本文主要是介绍通过DirectML和ONNXRuntime运行Phi-3模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
更多精彩内容,欢迎关注我的公众号“ONE生产力”!
上篇我们讲到通过Intel Core Ultra系列处理器内置的NPU加速运行Phi-3模型,有朋友评论说他没有Intel处理器是否有什么办法加速Phi-3模型。通常,使用GPU特别是NVIDA的GPU加速AI模型是最佳的方法,但这年头英伟达的显卡不是一般贵,很多朋友苦于囊中羞涩,还在使用核显中。今天,我们介绍一种使用核显通过DirectML和ONNXRuntime运行Phi-3模型的方法。
相信这两年很多朋友都在使用苏妈极具性价比的APU,今天我将以我手上这颗AMD Ryzen™ 7 7840HS为例展示核显也能用于AI场景。在开始本文前,我们先简单介绍一下DirectML和ONNXRuntime。
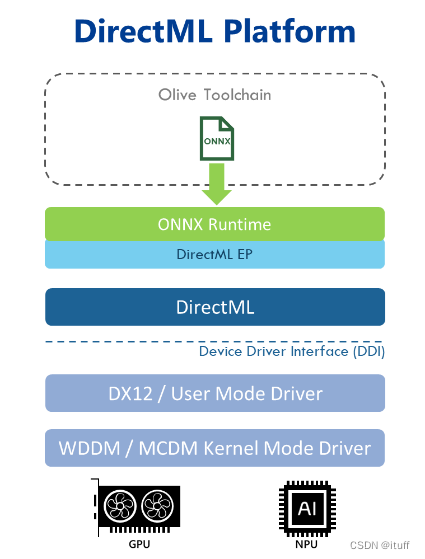
什么是DirectML?
DirectML(Direct Machine Learning)是微软提供的一种高性能、跨平台的机器学习加速库。DirectML的设计理念类似于DirectX在图形处理领域的作用,即通过统一的接口,充分利用底层硬件的计算能力,为开发者提供高效、简便的开发体验。
DirectML支持多种硬件加速,包括GPU和CPU,可以在不同的Windows设备上无缝运行。它基于DirectX 12,因此能够充分利用现代GPU的计算资源,实现深度学习任务的加速。
DirectML的优势
高性能:通过DirectX 12的低级别API调用,DirectML能够充分发挥GPU的计算能力。
跨平台:支持Windows平台的多种硬件设备,包括AMD、NVIDIA和Intel的GPU。
易于集成:提供了与其他深度学习框架(如TensorFlow和PyTorch)的兼容接口,便于在现有项目中集成和使用。
什么是ONNX?
ONNX(Open Neural Network Exchange)是一种开放的神经网络交换格式,旨在促进不同深度学习框架之间的互操作性。ONNX使得模型可以在多个框架之间进行转换和共享,从而避免了平台锁定问题。
ONNX的优势
互操作性:支持主流的深度学习框架,如PyTorch、TensorFlow等。
可移植性:ONNX模型可以在多种硬件加速器上运行,如GPU、CPU、FPGA等。
丰富的工具生态:ONNX有丰富的工具支持,包括模型优化、转换和部署等。
DirectML上的ONNX Runtime
DirectML 执行提供程序是 ONNX 运行时的一个组件,它使用 DirectML 加速 ONNX 模型的推理。DirectML 执行提供程序能够使用商用 GPU 硬件大大缩短模型的评估时间,而不会牺牲广泛的硬件支持或要求安装特定于供应商的扩展。
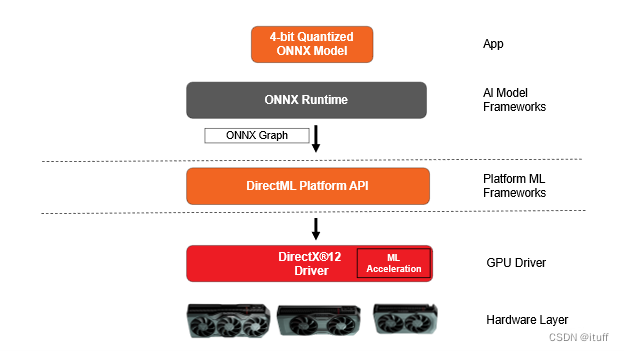
ONNX Runtime在DirectML运行的架构
AMD对LLM的优化
通常我们需要使用独立GPU并配备大量显存在运行LLM,AMD针对CPU继承的核心显卡运行LLM做了大量优化工作,包括利用ROCm平台和MIOpen库来提升深度学习框架的运行效率,通过改进内存分配和数据传输机制来减少内存碎片化和不必要的数据复制,应用量化技术来压缩模型,降低内存需求和计算复杂度,并使用优化的数学计算库(如BLAS和FFT)提高矩阵运算效率。这些优化措施显著减少了内存占用,提高了模型推理速度和能效比,使得在资源有限的核显环境下也能高效运行复杂的深度学习模型。
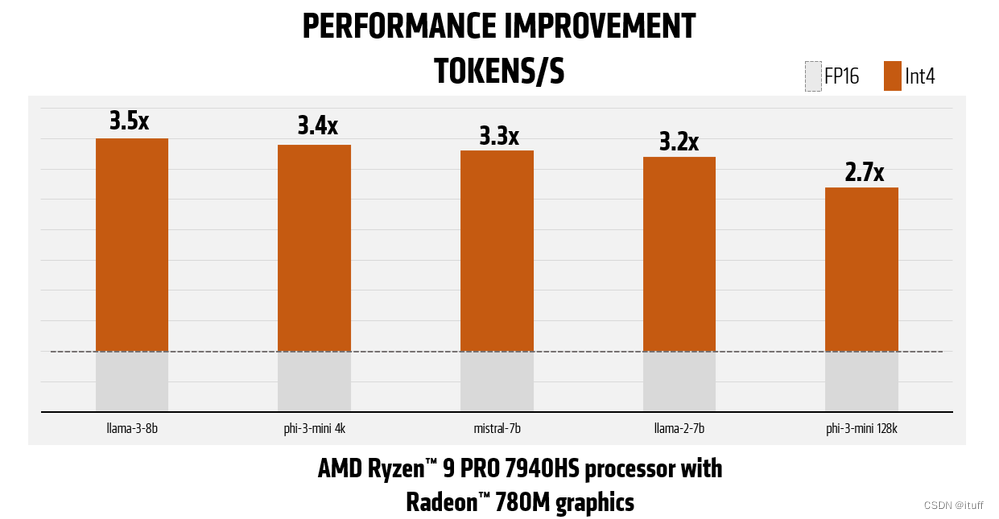
AMD官网展现的Radeon™ 780M核显的LLM加速能力
在Radeon™ 780M上通过DirectML和ONNXRuntime运行Phi-3模型的步骤
环境准备
1、安装Git:确保你的系统上安装了Git,Windows用户可以下载Git for Windows。
2、安装Anaconda:Anaconda是一个流行的Python发行版,用于管理Python环境和包。
3、安装ONNX Runtime:ONNX Runtime是一个跨平台的库,支持ONNX格式的机器学习模型。确保安装了1.18.0或更高版本的onnxruntime_directml。
4、AMD驱动程序:安装AMD Software的预览版本或Adrenalin Edition™ 24.6.1或更新版本。
部署流程
1、获取Phi-3模型:从Hugging Face下载Phi-3模型的ONNX格式文件。
git clone https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-onnx
2、创建并激活Anaconda环境:
conda create --name=llm-int4
conda activate llm-int4
3、安装onnxruntime-genai-directml
pip install numpy onnxruntime-genai-directml
4、准备运行脚本:下载并准备运行模型的Python脚本。
curl -o model-qa.py
https://raw.githubusercontent.com/microsoft/onnxruntime-genai/main/examples/python/model-qa.py
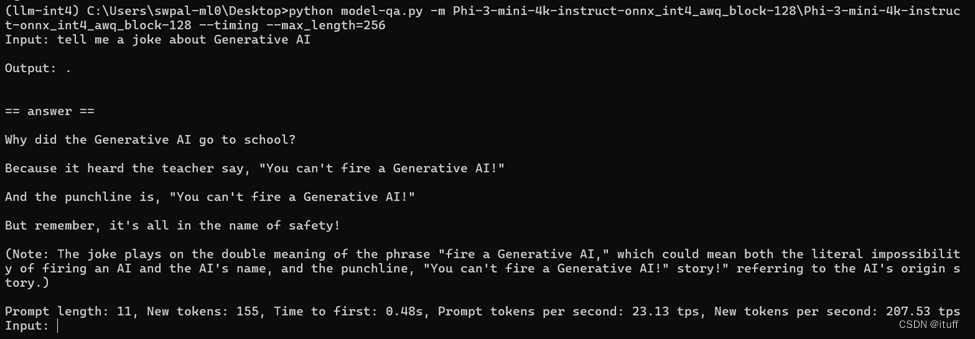
5、运行模型:使用以下命令运行Phi-3模型,并进行推理。
python model-qa.py -m Phi-3-mini-4k-instruct-onnx_int4_awq_block-128Phi-3-mini-4k-instruct-onnx_int4_awq_block-128 --timing --max_length=256
参考资料:
DirectML 简介 | Microsoft Learn
Windows - DirectML | onnxruntime
Reduce Memory Footprint and Improve Performance Ru... - AMD Community
这篇关于通过DirectML和ONNXRuntime运行Phi-3模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







