本文主要是介绍Ivy优化算法-2024年7月SCI一区顶刊新算法!公式原理详解与性能测评 Matlab代码免费获取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
原理简介
一、初始化
二、协调有序的种群增长
三、获得阳光来源生长
四、常青藤植物的传播和进化
五、生存者选择
算法伪代码
性能测评
参考文献
完整代码
Ivy算法是一种新型的元启发式算法(智能优化算法),灵感来源于常青藤的有序协调增长和扩散进化过程。比较有趣的是,这个算法的作者中包括了R.Venkata Rao。如果你不知道他是谁,那么,提到著名的Jaya优化算法、教与学优化算法TLBO,相信你应该就已经知道了,这些经典的算法都是由他提出的!
这位学者已经被引用了1w多次。众所周知,Jaya优化算法的优势就是速度快、参数少,此次提出来的算法也同样具备这两个特点!最重要的是,这个算法也是出版于2024年7月的新算法~非常新颖!
原文作者在26个经典测试函数上与12个工程优化问题上,与其他10种算法进行了比较,证明了其优越的性能。。该成果由Mojtaba Ghasemi等人于2024年7月发表在SCI一区顶刊《Knowledge-Based Systems 》上!


由于发表时间较短,谷歌学术上还无人引用!你先用,你就是创新!

原理简介
灵感:IVY指的是常春藤这种植物,这个算法主要模拟了常春藤的不同生命阶段,包括生长、上升和在常春藤植物群中传播。
一、初始化
在算法开始时,IVY种群在搜索空间中的初始位置是使用Eq.(1)随机确定的。
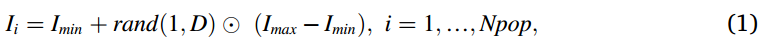
其中,区间[0,1]内均匀分布随机数的维数为D的向量用rand(1,D)表示。Imax和Imin分别是搜索空间的上界和下界,两个向量的Hadamard积(也称为元素积,在Matlab中表示为“.∗”)用运算“⊙”表示。
二、协调有序的种群增长
设Gv为增长率,φ为生长速度,φ为偏离生长的修正系数。在本文提出的算法中,基于数据密集型的实验和仿真过程,将Eq.(2)建模为成员Ii的生长速度Gvi(t)的差分方程。
![]()
其中向量ΔGvi(t)和ΔGvi(t+1)表示离散时间系统(时刻t和时刻t +1)的增长率,rand是区间[0,1]中的随机实数(即rand∈U[0,1]), rand^2是随机变量的随机数,其概率密度函数等于1/(2√x))。N(1, D)表示维数为D的随机向量,为标准高斯(正态)分布中的随机数。
三、获得阳光来源生长
对于自然界中常春藤的整体健康来说,找到一个附着的表面(例如,墙,岩石或树)以便向阳光爬去是至关重要的。在野生森林中,年轻的常春藤可以适当地选择向最近的树生长的方向,而且经常是另一棵已经找到支撑的老常春藤。这样,常春藤就可以逐渐填满大片连续的森林区域。对于森林中的其他树种来说,幸运的是,小常春藤在老常春藤上的攀爬导致了整个小常春藤和老常春藤群体中只有最强壮的存活下来,几乎与它们的年龄无关。

下面的等式描述了成员Ii如何利用成员Iii沿着光源的方向进行攀爬和逻辑移动
![]()
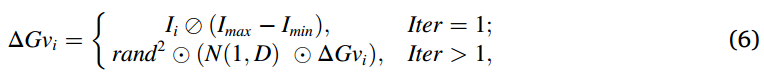
其中|N(1, D)|是矢量,其分量是矢量N(1, D)的分量的绝对值,运算“u⊘v”是矢量u除以矢量v的Hadamard除法(也称为逐元除法,在Matlab中表示为“./”)。
四、常青藤植物的传播和进化
在成员Ii通过搜索空间全局漫游到最近、最重要的邻居Iii的阶段之后,有一个阶段,成员Ii试图直接跟随整个种群的最佳成员IBest,这相当于在成员IBest周围寻找更好的最优解。这个阶段用数学公式表示如下:
![]()
随后,当前成员Inewi的增长率ΔGvnewi的新值由以下公式计算(这与初始化步骤中用于计算ΔGvi的公式完全类似)
![]()
五、生存者选择
Hoflacher和Bauer研究了常青藤植株最年轻和最老(基部)部分在常青藤两个生长阶段交替期间吸收阳光的能力,即“幼叶”形成阶段(典型的快速向上生长阶段)和“成叶”形成阶段(典型的新枝宽度和开花扩张阶段)。
为了模拟常青藤树生命中的两个交替阶段,即“爬升”和“扩张”,在IVY算法中,我们使用了以下决策方法。当成员Ii的目标函数值f(Ii)小于f(Ibest)的倍数时,参数β = (2 + rand)/2。然后,常春藤树开始扩展树枝和叶子的宽度(由式(5)给出)。否则,常春藤向上生长并爬升(由式(7)给出)。
算法伪代码
为了使大家更好地理解,这边给出算法的伪代码,非常清晰!

如果实在看不懂,不用担心,可以看下源代码,再结合上文公式理解就一目了然了!
性能测评
原文在26个经典测试函数上与其他10种算法进行了比较,证明了其优越的性能。此外,作者还求解了12个工程优化问题,并与各种优化算法的结果进行比较,证明了IVYA算法的有效性。
这边为了方便大家对比与理解,采用23个标准测试函数,即CEC2005,并与作者先前提出的Jaya优化算法进行对比!这边展示其中5个测试函数的图,其余十几个测试函数大家可以自行切换尝试!
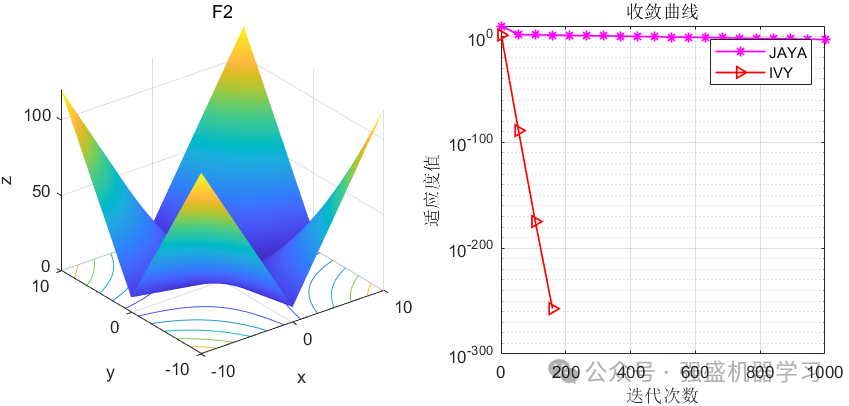
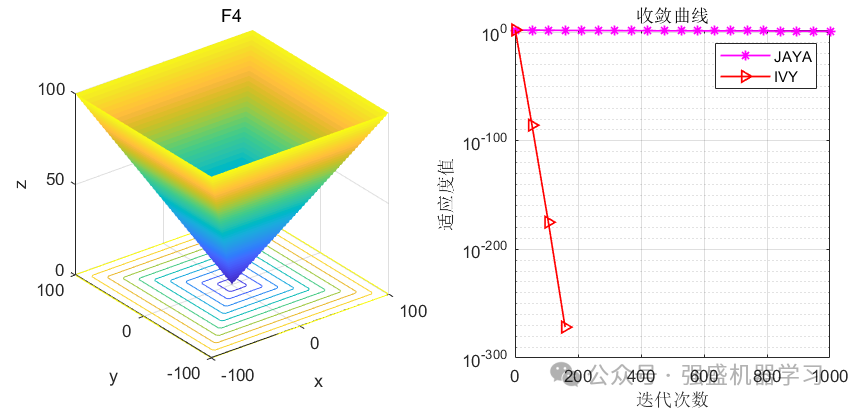
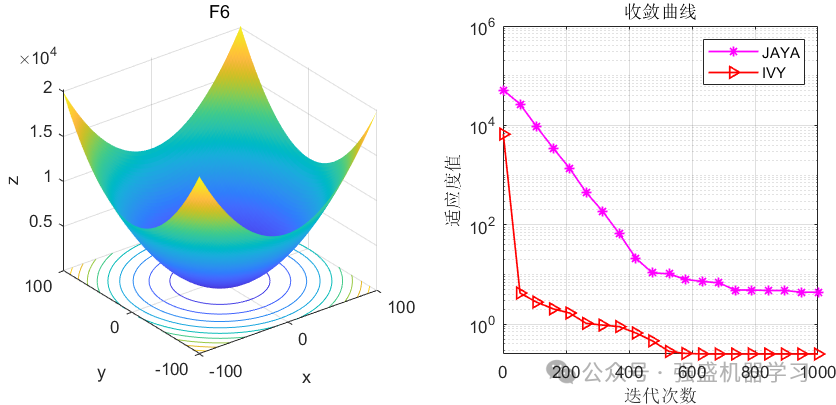
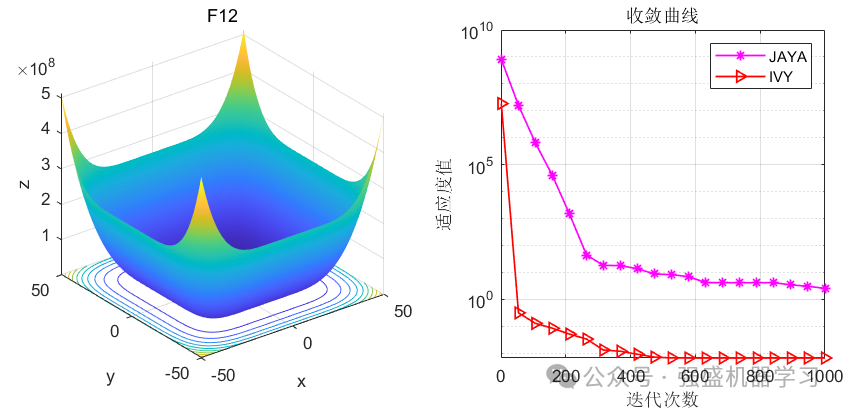
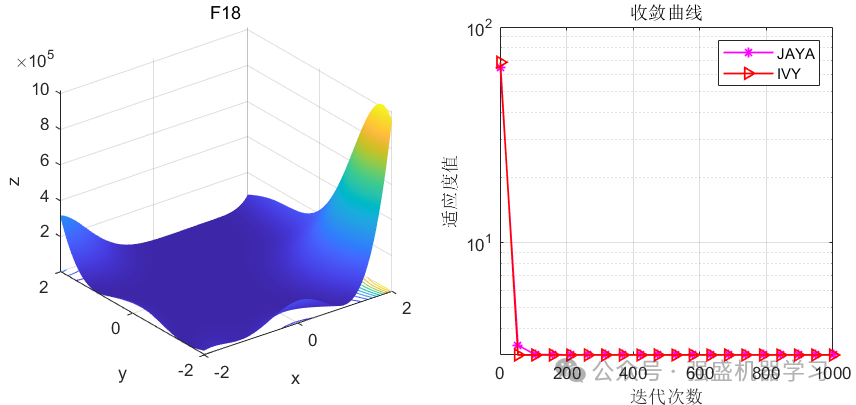
可以看到,IVY在大部分函数上都超过了作者之前提出的Jaya优化算法,尤其在F1-F4函数中,更是收敛极快,没见过这么快就收敛到0的,不知道是不是采取了偏向于0点的搜索策略~当然,大家应用到各类预测、优化问题中也是一个不错的选择~
参考文献
[1]Ghasemi M, Zare M, Trojovský P, et al. Optimization based on the smart behavior of plants with its engineering applications: Ivy algorithm[J]. Knowledge-Based Systems, 2024, 295: 111850.
完整代码
如果需要免费获得图中的完整测试代码,只需后台回复关键字:
IVY
也可后台回复个人需求(比如IVY-TCN)定制以下IVY算法优化模型(看到秒回):
1.回归/时序/分类预测类:SVM、RVM、LSSVM、ELM、KELM、HKELM、DELM、RELM、DHKELM、RF、LSTM、BiLSTM、GRU、BiGRU、PNN、CNN、BP、XGBoost、TCN、BiTCN、ESN等等均可~
2.组合预测类:CNN/TCN/BiTCN/DBN/Adaboost结合SVM、RVM、ELM、LSTM、BiLSTM、GRU、BiGRU、Attention机制类等均可(可任意搭配非常新颖)~
3.分解类:EMD、EEMD、VMD、REMD、FEEMD、TVFEMD、CEEMDAN、ICEEMDAN、SVMD、FMD等分解模型均可~
4.其他:机器人路径规划、无人机三维路径规划、DBSCAN聚类、VRPTW路径优化、微电网优化、无线传感器覆盖优化、故障诊断等等均可~
5.原创改进优化算法(适合需要创新的同学):原创改进2024年的IVY优化算法PKO以及麻雀SSA、蜣螂DBO等任意优化算法均可,保证测试函数效果!
更多免费代码链接:更多免费代码链接
这篇关于Ivy优化算法-2024年7月SCI一区顶刊新算法!公式原理详解与性能测评 Matlab代码免费获取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





