本文主要是介绍数据可视化之常用图表热力图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
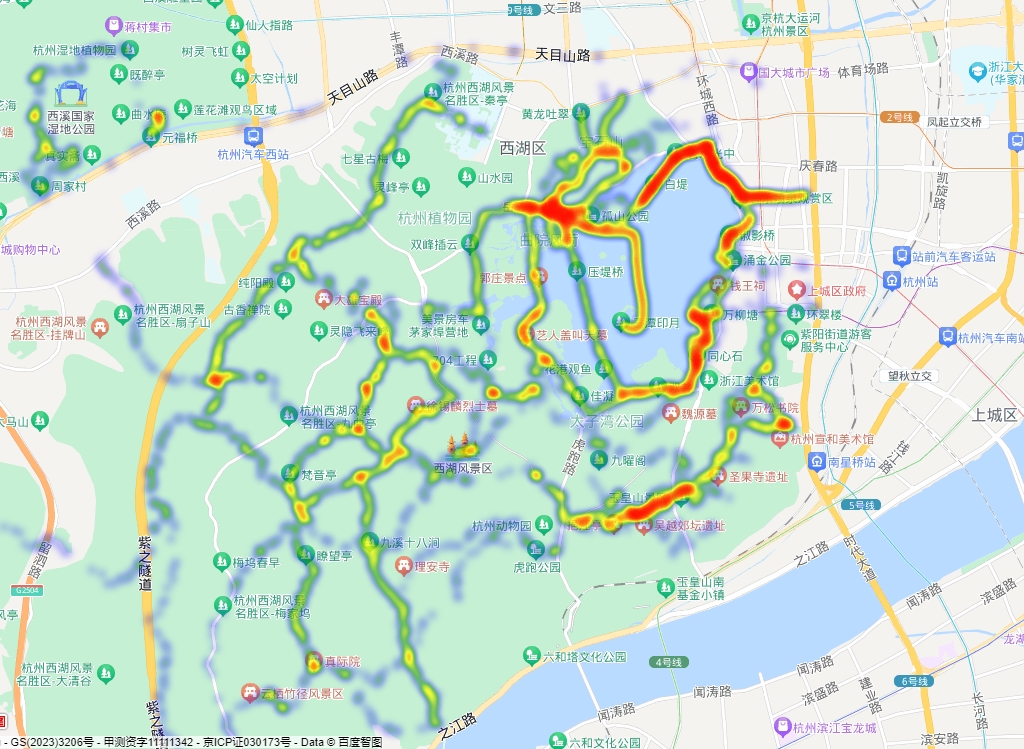
1.什么是热力图?
热力图,是一种通过对色块着色来显示数据的统计图表。 绘图时,需指定颜色映射的规则。
例如,较大的值由较深的颜色表示,较小的值由较浅的颜色表示;较大的值由偏暖的颜色表示,较小的值由较冷的颜色表示,等等。
热力图是数据统计中经常使用的一种数据表示方法,它能够直观地反映数据特征,查看数据总体情况,在诸多领域具有广泛应用。
热力图本质上是一个数值矩阵,图上每一个色块都是一个数值,通过离散数值、权重算法与分析模型等技术手段,将用户行为频度以色块的形式展现出来。
热力图是把用户的交互按照热度渲染出来的一个分析能力,因其丰富的色彩变化和生动饱满的信息表达,被应用在各种数据分析场景。
2.热力图(heatmap) 使用场景?
2.1热力图的优势在于“空间利用率高”,可以容纳较为庞大的数据。 热力图不仅有助于发现数据间的关系、找出极值,也常用于刻画数据的整体样貌,方便在数据集之间进行比较。
2.2如果将某行或某列设置为时间变量,热力图也可用于展示数据随时间的变化。
2.3.热力图的应用场景有:事件分析、页面分析、活跃分析、留存分析、漏斗分析、路径分析等。
3.热力图怎么用?
在热力图中,每个数据点或区域都被赋予一个颜色值,该颜色值反映了该位置上的数据密集程度或数值大小。
一般而言,较高的数值或密集程度会使用较暖的颜色表示如红色,而较低的数值或密集程度会使用较冷的颜色表示如蓝色或者浅蓝色。

其他颜色,如黄色和绿色,则表示中间程度的数值或密集程度。
具体操作步骤如下:
3.1准备好需要展示数据
首先需要准备数据,包括数据点的经度、纬度和权重等信息。可以使用Excel表格或者其他数据源来获取数据。
3.2选择热力图工具
选择适合自己的热力图工具,常见的热力图工具包括百度Echarts、Highcharts、或者是低代码工具如薪火数据等。可以根据自己的需求和技术水平来选择合适的工具。
3.3导入数据
将准备好的数据导入到热力图工具中,通常需要将经度和纬度等信息对应到位置。
3.4设置热力图属性
在热力图工具中,可以设置热力图的属性,包括颜色、透明度、权重等。可以根据数据的分布情况来选择颜色和权重等属性,以达到最佳的可视化效果。
3.5生成热力图
设置好热力图属性后,可以生成热力图并在地图上显示。热力图会根据数据的分布情况和权重等信息,显示出不同颜色和强度的热力图层,以便于我们更好地理解和分析数据。
3.6调整热力图布局
在热力图工具中,可以调整热力图的布局、尺寸和位置等属性。可以根据需要进行调整,以达到最佳的可视化效果。
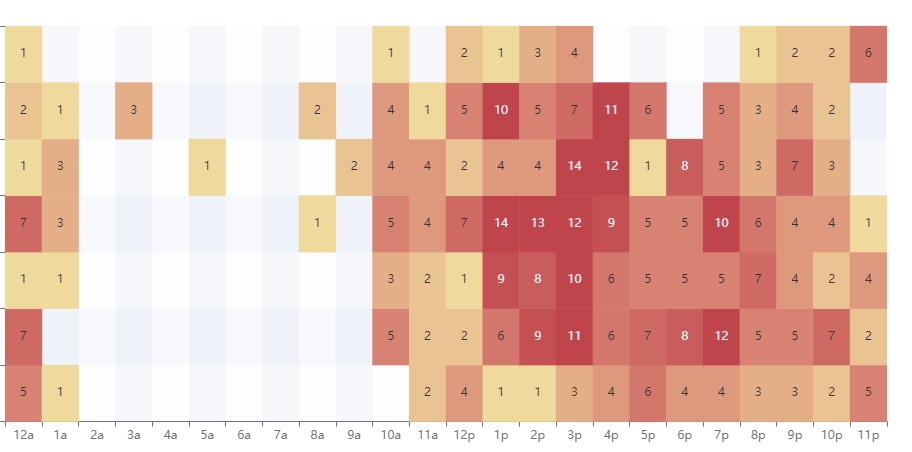
总之,使用热力图需要准备数据、选择热力图工具、导入数据、设置热力图属性、生成热力图和调整布局等步骤。
通过这些步骤,可以制作出具有良好可视化效果的热力图,以帮助我们更好地理解和分析数据。
这篇关于数据可视化之常用图表热力图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





