本文主要是介绍数据挖掘综合案例-家用热水器用户行为分析与事件识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1. 背景与挖掘目标
- 2. 分析方法与过程
- 3. 数据分析
- 3.1 数据探索分析
- 3. 2 数据预处理
- 1. 属性约束
- 2. 划分用水事件
- 3. 确定单次用水事件时长阈值
- 4. 属性构造
- 5.筛选候选洗浴事件
- 3.3 模型构建
- 3.4 模型检验
- 4. 思考总结

1. 背景与挖掘目标
随着国内大家电品牌的进入和国外品牌的涌入,电热水器相关技术在过去20年间得到了快速发展,屡屡创新。
-
首次提出封闭式电热水器的概念到水电分离技术的研发。
-
漏电保护技术的应用及出水断电技术和防电墙技术专利的申请突破。
如今高效能技术颠覆了业内对电热水器“高能耗”的认知。
-
当下的热水器行业也并非一片太平盛世,行业内正在上演一幕弱肉强食的“丛林法则”戏码,市场份额逐步向龙头企业集中,尤其是那些在资金、渠道和品牌影响力等方面拥有实力的综合家电品类巨头,正在不断蚕食鲸吞市场蛋糕。
-
要想在该行业立足,只能走产品差异化的路线,提升技术实力和产品质量,在功能卖点、外观等方面做出自身特色。
-
在热水器用户行为分析过程中,用水事件识别是最为关键的环节。根据该热水器生产厂商提供的数据热水器用户用水事件划分与识别项目的整体目标如下。
-
根据热水器采集到的数据,划分一次完整用水事件。
-
在划分好的一次完整用水事件中,识别出洗浴事件。
2. 分析方法与过程
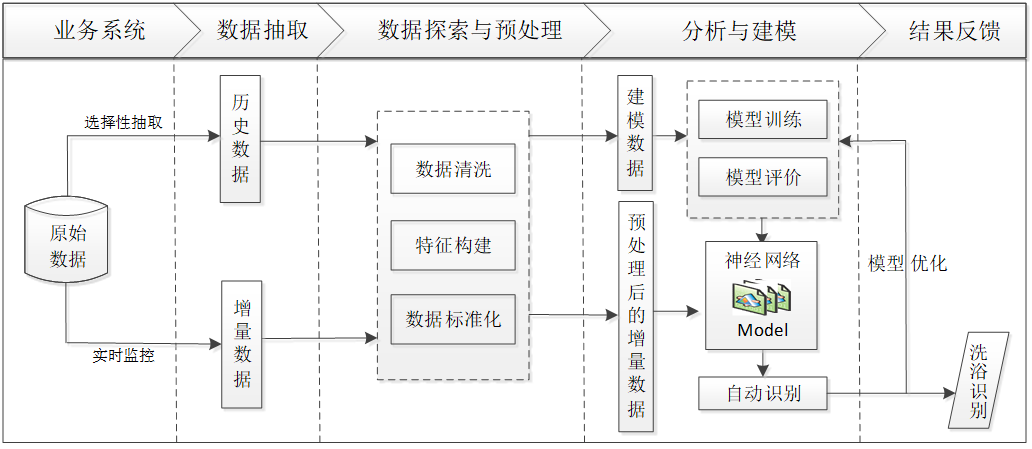
1.对热水用户的历史用水数据进行选择性抽取,构建专家样本。
2.对步骤1形成的数据集进行数据探索分析与预处理,包括探索水流量的分布情况,删除冗余属性,识别用水数据的缺失值,并对缺失值作处理,根据建模的需要进行属性构造等。根据以上处理,对用水样本数据建立用水事件时间间隔识别模型和划分一次完整的用水事件模型,再在一次完整用水事件划分结果的基础上,剔除短暂用水事件缩小识别范围等。
3.在步骤2得到的建模样本数据基础上,建立洗浴事件识别模型,对洗浴事件识别模型进行模型分析评价。
4.对步骤3形成的模型结果应用并对洗浴事件划分进行优化。
5.调用洗浴事件识别模型,对实时监控的热水器流水数据进行洗浴事件自动识别。
3. 数据分析
3.1 数据探索分析
1.在热水器的使用过程中,热水器的状态会经常发生改变,比如开机和关机、由加热转到保温、由无水流到有水流、水温由50℃变为49℃等。而智能热水器在状态发生改变或者水流量非零时,每两秒会采集一条状态数据。由于数据的采集频率较高,并且数据来自大量用户,数据总量非常大。
2.对原始数据采用无放回随机抽样法抽取200家热水器用户从2014年1月1日至2014年12月31日的用水记录作为原始建模数据。
3.由于用户不仅使用热水器来洗浴,而且包括了洗手、洗脸、刷牙、洗菜、做饭等用水行为,所以热水器采集到的数据来自各种不同的用水事件。
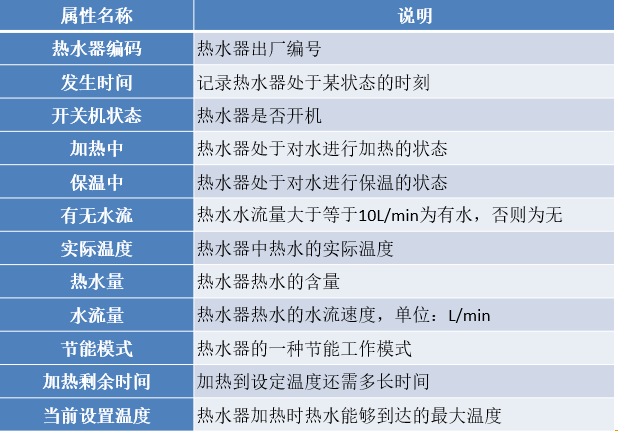
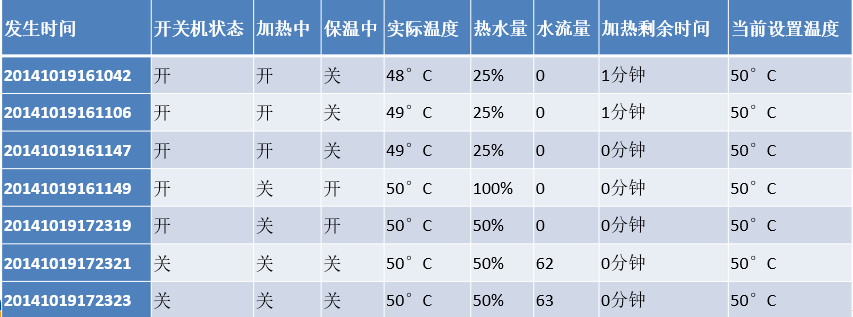
热水器采集的用水数据包含12个属性:热水器编码,发生时间,开关机状态,加热中,保温中,有无水流,实际温度,热水量,水流量,节能模式,加热剩余时间和当前设置温度。其解释说明下表所示。
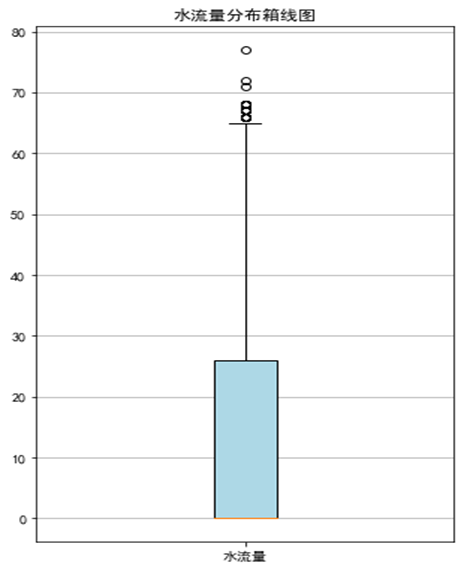
探索分析热水器的水流量状况,其中有无水流和水流量属性最能直观体现热水器的水流量情况,对这两个属性进行探索分析,得到不同水流状态的记录的条形图,无水流状态的记录明显比有水流状态的记录要多

不同水流状态的记录的箱线图,箱体贴近0,说明无水流量的记录较多,水流量的分布与水流状态的分布一致
用水停顿时间间隔定义为一条水流量不为0的流水记录同下一条水流量不为0的流水记录之间的时间间隔。
根据现场实验统计,两次用水的过程的用水停顿的间隔时长一般在不大于4分钟。
为了探究用户真实用水停顿时间间隔的分布情况,统计用水停顿的时间间隔并做频率分布表。
通过频率分布表分析用户用水停顿时间间隔的规律性,具体的数据如下表所示。
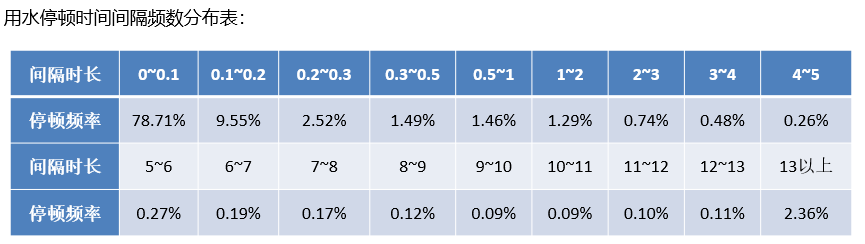
停顿时间间隔为00.3分钟的频率很高,根据日常用水经验可以判断其为一次用水时间中的停顿;停顿时间间隔为613分钟的频率较低,分析其为两次用水事件之间的停顿间隔。
两次用水事件的停顿时间间隔分布在3~7分钟。根据现场实验统计用水停顿的时间间隔近似。
3. 2 数据预处理
1. 属性约束
由于热水器采集的用水数据属性较多,做以下处理,因分析的主要对象为用户,分析的主要目标为用户的洗浴行为的一般规律,所以“热水器编号”属性可以去除;因热水器采集的数据中,“有无水流”属性可以通过“水流量”属性反应,“节能模式”属性取值相同均为“关”,对分析无作用,可以去除。
删除冗余属性“热水器编号”“有无水流”“节能模式”,删除冗余属性后得到用来建模的属性如下表所示。
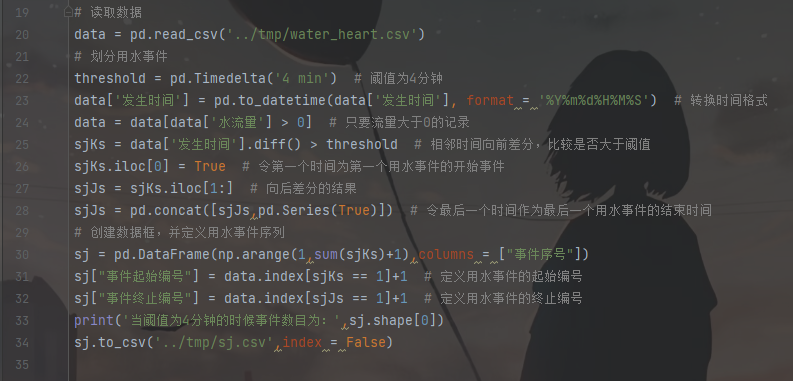
2. 划分用水事件
用水状态记录中,水流量不为0表明用户正在使用热水;而水流量为0时用户用热水发生停顿或者用热水结束。对于任一个用水记录,如果它的向前时差超过阈值 ,则将它记为事件的开始编号;如果向后时差超过阈值 ,则将其记为事件的结束编号。划分模型的符号说明如下表所示。

一次完整用水事件的划分步骤如下。
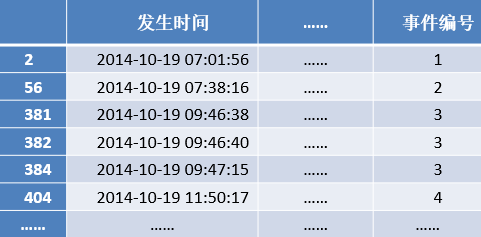
(1) 读取数据记录,识别到所有水流量不为0的状态记录,将它们的发生时间记为序列t1。
(2) 对序列t1构建其向前时差列和向后时差列,并分别与阈值进行比较。向前时差超过阈值T,则将它记为新的用水事件的开始编号;如果向后时差超过阈值T,则将其记为用水事件的结束编号。
循环执行步骤(2)直到向前时差列和向后时差列与均值比较完毕,结束事件划分。
对用户的用水数据进行划分结果如下表所示。
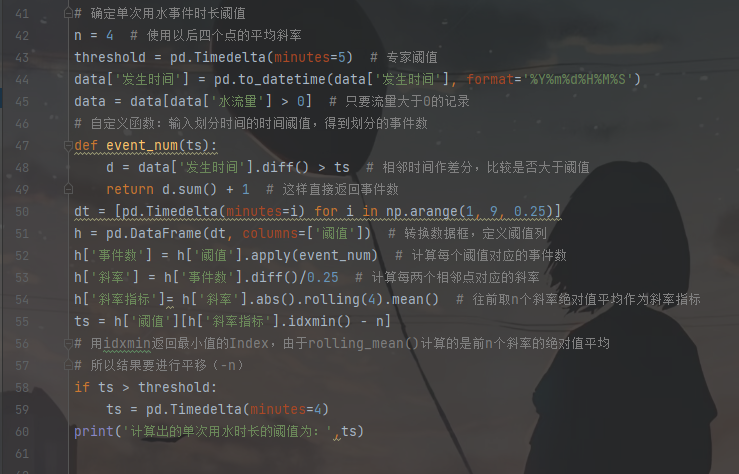
3. 确定单次用水事件时长阈值
对某热水器用户的数据根据不同的阈值划分用水事件,得到了相应的事件个数,阈值变化与划分得到事件个数如下表所示。
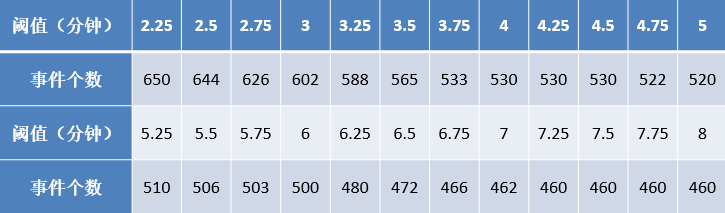
阈值与划分事件个数关系如下图所示。
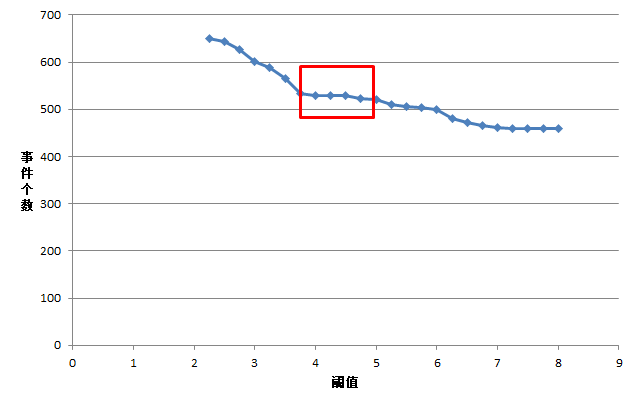
上图为阈值与划分事件个数的散点图,图中某段阈值范围内,下降趋势明显,说明在该段阈值范围内,用户的停顿习惯比较集中。如果趋势比较平缓,则说明用户的停顿热水的习惯趋于稳定,所以取该段时间开始的时间点作为阈值,既不会将短的用水事件合并,又不会将长的用水事件拆开。
用户停顿热水的习惯在方框的位置趋于稳定,说明热水器用户的用水的停顿习惯用方框开始的时间点作为划分阈值会有一个好的效果。
曲线在上图(散点图)中方框趋于稳定时,其方框开始的点的斜率趋于一个较小的值。为了用程序来识别这一特征,将这一特征提取为规则。根据用水停顿时间间隔频数分布表说明如何识别上图中的方框中起始的时间。
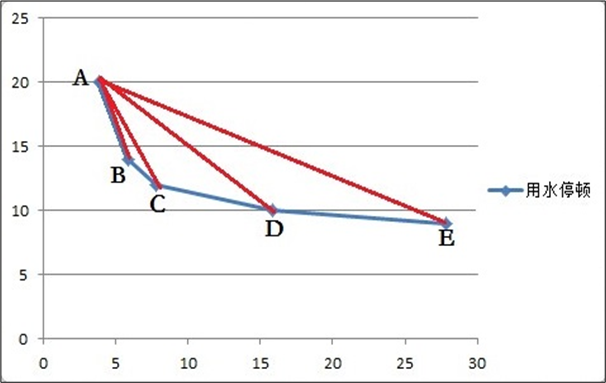
每个阈值对应一个点,给每个阈值计算得到一个斜率指标,如上图所示,其中A点是要计算的斜率指标点。为了直观的展示,如下表所示。



4. 属性构造
1.构建用水时长与频率属性
不同用水事件的用水时长是基础特征之一。根据用水时长这一特征可以构建下表所示的事件开始时间、事件结束时间、洗浴时间点、用水时长、总用水时长和用水时长/总用水时长这6个特征。
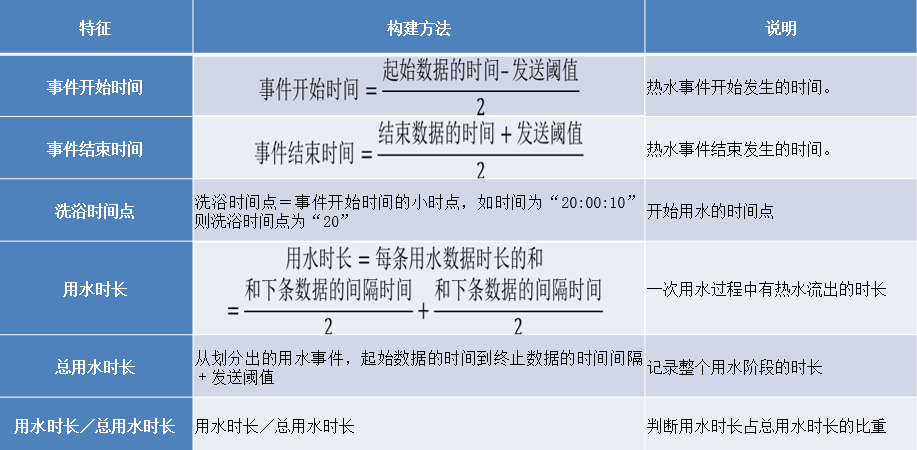
构建用水开始时间或结束的时间两个特征时分别减去或加上了发送阈值(发送阈值是指热水器传输数据的频率的大小)。其原因如下,取平均值会导致很大的偏差。
综合分析构建“用水开始时间”为起始数据的时间减去“发送阈值”的一半。
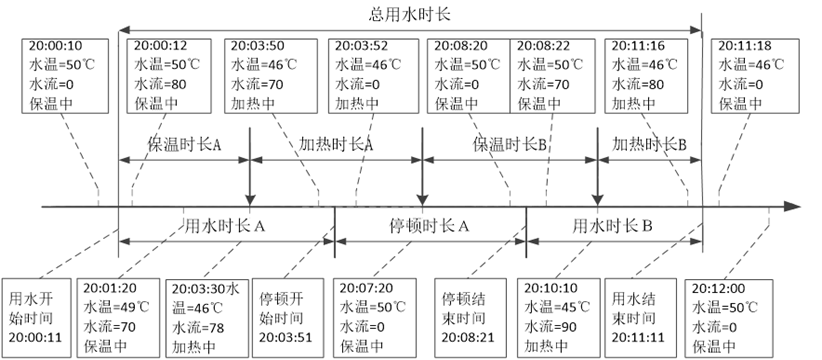
用水时长相关的特征只能够区分出一部分用水事件,不同用水事件的用水停顿和频率也不同。

# 转换时间格式
data["发生时间"] = pd.to_datetime(data["发生时间"],format="%Y%m%d%H%M%S")# 构造特征:总用水时长
timeDel = pd.Timedelta("0.5 sec")
sj["事件开始时间"] = data.iloc[sj["事件起始编号"]-1,0].values- timeDel
sj["事件结束时间"] = data.iloc[sj["事件终止编号"]-1,0].values + timeDel
sj['洗浴时间点'] = [i.hour for i in sj["事件开始时间"]]
sj["总用水时长"] = np.int64(sj["事件结束时间"] - sj["事件开始时间"])/1000000000 + 1# 构造用水停顿事件
# 构造特征“停顿开始时间”、“停顿结束时间”
# 停顿开始时间指从有水流到无水流,停顿结束时间指从无水流到有水流
for i in range(len(data)-1):if (data.loc[i,"水流量"] != 0) & (data.loc[i + 1,"水流量"] == 0) :data.loc[i + 1,"停顿开始时间"] = data.loc[i +1, "发生时间"] - timeDelif (data.loc[i,"水流量"] == 0) & (data.loc[i + 1,"水流量"] != 0) :data.loc[i,"停顿结束时间"] = data.loc[i , "发生时间"] + timeDel# 提取停顿开始时间与结束时间所对应行号,放在数据框Stop中
indStopStart = data.index[data["停顿开始时间"].notnull()]+1
indStopEnd = data.index[data["停顿结束时间"].notnull()]+1
Stop = pd.DataFrame(data={"停顿开始编号":indStopStart[:-1],"停顿结束编号":indStopEnd[1:]})
# 计算停顿时长,并放在数据框stop中,停顿时长=停顿结束时间-停顿结束时间
Stop["停顿时长"] = np.int64(data.loc[indStopEnd[1:]-1,"停顿结束时间"].values-data.loc[indStopStart[:-1]-1,"停顿开始时间"].values)/1000000000
# 将每次停顿与事件匹配,停顿的开始时间要大于事件的开始时间,
# 且停顿的结束时间要小于事件的结束时间
for i in range(len(sj)):Stop.loc[(Stop["停顿开始编号"] > sj.loc[i,"事件起始编号"]) & (Stop["停顿结束编号"] < sj.loc[i,"事件终止编号"]),"停顿归属事件"]=i+1# 删除停顿次数为0的事件
Stop = Stop[Stop["停顿归属事件"].notnull()]# 构造特征 用水事件停顿总时长、停顿次数、停顿平均时长、
# 用水时长,用水/总时长
stopAgg = Stop.groupby("停顿归属事件").agg({"停顿时长":sum,"停顿开始编号":len})
sj.loc[stopAgg.index - 1,"总停顿时长"] = stopAgg.loc[:,"停顿时长"].values
sj.loc[stopAgg.index-1,"停顿次数"] = stopAgg.loc[:,"停顿开始编号"].values
sj.fillna(0,inplace=True) # 对缺失值用0插补
stopNo0 = sj["停顿次数"] != 0 # 判断用水事件是否存在停顿
sj.loc[stopNo0,"平均停顿时长"] = sj.loc[stopNo0,"总停顿时长"]/sj.loc[stopNo0,"停顿次数"]
sj.fillna(0,inplace=True) # 对缺失值用0插补
sj["用水时长"] = sj["总用水时长"] - sj["总停顿时长"] # 定义特征用水时长
sj["用水/总时长"] = sj["用水时长"] / sj["总用水时长"] # 定义特征 用水/总时长
print('用水事件用水时长与频率特征构造完成后数据的特征为:\n',sj.columns)
print('用水事件用水时长与频率特征构造完成后数据的前5行5列特征为:\n',sj.iloc[:5,:5])2.构建用水量与波动属性
除了用水时长,停顿和频率外,用水量也是识别该事件是否为洗浴事件的重要特征。可以构建出下表所示的两个用水量特征。

同时用水波动也是区分不同用水事件的关键。根据不同用水事件的这一特征可以构建下表所示的水流量波动和停顿时长波动两个特征。

data["水流量"] = data["水流量"] / 60 # 原单位L/min,现转换为L/sec
sj["总用水量"] = 0 # 给总用水量赋一个初始值0
for i in range(len(sj)):Start = sj.loc[i,"事件起始编号"]-1End = sj.loc[i,"事件终止编号"]-1if Start != End:for j in range(Start,End):if data.loc[j,"水流量"] != 0:sj.loc[i,"总用水量"] = (data.loc[j + 1,"发生时间"] - data.loc[j,"发生时间"]).seconds* \data.loc[j,"水流量"] + sj.loc[i,"总用水量"]sj.loc[i,"总用水量"] = sj.loc[i,"总用水量"] + data.loc[End,"水流量"] * 2else:sj.loc[i,"总用水量"] = data.loc[Start,"水流量"] * 2sj["平均水流量"] = sj["总用水量"] / sj["用水时长"] # 定义特征 平均水流量
# 构造特征:水流量波动
# 水流量波动=∑(((单次水流的值-平均水流量)^2)*持续时间)/用水时长
sj["水流量波动"] = 0 # 给水流量波动赋一个初始值0
for i in range(len(sj)):Start = sj.loc[i,"事件起始编号"] - 1End = sj.loc[i,"事件终止编号"] - 1for j in range(Start,End + 1):if data.loc[j,"水流量"] != 0:slbd = (data.loc[j,"水流量"] - sj.loc[i,"平均水流量"])**2slsj = (data.loc[j + 1,"发生时间"] - data.loc[j,"发生时间"]).secondssj.loc[i,"水流量波动"] = slbd * slsj + sj.loc[i,"水流量波动"]sj.loc[i,"水流量波动"] = sj.loc[i,"水流量波动"] / sj.loc[i,"用水时长"] # 构造特征:停顿时长波动
# 停顿时长波动=∑(((单次停顿时长-平均停顿时长)^2)*持续时间)/总停顿时长
sj["停顿时长波动"] = 0 # 给停顿时长波动赋一个初始值0
for i in range(len(sj)):if sj.loc[i,"停顿次数"] > 1: # 当停顿次数为0或1时,停顿时长波动值为0,故排除for j in Stop.loc[Stop["停顿归属事件"] == (i+1),"停顿时长"].values:sj.loc[i,"停顿时长波动"] = ((j - sj.loc[i,"平均停顿时长"])**2) * j + \sj.loc[i,"停顿时长波动"]sj.loc[i,"停顿时长波动"] = sj.loc[i,"停顿时长波动"] / sj.loc[i,"总停顿时长"]print('用水量和波动特征构造完成后数据的特征为:\n',sj.columns)
print('用水量和波动特征构造完成后数据的前5行5列特征为:\n',sj.iloc[:5,:5])5.筛选候选洗浴事件
洗浴事件的识别是建立在一次用水事件识别的基础上,也就是从已经划分好的一次用水事件中识别出哪些一次用水事件是洗浴事件。
可以使用3个比较宽松的条件筛选掉那些非常短暂的用水事件,确定不可能为洗浴事件的数据去除掉,剩余的事件称为“候选洗浴事件”。这三个条件是“或”的关系,也就是说,只要一次完整的用水事件满足任意一个条件,就被判定为短暂用水事件,即会被筛选掉。3个筛选条件如下:
1.一次用水事件中总用水量小于5升。
2.用水时长小于100秒。
3.总用水时长小于120秒。

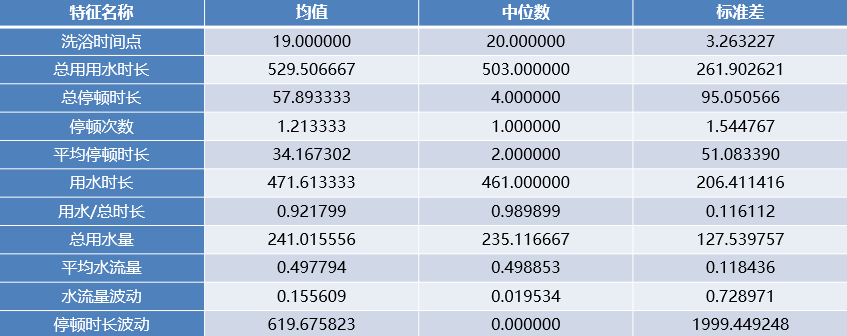
筛选前用水事件数目总共172个,经过筛选后,余下75个用水事件。结合日志,最终用于建模的属性的总数为11个,其基本状况
3.3 模型构建
根据建模样本数据建立BP神经网络模型识别洗浴事件。由于洗浴事件与普通用水事件在特征上存在不同,而且这些不同的特征在特征上被体现出来。于是,根据用户提供的用水日志,将其中洗浴事件的数据状态记录作为训练样本训练BP神经网络。然后根据训练好的网络来检验新采集到的数据,具体过程如下图所示。

在训练神经网络的时候,选取了“候选洗浴事件”的11个属性作为网络的输入,分别为:洗浴时间点,总用水时长,总停顿时长,平均停顿时长,停顿次数,用水时长,用水时长/总用水时长,总用水量,平均水流量,水流量波动和停顿时长波动。
训练BP网络时给定的输出(教师信号)为1与0,其中1代表该次事件为洗浴事件,0表示该次事件不是洗浴事件。是否为洗浴事件的标签是根据热水器的用水记录日志得到。
构建神经网络模型需要注意数据本身属性之间的存在量级差异,因此需要进行标准化,消除量级差异。另外,为了便于后续应用模型,可以用joblib.dump函数保存模型。
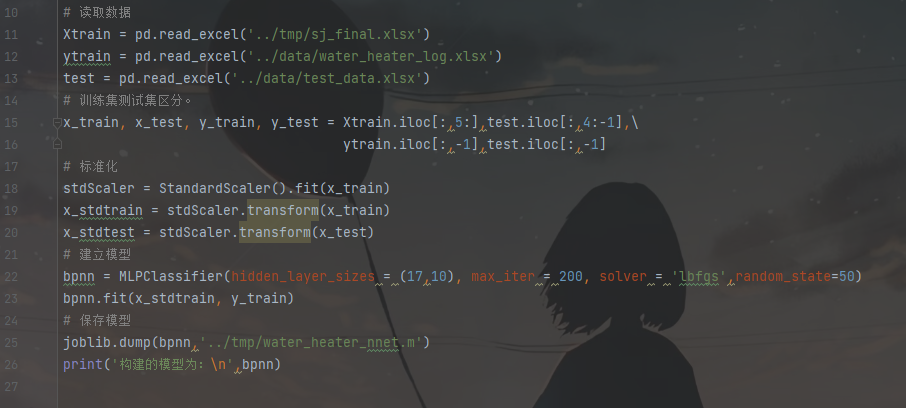
在训练BP神经网络时,对神经网络的参数进行了寻优,发现含2个隐层的神经网络训练效果较好,其中2个隐层的隐节点数分别为17和10时训练的效果较好。
根据样本,得到训练好的神经网络后,就可以用来识别对应的用户家的洗浴事件,其中待检测的样本的11个属性作为输入,输出层输出一个值在[-1,1]范围内,如果该值小于0,则该事件不是洗浴事件,如果该值大于0,则该事件是洗浴事件。某热水器用户记录了两周的热水器用水日志,将前一周的数据作为训练数据,后一周的数据作为测试数据,代入上述模型进行测试。
3.4 模型检验
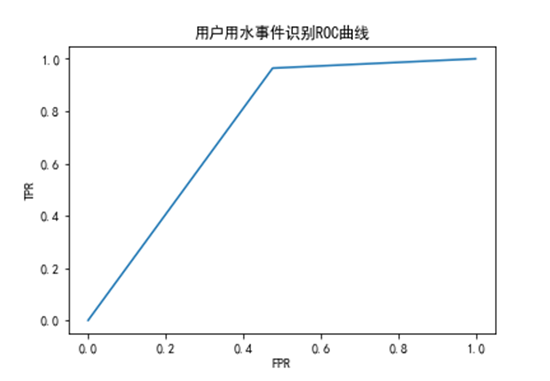
结合模型评价相关的知识,使用精确率(precision)、召回率(recall)和f1值来做模型评价的效果先顾地较为客观、准确。同时结合ROC曲线,可以进一步更加直观地评价模型的效果,得到模型的ROC曲线如下图所示, ROC曲线覆盖的面积较大,说明模型的识别效果较好。
from sklearn.metrics import classification_report
from sklearn.metrics import roc_curve
from sklearn.externals import joblib
import matplotlib.pyplot as pltbpnn = joblib.load('../tmp/water_heater_nnet.m') # 加载模型
y_pred = bpnn.predict(x_stdtest) # 返回预测结果
print('神经网络预测结果评价报告:\n',classification_report(y_test,y_pred))
# 绘制roc曲线图
plt.rcParams['font.sans-serif'] = 'SimHei' # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示负号
fpr, tpr, thresholds = roc_curve(y_pred,y_test) # 求出TPR和FPR
plt.figure(figsize=(6,4)) # 创建画布
plt.plot(fpr,tpr) # 绘制曲线
plt.title('用户用水事件识别ROC曲线') # 标题
plt.xlabel('FPR') # x轴标签
plt.ylabel('TPR') # y轴标签
plt.savefig('../tmp/用户用水事件识别ROC曲线.png') # 保存图片
plt.show() # 显示图形
根据该热水器用户提供的用水日志判断事件是否为洗浴与多层神经网络模型识别结果报告,如下表所示。
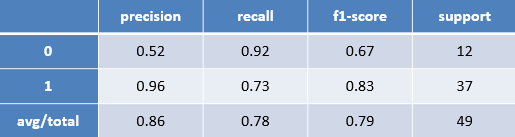
根据模型评估报告表可以看出,在洗浴事件的识别上精确率(precision)非常高,达到了96%,同时召回率(recall)也达到了70%以上。综合上述结果,可以确定此次创建的模型是有效并且效果良好的能够用于实际的洗浴事件的识别中。
4. 思考总结
根据模型划分的结果,发现有时候会将两次(或多次)洗浴划分为一次洗浴,因为在实际情况中,存在着一个人洗完澡后,另一个人马上洗的情况,这中间过渡期间的停顿间隔小于阈值。针对两次(或多次)洗浴事件被合并为一次洗浴事件的情况,需要进行优化,对连续洗浴事件作识别,提高模型识别精确度。
连续洗浴识别法如下:
1.对每次用水事件,建立一个连续洗浴判别指标。连续洗浴判别指标初始值为0,每当有一个属性超过设定的阈值,就给该指标加上相应的值,最后判别连续洗浴指标是否超过给定的阈值,如果超过给定的阈值,认为该次用水事件为连续洗浴事件。
2.选取5个前面提取得到的属性,做为判别连续洗浴事件的特征属性,5个属性分别为:总用水时长、停顿次数、用水时长/总用水时长、总用水量、停顿时长波动。详细的说明如下。
(1) 总用水时长的阈值为900秒,如果超过900秒,就认为可能是连续洗浴,对于每超出的一秒,在该事件的连续洗浴判别指标上加上0.005,详情见表 10 21。
(2) 停顿次数的阈值为10次,如果超过10次,就认为可能是连续洗浴,对于每超出的一次,在该事件的连续洗浴判别指标上加上0.5,详情见表 10 21。
(3) 用水时长/总用水时长的阈值为0.5,如果小于0.5,就认为可能是连续洗浴,对于每少一个单位在该事件的连续洗浴判别指标上加上0.2,详情见表 10 21。
(4) 总用水量的阈值为30L次,如果超过30L,就认为可能是连续洗浴,对于每超出的1L,在该事件的连续洗浴判别指标上加上0.2,详情见表 10 21。
(5) 停顿时长波动的阈值为1000,如果超过1000,就认为可能是连续洗浴,对于每超出一个单位,在该事件的连续洗浴判别指标上加上0.002,详细见下表。

建立优化模型

其中S是连续洗浴判别指标。
连续洗浴事件的划分模型如下:
(1) 当用水事件的连续洗浴判别指标 大于5时,确定为连续洗浴事件或一次洗浴事件加一次短暂用水事件,取中间停顿时间最长的停顿,划分为两次事件。
(2) 如果 不大于5,确定为一次洗浴事件。
这篇关于数据挖掘综合案例-家用热水器用户行为分析与事件识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






