本文主要是介绍CV技术指南 | 中科院又一创举 SecViT | 多功能视觉 Backbone 网络,图像分类、目标检测、实例分割和语义分割都性能起飞!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文来源公众号“CV技术指南”,仅用于学术分享,侵权删,干货满满。
原文链接:中科院又一创举 SecViT | 多功能视觉 Backbone 网络,图像分类、目标检测、实例分割和语义分割都性能起飞!
前言
视觉 Transformer (ViT)因其卓越的关系建模能力而受到关注。然而,其全局注意力机制的二次复杂度带来了相当大的计算负担。常见的解决方法是空间地分组 Token 以进行自注意力,减少计算需求。然而,这种策略忽略了 Token 中的语义信息,可能将语义相关的 Token 分散到不同的组中,从而损害了用于建模 Token 间依赖的自注意力的有效性。基于这些洞察,作者引入了一种快速且均衡的聚类方法,名为语义均衡聚类(SEC)。SEC以一种高效、直接的方式根据 Token 的全局语义相关性对 Token 进行聚类。与需要多次迭代的传统聚类方法不同,作者的方法在一次传递中完成 Token 聚类。此外,SEC调节每个簇中的 Token 数量,确保在当前计算平台上进行有效的并行处理,而无需进一步优化。
来源:AI视界引擎
仅用于学术分享,若侵权请联系删除

代码将可在https://github.com/qhfan/SecViT获取。
1 Introduction
自从Vision Transformer(ViT)[13]问世以来,由于其强大的建模能力,已经引起了研究界的广泛关注。然而,自注意力机制的二次复杂度导致了巨大的计算开销,从而限制了ViT的实际应用。已经设计出多种策略来减轻这种计算负担,其中最普遍的做法涉及 Token 分组,从而限制每个 Token 的注意力范围。
具体来说,Swin-Transformer [36]将 Token 划分为多个小窗口,限制每个窗口内的 Token 注意力。CSWin-Transformer [12]采用十字形分组,赋予每个 Token 一个全局感受野。MaxViT [48]结合了窗口和网格注意力,使窗口内的 Token 能够关注到其他窗口的对应 Token 。然而,这些仅依赖于空间定位的方法忽视了 Token 语义,可能限制了自注意力建模语义依赖的能力。为了减轻这个问题,DGT [35]采用k-means聚类进行 Query 分组,考虑 Token 的语义信息以增强特征学习。然而,k-means聚类的迭代性质以及每个簇中 Token 数量可能不均,这影响了并行注意力操作的效率。
考虑到这些因素,一个理想的 Token 划分方案应该高效地分离 Token ,融入语义信息,并高效利用计算资源(如GPU)。对此,作者提出了一种简单、快速且公平的聚类方法,名为Semantic Equitable Clustering(SEC)。SEC根据 Token 与全局语义信息的关联度来分割 Token 。具体来说,作者使用全局池化生成一个包含全局语义信息的全局 Token 。然后计算这个全局 Token 与所有其他 Token 之间的相似性,反映全局语义相关性。在获得相似性矩阵后,将 Token (除全局 Token 外)按相似性分数排序,并将相似分数的 Token 分组到簇中,确保簇间 Token 分布均匀。如图1所示,SEC全面考虑了 Token 语义,并在单次迭代中完成聚类过程,与多次迭代的k-means不同。由此产生的包含相等数量 Token 的簇可以被GPU高效地并行处理。
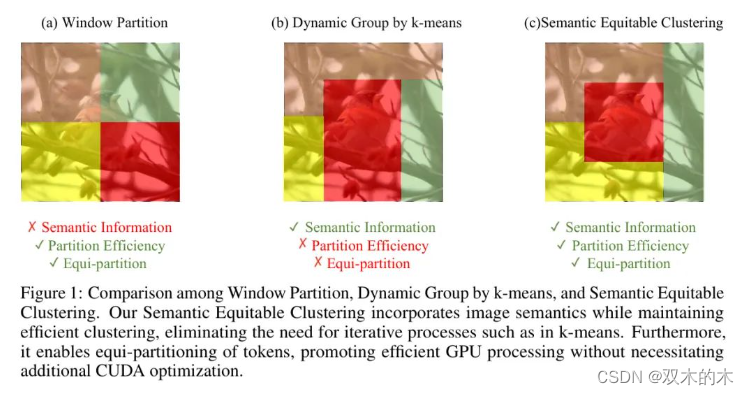
图1:窗口划分、动态k-means分组与语义公平聚类的比较。作者的语义公平聚类在保持高效聚类的同时融入了图像语义,无需像k-means那样的迭代过程。此外,它使得 Token 的均等划分成为可能,促进了无需额外CUDA优化的GPU高效处理。
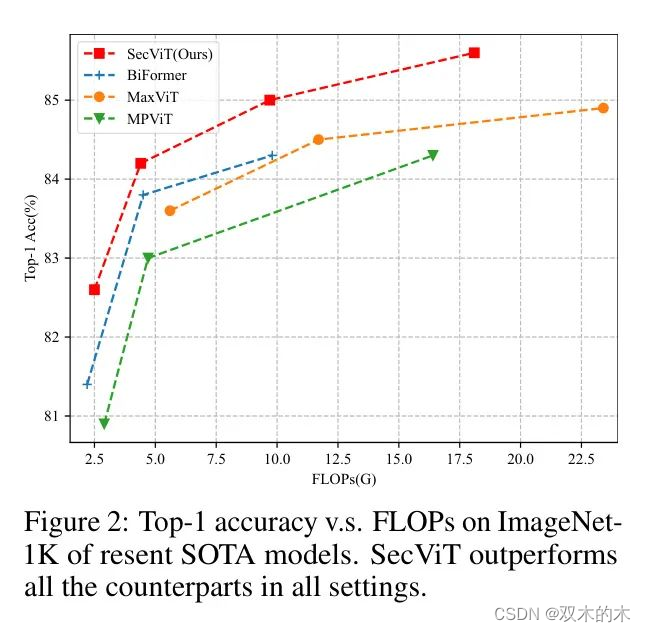
图2:在ImageNet-1K上,resent SOTA模型的Top-1准确度与FLOPs对比。SecViT在所有设置中均超越了所有同类模型。

2 相关工作
视觉Transformer(ViT)[13]被认为是一个强大的视觉架构,因其出色的视觉建模能力而受到认可。许多研究改进了Vision Transformer,包括提高其训练效率和降低计算成本。DeiT使用了蒸馏损失,并将大量的数据增强方法融入到ViT的训练过程中,这增加了模型的数据利用效率,使其能够在数据较少的情况下训练出有效的ViT。由PVT 表示的分层结构通过下采样键和值(KV)减少了全局注意力中的标记数量,从而将全局注意力的计算成本保持在可接受的范围内。除了使用下采样减少标记数量外,一些方法还直接根据标记的重要性进行剪枝,保留重要标记同时丢弃或合并不重要标记[15; 42]。这减少了标记的数量,进而降低了模型的计算成本。另一种极具代表性的方法是将所有标记分组,使得每个标记只能关注其所在组内的标记。这种方法也显著降低了自注意力的计算成本。
基于分组的视觉Transformer。大多数基于分组的注意力机制根据空间结构进行分组[36; 12; 48; 11; 35]。具体来说,Swin-Transformer [36] 根据它们的空间位置将所有标记划分为大小相等的窗口,其中每个标记只能关注其自身窗口内的标记。这显著降低了模型的计算成本。相比之下,CSWin [12] 将标记划分为交叉结构,这也降低了模型的计算成本。除了沿空间维度将标记划分为小窗口外,DaViT [11] 还沿通道维度将通道划分为多个组。与仅考虑位置信息进行分组的方法不同,DGT [35] 通过使用k-means聚类来对 Query 进行分组,同时考虑了语义信息。
3 Method
3.1 Overall Architecture
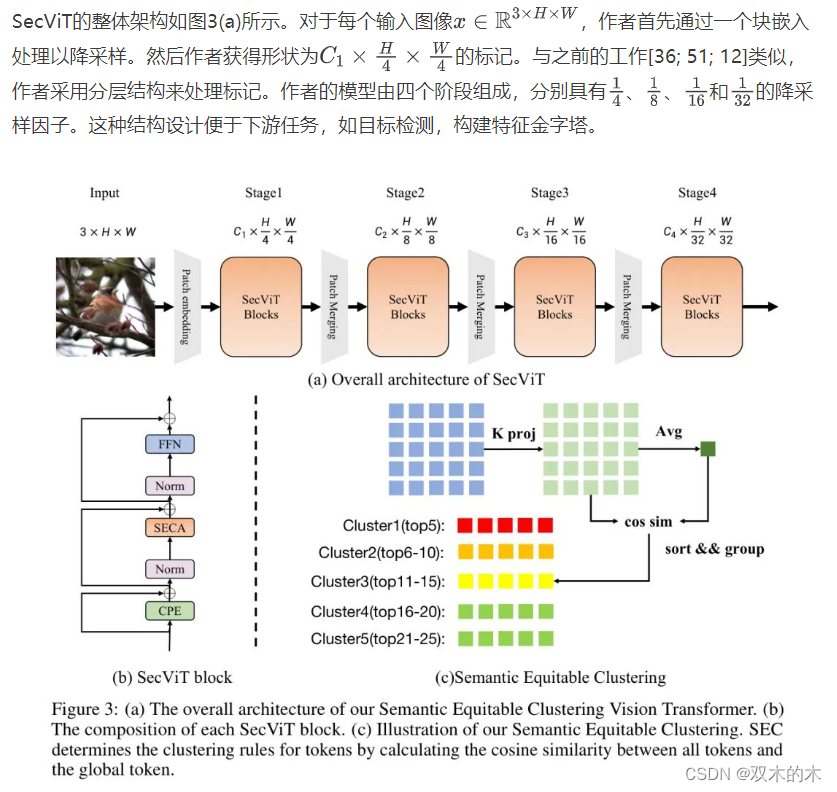

3.2 Semantic Equitable Clustering
正如先前所提及,语义公平聚类的设计目标有三:
-
在聚类过程中充分考虑不同标记中包含的语义信息。
-
与需要多次迭代的k-means等其他聚类方法不同,语义公平聚类可以在一步完成聚类。
-
确保每个簇中标记数量相等,便于在GPU上进行并行处理。在以下段落中,作者将详细描述作者的语义公平聚类如何实现这三个目标。整个过程如图3(c)所示。
与语义相关的单一聚类中心。k-means之所以相对复杂,有两个原因。首先,它具有多个聚类中心,每个标记需要计算其与每个聚类中心的距离以确定其簇成员身份。其次,K-means中每个聚类中心的确定并不精确,需要多次迭代才能准确建立簇中心。


基于以上步骤,作者完成了以最小的排序成本捕捉图像中语义信息的聚类过程。此外,与K-means相比,作者已经实现了每个簇的均等划分。聚类完成后,作者在每个簇内的标记上应用标准的Self-Attention(SECA),从而完成标记间信息的交互。
在完成SECA之后,为了进一步增强模型捕捉局部信息的能力,作者采用了一个局部上下文增强模块来建模局部信息,其中LCE [62; 12] 是一个简单的深度卷积:
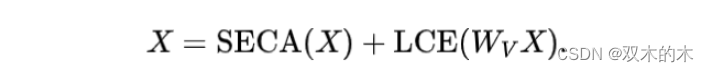
4 Experiments
作者在包括ImageNet-1k [10]上的图像分类、COCO [33]上的目标检测和实例分割以及ADE20K [61]上的语义分割在内的广泛视觉任务上进行了实验。所有模型都可以使用8个A100 80G GPU进行训练。
4.1 ImageNet Classification
作者从头开始在ImageNet-1k [10]上训练作者的模型。为了公平比较,作者遵循DeiT [47]中的训练策略,仅以分类损失作为监督。对于SecViT-T、SecViT-S、SecViT-B和SecViT-L,增加随机深度[23]的最大速率分别设置为0.1、0.15、0.4和0.5。
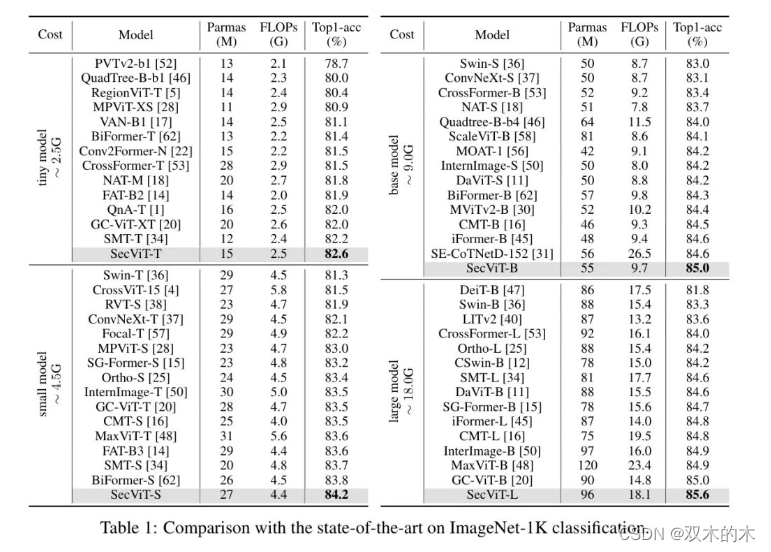
与SOTA的比较。作者将SecViT与众多最先进的模型进行比较,结果展示在表1中。SecViT在所有尺度上一致优于先前模型。值得注意的是,SecViT-S仅用1500万个参数和2.5G FLOPs就达到了84.2%的Top1准确率。对于更大的模型,SecViT-L在9600万个参数和18.1G FLOPs的情况下达到了**85.6%**的Top1准确率。
与 Baseline 的严格比较。作者选择了两个 Baseline :一个通用目的的 Backbone 网络,Swin-Transformer [36],和一个以效率为导向的 Backbone 网络,FasterViT [19],以与作者的SecViT进行比较。在比较模型(SEC-Swin和SEC-FasterViT)中,作者仅将原始Swin-Transformer和FasterViT中的注意力机制替换为基于语义平等聚类的自注意力,而没有引入其他任何模块(如CPE、卷积Stem等)。如表2所示,仅替换注意力机制就能在性能和效率方面带来显著优势。具体来说,SEC-Swin在Tiny和小型模型尺寸上实现了比Swin**2.0%**的改进甚至超越。同时,SEC-FasterViT在参数更少的情况下达到了比FasterViT更高的准确率。

4.2 Object Detection and Instance Segmentation

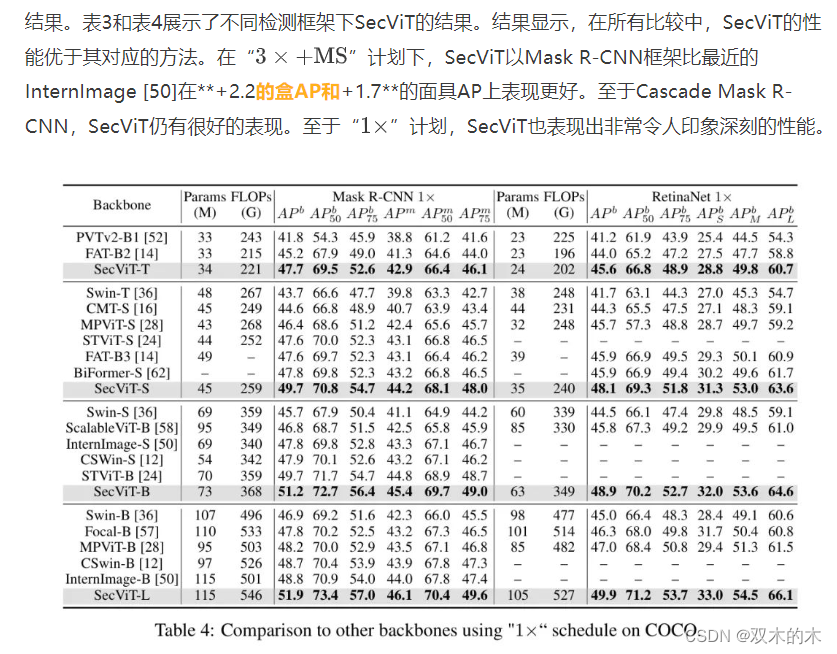

与CSWin-Transformer的比较。如表6所示,基于SecViT-T架构,作者将SECA替换为来自CSwin-Transformer的CSWSA。这导致分类性能显著下降(下降了1.2%)。这充分证明了作者提出的标记聚类方法的有效性。
Lce。LCE是一个简单的深度卷积模块,用于进一步增强模型建模局部信息的能力。作者对LCE进行了消融实验,并发现它对模型性能有一定的提升作用。结果在表6中展示。具体来说,它将模型的分类准确率提高了**+0.2**。
Cpe。在CPVT [7]中提出的CPE是一种即插即用、高度可移植的位置编码方法,被许多方法广泛采用以向模型提供位置信息。它由仅包含3x3深度卷积的残差块组成。表6中关于CPE的消融结果表明,它为模型提供了一定的性能提升(大约在分类准确率上增加了**+0.2**)。
Conv Stem。Conv Stem在模型的早期阶段使用,以提取更精细的局部特征。如表6中的数据所示,在分类任务中,Conv Stem在一定程度上增强了模型的性能。具体来说,Conv Stem将分类准确率提高了**+0.3**。
表7:聚类数量的影响。
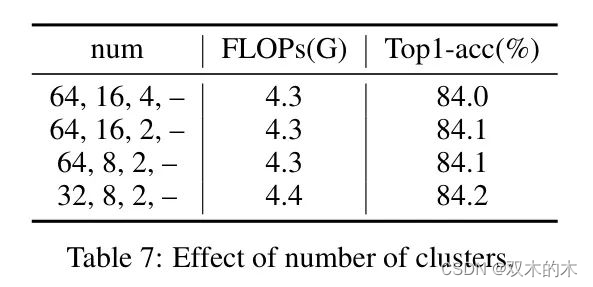
聚类数量的影响。在表7中,作者验证了在模型的最初三个阶段选择不同聚类数量对性能的影响。对于SecViT-S,作者分别为前三个阶段选择了32、8和2个簇。这个配置达到了84.2%的分类准确率。随着作者在每个阶段逐渐增加簇的数量,模型的总体计算量减少,准确率略有下降。这证明了语义聚类在聚类数量方面的鲁棒性。
4.3 Visualization of Semantic Clustering
为了进一步了解作者的语义公平聚类是如何工作的,作者可视化了一些样本的聚类结果。如图4所示,作者选择了预训练SecViT-B的第一、第二和第三阶段来观察不同标记的聚类结果。在图中,颜色相同的 Patch 属于同一个簇。很明显,在第一和第二阶段,作者的模型倾向于捕捉详细的信息,而在第三阶段,它倾向于捕捉语义信息。

5 Conclusion
作者提出了一种简单直接的针对视觉 Transformer (Vision Transformers)的聚类方法——语义公平聚类(Semantic Equitable Clustering,简称SEC)。
该方法通过计算每个标记与全局标记之间的相似性,然后相应地进行排序,将每个标记分配给一个簇。作者的聚类方法考虑了标记中包含的语义信息,在一步内完成聚类,并确保每个簇中标记数量相等,这有助于在现代GPU上进行高效的并行处理。基于语义公平聚类,作者设计了SecViT,一个多功能的视觉 Backbone 网络,在包括图像分类、目标检测、实例分割和语义分割在内的各种视觉任务上取得了令人印象深刻的结果。
5.1 Appendix A Architecture Details
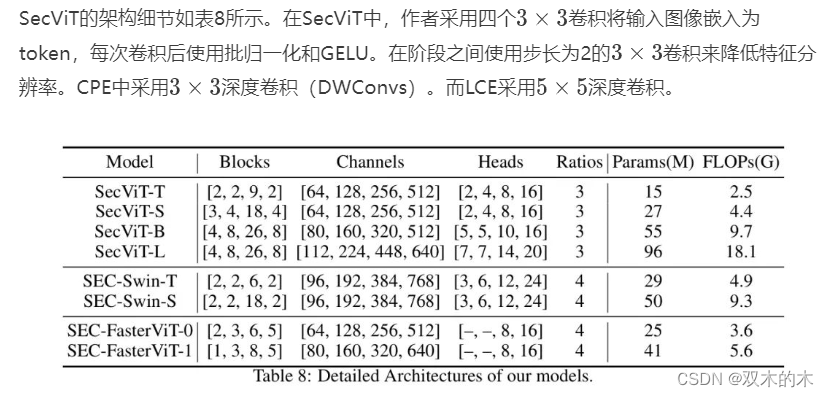
对于SEC-Swin,作者遵循Swin-Transformer [36]的设计原则,不使用额外的结构,如CPE或卷积干细胞。
对于SEC-FasterViT,作者遵循FasterViT [19]的设计原则。作者在模型的前两个阶段使用卷积以实现快速推理速度,在后两个阶段使用基于语义均衡聚类的自注意力(SECA)。
对于所有模型,作者将前三个阶段的簇数量分别设置为32、8和2。
5.2 Appendix B Experimental Settings
ImageNet图像分类。作者采用了DeiT [47]中提出的训练策略,唯一的监督是交叉熵损失。作者的所有模型都是从零开始训练300个周期,输入分辨率为224x224。使用了AdamW优化器,并配合余弦衰减学习率调度器和5个周期的线性预热。批量大小设置为1024。作者应用了与DeiT [47]中相同的适配和正则化方法,包括RandAugment [9](randn9-mstd0.5-inc1)、Mixup [60](prob = 0.8)、CutMix [59](prob = 1.0)、随机擦除(prob = 0.25)和指数移动平均(EMA)[41]。增加随机深度[23]的最大速率设置为SecViT-T/S/B/L分别为0.1/0.15/0.4/0.5。
COCO目标检测和实例分割。作者在MMDetection [6]的基础上应用了RetinaNet [32]、Mask-RCNN [21]和级联Mask R-CNN [3]作为检测框架。作者的所有模型都采用"1x "(12个训练周期)和"3x +MS"(36个训练周期,配合多尺度训练)设置进行训练。对于"1x "设置,图像被调整到较短的边为800像素,而较长的边在1333像素以内。对于"3 x +MS",使用多尺度训练策略,随机调整图像较短的边在480到800像素之间。对于这两个框架,作者使用初始学习率为1e-4的AdamW。对于RetinaNet,作者将权重衰减设置为1e-4。而对于Mask-RCNN和级联Mask R-CNN,作者将其设置为5e-2。
ADE20K语义分割。基于MMSegmentation [8],作者实现了UperNet [55]和SemanticFPN [27]来评估作者的模型在语义分割上的性能。对于UperNet,作者遵循Swin-Transformer [36]的先前设置,以512x512的输入大小训练模型160k次迭代。对于SemanticFPN,作者也使用512x512的输入分辨率,但训练模型80k次迭代。局限性和未来工作
尽管作者提出的语义均衡聚类在聚类标记和许多视觉任务上表现出显著的效率,但仍然存在一些需要在未来工作中解决的局限性。首先,计算限制阻止了作者实验更大模型和如ImageNet-21k这样的大型数据集。探索语义均衡聚类在大规模数据集和更大模型上的潜力可能会为其可扩展性和效率提供进一步见解。
未来,作者将努力验证作者的SecViT在大数据集和更大模型上的性能。
5.3 Appendix D Broader Impact Statement
语义均衡聚类(SEC)的发展有望通过为视觉 Transformer 中的标记提供一种高效且与语义相关的分组方法,影响计算机视觉领域。通过聚类标记,SEC减少了计算负载,提高了视觉模型的效率,这可能导致更广泛的应用。
所提出的SecViT是一个通用的视觉 Backbone 网络,可应用于不同的视觉任务,例如图像分类、目标检测、实例分割和语义分割。它没有直接的社会负面影响。作为通用 Backbone 网络的SecViT可能存在的恶意使用超出了作者研究的讨论范围。
5.4 Appendix E Code
作者提供了基于自注意力机制的语义均衡聚类(Semantic Equitable Clustering)的代码。
2 def __init__(self, embed_dim, num_heads, num_clusters): super().__init__()self.num_clusters = num_clusters self.embed_dim = embed_dim self.num_heads = num_heads self.head_dim = embed_dim // num_heads self.scaling = self.head_dim ** -0.5 self.qkv = nn.Conv2d(embed_dim, embed_dim*3, 1, bias=True) self.out_proj = nn.Conv2d(embed_dim, embed_dim, 1, bias=True)
3 def sort_sim(self, q: torch.Tensor, k: torch.Tensor):''' q: (b n h w)d k: (b n h w)d '''cls_token = q.mean(2, keepdim=True) # (b 1 d)cls_token = F.normalize(cls_token, dim=-1)k = F.normalize(k, dim=-1)cos_sim = cls_token @ k.transpose(-1, -2) # (b 1 (h w))sort_indices = torch.argsort(cos_sim, dim=-1)return sort_indices.squeeze(2) # (b (h w))
4 def sort_tensor(self, indices: torch.Tensor, target: torch.Tensor):'''indices: (b 1)target: (b 1 d)'''sorted_tensor = torch.gather(target, dim=-2, index=indices.unsqueeze(-1).expand_as(target))return sorted_tensor
5 def restore_tensor(self, indices: torch.Tensor, target: torch.Tensor):'''indices: (b m 1)target: (b m d)'''restored_tensor = torch.gather(target, dim=-2, index=indices.sort(dim=-1).indices.unsqueeze(-1).expand_as(target))return restored_tensor
6 def forward(self, x: torch.Tensor):'''x: (b c h w)'''bsz, _, h, w = x.size()l = h * wassert l % self.num_clusters == 0qkv = self.qkv(x) # (b 3*c h w)q, k, v = rearrange(qkv, 'b(m n d) h w -> m b n (h w) d', m=3, n=self.num_heads) # q,k,v -> b n (h w) dk = k * self.scalingif self.num_clusters > 1:indices = self.sort_sim(k, k) # (b n (h w))q = self.sort_tensor(indices, q) # (b n (h w) d)k = self.sort_tensor(indices, k) # (b n (h w) d)v = self.sort_tensor(indices, v) # (b n (h w) d)q_1 = rearrange(q, 'b n (c l) d -> b n c l d', c=self.num_clusters)k_l = rearrange(k, 'b n (c l) d -> b n c l d', c=self.num_clusters)v = rearrange(v, 'b n (c l) d -> b n c l d', c=self.num_clusters)attn = torch.softmax(q_l @ k_l.transpose(-1, -2), dim=-1) # (b n c l l)v = attn @ v # (b n c l d)v = rearrange(v, 'b n c l d -> b n (c l) d')v = self.restore_tensor(indices, v) # (b n (h w) d)v = rearrange(v, 'b n (h w) d -> b n (d) h w', h=h, w=w)else:attn = torch.softmax(q @ k.transpose(-1, -2), dim=-1) # (b n (h w))v = attn @ v # (b n (h w) d)v = rearrange(v, 'b n (h w) d -> b (n d) h w', h=h, w=w)return self.out_proj(v)
6 参考
[1].Semantic Equitable Clustering: A Simple, Fast and Effective Strategy for Vision Transformer.
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。
这篇关于CV技术指南 | 中科院又一创举 SecViT | 多功能视觉 Backbone 网络,图像分类、目标检测、实例分割和语义分割都性能起飞!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






