本文主要是介绍COLING 2024: 复旦发布AoR,层级聚合推理突破大模型复杂推理上限,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
“三个臭皮匠,顶个诸葛亮?”
“一个模型不行,那就再堆一个?”
过去当我们在处理复杂任务的时候,往往会考虑集成策略(Ensembling Strategy),通过多个模型投票的方式,选出更可能正确的答案。然而在更复杂的情况下,“真理往往掌握在少数人手中”,这时采取多数投票,就会使得结论偏离正确答案更远。
3.5研究测试:
hujiaoai.cn
4研究测试:
askmanyai.cn
Claude-3研究测试:
hiclaude3.com
因此,与其单纯评估答案是否正确来进行投票,不如反推思考过程,就好比在考试的时候,写出正确的应用题解题步骤至少就能得到大半的分。如果能对模型的中间推理步骤也做进一步剖析,将有助于得到更可靠的结果。
论文标题:
Aggregation of Reasoning: A Hierarchical Framework for Enhancing Answer Selection in Large Language Models
论文链接:
https://arxiv.org/pdf/2405.12939.pdf
思维链
思维链(Chain-of-Thought,CoT)技术是一种在大模型(LLMs)中引入的技术,旨在通过生成一系列中间步骤来解决复杂的推理任务。这种方法不仅仅是简单地给出答案,而是通过详细的推理过程来逐步解决问题,从而使得模型的推理能力得到显著提升。CoT技术通过引导模型生成逻辑上连贯的推理链,帮助模型更好地理解和处理复杂问题。
研究表明,CoT技术可以在不需要额外训练的情况下,通过简单的提示改进来提升模型在复杂推理任务上的表现。此外,CoT技术还被用于多步骤解决方案的生成,使得模型能够处理更加复杂和多变的问题。
然而,这种技术也存在一定的局限性,例如在使用单一推理链时可能出现随机性,这可能导致模型在选择最终答案时出现偏差。为了克服这一点,研究者提出了通过调整采样温度来收集多样化的推理链,并通过多数投票机制来选择最一致的答案。尽管这种方式在大多数情况下被验证有效,然而当正确答案出现在占少数比例的推理链时,这种方式则限制了CoT集成方法的能力上限。
基本概念
-
标准提示(Standard Prompting):在标准提示下,大语言模型(LLM)接收问题和提示作为输入。模型将依次生成答案的每个token,目标是在每一步最大化似然概率。
-
思维链提示(CoT Prompting):思维链提示法通过增强提示,从而将问题解决过程整合进去,并引导LLM在生成答案之前生成一个理由。将理由和答案对称为一个推理链。推理链的概率公式包括理由在给定提示和问题下的概率,以及在给定理由和问题下生成答案的概率。
-
自我一致性(Self-Consistency):自我一致性方法使用CoT提示来采样个推理链集合,每个推理链包括一个理由和一个答案。最终答案来自于答案集合中出现次数最频繁的那个。
AoR框架
AoR(Aggregation of Reasoning)框架分为两个主要阶段:局部评分(Local-Scoring)和全局评估(Global-Evaluation)。此外为提高性能,该框架也引入了动态采样(Dynamic Sampling)过程。
两阶段架构
首先,使用思维链提示法采样个推理链,每个推理链包括一个理由和一个答案,如果有个不同的答案生成,这些答案将被分类到个不同的桶中,每个桶代表一个答案集合。在局部评分阶段,对每个桶内的推理链进行评分。在全局评估阶段,从每个桶中选择代表进行评估,以确定最终输出。
-
局部评分:局部评分专注于在具有相同答案的组内选择高质量的推理链。假设有个推理链引导出一致的答案,这些推理链就形成一个桶,当这些推理链同时输入LLM时,根据提示中的评估标准(下图右上角黄色方框),LLM为每个推理链分配一个分数。然后基于预定义的阈值ϵ,高质量推理链被识别出来,并从这个筛选后的集合中选择前个作为桶的代表。
-
全局评估:全局评估的任务是在不同答案的推理链中区分和选择最佳推理链,以确定最佳推理过程。假设有个桶,每个桶选择一个代表,形成一组个代表。当这些代表同时输入LLM时,根据提示中的评估标准(下图右下角绿色方框),LLM为每个代表分配一个分数。
-
多轮评估:通过k轮评估,最终选择平均分数最高的桶作为最终答案。

动态采样
与此同时,AoR框架还创新性地引入了动态采样策略。利用全局评估阶段的分数,AoR根据当前LLM对最优推理链的信心水平来动态决定是否需要采样更多的推理链。这一策略使得AoR能够根据问题的复杂性和模型的当前表现来调整推理链的采样数量,有效地平衡了性能和计算成本,减少了不必要的计算开销。
动态采样的步骤如下:
-
确定两个关键答案:α(平均分数最高)和β(平均分数第二高)。
-
如果α和β之间的分数差距超过预定义阈值θ,则选择α作为最终答案并终止采样过程。
-
如果分数差距小于θ,AoR继续采样额外的个推理链,并根据既定标准评估这些新链的分数。
-
如果新采样的链引入了新答案或显著改变了分数排名,则需要在全局评估阶段重新评估以重新校准分数。
总的来说,动态采样在两种情况下停止:领先答案之间的信心差距达到或超过θ,或采样的推理链总数达到预定义的最大值。

实验
实验任务和数据集
本研究涉及三种推理任务:数学推理、常识推理和符号推理。
数学推理任务包括GSM8K、MultiArith、SingleEQ、SVAMP、AddSub和AQuA数据集。
常识推理任务涵盖StrategyQA、CommonsenseQA、BoolQ和ARC-C数据集。
符号推理任务则包括Date Understanding、Penguins in a Table、Colored Objects和Object Counting数据集。
实验结果与分析
AoR在六个数学推理数据集上的表现超过了所有基线方法。特别是在AQuA数据集上,AoR相比于次优方法DiVeRSe提高了7.2%的平均性能。
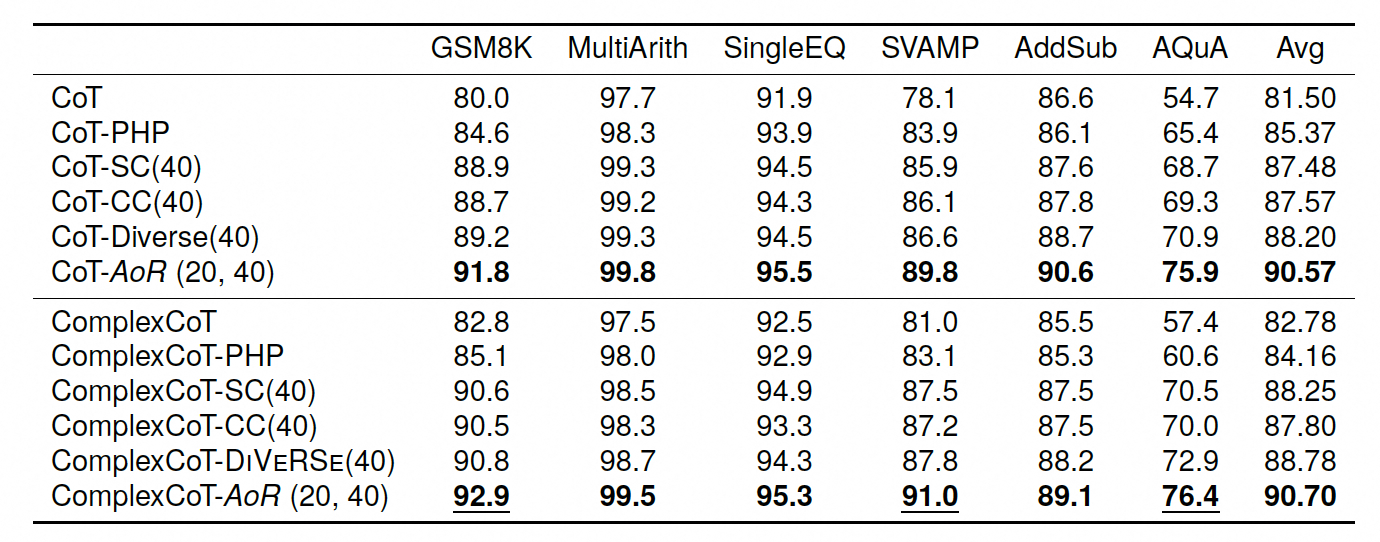
此外,AoR在常识推理任务中也表现出显著的性能提升,相比于SC和CC方法,平均提高了8.45%和8.27%。在符号推理任务中,AoR在Date Understanding和Penguins数据集上相比SC分别提高了5.8%和8.9%。

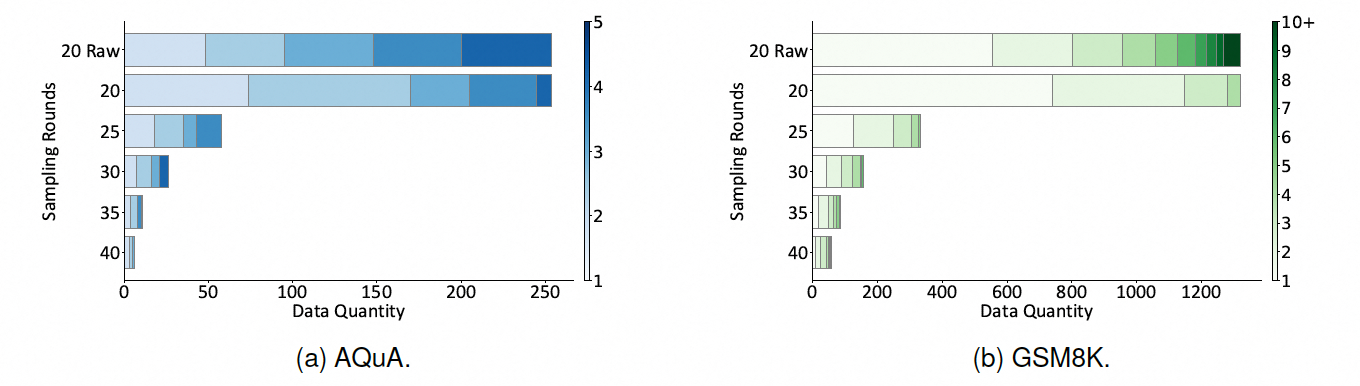
动态采样是AoR方法的一个关键特性,它根据LLM在最优推理链上的信心水平动态决定是否需要采样更多推理链。如下图所示,在AQuA和GSM8K数据集上,大部分样本在第一轮后就已经得到了满意的答案,只有少数更复杂的样本需要进一步的推理链。这种方法不仅提高了决策的准确性,还通过减少不必要的计算,实现了性能与计算成本之间的平衡。
讨论
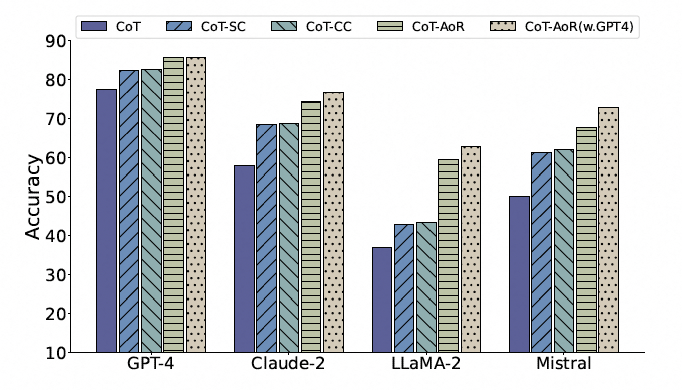
本文评估了AoR框架在包括GPT-4,Claude-2,LLaMA-2,Mistral在内不同LLMs上的效果,与SC和CC方法相比,AoR平均分别提高了8.1%和7.6%。尤其在LLaMA-2模型上,与SC相比,AoR的性能提高了16.6%。
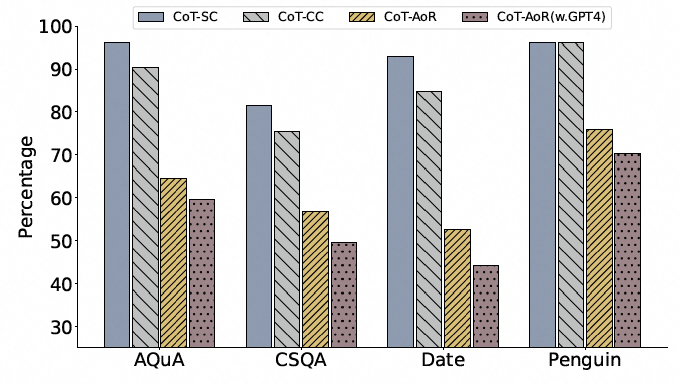
此外,当候选集中包含正确答案时,AoR未能正确选择该答案的样本比例显著减少,表明AoR在利用推理链信息提高选择正确答案的可能性方面是高效的。
AoR在提高性能的同时显著降低了开销。例如,CoT-AoR (20,40)在性能上超过CoT-SC(40),并且开销减少了20%。
在动态采样的局部评估阶段,本文使用不同的示例策略对最终答案的影响进行了评估。使用最高分和最低分的推理链作为示例可以获得最佳性能。
总结与展望
AoR方法通过引入层次化的推理链聚合框架,显著提高了LLM在复杂推理任务中的表现。通过局部评分和全局评估的两阶段过程,AoR不仅提高了答案的准确性,还通过动态采样机制有效平衡了性能和计算成本。此外,AoR的设计充分利用了LLM的评估能力,进一步提升了模型判断的准确性。
尽管AoR在提高推理任务的性能方面取得了显著成效,但仍有一些潜在的改进空间。首先,当前的AoR框架可能在处理极其复杂或含糊不清的问题时仍会遇到挑战。这些情况下,即使是经过筛选的高质量推理链也可能无法覆盖所有可能的答案,导致最终选择的答案不够准确。
其次,AoR的效率和效果很大程度上依赖于LLM的评估能力。如果能进一步提高LLM的评估准确性,或者开发出更先进的评估算法,那么AoR的性能可能会得到进一步的提升。
最后,考虑到不同任务和数据集特性,AoR的通用性和适应性也是未来研究的一个重要方向。通过对不同类型的推理任务进行更深入的分析和优化,可以使AoR方法在更广泛的应用场景中发挥更大的效用。


这篇关于COLING 2024: 复旦发布AoR,层级聚合推理突破大模型复杂推理上限的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








