本文主要是介绍LLMs Can’t Plan, But Can Help Planning in LLM-Modulo Frameworks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
更多精彩内容,请关注微信公众号:NLP分享汇
原文链接:LLMs Can’t Plan, But Can Help Planning in LLM-Modulo Frameworks

你是怎么理解LLM的规划和推理能力呢,来自亚利桑那州立大学最近的一篇论文,对LLM的规划、推理能力提出了一些新看法。
在看这篇文章时,你不妨可以带入以下角色进行理解:
-
乐观型:认为只要采用了合适的提示策略,LLM就能很好的完成任务
-
悲观型:LLM在规划,或者推理任务唯一的好处是将问题从一种句法格式翻译成另一种,真正解决问题还需要靠外部符号求解器。
为什么会觉得LLM不能规划?
从丹尼尔·卡尼曼的《Thinking fast and slow》看LLM
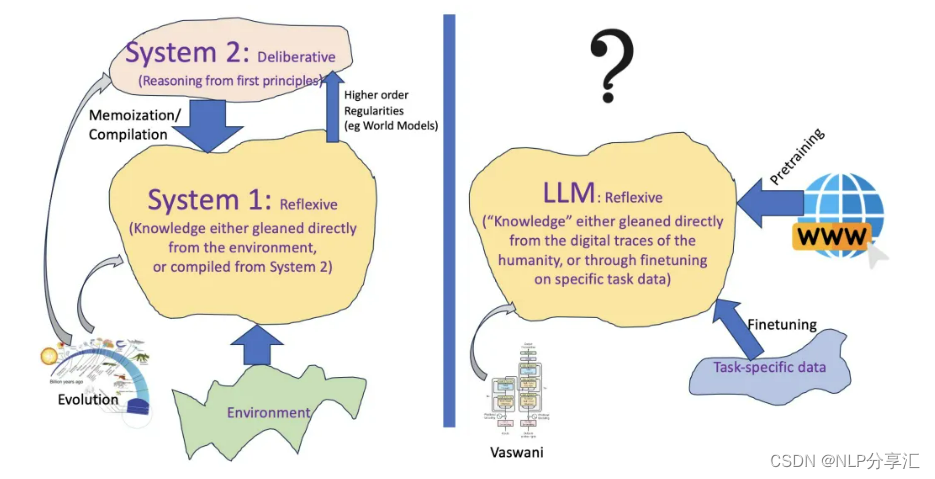
图1 An informal account of viewing LLM
图1提供了一个非正式的视角,将大型语言模型(LLMs)视为一个巨大的外部非真实记忆(external non-veridical memory),充当伪系统1(pseudo System 1)。这一视角旨在解释LLMs在规划和推理任务中的作用及其局限性。
在心理学中,系统1通常指的是快速、直觉和自动的认知过程,而系统2则涉及缓慢、逻辑和努力的认知过程。这里,作者使用Kahneman(2011)的理论《Thinking fast and slow》,将LLMs比作一个巨大的伪系统1,意味着它们能够快速生成文本和响应,但并不涉及深层次的推理或规划。
为什么LLM不能规划?
自主模式下的限制:尽管最初有关LLMs规划能力的说法颇为乐观,但近期的多项研究一致表明,在自主模式下,LLMs实际上无法生成可执行的计划。即使是表现最佳的LLM(GPT-4),平均也只有大约12%的生成计划是无误且能达到目标的。这说明LLM可能只是做近似的规划检索,而不是真正的规划。
无法自我验证:LLM无法验证自己生成的规划,因此无法通过自我批评改进规划。尽管LLM不能一次性生成正确的解决方案,但通过迭代提示,它们可能会通过自我批评提高准确性。但研究表明,LLM在验证解决方案方面并不比生成解决方案表现更佳。
知识获取与执行规划混淆:规划任务需要的不仅仅是规划领域知识,还需要能够将这些知识组装成一个可执行的规划,考虑到目标与资源的相互作用。LLM通常在提取规划知识方面做的很好,但这并不意味着它们能够生成可执行的规划。
对自我改进的误解:LLM可以通过生成规划、自我批评规划,然后使用这些规划来自我改进(例如通过合成数据微调)。但是,由于LLM无法验证自己的解决方案,这种自我改进的方法实际上是不可行的。
LLM-Modulo
有了动机,自然要提出解决方案,LLM-Modulo就是论文提出用于解决LLM无法规划的框架。如下图2就是LLM-Modulo的模型架构。
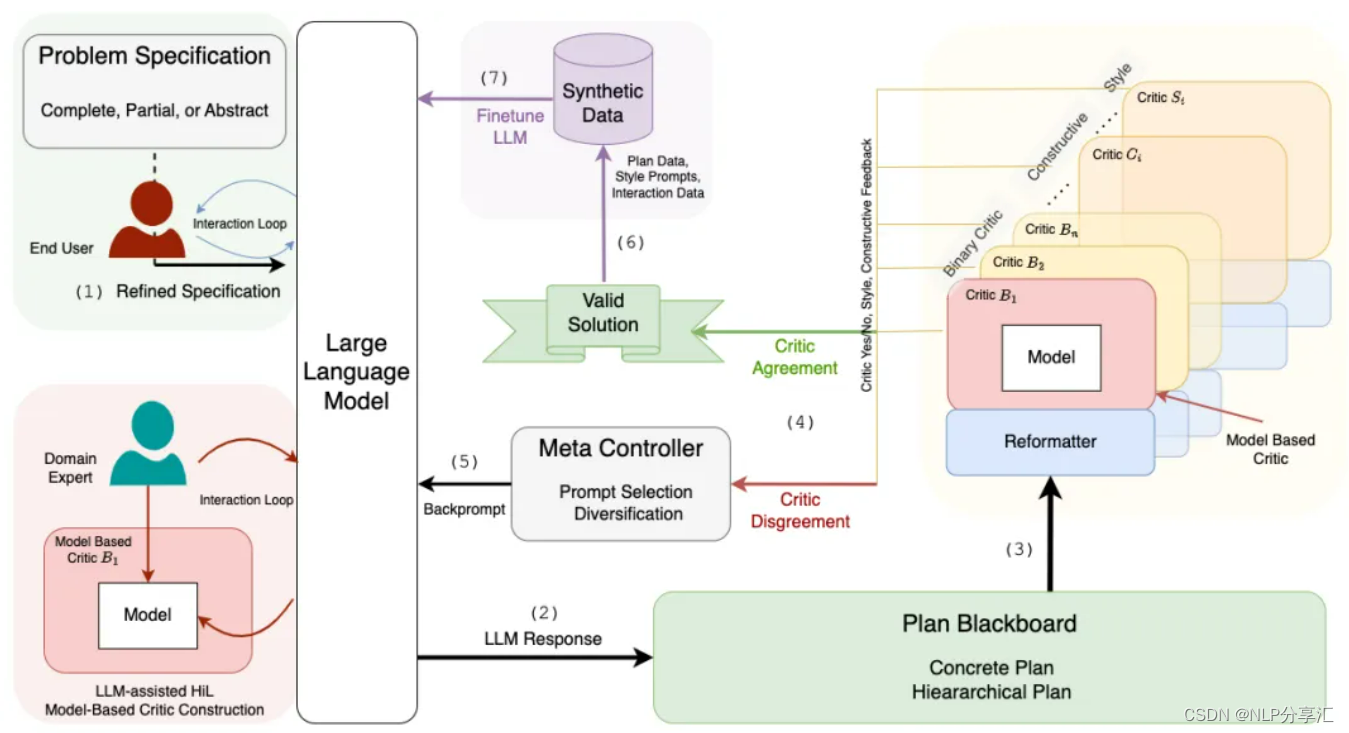
图2 LLM-Modulo
LLM-Modulo架构就是一个“生成-测试-批评”的循环。通过让LLM生成候选规划,并利用一系列外部验证器对这些规划进行评估和反馈,确保了规划的准确性和可靠性。
语言模型生成创意和潜在解决方案方面表现出色,而外部验证器则严格检查规划是否满足所有必要的约束条件。这种结合神经网络和符号逻辑的方法,不仅提高了规划任务的准确性,还增强了框架的灵活性、扩展性,使其能够适应各种不同规划场景。
该框架另一个优势是支持人机协作。领域专家在整个过程发挥至关重要的作用,它们的知识用于指导和细化LLM生成的规划,确保规划符合实际需求和约束。
模型架构流程
-
Refined Specification:用户有大量问题规范(Promblem Specification)需要去改进提升,问题规范可能是完整/部分/抽象的。LLM接收一个问题规范或描述,这个问题规范是对所需要解决的任务的描述,可能包含目标、约束、初始状态和可能的动作等信息。
-
LLM Response:LLM根据接收到的问题规范生成一个/多个候选计划,这些计划是解决问题的潜在方案,它们可能不完全正确或可行。
-
外部验证环节
-
Critics(外部验证器):通过Hard/Soft Critics评估LLM生成的规划、推理候选。
-
Hard Critics:基于模型的验证器。评估计划是否满足所有硬性约束。如因果正确性等。
-
Soft Critics:可能基于LLM,评估计划的其他方面,如风格,可解释性或偏好符合性等。
-
如果所有的Critics都认可当前候选方案,那么将被认为是返回给用户的有效解决方案。如果不认可,则提供不同程度的反馈
-
No, try again
-
No, try again, here is one things wrong with the current plan
-
No, try again, here are all the things wrong with the current plan
-
-
-
Reformatter(重组器)
-
该组件将LLM生成的候选计划转为外部验证器所需的特定语言形式。由于不同的验证器可能需要特定格式的输入,Reformatter负责将LLM的输出调整为这些特定格式,以便critics能够有效评估计划的有效性和正确性。
-
-
-
Fine-tuning & Synthetic Data
-
一但LLM-Modulo框架解决了一个规划实例,该解决方案就可以添加到合成数据语料库中。该数据语料间歇性地用于微调LLM,以此提升模型生成规划的能力
-
虽然微调不能保证生成的解决方案正确性,但它可能会提高LLM猜测更接近Critics审查候选时被接受的机会。
-
为什么不用LLM作为外部验证器?
要解释这个问题,可以引用该篇论文作者在23年发表的论文《Can Large Language Models Really Improve by Self-critiquing Their Own Plans?》进行解释。感兴趣的具体看看文章:https://arxiv.org/pdf/2310.08118。
自我批评会降低规划生成的性能,特别是与具有外部验证器和LLM验证器的系统相比。LLM会产生大量错误信息,从而损害系统的可靠性。

表1 Comparison between various plan generation methods on the Blocksworld domain
总之,这篇论文主张大型语言模型(LLMs)自身无法执行复杂的规划任务,但可以在LLM-Modulo框架内,与外部基于模型的验证器相结合,发挥辅助规划的作用,通过这种神经符号集成方法,提高规划和推理任务的灵活性和表达力。
这篇关于LLMs Can’t Plan, But Can Help Planning in LLM-Modulo Frameworks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

![[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs](https://img-blog.csdnimg.cn/img_convert/e75c9a4137c39630cd34c5ebe3fe8196.png)