本文主要是介绍后期需求的数据开发,对于新增指标字段,应该如何应对,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
很多小伙伴在后期业务给到的迭代需求开发中,或者说上线之后,无法满足现有的需求,需要对原本的表新增字段,这个时候应该怎么办呢??
0,需求(新增字段)描述
原需求字段:
| 日期(yyyy-mm-dd) | 产品类型 | 产品代码 | 折算系数 |
| upl_date | prd_type | prd_code | cnvr_coef |
现需求字段:
| 日期(yyyy-mm-dd) | 产品类型 | 产品代码 | 产品名称 | 折算系数 |
| upl_date | prd_type | prd_code | prd_name | cnvr_coef |
现在需要新增一个字段,在产品代码后面。
这个时候,你该如何应对呢???
一,普通迭代需求【字段放最后】
1,错误应对(普通迭代需求)
可能很多小伙伴,甚至绝大部分中级开发工程师,依旧会犯错:他们会直接会写一段sql追加字段到对应的位置。
alter table db_ods.ley_prd add columns (prd_name string comment '产品名称') ;alter table db_ods.ley_prd change column prd_name prd_name string after prd_code cascade ;
以为把字段放在对应的位置,在脚本中补充上其对应的逻辑就万事大吉,
but,这不对,这在工作中是大忌。
1.1,生产数据
为什么呢???因为已经上线的需求,该表是有数据的。
来,咱们验证下我们为什么是错误的。
咱们自己先建个表,然后插入数据,模拟一下上了生产之后的表。

生产结果展示:
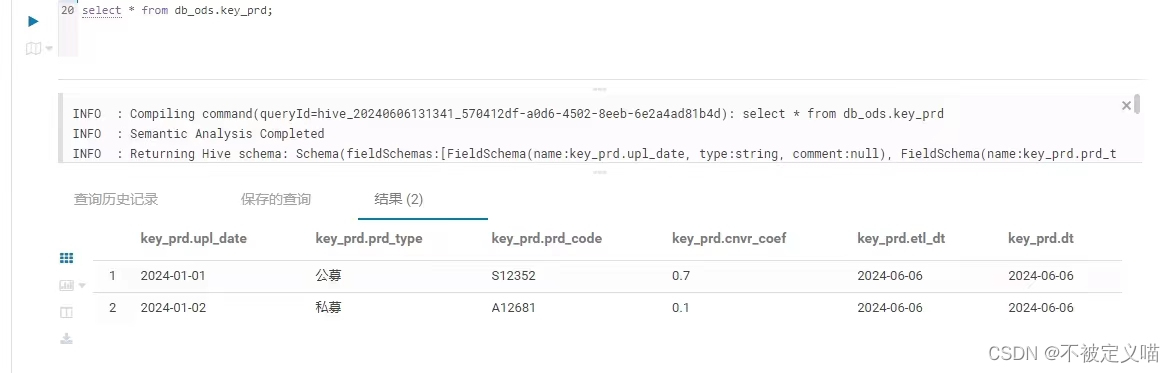
很好,数据如我们写入的一样,没有问题。
1.2,新增字段
但是,这个时候如果你要新增字段:(默认加在最后)

数据展示:
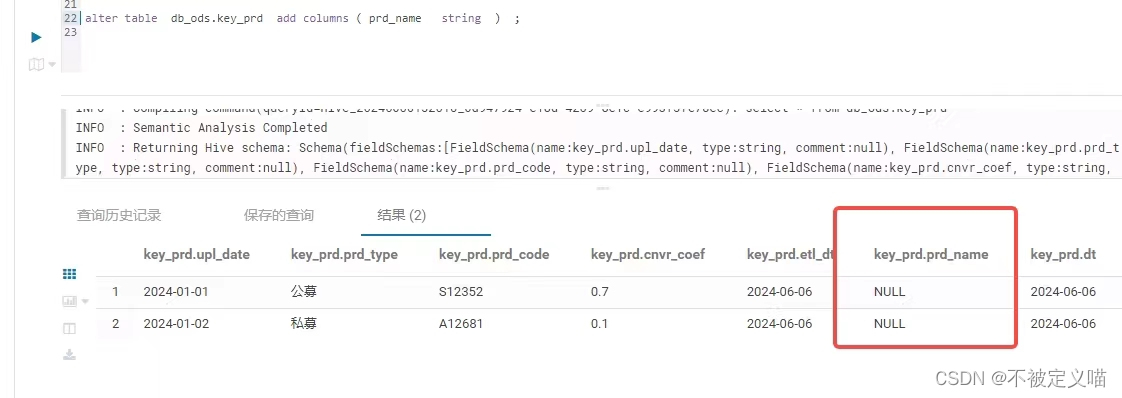
我们发现,表的最后一个新增字段,数据默认显示位NULL。
注意,最后一个字段是分区字段,虽然这么叫,但其实这个是不占内存的,只是HDFS文件命名分区的一个方式。
1.3,指定字段位置
接下来,我们对该字段进行位置的指定:

数据展示:

发现什么了嘛???
数据一直都是这个顺序,数据丝毫没有变化(增加字段,只是在最后展示NULL),
/是,我们的字段名字,prd_name, 我们是没有插入数的,但是其对应的数据是(0.7/0.1),这个是折算系数字段啊,好家伙,字段名称的顺序对了,但是数据却错位了。
无法做到字段名与实际数据,一一对应。这不完蛋嘛???
所以,我们在数据的开发中,绝对不能这么干!!!
我们能做的,就是,把新增字段,加在最后。(有小伙伴说,那这个不符合要求啊。但就应该这样做,做人不能既要又要还要。)
2,正确应对
正确应对,当然是把字段放在表的最后咯,然后按照逻辑进行开发。
当然,大部分需求都会是这样子,这个不涉及的系统的迁移。
二,系统迁移需求【字段放指定位置】
2.1,背景
之前的是普通的迭代需求,和现在讲的系统迁移的需求,有什么不一样呢???
普通的迭代需求:是数据的系统,没有发生变化,也没有业务的异构。
系统迁移需求:是业务发生巨大变化,存在功能异构,数据需要进行迁移升级改造。
2.2,如何处理
思路:就是说,这些表,我们以前的数据我还是要的,需要保留下来,但是因为发生了新的业务需求,涉及系统的升级改造,咱们的表的旧数据,需要迁移的新的系统(表字段有新增),新系统是按照新的业务体系来建造的。
需要把数据备份下来,新建表(字段放在指定位置),然后把备份的数据回插到新的表。
这里大家可以自己整理个思路出来,自己可以解决。下一期,会给大家详细分享。
下一期,给大家具体详细分享核心干货,工作实战,关于系统迁移类的项目,某需求表的字段的新增,删除,变更,需要如何处理。
欢迎一键三连。
这篇关于后期需求的数据开发,对于新增指标字段,应该如何应对的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




