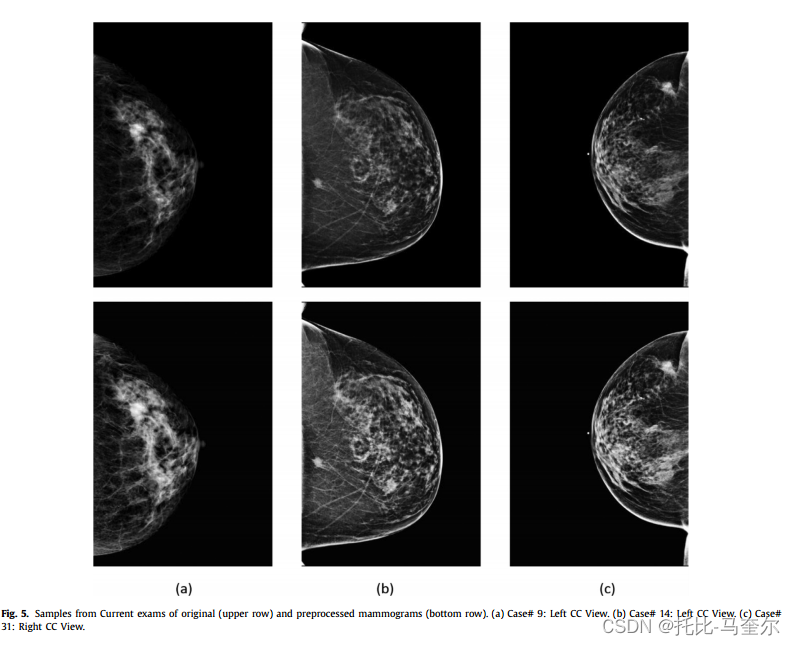
所有乳房 X 光检查图像均使用数字 X 射线乳房 X 光检查工具收集,以 DICOM 格式压缩和存储图像。因此,在训练过程之前对所有原始图像应用了一些预处理步骤,使用去噪和直方图均衡方法以提高质量。由于原始 DICOM 图像尺寸较大,所有乳房 X 光检查图像均使用 4×4 邻域的双三次插值进行下采样。在实验中,使用的图像大小为 448×448 像素(即根据 YOLO-V3 的 DarkNet 主干架构可以被 32 整除)。最后,所有训练图像都被归一化以使强度值在 [0, 1] 范围内。原始图像和预处理图像的样本如下图所示。
具体来说,输入图像的宽度和高度都应该是32的整数倍。这是因为 DarkNet 在进行特征提取和降采样时,会使用步长为32的卷积或池化操作,以确保特征图的大小与网络架构兼容。
由于很难收集和标记医学图像,医学数据集缺乏带注释的图像。为了解决这个问题,主要提出了数据增强技术,通过旋转或翻转实例来增加数据集的大小。本文中,将原始图像旋转了四次,角度为。因此,为 UCHCDM 数据集生成了总共 1,652 张乳房 X 光照片来训练和测试模型。每个类别的原始样本如下图所示。

4.3 评估指标和实验设置
在研究中,使用对象检测和分类指标来衡量基于 YOLO 的模型的性能。为了评估乳房病变在乳房 X 光检查中的位置及其类型的检测,首先测量每个检测到的框与其对应的地面真相(即 (x, y, h, w) 坐标和类标签)之间的交并比 (IoU) 分数,然后验证它是否超过置信度分数阈值 0.35。
IoU 分数公式:
之后报告了一个最终的客观指标,称为检测准确率,考虑了真实检测框的预测类别概率。受 Samuelson 等人[49] 的工作启发,计算病变类型(即肿块、钙化、结构扭曲)和正常图像中真实检测到的图像数量与使用的乳房 X 线照片总数,如下面的公式中定义。
仅考虑置信度概率分数等于或大于置信度分数阈值的预测框。整体测量了检测准确率,并分别测量了每个类别标签的检测准确率,以评估基于 YOLO 的模型的性能。
使用 CycleGAN 和 Pix2Pix 模型进行的图像到图像技术实验在非配对和配对数据集图像上进行了相应的训练。CycleGAN 架构模型有两个生成器和两个鉴别器网络。 生成器网络由两个滤波器大小为 [128, 256] 的下采样块、九个滤波器大小为 256 的残差块和两个滤波器大小为 [128, 64] 的上采样块组成。鉴别器网络基于四个滤波器大小为 [64, 128, 256, 512] 的下采样块。
对于 Pix2Pix 模型,同样使用了两个生成器和两个鉴别器网络。生成器网络包含 7 个下采样和上采样块,滤波器大小为 [64、128、256、512、512、512、512]。使用了 CycleGAN 架构模型中的相同鉴别器网络。因此,这两个模型在 100 个时期内进行了训练和评估,并使用 Adam 技术进行了优化,学习率为 0.0002,beta 分数为 0.5。
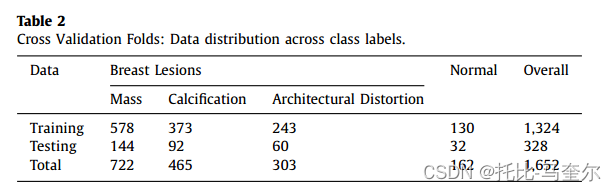
为了确保模型的稳健性,通过使用不同的随机乳房 X 光检查测试集对模型进行训练和测试,进行了 5 倍交叉验证。因此,整个数据集被随机分成 5 份,每份为 1,324 张训练图像(80%)和 328 张测试图像(20%),具体不平衡类别如表 2 所示。最后,我们报告了所有结果的平均值。
将学习率设置为 0.001,批次大小设置为 8,周期数设置为 100。损失函数结合了边界框回归损失、类标签损失和置信度损失。 所有函数都基于交叉熵,并进行了缩放以处理每个批次上的类标签不平衡。
在损失函数值恒定的情况下,在迭代的后半部分使用提前停止方法,每 10 个周期动态降低 10% 的学习率。为了防止过度拟合,所有模型都由大型公共数据集 Microsoft COCO 上的预训练模型的权重初始化。然后,重新训练模型,并在乳房 X 线摄影数据集上微调新的层。因此,我们只监控了损失函数的学习曲线,该损失函数在周期内迭代下降和优化。如下图 7 所示,在学习过程中没有观察到过度拟合。
4.4 基于 YOLO 的模型对当前乳房 X 光检查结果的评估
基于 YOLO 的模型在 UCHCDM 数据集的当前视图上进行了不同的训练。根据输入数据集和目标类别改变模型。因此,模型 1 配置为单个类别,模型 2 配置为混合类别。最后,根据 [31] 中描述的方法,指定融合模型将模型 1 和模型 2 结合到每个目标类别中。表 3 显示了使用 5 倍交叉验证报告的检测准确率和计数的定量比较,即 μ ± σ,其中 μ 和 σ 分别指平均值和标准差。
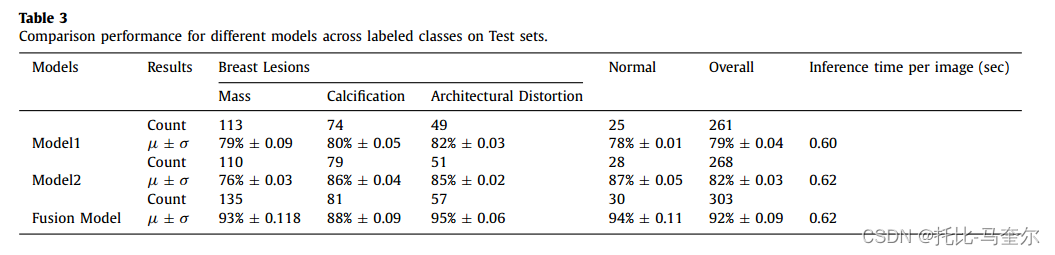
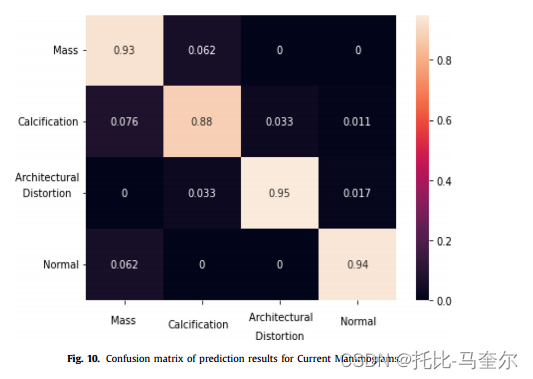
融合模型在结构扭曲病变方面的得分最高,为 95%,总体得分为 92%。此外,表 3 中的结果显示了 YOLO 架构检测和分类乳腺病变的能力,对于有肿块病变的乳房 X 线照片,最大准确率为 93%,对于有钙化病变的乳房 X 线照片,最大准确率为 88%,对于有结构扭曲病变的乳房 X 线照片,最大准确率为 95%。 恰当地说,正常乳房 X 线照片也被正确分类,最大准确率为 94%,没有检测到边界框。所有实验的推理时间都相似,每张图像的最大值为 0.62 秒。
此外,为了更好地了解模型的性能,生成了自由响应接收者操作特性 (FROC) 曲线,以说明每个目标类别标签的每幅图像 (FPI) 的假阳性数量。下图显示了平均敏感度和平均假阳性数量之间的 FROC 图,具体比较了模型 1、模型 2 和融合模型。

通过改变阈值和总体上在 0.05 和 0.20 之间的假阳性范围,可以为所有病例实现 0.7 到 0.95 之间的平均敏感度。上图清楚地表明,与其他评估模型相比,Fusion 模型具有最高的性能。观察到,所提出的模型对于肿块病变可以获得超过 0.90 的平均敏感度,平均 FPI 为 0.20,对于钙化病变可以获得超过 0.85 的平均敏感度,平均 FPI 为 0.12,对于结构扭曲病变可以获得超过 0.90 的平均敏感度,平均 FPI 为 0.175。因此,使用 FROC 分析评估当前视图中的正常病例,并且当非癌性病例中不应出现检测但模型遗漏时,则考虑假阳性。值得注意的是,可以获得约 0.95 的平均敏感度,平均 FPI 为 0.20。
下表 探讨了按每个类别标签计算出的分类指标,其中我们对具有结构扭曲的癌症病例实现了最高灵敏度 94.11%,对非癌症病例实现了最高灵敏度 92.09%。
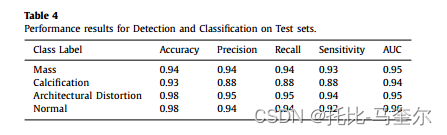
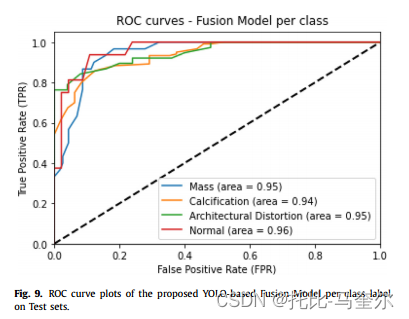
下图直观地比较了不同病例之间根据 ROC 曲线图得出的假阳性率 (FPR) 和真阳性率 (TPR) 之间的权衡。 观察到肿块和结构扭曲病例的 AUC 得分最高,为 0.95,正常病例的 AUC 得分为 0.96。钙化病变的低结果可以解释为这种类型的乳腺病变没有标准的形状和位置,而且它们通常很小且随机分布,这会限制自动检测。
下图说明了当前乳房 X 光片上应用的真实检测到的边界框分类的混淆矩阵,其中三种类型的病变与正常情况一起呈现(即没有检测到病变的正确预测)。显然,不同类别的预测误差较低,其中对应于正常类别标签的预测误差较高,为 6.2%,对应于钙化情况的预测误差较高,为 7.6%。类别内误差的分布可以通过基于 YOLO 的模型无法检测和区分具有相似形状的某些不同类型的病变来解释,例如钙化和结构扭曲,它们通常在乳房内具有挑战性的位置具有不规则的形状。
4.5 基于 YOLO 的模型在乳房 X 光检查结果上的评估
研究的第二部分集中在使用成对的乳房X光图像上,包括当前图像和先前的筛查图像。其目标是对先前的筛查图像中的病变进行早期检测和分类。所有先前的乳房X光图像都没有经过诊断标注,因此被视为正常(即非癌症)。这些图像对应的标注是0。
回顾性方法:回顾先前的乳房X光图像,试图在等待后续筛查之前探索乳房病变的任何模式。
通过连接当前乳房X光图像和经过专家标注的训练模型之间的学习映射。首先,准备成对的数据集,并使用相同的配置。然后,训练两个图像到图像的转换模型来确定图像之间的映射。基于这种映射,生成与当前乳房X光图像相似的先前筛查图像的合成图像,同时保留先前图像的一般纹理。
使用先前在当前乳房X光图像上训练和验证过的基于YOLO的模型进行推理,对先前的乳房X光图像进行分类。
实验评估:首先,使用原始先前的乳房X光图像(未经图像到图像的转换)进行性能评估,然后与使用 CycleGAN 和 Pix2Pix 技术转换的先前图像进行比较。通过5折交叉验证报告先前乳房X光图像的早期预测结果,结果以平均值和标准差的形式给出。当位置和类型的乳腺病变使用推理模型在t=0年的非癌症筛查图像上被正确捕获时,认为这是一个真实的预测。
所有真实预测都呈现两种情况:一种情况是当前乳房 X 光检查和第一次检查(即 t=0)的相应先前视图的所有预测都正确,另一种情况是仅对先前乳房 X 光检查进行正确预测,即使其相应的当前视图未被正确预测。
错误预测率,即推理模型在先前视图上错过的病例数量。这可能是因为模型没有在先前视图上进行训练,即被专家标注为t=0时的正常图像。
4.6 早期发现和分类的回顾性分析
具体来说,肿块病变是事先预测到的,但后来被专家和放射科医生在 2 到 3.5 年内发现。对比图还表示使用图像到图像转换技术与原始乳房 X 线照片的结果的最新随访检查时间。 此外,下图展示了基于 YOLO 的模型在不同类别和整体上有无图像到图像转换的推理结果的比较。可以直观地得出结论,与使用非配对图像的 CycleGAN 模型相比,Pix2Pix 转换方法总体上具有最佳性能,也可以通过 Pix2Pix 模型是在配对图像之间训练的事实来解释。因此,考虑到在配对数据集之间呈现的图像对齐优势,Pix2Pix 模型对于图像到图像转换这一特定任务比 CycleGAN 更有效。
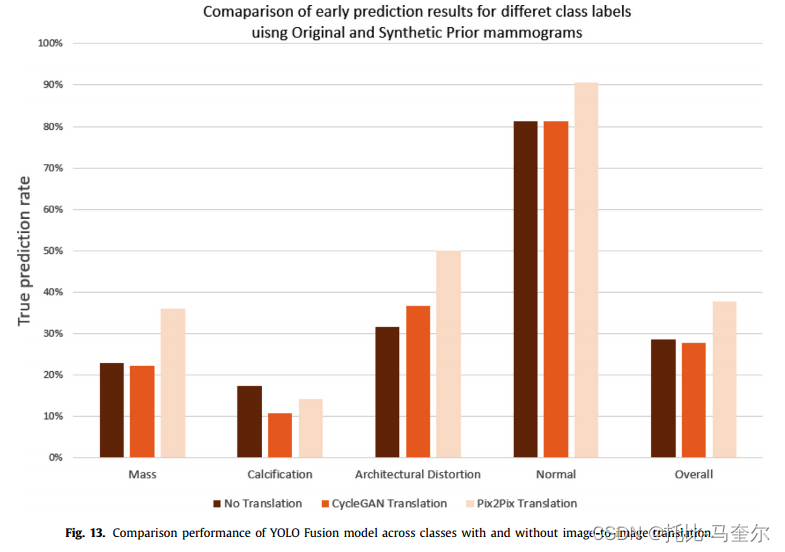
可以通过不同类型乳腺病变在形状、大小和质地方面的差异来解释。众所周知,钙化不会出现在标准的形状和位置,它们可以是双侧的、厚的、聚集的、多形性的和血管性的等等。由于它们的大小和位置不规则,使用图像到图像合成复制此类异常无助于在先前视图中检测和识别钙化病变。钙化通常很小且聚集在一起,需要平滑的像素分布,但是 X 射线图像可能会降级,并且在早期状态下很难识别乳房钙化。 此外,比较了 1 至 6 年之间变化的 Prior 检查时间内的早期检测和分类结果。下图使用最佳报告实验(即使用 Pix2Pix 转换)提供了对每个类别标签正确预测的 Prior 乳房 X 线照片百分比的视觉观察。 很明显,1 年的随访检查时间具有最高的预测图像率。强调了我们的方法在早期定位和识别通常被认为最难诊断的病变方面的成功。另一个观察结果是,我们的方法捕获了 3 年以后才要求随访的肿块病变,这可能对诊断患有肿块性乳腺病变的患者来说为时已晚。

5. 讨论和结论
提出使用 YOLO 架构模型来检测和分类乳房 X 光检查中的可疑病变。 根据最近的工作,展示了使用基于 YOLO 的融合模型来正确定位和识别三种不同类型的病变的优势:肿块、钙化和结构扭曲。此外,进一步开发了所提出的框架,以整合所有使用的后续筛查中的先前乳房 X 光检查,并对初始筛查的乳房 X 光检查进行早期检测和分类。这项工作强调了对先前诊断为正常但在后期报告有明显异常发现和进展的乳房 X 光检查进行回顾性预测的能力。 类似的方法解决了这个问题,并使用乳房 X 光检查对来增强 CAD 系统对当前乳房 X 光检查的结果,方法是包括区域配准的时间特征 [35],或在 SVM 分类器 [36] 或 CNN 模型 [37] 中添加配对之间的时间减法。然而,我们的研究只采用了一个模型,该模型在当前视图上进行训练和测试,然后在其对应的先前视图上进行推断。通过将保存的基于 YOLO 的融合模型以不同的方式直接应用于使用图像到图像转换技术生成的原始和合成先前乳房 X 光片上,强调了提出的方法的性能。在乳房 X 光片对(先前、当前)之间训练和验证了两种最先进的模型 CycleGAN 和 Pix2Pix,以创建新的转换先前乳房 X 光片,从而克服由于时间和纹理变化导致两次筛查之间的错位。
这篇关于5.31.15 使用图像到图像转换和 YOLO 技术对先前的乳房 X 光检查结果中的异常进行早期检测和分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




