本文主要是介绍用于原发性进行性失语症分类的可解释性机器学习影像组学模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
背景:原发性进行性失语症(PPA)是一种以语言障碍为特征的神经退行性疾病。两种主要的临床亚型分别为语义型(svPPA)和非流利型失语(nfvPPA)。对PPA患者的诊断和分类是一个复杂的挑战,需要整合多模态信息,包括临床、生物学和放射学特征。结构神经影像学在辅助PPA鉴别诊断和构建诊断支持系统方面起着至关重要的作用。
方法:本研究对56例PPA患者(31例svPPA和25例nfvPPA)以及53名年龄性别匹配的对照组进行了T1加权图像的白质纹理分析。结合临床/影像组学测量训练了一种基于树的算法,并使用Shapley加法解释(SHAP)模型来提取区分svPPA和nfvPPA患者与对照组以及彼此之间更有效的指标。
结果:影像组学集成分类模型在区分svPPA患者和对照组方面的准确率为95%,区分svPPA和nfvPPA的准确率为93.7%。在区分nfvPPA患者和对照组方面的准确率为93.7%。此外,Shapley值显示了患者分类模型中左内嗅皮层附近的白质参与度较高。
讨论:本研究为影像组学特征在svPPA和nfvPPA患者分类中的实用性提供了新的证据,并证明了可解释的机器学习方法在提取评估PPA最具影响力特征方面的有效性。
引言
原发性进行性失语症(PPA)是一种神经退行性疾病,每10万人中约有3~4人患病。PPA是额颞叶变性(FTLD)的另一种主要形式,其临床特征是语言障碍,影响口语、写作和理解能力。PPA的两种最显著的亚型包括以言语缓慢、费力和语法错误为特征的非流利型失语(nfvPPA),以及以无法理解单词或构建句子为特征的语义型失语(svPPA)。每种亚型都表现出与潜在病理相对应的特定表型特征。SvPPA通常与TDP-43-C病理聚集物相关(75-100%的患者),通常也与FTD tau病理有关。相反,nfvPPA通常与FTD-4R tau有关。
PPA患者的诊断和分类是一项复杂的挑战,需要整合临床、生物学和影像学特征等多模态信息。关于脑成像变化,一些研究报告了语言障碍与灰质区域的变化以及与语言相关的皮层区域的白质纤维束之间的关联。此外,svPPA显示腹侧流中断,从而影响枕颞叶通路。相反,nfvPPA的特征是更多的背侧通路受损,通常会涉及顶叶-额叶区域。近年来,在脑灰质和白质区域提取的形态和扩散特征也被用于开发诊断支持系统,以辅助临床诊断和鉴别PPA患者。虽然许多研究都集中于利用灰质萎缩特征创建自动化系统,但只有少数研究人员建立了基于扩散的白质损伤分类模型。
在影像诊断领域,影像组学提出了一种新的分析方法,能够揭示图像中难以察觉的细节。它量化了感兴趣病理区域(ROIs)的纹理变化。因此,许多研究利用影像组学方法来揭示癌症等疾病中的影像生物标志物,最近还用于评估其他疾病(包括神经退行性疾病)的诊断和预后。特别是,分类模型是通过提取特定脑区的高维影像组学测量集,然后结合特征选择和机器学习算法来区分诊断类别。然而,尽管这些分类框架获得了最优性能,但每个特征对模型分类贡献的估计往往不明确,从而限制了结果的可解释性。因此,近年来,可解释性的概念受到了广泛关注,其目的是理解模型背后的推理,并以此方式评估哪些信息对性能的影响最大。
在本研究中,研究者开发了一种基于影像组学的分类方法来对PPA患者进行分类,并对研究者之前在相同人群中评估结构性白质偏侧损伤的研究进行了二次分析。特别是,从白质区域提取的一阶和二阶统计量,并结合临床信息作为输入,用于基于树的算法从健康对照中区分出svPPA和nfvPPA,以及区分不同的PPA表型。此外,本研究使用了一种能够提高机器学习模型可解释性的Shapley加法解释(SHAP)方法来评估特征在分类性能中的重要性。
材料与方法
参与者
数据来自额颞叶变性神经影像计划(FTLDNI)数据库(请访问http://memory.ucsf.edu/research)。为了最大限度地减少由不同成像协议引起的潜在偏差,本研究专门选择了在加州大学旧金山分校(最大的招募中心)获取的图像。特别是在FTLDNI UCSF的总样本中(37例nfvPPA;34例svPPA;127例HC),本研究首先考虑了具有有效T1加权MRI序列的被试。接下来,随机选择svPPA患者、nfvPPA患者和健康对照者,以获得性别和年龄匹配的组。
FTLDNI的主要目标是确定用于追踪额颞叶变性的神经影像模态和分析方法,并评估影像学与其他标志物在诊断中的价值。所有患者均接受了临床、影像学、语言和神经心理学检查,并符合Gorno-Tempini等人(2011)定义的原发性进行性失语症(PPA)的现行诊断标准。采用临床痴呆评定量表(CDR)及语言分项评分(CDR语言)评估总体认知状态。通过语言能力测试,如语义流畅性测试(动物类别)、语音流畅性测试(d词)和波士顿命名测试(BNT)来评估语言能力。对照组均无神经系统或精神疾病史(有关更多信息,请参阅https://memory.ucsf.edu/research-trials/research/4rtni-2)。
MRI数据提取
所有被试均在配备12通道头线圈的3T西门子Trio Tim系统上进行标准的MR图像采集,包括全脑三维T1 MPRAGE序列(TR/TE=2300/2.9ms,矩阵=240×256×160,各向同性体素1mm3,层厚=1mm)。由一名经验丰富的神经放射科医生检查图像以排除大脑异常,包括腔隙性和广泛的脑血管病变。
使用FreeSurfer 6.0对MRI图像进行区域分割。将图像大小调整为1mm³各向同性体素,然后去除非脑组织、校正偏差,并将图像分割为灰质(GM)、白质(WM)和脑脊液。对颅骨剥离后的非均匀强度校正图像(nu.mgz)进行影像组学特征提取。采用FreeSurfer白质分割法描绘白质感兴趣区(ROIs),该方法基于Desikan-Killiany图谱对白质进行分类。因此,本研究获得了每个半球34个白质ROIs,以解释通常在PPA患者中观察到的不对称性脑萎缩。
对于每个ROI,根据图像生物标志物标准化倡议(IBSI)定义了一组86个影像组学特征,其中包括16个一阶特征(用于描述图像掩模内的体素强度分布)和70个二阶纹理特征:来自灰度共生矩阵(GLCM)的24个特征、灰度游程矩阵(GLRLM)的16个特征、灰度依赖矩阵(GLDM)的14个特征,以及来自灰度大小区域矩阵(GLSZM)的16个特征。总的来说,为每个被试收集了5848个影像组学测量值。特征提取过程的示意图如图1所示。使用Python包PyRadiomics 3.0来提取影像组学特征。
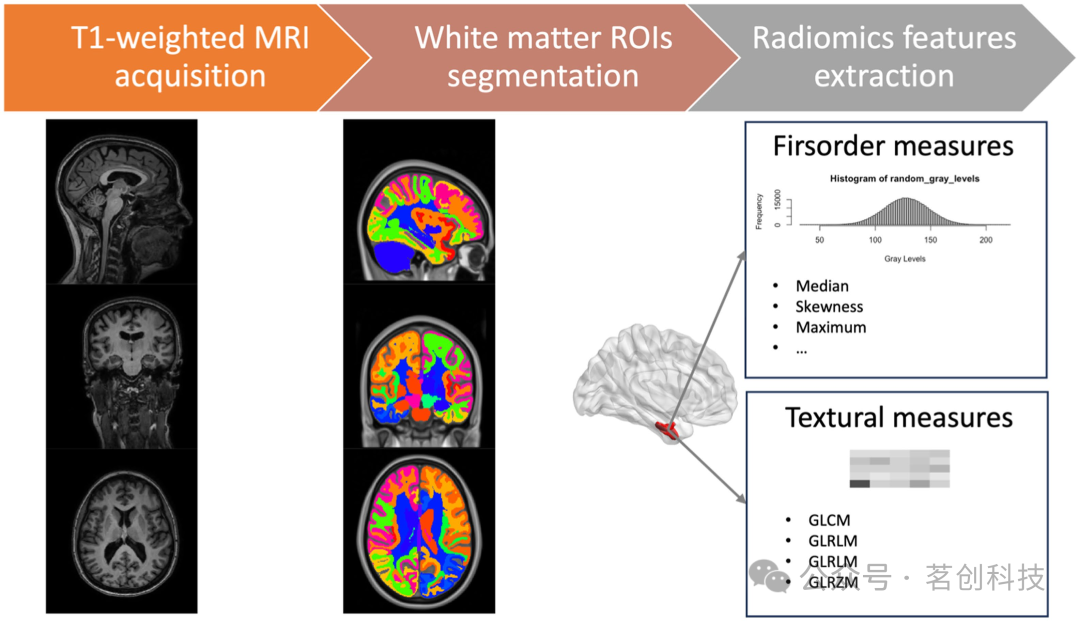
图1.特征提取过程示意图。
可解释的机器学习管道
首先,按照70:30的比例将数据随机分为训练集和测试集,确保样本分层以保持训练和测试部分的标签比例相同。然后,在训练集上应用特征选择方法来防止模型过拟合。通过Pearson相关分析消除特征之间的冗余,将cutoff系数设置为0.9。特别是,本研究确定了绝对相关系数最高的特征对。随后,计算每个特征与所有其他特征的平均绝对相关系数,排除每次迭代中平均绝对相关系数最高的特征。这种迭代过程会持续进行,直到影像组学特征之间的成对相关系数低于0.9。剩下的测量值将用于模型开发。
本研究选择XGBoost分类器作为基准算法。XGBoost因其出色的分类性能,尤其是对于不平衡数据,成为boosting技术的首选。更具体地说,L1和L2正则化负责管理稀疏性并减少过拟合。为了优化模型,本研究采用了随机网格搜索技术,在训练集上使用5折交叉验证设置运行了60次迭代。通过优化学习率(从0.01到0.1)、最大深度(从3到10)、估计器数目(从50到200)和子采样(从0.5到1),使用接收者操作特征曲线下面积(AUC-ROC)作为评估交叉验证模型性能的指标,从而确定最佳模型。最后,使用基于Shapley值(SHAP)评估每个特征的重要性。这种方法使我们能够评估哪种测量对模型性能的影响最大。具体而言,它使我们能够评估一个特征对整个训练集的影响,当与其他特征值结合考虑时,提供了特征重要性之外的其他信息,而不是作为一个单一的解释器。
统计分析
使用均值和标准差等描述性统计指标来探索每组的数据。使用卡方检验和Kruskal-Wallis方差分析来分析人口统计学和临床数据的组间差异,然后进行事后检验(Wilcoxon符号秩检验)。在分类分析方面,本研究将每个训练过的模型应用于保留测试集,使用各种指标来评估其性能,包括灵敏度、特异度、平衡准确度、精确度、AUC-ROC和F1分数。为了评估和比较本研究的影像组学组合模型与经典形态学测量方法,使用FreeSurfer工具包提取的每个ROI的体积数据重复相同的分析。
结果
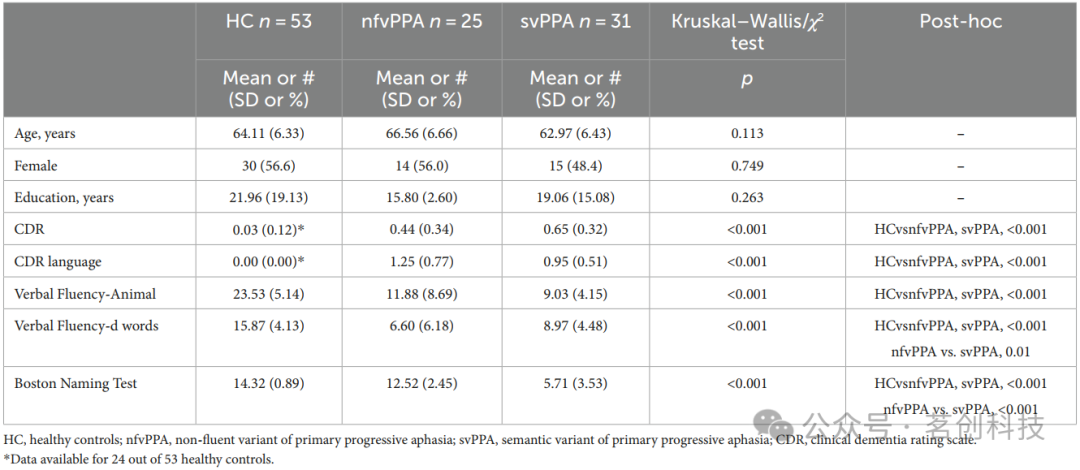
最终纳入109名被试:31名svPPA患者和25名nfvPPA患者,以及53名性别和年龄匹配的健康对照组(HC)。在临床数据方面,PPA组与HC组之间存在显著差异(见表1)。此外,相较于nfvPPA组,svPPA组在波士顿命名测试中的表现显著受损(p<0.001),而在语音流畅性测试中的表现优于nfvPPA组(p<0.001)。
表1.人口统计学和临床/认知信息。
所有XGBoost二分类模型都在70%的样本上进行训练(包括37名HC,21名svPPA和17名nfvPPA),并在剩余的30%数据集上进行评估(包括16名HC,10名svPPA和8名nfvPPA)。
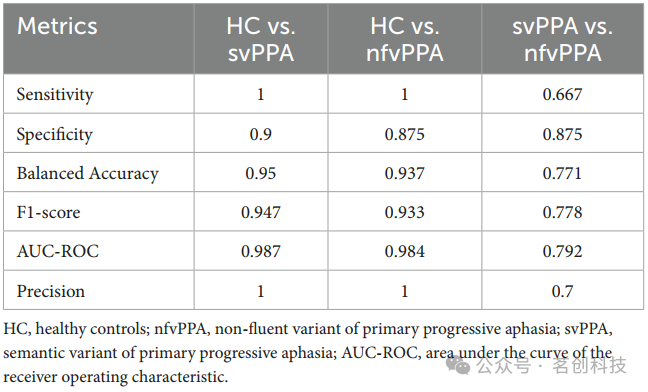
首先,本研究检查了仅考虑临床/认知变量训练的模型性能。结果如表2所示,PPA患者与HC之间的比较性能达到最佳值(svPPA与HC之间的平衡准确度为0.95,灵敏度为1,特异度为0.9,而nfvPPA与HC之间的平衡准确度为0.937,灵敏度为1,特异度为0.875)。相比之下,语义型和非流利型失语PPA之间的区分仍然欠佳(平衡准确度为0.771,灵敏度为0.667,特异度为0.875)。
表2.临床/认知模型在测试集上的组间分类性能比较。
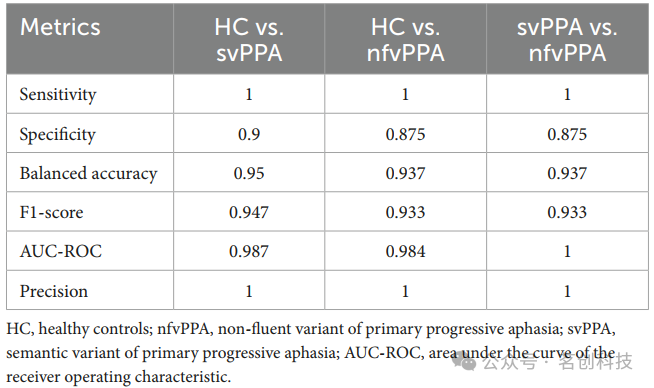
在影像组学分析中,将每个训练步骤中选择的影像组学特征结合临床/认知信息作为输入进行分类分析。如表3所示,XGBoost模型证实了在区分svPPA和nfvPPA患者与HC方面取得了最佳结果(svPPA与HC之间的平衡准确度为0.95,灵敏度为1,特异度为0.9;而nfvPPA与HC之间的平衡准确度为0.937,灵敏度为1,特异度为0.875)。此外,svPPA和nfvPPA患者之间的平衡准确度为0.937,灵敏度为1,特异度为0.875。即使经典的形态学特征达到了最优结果,但影像组学模型进一步优化了分类性能。
表3.临床/认知+影像组学模型在测试集上的组间分类性能比较。
关于各指标(临床/认知和影像组学)对分类性能的影响,svPPA分类的可解释性分析(见图2)显示,语言障碍(语言流畅性-动物和BNT测试)以及患者临床状况(CDR)受损对分类性能产生了较大的影响。然而,与对照组相比,来自左内嗅皮层附近白质区域的影像组学指标对于预测svPPA综合征有显著影响,同时也对应于患者的影像组学特征值较低。
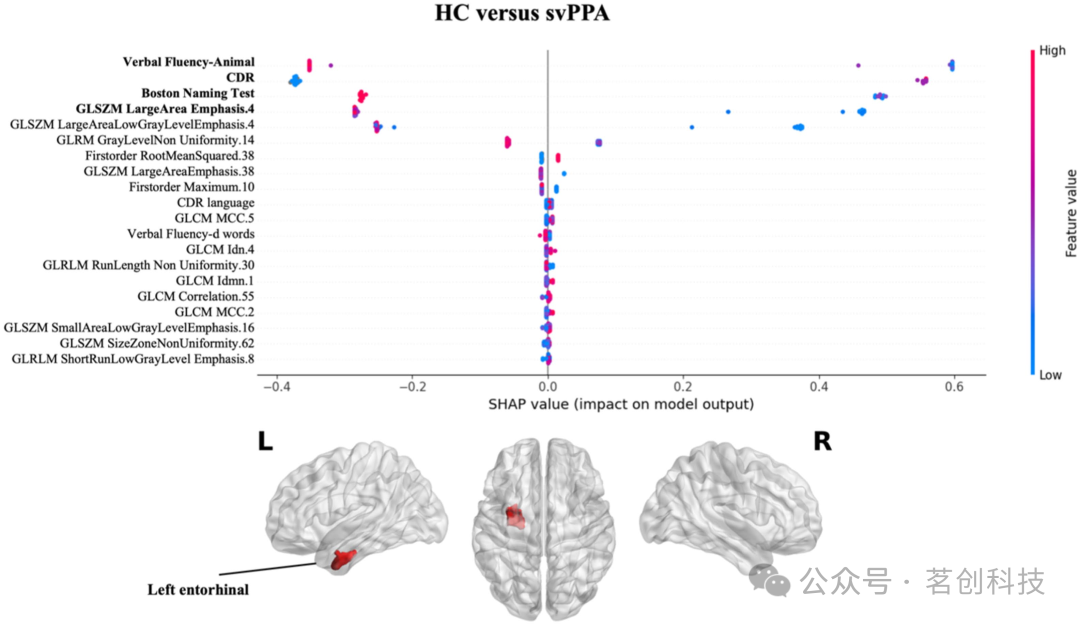
图2.影像组学特征对HC与svPPA组分类的影响。
图3显示了用于将nfvPPA患者与健康对照组分类的SHAP值结果。与svPPA分类类似,语言评分(CDR语言和言语流畅性测试)以及左侧额中回尾侧白质的影像组学特征对分类的影响最大,且患者的值低于对照组。
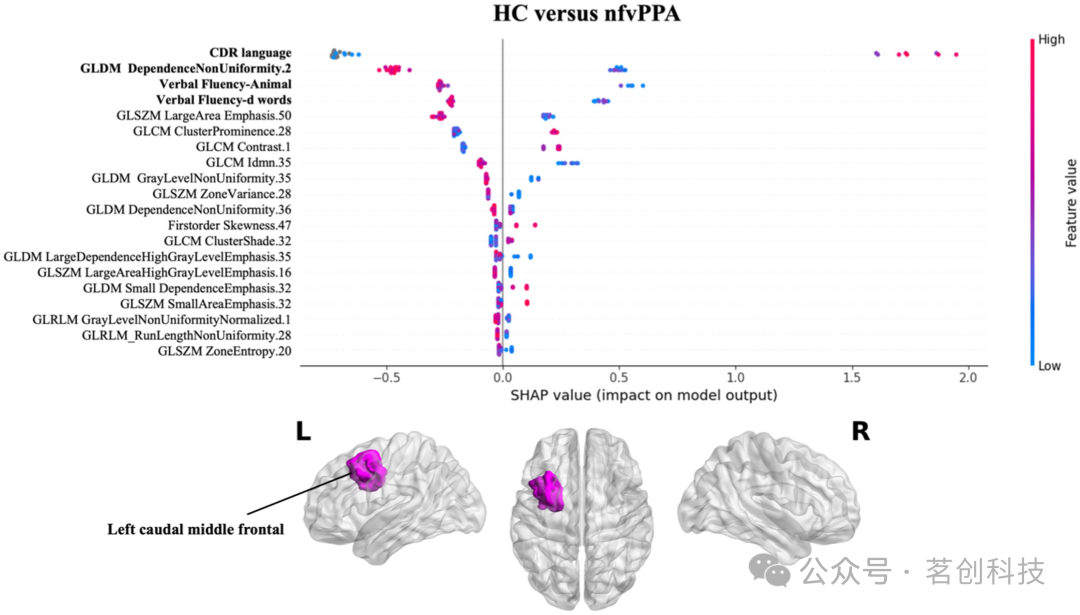
图3.影像组学特征对HC与nfvPPA组分类的影响。
最后,相对于svPPA,nfvPPA的分类结果显示左内嗅白质的影像组学特征和波士顿命名测试(BNT)评分对模型具有最大的预测能力。特别是左内嗅的GLRLM游程非均一度的值较高,对nfvPPA综合征的预测性较高(见图4)。
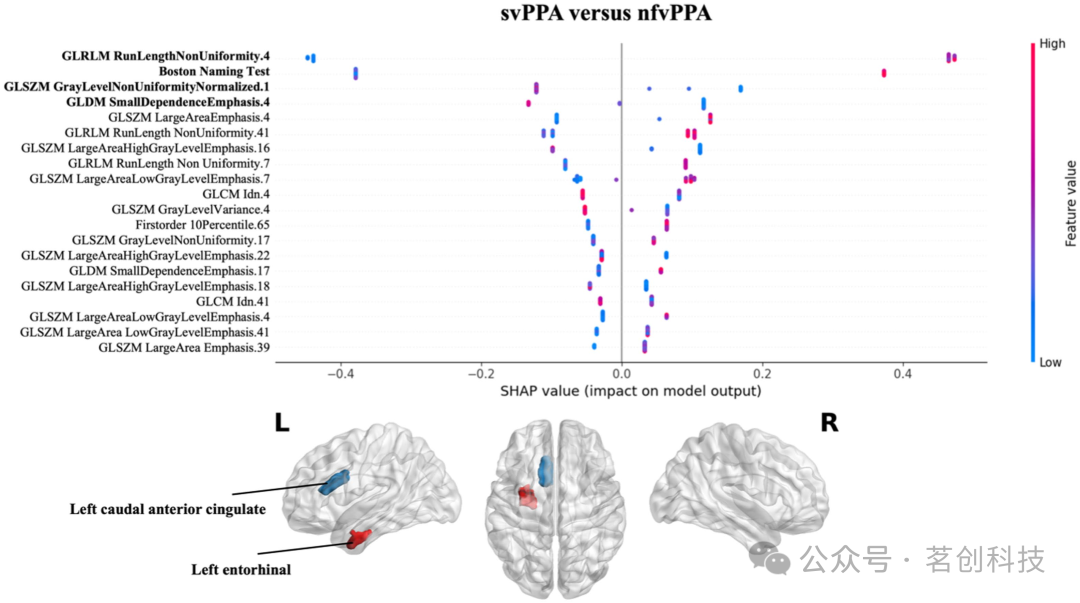
图4.影像组学特征对svPPA与nfvPPA组分类的影响。
讨论
本研究利用临床信息和白质区域影像组学特征来区分PPA患者。相较于仅依赖临床/认知评分,影像组学特征显著提高了患者组之间的分类性能。在特征可解释性方面,SHAP方法强调了左内嗅皮层在区分svPPA和nfvPPA患者中的作用更大。相反,影像组学在分类患者与对照组方面的作用有限。事实上,SHAP方法显示临床/认知评分在区分PPA患者与对照组方面具有更强的影响力。
本研究模型的性能与先前利用MRI数据支持PPA患者临床诊断的研究结果一致。具体而言,在将svPPA与健康对照组进行分类时,本研究模型达到了95%的准确率,这与使用灰质影像组学指标、皮质厚度以及扩散张量成像(DTI)等特征获得的结果相当。此外,通过SHAP值的可解释性分析证实,无论是灰质还是白质,左侧颞叶,尤其是内嗅皮层是svPPA患者中受影响最大的区域。
正如以往研究所观察到的那样,使用影像学数据对nfvPPA进行分类是一项更具挑战性和难度的任务。具体来说,Lampe等人(2022)的研究报告了基于多中心MRI数据集的多综合征模型对nfvPPA患者分类的性能较差。本研究的影像组学整合模型在区分这些患者与健康对照组时显示了93.7%的最佳准确率。然而,当考虑各项指标对模型的影响时发现,对模型影响最大的变量与临床评分相对应,这证实了影像标志物在区分nfvPPA患者和健康对照组方面的贡献较小。
对于两种PPA亚型的区分,本研究的综合模型在测试集上达到了93.7%的诊断准确率。这一结果超越了仅使用传统形态测量和灰质ROI的影像组学,结合支持向量机、随机森林或线性判别分析等机器学习系统所取得的最新成果。值得注意的是,与病理和健康被试之间的比较相反,临床/认知变量无法正确识别PPA表型,分类准确率仅为77.1%。相反,与影像组学指标的结合达到了93.7%的准确率,而模型中影响最大的特征与左内嗅皮质相关。如之前的影像组学结果所示,该区域是svPPA亚型的一个显著特征,并且与nfvPPA相比,该区域在形态学上与更明显的皮质变薄有关。
本研究也存在一定的局限性。首先,本研究基于机器学习方法背景下的适度样本量,需要通过实施交叉验证来解决这一问题。因此,未来的研究方法应优先考虑涵盖整个PPA范围且更具代表性的数据样本,同时结合更可靠的特征选择方法以确保泛化性最大。其次,从T1加权MR图像中提取白质区域的影像组学特征,排除了使用扩散率信息进行比较分析的可能性。因此,需要进一步研究DTI影像组学在鉴别PPA患者中的应用价值。另一个潜在局限性是缺乏生物学证据,如脑脊液(CSF)或淀粉样PET样本。未来,结合生物学和使用多中心数据集来评估各种分类算法是有益的。第三,本研究在模型训练前进行Pearson相关分析以消除特征冗余。尽管这种方法通常用于解决影像组学测量固有的多重共线性问题,但通过考虑排除的影像组学特征,也可能获得类似的分类度量值。最后,需要进行纵向研究来评估WM影像组学特征是否也可用于开发临床病理进展的预测模型。
结论
本研究为影像组学特征在分类神经退行性疾病患者方面的有效性提供了新的证据。具体而言,本研究的结果表明,基于常规T1加权MR图像的脑白质纹理特性显著提高了分类性能,为新的潜在影像学生物标志物对PPA患者进行分类开辟了道路。特别是,在左内嗅皮层附近的白质中提取的影像组学特征可能有助于nfvPPA与svPPA患者的区分。
参考文献:Tafuri B, De Blasi R, Nigro S and Logroscino G (2024) Explainable machine learning radiomics model for Primary Progressive Aphasia classification. Front. Syst. Neurosci. 18:1324437. doi: 10.3389/fnsys.2024.1324437
小伙伴们关注茗创科技,将第一时间收到精彩内容推送哦~
这篇关于用于原发性进行性失语症分类的可解释性机器学习影像组学模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








