本文主要是介绍计算机毕业设计hadoop++hive微博舆情预测 微博舆情分析 微博推荐系统 微博预警系统 微博数据分析可视化大屏 微博情感分析 微博爬虫 知识图谱,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Abstract
With the popularity of social media and the rapid development of Internet technology, hot public opinion events occur frequently. For the government, enterprises and the public, it has become an important task to timely understand and analyze hot public opinion and grasp the trend of public opinion. However, the traditional data processing and analysis methods are powerless in the face of massive and real-time public opinion data, and cannot meet the needs of timely, accurate and comprehensive analysis. Therefore, this study uses Hadoop, Hive and other technologies to conduct a comprehensive analysis of hot public opinion by taking microblog data as an example.
Aiming at the crawling problem of microblog data, this system uses Selenium to realize the automatic crawling of data and store the data into MySQL database. It can efficiently crawl a large number of microblog data, including title, popularity, time, author, province, forwarding, hot search and other information.
For massive data preprocessing, the system uses mapreduce for data preprocessing. The data in MySQL is divided, sorted, merged, reduced and other operations are distributed to achieve fast and efficient data preprocessing. Then, to facilitate data analysis and visualization, convert the preprocessed data into.csv files and upload them to the HDFS file system. Then use Hive to create libraries and tables and import.CSV data sets.
Faced with the problem of analysis and visualization of microblog data, the system uses Hive for data analysis, and can quickly aggregate and screen microblog data. Import the analysis results into MySQL database using sqoop, and use Flask and Echarts to visually visualize the data, such as drawing pie charts, scatter charts, bar charts, maps, etc., for easy analysis and decision making.
To sum up, the system realizes automatic crawling of microblog data, efficient pre-processing of massive data, distributed uploading of data, and rapid analysis and visualization of data through the above steps. This research can provide data support for relevant enterprises such as airlines, so as to optimize and make decisions on flight routes.
Key Words:Hadoop; Public sentiment; Hive; Sqoop; visualization
目 录
摘 要
Abstract
1.绪论
1.1研究背景及意义
2.相关平台与技术介绍
2.1 Hadoop 集群
2.2 MySQL
2.3 Hive
2.4 Selenium
2.5 ECharts
3系统实现过程
4.平台搭建与部署
4.1 MySQL 部署
4.2Xshell部署
4.3Hadoop部署
4.4Hive部署
5.数据的流转过程与处理
5.1舆情数据分析的意义
5.2数据的爬取过程
5.2.1爬取评论数据(标题、链接)
5.2.2爬取热搜数据
5.2.3爬取文章数据(用户姓名、内容,转发评论点赞数)
5.3数据预处理
5.4数据上传Hive
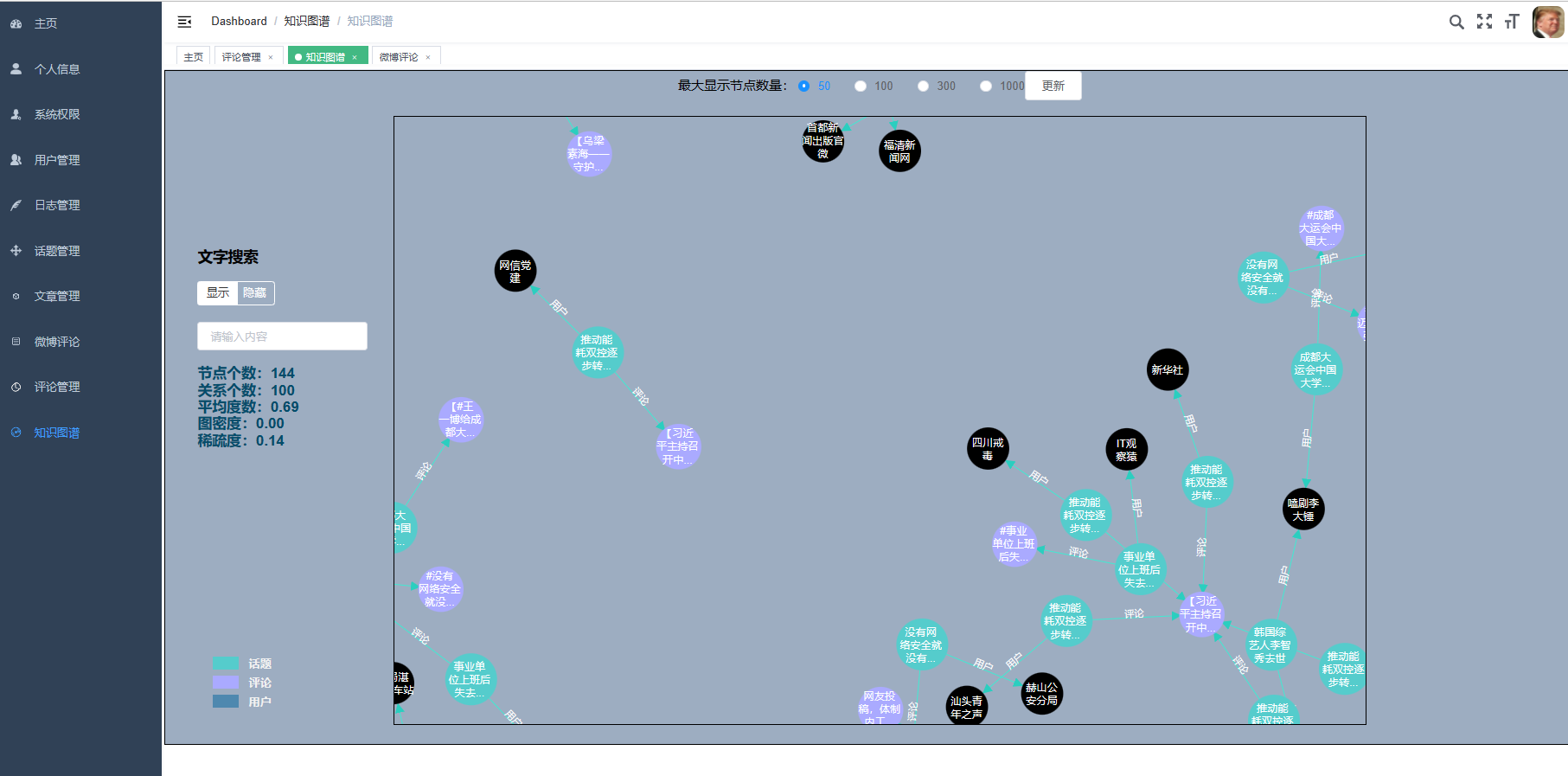
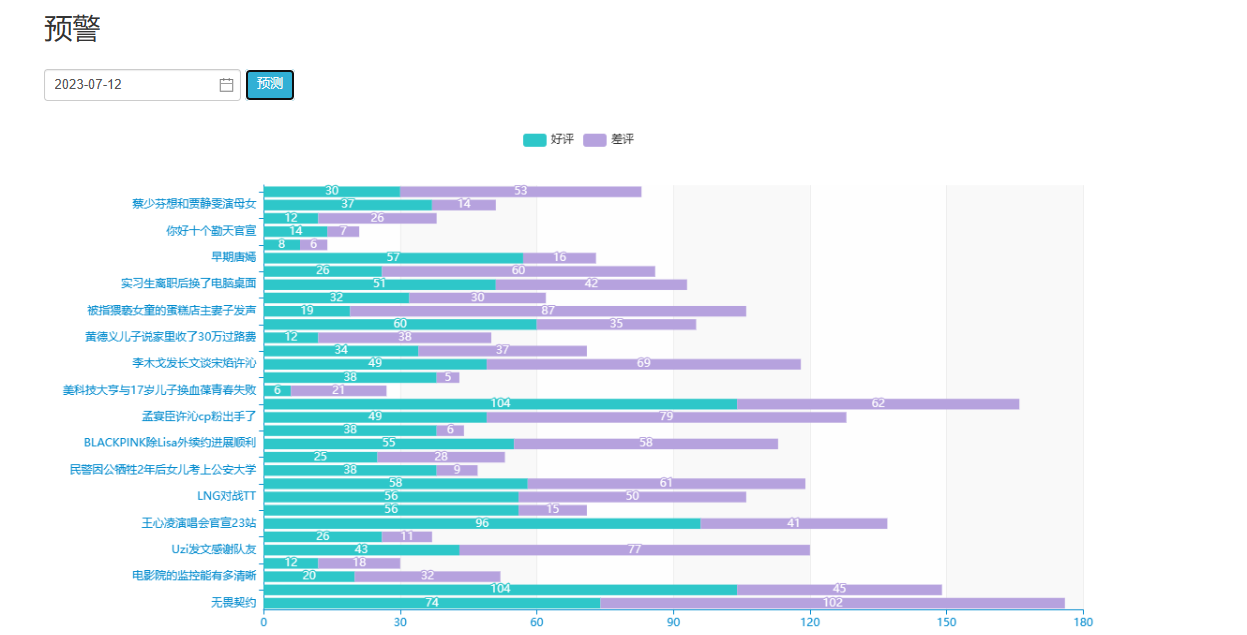
5.5数据可视化
6.结论和展望
6.1研究总结和贡献
6.2局限性和改进方向
6.3未来的发展和应用展望
参考文献
致 谢







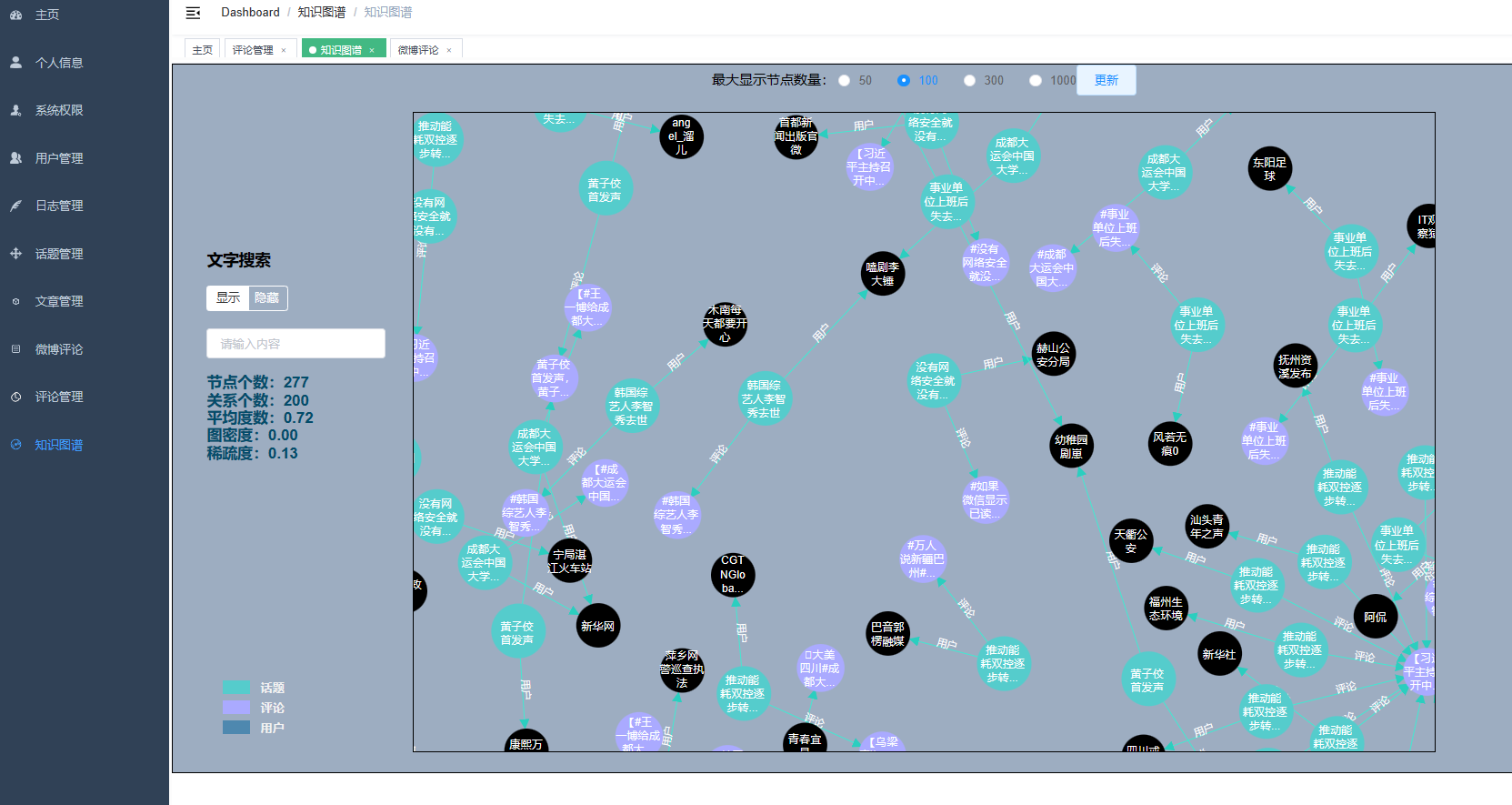
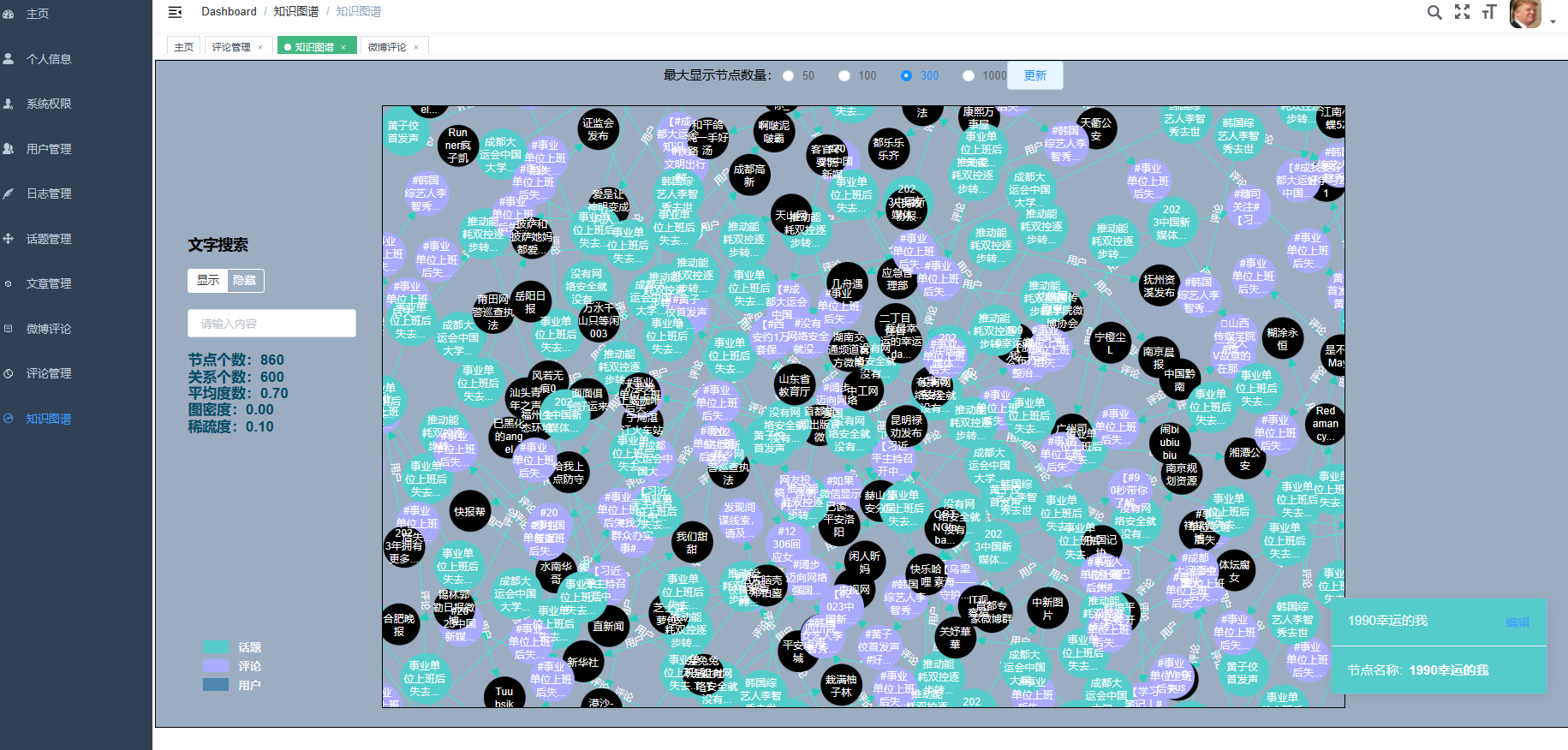

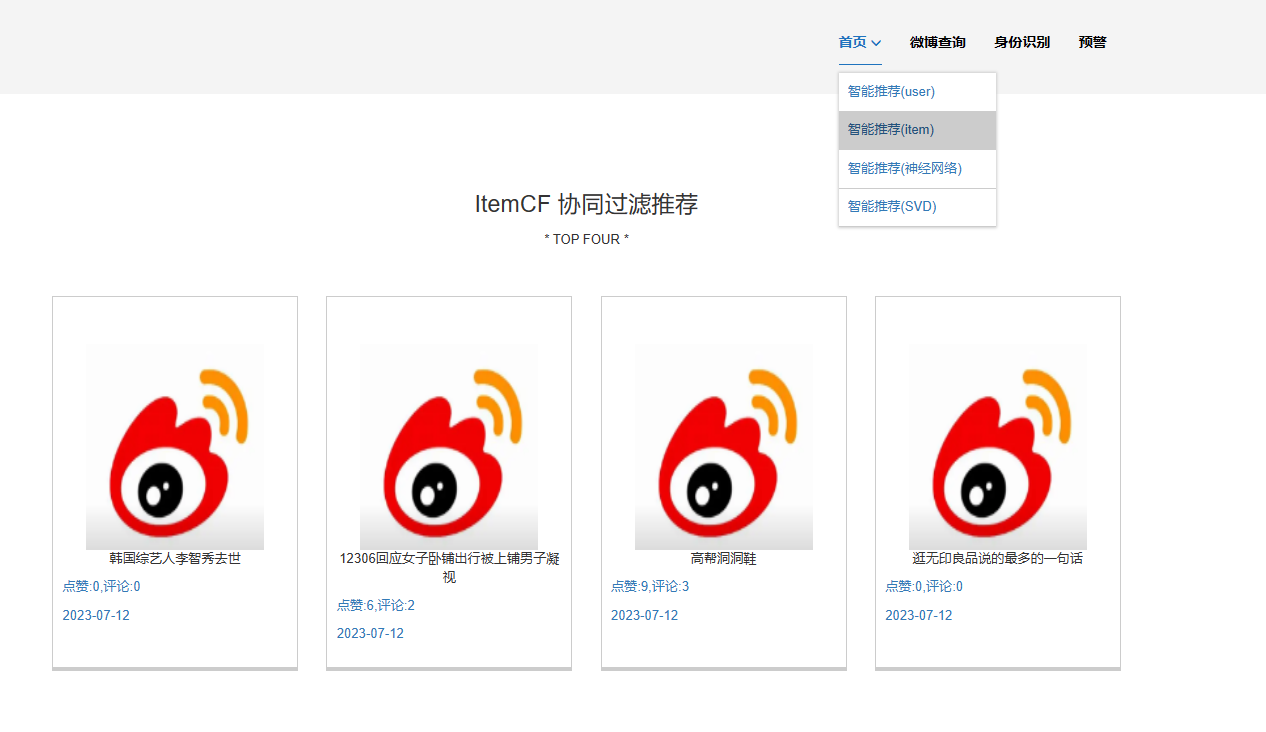
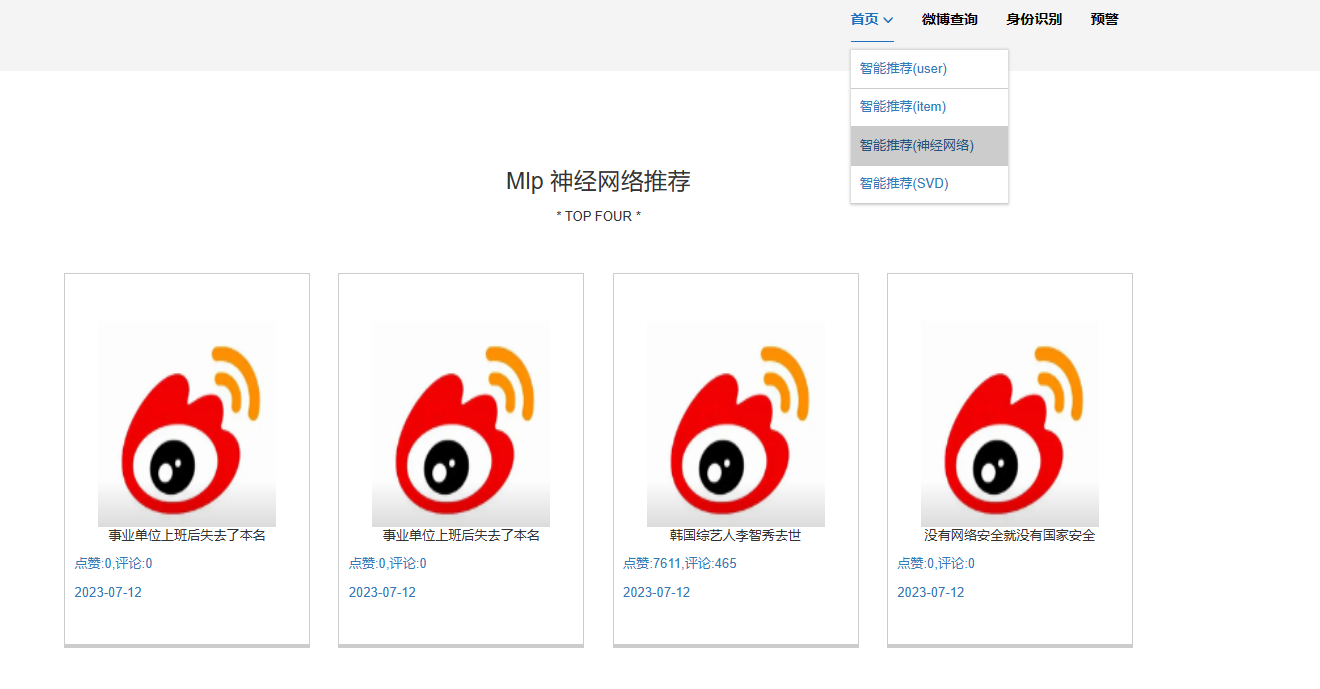
核心算法代码分享如下:
import requests
import json
import pprintdef address(address):url="XXXXXXXXXXXXXXXXX"%('f1063cfc84a84bd3b1d3a339c87b8bd0',address)data=requests.get(url)contest=data.json()#返回经度和纬度print(contest)contest=contest['geocodes'][0]['location']return contestif __name__ == '__main__':resp=address('北京市')print(resp)print(resp.split(',')[0])print(resp.split(',')[1])这篇关于计算机毕业设计hadoop++hive微博舆情预测 微博舆情分析 微博推荐系统 微博预警系统 微博数据分析可视化大屏 微博情感分析 微博爬虫 知识图谱的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








